LLM PuzzleTest
1.0.0
PuzzleVQA، تكشف مجموعة البيانات الجديدة لدينا عن تحديات خطيرة تواجه ماجستير إدارة الأعمال متعدد الوسائط في فهم الأنماط المجردة البسيطة. ورق | موقع إلكتروني
نحن نصدر AlgoPuzzleVQA، وهي مجموعة بيانات جديدة ومليئة بالتحديات للاستدلال متعدد الوسائط! وسنقوم قريبًا بإصدار المزيد من مجموعات بيانات الألغاز متعددة الوسائط. ابقوا متابعين! ورق | موقع إلكتروني
يسعدنا أن نعلن عن إصدار مجموعتي بيانات VQA الجديدتين اللتين تتمحوران حول الألغاز:
إن أداء MLLMs في كلتا مجموعتي البيانات ناقص بشكل ملحوظ، مما يؤكد الحاجة الملحة لإجراء تحسينات كبيرة في قدراتهم المنطقية متعددة الوسائط.
تعمل النماذج الكبيرة متعددة الوسائط على توسيع القدرات الرائعة لنماذج اللغات الكبيرة من خلال دمج قدرات الفهم متعدد الوسائط. ومع ذلك، ليس من الواضح كيف يمكنهم محاكاة الذكاء العام والقدرة على التفكير لدى البشر. نظرًا لأن التعرف على الأنماط والمفاهيم المجردة يعد أمرًا أساسيًا للذكاء العام، فإننا نقدم PuzzleVQA، وهي مجموعة من الألغاز المبنية على أنماط مجردة. باستخدام مجموعة البيانات هذه، نقوم بتقييم نماذج كبيرة متعددة الوسائط بأنماط مجردة تعتمد على المفاهيم الأساسية، بما في ذلك الألوان والأرقام والأحجام والأشكال. ومن خلال تجاربنا على أحدث النماذج الكبيرة متعددة الوسائط، نجد أنها غير قادرة على التعميم بشكل جيد على الأنماط المجردة البسيطة. والجدير بالذكر أن حتى GPT-4V لا يمكنه حل أكثر من نصف الألغاز. لتشخيص تحديات الاستدلال في النماذج الكبيرة متعددة الوسائط، نقوم بتوجيه النماذج تدريجيًا من خلال تفسيرات الاستدلال المنطقي للحقيقة الأرضية للإدراك البصري، والاستدلال الاستقرائي، والاستدلال الاستنتاجي. يجد تحليلنا المنهجي أن الاختناقات الرئيسية لـ GPT-4V هي ضعف الإدراك البصري وقدرات التفكير الاستقرائي. ومن خلال هذا العمل، نأمل في تسليط الضوء على القيود المفروضة على النماذج الكبيرة متعددة الوسائط وكيف يمكنها محاكاة العمليات المعرفية البشرية بشكل أفضل في المستقبل.
يتوفر PuzzleVQA هنا وأيضًا على Huggingface.
يوضح الشكل أدناه سؤالاً نموذجيًا يتضمن مفهوم اللون في PuzzleVQA، وإجابة غير صحيحة من GPT-4V. هناك بشكل عام ثلاث مراحل يمكن ملاحظتها في عملية الحل: الإدراك البصري (الأزرق)، والتفكير الاستقرائي (الأخضر)، والتفكير الاستنتاجي (الأحمر). وهنا، كان الإدراك البصري غير مكتمل، مما تسبب في حدوث خطأ أثناء الاستدلال الاستنتاجي.

