llm data annotation
1.0.0
يجمع هذا الإطار بين الخبرة البشرية وكفاءة نماذج اللغات الكبيرة (LLMs) مثل OpenAI's GPT-3.5 لتبسيط التعليقات التوضيحية لمجموعة البيانات وتحسين النموذج. ويضمن النهج التكراري التحسين المستمر لجودة البيانات، وبالتالي تحسين أداء النماذج باستخدام هذه البيانات. وهذا لا يوفر الوقت فحسب، بل يمكّن أيضًا من إنشاء دورات LLM مخصصة تستفيد من كل من المفسرين البشريين والدقة المستندة إلى LLM.
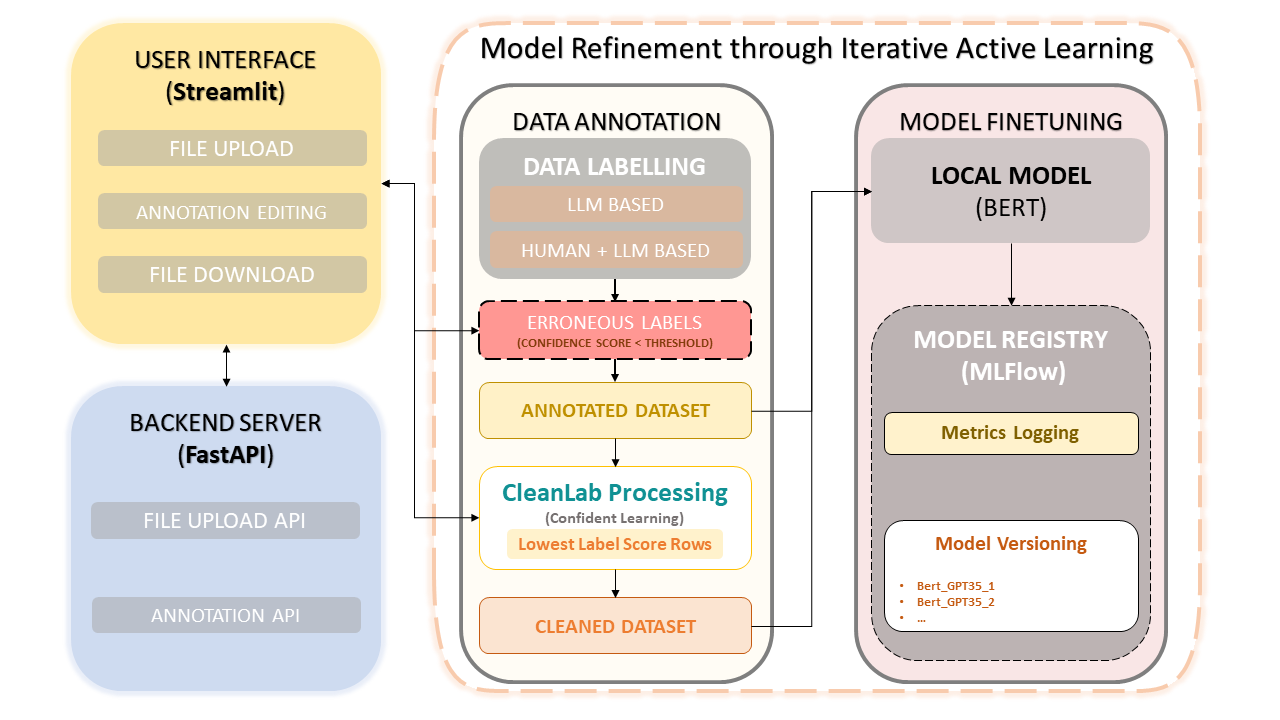
تحميل مجموعة البيانات والتعليق التوضيحي
تصحيحات التعليقات التوضيحية اليدوية
CleanLab: نهج التعلم الواثق
إصدار البيانات وحفظها
التدريب النموذجي
pip install -r requirements.txtابدأ الواجهة الخلفية لـ FastAPI :
uvicorn app:app --reloadقم بتشغيل تطبيق Streamlit :
streamlit run frontend.pyتشغيل واجهة مستخدم MLflow : لعرض النماذج والمقاييس والنماذج المسجلة، يمكنك الوصول إلى واجهة مستخدم MLflow باستخدام الأمر التالي:
mlflow uiالوصول إلى الروابط المتوفرة في متصفح الويب الخاص بك :
http://127.0.0.1:5000 .اتبع المطالبات التي تظهر على الشاشة لتحميل مجموعة البيانات الخاصة بك والتعليق عليها وتصحيحها والتدريب عليها.
لقد ظهر التعلم الواثق كأسلوب رائد في التعلم الخاضع للإشراف والإشراف الضعيف. ويهدف إلى توصيف ضوضاء الملصقات، والعثور على أخطاء الملصقات، والتعلم بكفاءة باستخدام الملصقات المزعجة. من خلال تقليم البيانات المزعجة وتصنيف الأمثلة للتدريب بثقة، تضمن هذه الطريقة مجموعة بيانات نظيفة وموثوقة، مما يعزز الأداء العام للنموذج.
هذا المشروع مفتوح المصدر بموجب ترخيص MIT.


