DiagGPT
1.0.0
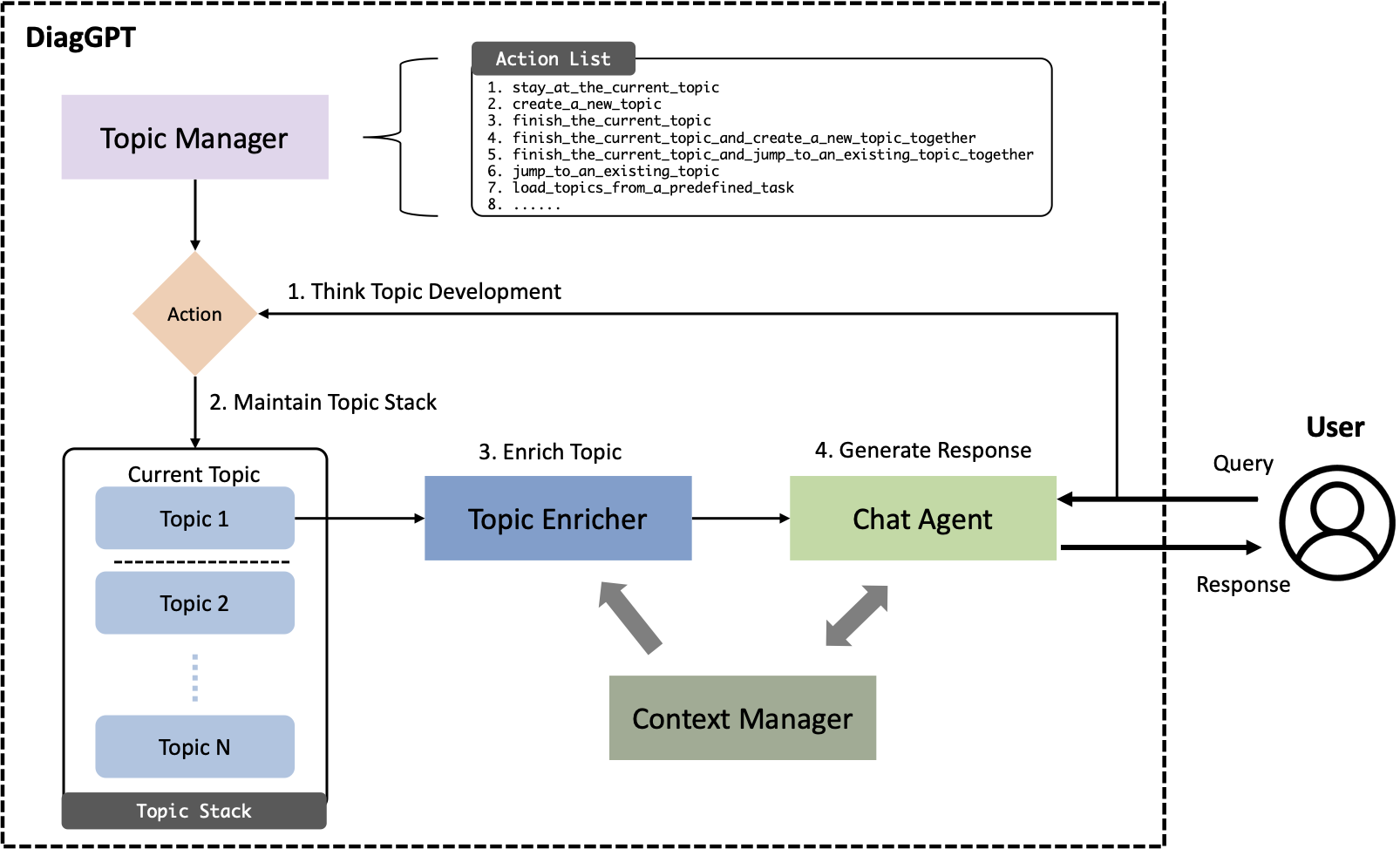
أحد التطبيقات المهمة لنماذج اللغات الكبيرة (LLMs)، مثل ChatGPT، هو نشرها كوكلاء دردشة، يستجيبون للاستفسارات البشرية عبر مجموعة متنوعة من المجالات. في حين أن حاملي شهادة الماجستير في القانون الحاليين يجيبون على الأسئلة العامة بكفاءة، إلا أنهم غالبًا ما يقصرون في سيناريوهات التشخيص المعقدة مثل الاستشارات القانونية أو الطبية أو غيرها من الاستشارات المتخصصة. تتطلب هذه السيناريوهات عادةً حوارًا موجهًا نحو المهام (TOD)، حيث يجب على وكيل الدردشة المدعم بالذكاء الاصطناعي طرح الأسئلة بشكل استباقي وتوجيه المستخدمين نحو أهداف محددة أو إكمال المهام. لقد كان أداء نماذج الضبط الدقيق السابقة ضعيفًا في TOD ولم يتم بعد استكشاف الإمكانات الكاملة لقدرة المحادثة في LLMs الحالية بشكل كامل. في هذه الورقة، نقدم DiagGPT (الحوار في تشخيص GPT)، وهو نهج مبتكر يوسع LLMs إلى المزيد من سيناريوهات TOD. بالإضافة إلى توجيه المستخدمين لإكمال المهام، يستطيع DiagGPT إدارة حالة جميع المواضيع بشكل فعال طوال عملية تطوير الحوار. تعمل هذه الميزة على تحسين تجربة المستخدم وتوفر تفاعلًا أكثر مرونة في TOD. تُظهر تجاربنا أن DiagGPT يُظهر أداءً متميزًا في إجراء TOD مع المستخدمين، مما يُظهر إمكاناته للتطبيقات العملية في مختلف المجالات.