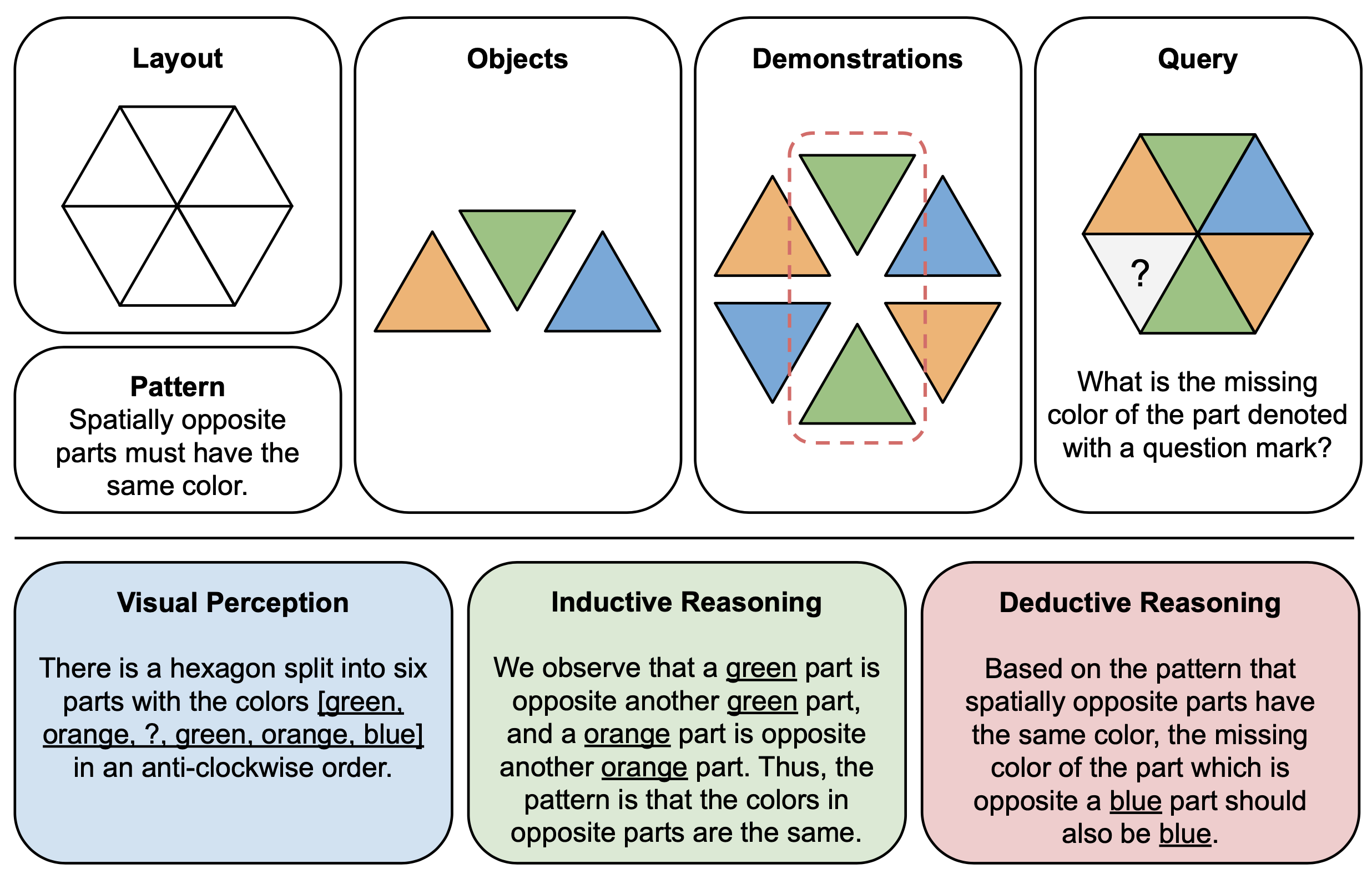
يوضح الشكل أدناه مثالًا توضيحيًا للمكونات (أعلى) وتفسيرات المنطق (أسفل) للألغاز المجردة في PuzzleVQA. لإنشاء كل مثيل لغز، نقوم أولاً بتحديد تخطيط ونمط قالب متعدد الوسائط، وملء القالب بالكائنات المناسبة التي توضح النمط الأساسي. من أجل قابلية التفسير، نقوم أيضًا ببناء تفسيرات منطقية للحقيقة الأساسية لتفسير اللغز وشرح مراحل الحل العامة.
