lightllm
1.0.0
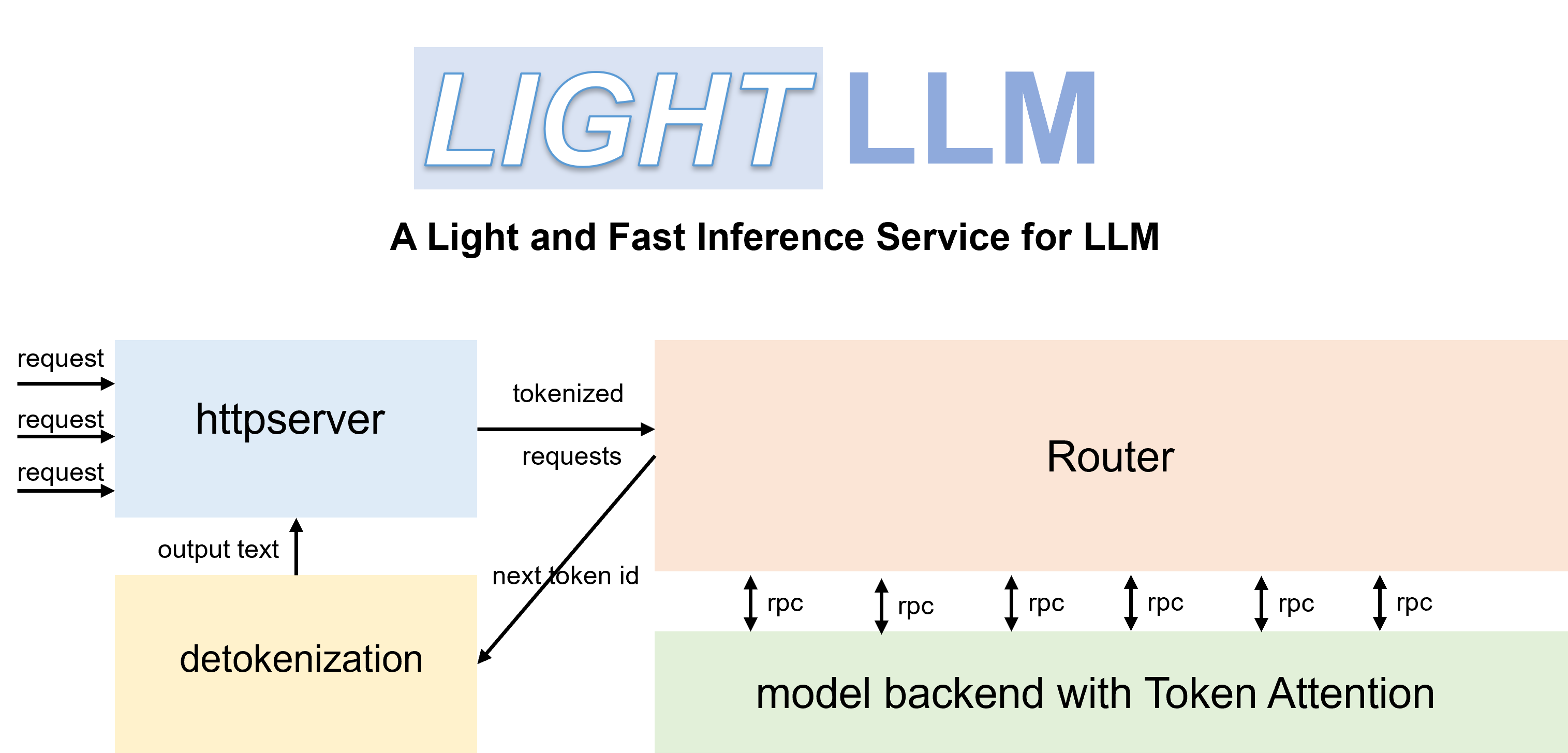
LightLLM عبارة عن إطار استدلال وخدمة LLM (نموذج لغة كبير) قائم على Python، ويتميز بتصميمه خفيف الوزن وقابلية التوسع السهلة والأداء عالي السرعة. يستخدم LightLLM نقاط القوة في العديد من التطبيقات مفتوحة المصدر المشهورة، بما في ذلك على سبيل المثال لا الحصر FasterTransformer وTGI وvLLM وFlashAttention.
مستندات انجليزية | 中文文档
عند بدء تشغيل Qwen-7b، تحتاج إلى تعيين المعلمة "--eos_id 151643 --trust_remote_code".
يحتاج ChatGLM2 إلى تعيين المعلمة "--trust_remote_code".
يحتاج InterLM إلى تعيين المعلمة "-trust_remote_code".
يحتاج InternVL-Chat(Phi3) إلى تعيين المعلمة "--eos_id 32007 --trust_remote_code".