نقوم ببناء مجموعة بيانات جديدة، LLM-TOD (حوار موجه نحو المهام لمجموعة بيانات نماذج اللغة الكبيرة). يتم استخدامه لتقييم أداء نماذج الحوار الموجهة نحو المهام القائمة على LLM من الناحية الكمية. تشتمل مجموعة البيانات على 20 بيانات، يمثل كل منها موضوعًا مختلفًا: سريري، مطعم، فندق، مستشفى، قطار، شرطة، حافلة، منطقة جذب، مطار، بار، مكتبة، متحف، متنزه، صالة ألعاب رياضية، سينما، مكتب، صالون حلاقة، مخبز، حديقة حيوانات، والبنك.
.
├── chatgpt # implementation of base chatgpt
├── data
│ └── LLM-TOD # LLM-TOD dataset
├── demo.py # DiagGPT for demo test
├── diaggpt # simple version of DiagGPT for quantitative experiments
├── diaggpt_medical # full version of DiagGPT in the medical consulting scenario
│ ├── embedding # file store, retrieval, etc.
│ ├── main.py # main code of implementation
│ ├── prompts # all prompts in DiagGPT
│ ...
├── evalgpt # implementation of GPT evaluation
├── exp.py # code of quantitative experiments
├── exp_output # experiment results
├── openai_api_key.txt # openai key
├── requirements.txt # dependencies
├── usergpt # simulation of the user for quantitative experiments
...pip install -r requirements.txttouch openai_api_key.txt # put your openai api key in it
python demo.py # demo test
python exp.py # run quantitative experimentsفيما يلي عرض توضيحي بسيط للغاية لعملية الدردشة الخاصة ببرنامج الدردشة الآلية في سيناريو التشخيص الطبي. قمنا بمحاكاة عملية زيارة المريض للطبيب. (يتم إنشاء بعض مدخلات المريض/المستخدم بواسطة GPT-4.)
في هذه العملية، يقوم الطبيب باستمرار بجمع المعلومات من المرضى وتحليلها خطوة بخطوة
في الوقت الحاضر، الوظائف الحالية للمشروع أولية للغاية. إنها مجرد نسخة توضيحية لإظهار قدرة LLMs على إدارة المواضيع، والتي لا يمكنها تلبية احتياجات الاستشارة المهنية الفعلية.
الهدف الأساسي من هذه التجربة هو إظهار إمكانات GPT-4، ومع ذلك، من المهم ملاحظة أن هذا ليس تطبيقًا أو منتجًا مصقولًا بالكامل، ولكنه بالأحرى مشروع تجريبي. من المحتمل ألا يؤدي GPT-4 الأداء الأمثل في سيناريوهات الأعمال المعقدة في العالم الحقيقي. نحن نشجعك على تحسينه وتطبيقه في سيناريوهات مختلفة، وسنكون سعداء لسماع نتائجك!
إذا وجدت هذا الريبو مفيدًا، فيرجى الاستشهاد بالمقالة التالية:
@misc{cao2023diaggpt,
title={DiagGPT: An LLM-based and Multi-agent Dialogue System with Automatic Topic Management for Flexible Task-Oriented Dialogue},
author={Lang Cao},
year={2023},
eprint={2308.08043},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