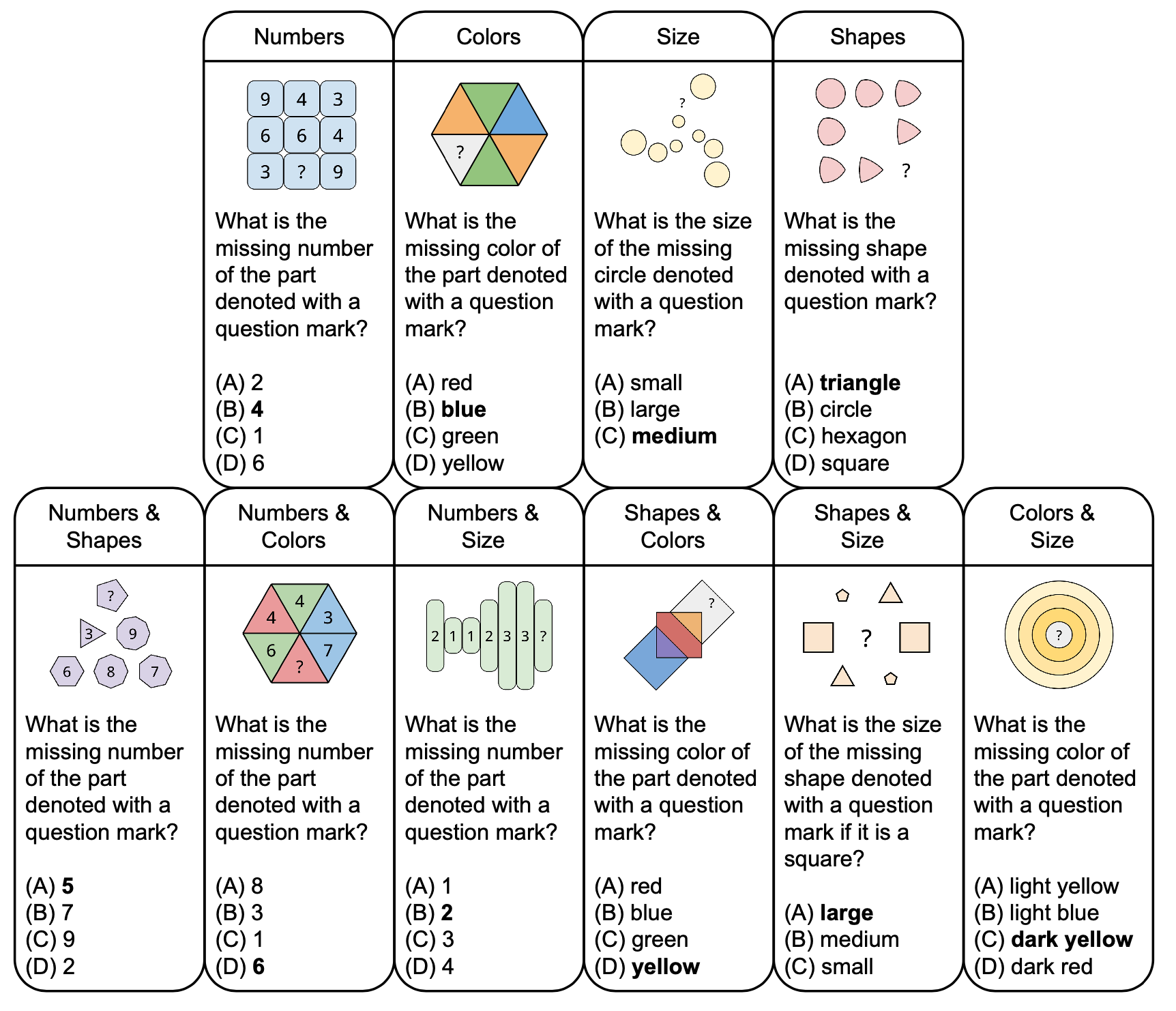
يوضح الشكل أدناه تصنيف الألغاز المجردة في PuzzleVQA مع نماذج الأسئلة، بناءً على المفاهيم الأساسية مثل الألوان والحجم. لتعزيز التنوع، نقوم بتصميم ألغاز ذات مفهوم واحد وألغاز ذات مفهوم مزدوج.