يحتاج InternVL-Chat(InternLM2) إلى تعيين المعلمة "-eos_id 92542 --trust_remote_code".
يحتاج Qwen2-VL-7b إلى تعيين المعلمة "--eos_id 151645 --trust_remote_code"، واستخدام "pip install git+https://github.com/huggingface/transformers" للترقية إلى الإصدار الأحدث.
يحتاج Stablelm إلى تعيين المعلمة "-trust_remote_code".
يدعم Phi-3 الأجهزة الصغيرة والصغيرة فقط.
يحتاج DeepSeek-V2-Lite وDeepSeek-V2 إلى تعيين المعلمة "-data_type bfloat16"
تم اختبار الكود باستخدام Pytorch>=1.3 وCUDA 11.8 وPython 3.9. لتثبيت التبعيات الضرورية، يرجى الرجوع إلى ملف Requirements.txt المقدم واتباع التعليمات كما يلي
# for cuda 11.8
pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
# this version nccl can support torch cuda graph
pip install nvidia-nccl-cu12==2.20.5يمكنك استخدام حاوية Docker الرسمية لتشغيل النموذج بسهولة أكبر. للقيام بذلك، اتبع الخطوات التالية:
اسحب الحاوية من سجل حاوية GitHub:
docker pull ghcr.io/modeltc/lightllm:mainقم بتشغيل الحاوية بدعم GPU وتعيين المنافذ:
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
ghcr.io/modeltc/lightllm:main /bin/bashوبدلاً من ذلك، يمكنك بناء الحاوية بنفسك:
docker build -t < image_name > .
docker run -it --gpus all -p 8080:8080
--shm-size 1g -v your_local_path:/data/
< image_name > /bin/bashيمكنك أيضًا استخدام برنامج نصي مساعد لتشغيل كل من الحاوية والخادم:
python tools/quick_launch_docker.py --help ملاحظة: إذا كنت تستخدم وحدات معالجة رسومات متعددة، فقد تحتاج إلى زيادة حجم الذاكرة المشتركة عن طريق إضافة --shm-size إلى أمر docker run .
python setup.py installتم اختبار الكود على مجموعة من وحدات معالجة الرسومات بما في ذلك V100 وA100 وA800 و4090 وH800. إذا كنت تقوم بتشغيل الكود على A100، A800، وما إلى ذلك، فإننا نوصي باستخدام triton==3.0.0.
pip install triton==3.0.0 --no-depsإذا كنت تقوم بتشغيل الكود على H800 أو V100، فيمكنك تجربة triton-nightly للحصول على أداء أفضل.
pip install -U --index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/Triton-Nightly/pypi/simple/ triton-nightly --no-depsباستخدام أجهزة التوجيه الفعالة وTokenAttention، يمكن نشر LightLLM كخدمة وتحقيق أداء إنتاجي متطور.
إطلاق الخادم:
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 120000 تتأثر المعلمة max_total_token_num بذاكرة GPU الخاصة ببيئة النشر. يمكنك أيضًا تحديد --mem_faction ليتم حسابه تلقائيًا.
python -m lightllm.server.api_server --model_dir /path/llama-7B
--host 0.0.0.0
--port 8080
--tp 1
--mem_faction 0.9لبدء استعلام في الصدفة:
curl http://127.0.0.1:8080/generate
-X POST
-d ' {"inputs":"What is AI?","parameters":{"max_new_tokens":17, "frequency_penalty":1}} '
-H ' Content-Type: application/json 'للاستعلام من بايثون:
import time
import requests
import json
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
data = {
'inputs' : 'What is AI?' ,
"parameters" : {
'do_sample' : False ,
'ignore_eos' : False ,
'max_new_tokens' : 1024 ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )python -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/Qwen-VL or /path/of/Qwen-VL-Chatpython -m lightllm.server.api_server
--host 0.0.0.0
--port 8080
--tp 1
--max_total_token_num 12000
--trust_remote_code
--enable_multimodal
--cache_capacity 1000
--model_dir /path/of/llava-v1.5-7b or /path/of/llava-v1.5-13b import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "<img></img>Generate the caption in English with grounding:" ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text ) import json
import requests
import base64
def run_once ( query , uris ):
images = []
for uri in uris :
if uri . startswith ( "http" ):
images . append ({ "type" : "url" , "data" : uri })
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images . append ({ 'type' : "base64" , "data" : b64 })
data = {
"inputs" : query ,
"parameters" : {
"max_new_tokens" : 200 ,
# The space before <|endoftext|> is important, the server will remove the first bos_token_id, but QWen tokenizer does not has bos_token_id
"stop_sequences" : [ " <|endoftext|>" , " <|im_start|>" , " <|im_end|>" ],
},
"multimodal_params" : {
"images" : images ,