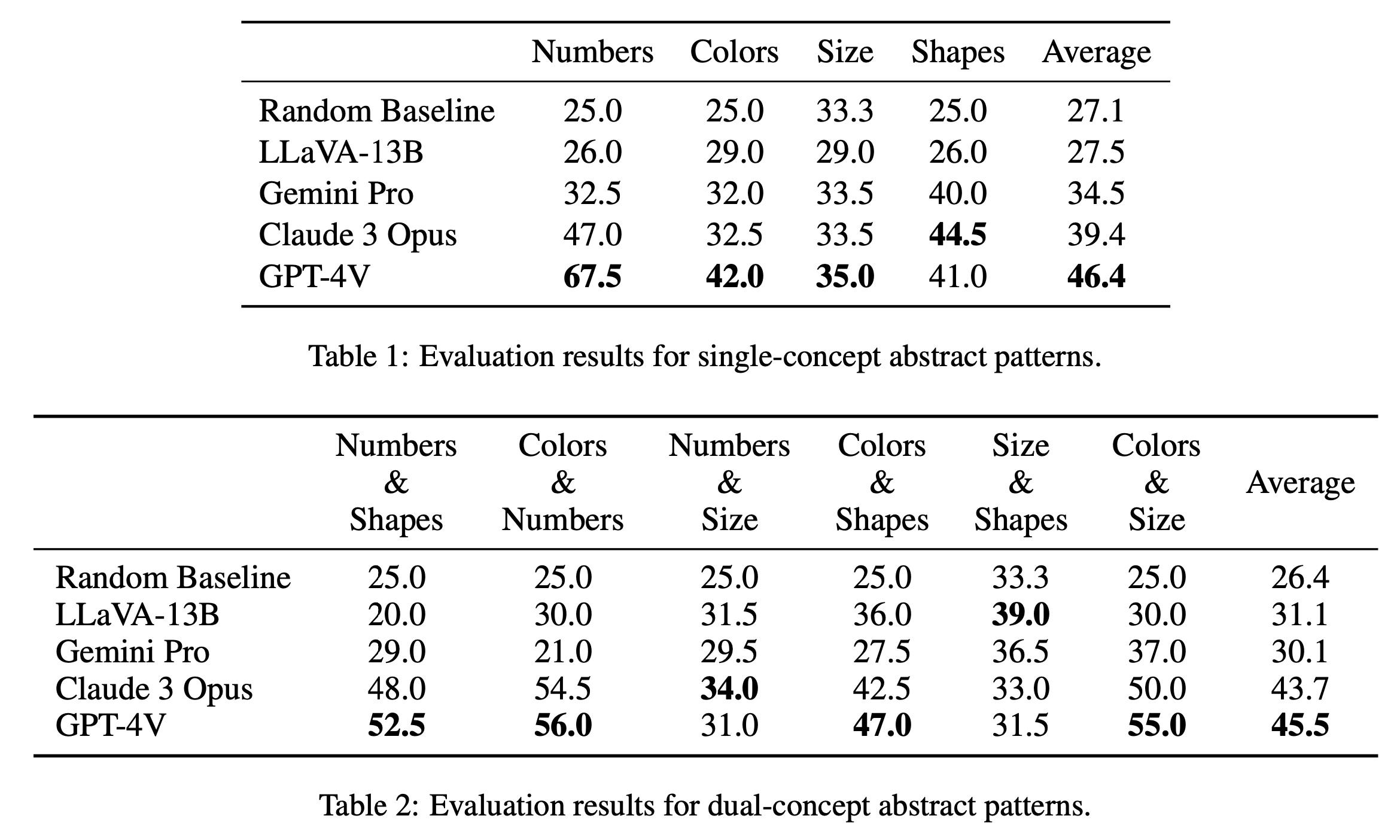
نقوم بالإبلاغ عن نتائج التقييم الرئيسية للألغاز ذات المفهوم الفردي والمفهوم المزدوج في الجدول 1 والجدول 2 على التوالي. تكشف نتائج التقييم للألغاز ذات المفهوم الواحد، كما هو موضح في الجدول 1، اختلافات ملحوظة في الأداء بين النماذج مفتوحة المصدر ومغلقة المصدر. يتميز GPT-4V بأعلى متوسط درجات يبلغ 46.4، مما يدل على تفكير نمطي تجريدي متفوق في الألغاز ذات المفهوم الواحد مثل الأرقام والألوان والحجم. وهو يتفوق بشكل خاص في فئة "الأرقام" بدرجة 67.5، متفوقًا بكثير على النماذج الأخرى، وهو ما قد يكون بسبب ميزته في مهام الاستدلال الرياضي (Yang et al., 2023). يتبع Claude 3 Opus بمتوسط إجمالي قدره 39.4، مما يظهر قوته في فئة "الأشكال" بأعلى درجة تبلغ 44.5. النماذج الأخرى، بما في ذلك Gemini Pro وLLaVA-13B، تتأخر بمتوسطات 34.5 و27.5 على التوالي، وتؤدي أداءً مشابهًا لخط الأساس العشوائي في عدة فئات.