}
}
# url = "http://127.0.0.1:8080/generate_stream"
url = "http://127.0.0.1:8080/generate"
headers = { 'Content-Type' : 'application/json' }
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( " + result: ({})" . format ( response . json ()))
else :
print ( ' + error: {}, {}' . format ( response . status_code , response . text ))
"""
multi-img, multi-round:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
<img></img>
<img></img>
上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|>
<|im_start|>assistant
根据提供的信息,两张图片分别是重庆和北京。<|im_end|>
<|im_start|>user
这两座城市分别在什么地方?<|im_end|>
<|im_start|>assistant
"""
run_once (
uris = [
"assets/mm_tutorial/Chongqing.jpeg" ,
"assets/mm_tutorial/Beijing.jpeg" ,
],
query = "<|im_start|>system n You are a helpful assistant.<|im_end|> n <|im_start|>user n <img></img> n <img></img> n上面两张图片分别是哪两个城市?请对它们进行对比。<|im_end|> n <|im_start|>assistant n根据提供的信息,两张图片分别是重庆和北京。<|im_end|> n <|im_start|>user n这两座城市分别在什么地方?<|im_end|> n <|im_start|>assistant n "
) import time
import requests
import json
import base64
url = 'http://localhost:8080/generate'
headers = { 'Content-Type' : 'application/json' }
uri = "/local/path/of/image" # or "/http/path/of/image"
if uri . startswith ( "http" ):
images = [{ "type" : "url" , "data" : uri }]
else :
with open ( uri , 'rb' ) as fin :
b64 = base64 . b64encode ( fin . read ()). decode ( "utf-8" )
images = [{ 'type' : "base64" , "data" : b64 }]
data = {
"inputs" : "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions. USER: <image> n Please explain the picture. ASSISTANT:" ,
"parameters" : {
"max_new_tokens" : 200 ,
},
"multimodal_params" : {
"images" : images ,
}
}
response = requests . post ( url , headers = headers , data = json . dumps ( data ))
if response . status_code == 200 :
print ( response . json ())
else :
print ( 'Error:' , response . status_code , response . text )معلمات lanuch الإضافية:
--enable_multimodal،--cache_capacity، أكبر--cache_capacityيتطلبshm-sizeأكبر
الدعم
--tp > 1، عندما يكونtp > 1، يتم تشغيل النموذج المرئي على وحدة معالجة الرسومات 0
علامة الصورة الخاصة لـ Qwen-VL هي
<img></img>(<image>for Lava)، يجب أن يكون طولdata["multimodal_params"]["images"]هو نفس عدد العلامات، العدد يمكن أن يكون 0، 1، 2، ...
تنسيق صور الإدخال: قائمة للإملاء مثل
{'type': 'url'/'base64', 'data': xxx}
قمنا بمقارنة أداء خدمة LightLLM وvLLM==0.1.2 على LLaMA-7B باستخدام A800 مع ذاكرة GPU 80G.
للبدء، قم بإعداد البيانات على النحو التالي:
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.jsonإطلاق الخدمة:
python -m lightllm.server.api_server --model_dir /path/llama-7b --tp 1 --max_total_token_num 121060 --tokenizer_mode autoتقييم:
cd test
python benchmark_serving.py --tokenizer /path/llama-7b --dataset /path/ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 2000 --request-rate 200نتائج مقارنة الأداء معروضة أدناه:
| vLLM | LightLLM |
|---|---|
| الوقت الإجمالي: 361.79 ثانية الإنتاجية: 5.53 طلب/ثانية | الوقت الإجمالي: 188.85 ثانية الإنتاجية: 10.59 طلب/ثانية |
لتصحيح الأخطاء، نقدم نصوصًا برمجية لاختبار الأداء الثابت لنماذج مختلفة. على سبيل المثال، يمكنك تقييم أداء الاستدلال لنموذج LLaMA من خلال
cd test/model
python test_llama.pypip install protobuf==3.20.0 .error : PTX .version 7.4 does not support .target sm_89bash tools/resolve_ptx_version python -m lightllm.server.api_server ... إذا كان لديك مشروع ينبغي دمجه، يرجى الاتصال عبر البريد الإلكتروني أو إنشاء طلب سحب.
بمجرد تثبيت lightllm و lazyllm ، يمكنك بعد ذلك استخدام الكود التالي لإنشاء برنامج الدردشة الآلي الخاص بك:
from lazyllm import TrainableModule , deploy , WebModule
# Model will be download automatically if you have an internet connection
m = TrainableModule ( 'internlm2-chat-7b' ). deploy_method ( deploy . lightllm )
WebModule ( m ). start (). wait ()المستندات: https://lazyllm.readthedocs.io/
لمزيد من المعلومات والمناقشة، انضم إلى خادم الديسكورد الخاص بنا.
تم إصدار هذا المستودع بموجب ترخيص Apache-2.0.
لقد تعلمنا الكثير من المشاريع التالية عند تطوير LightLLM.