في تقييم الألغاز ذات المفهوم المزدوج، كما هو موضح في الجدول 2، تبرز GPT-4V مرة أخرى بأعلى متوسط درجات يبلغ 45.5. لقد كان أداؤها جيدًا بشكل خاص في فئات مثل "الألوان والأرقام" و"الألوان والحجم" بنتيجة 56.0 و55.0 على التوالي. يليه Claude 3 Opus بمتوسط 43.7، ويظهر أداءً قويًا في "الأرقام والحجم" بأعلى درجة 34.0. ومن المثير للاهتمام، أن LLaVA-13B، على الرغم من انخفاض متوسطه الإجمالي البالغ 31.1، يسجل أعلى مستوى في فئة "الحجم والأشكال" عند 39.0. من ناحية أخرى، يتمتع Gemini Pro بأداء أكثر توازناً عبر الفئات ولكن بمتوسط إجمالي أقل قليلاً يبلغ 30.1. بشكل عام، نجد أن النماذج تؤدي أداءً متماثلًا في المتوسط بالنسبة لأنماط المفهوم الفردي والمفهوم المزدوج، مما يشير إلى أنها قادرة على ربط مفاهيم متعددة مثل الألوان والأرقام معًا.
@misc{chia2024puzzlevqa,
title={PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns},
author={Yew Ken Chia and Vernon Toh Yan Han and Deepanway Ghosal and Lidong Bing and Soujanya Poria},
year={2024},
eprint={2403.13315},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
نحن نقدم المهمة الجديدة المتمثلة في حل الألغاز متعددة الوسائط، ضمن سياق الإجابة على الأسئلة المرئية. نقدم مجموعة بيانات جديدة، AlgoPuzzleVQA مصممة لتحدي وتقييم قدرات نماذج اللغة متعددة الوسائط في حل الألغاز الخوارزمية التي تتطلب الفهم البصري وفهم اللغة والتفكير الخوارزمي المعقد. نقوم بإنشاء الألغاز لتشمل مجموعة متنوعة من المواضيع الرياضية والخوارزمية مثل المنطق المنطقي، والتوافقيات، ونظرية الرسم البياني، والتحسين، والبحث، وما إلى ذلك، بهدف تقييم الفجوة بين تفسير البيانات المرئية ومهارات حل المشكلات الخوارزمية. يتم إنشاء مجموعة البيانات تلقائيًا من التعليمات البرمجية التي كتبها البشر. تحتوي جميع الألغاز لدينا على حلول دقيقة يمكن العثور عليها من خلال الخوارزمية دون إجراء حسابات بشرية مملة. إنه يضمن إمكانية توسيع نطاق مجموعة البيانات الخاصة بنا بشكل تعسفي من حيث التعقيد المنطقي وحجم مجموعة البيانات. يكشف تحقيقنا أن نماذج اللغات الكبيرة (LLMs) مثل GPT4V وGemini تظهر أداءً محدودًا في مهام حل الألغاز. نجد أن أدائهم يكون شبه عشوائي في إعداد الإجابة على الأسئلة متعددة الاختيارات لعدد كبير من الألغاز. تؤكد النتائج على تحديات دمج المعرفة البصرية واللغوية والخوارزمية لحل مشاكل التفكير المعقدة.
يتوفر PuzzleVQA هنا وأيضًا على Huggingface.
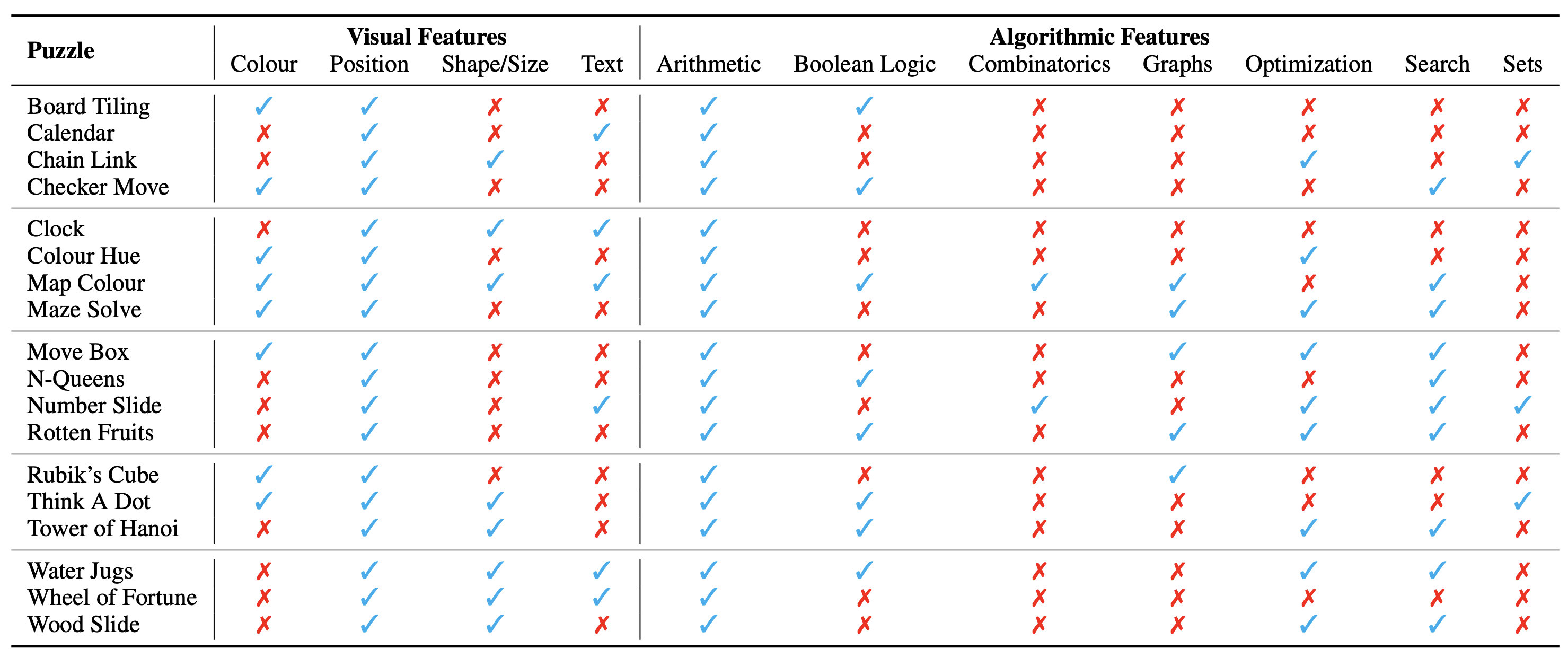
يتم عرض تكوين اللغز/المشكلة كصورة تشكل سياقها البصري. نحدد الجوانب الأساسية التالية للسياق البصري الذي يؤثر على طبيعة الألغاز:

نحدد أيضًا المفاهيم الخوارزمية المطلوبة لحل الألغاز، أي للإجابة على الأسئلة الخاصة بحالات اللغز. وهم على النحو التالي:

الفئات الخوارزمية ليست حصرية، حيث نحتاج إلى استخدام فئتين أو أكثر لاستخلاص الإجابة لمعظم الألغاز.
مجموعة البيانات متاحة هنا بهذا التنسيق. لقد أنشأنا ما مجموعه 18 ألغازًا مختلفة تغطي موضوعات خوارزمية ورياضية مختلفة. تحظى العديد من هذه الألغاز بشعبية في مختلف البيئات الترفيهية أو الأكاديمية.
في المجمل، لدينا 1800 حالة من 18 لغزًا مختلفًا. تشبه هذه الحالات حالات اختبار مختلفة للغز، أي أنها تحتوي على مجموعات إدخال مختلفة، وحالات أولية وحالة هدف، وما إلى ذلك. ويتطلب حل جميع الحالات بشكل موثوق العثور على الخوارزمية الدقيقة لاستخدامها ثم تطبيقها بدقة. وهذا يشبه كيفية التحقق من دقة برنامج كمبيوتر يهدف إلى حل مهمة معينة من خلال مجموعة واسعة من حالات الاختبار.
نحن نعتبر حاليًا مجموعة البيانات الكاملة كمعيار للتقييم فقط . يتم عرض الأمثلة التفصيلية لجميع الألغاز هنا.
يمكن العثور على تعليمات إنشاء مجموعة البيانات هنا. يمكن تحجيم عدد الحالات وصعوبة الألغاز بشكل تعسفي إلى أي حجم أو مستوى مرغوب.
التصنيف الوجودي للألغاز هو كما يلي:
يمكن العثور على الإعداد التجريبي والبرامج النصية في دليل AlgoPuzzleVQA.
يرجى النظر في الاستشهاد بالمقالة التالية إذا وجدت عملنا مفيدًا:
@article { ghosal2024algopuzzlevqa ,
title = { Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning } ,
author = { Ghosal, Deepanway and Han, Vernon Toh Yan and Chia, Yew Ken and and Poria, Soujanya } ,
journal = { arXiv preprint arXiv:2403.03864 } ,
year = { 2024 }
}

