RWKV LM
v5
صفحة RWKV الرئيسية: https://www.rwkv.com
ورقة RWKV-5/6 إيجل/فينش : https://arxiv.org/abs/2404.05892
RWKV رائع في الرؤية: https://github.com/Yaziwel/Awesome-RWKV-in-Vision
عرض RWKV-6 3B التجريبي: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-1
عرض RWKV-6 7B: https://huggingface.co/spaces/BlinkDL/RWKV-Gradio-2
الكود التجريبي لوضع RWKV-6 GPT (مع التعليقات والشروحات) : https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/rwkv_v6_demo.py
العرض التوضيحي لوضع RWKV-6 RNN: https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
كمرجع، استخدم python 3.10+، torch 2.5+، cuda 12.5+، أحدث سرعة عميقة، لكن احتفظ بـ pytorch-lightning==1.9.5
تدريب RWKV-6 : استخدم /RWKV-v5/ واستخدم --my_testing "x060" في demo-training-prepare.sh وdemo-training-run.sh
تدريب RWKV-7 : استخدم /RWKV-v5/ واستخدم --my_testing "x070" في demo-training-prepare.sh وdemo-training-run.sh
pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu121
pip install pytorch-lightning==1.9.5 deepspeed wandb ninja --upgrade
cd RWKV-v5/
./demo-training-prepare.sh
./demo-training-run.sh
(you may want to log in to wandb first)
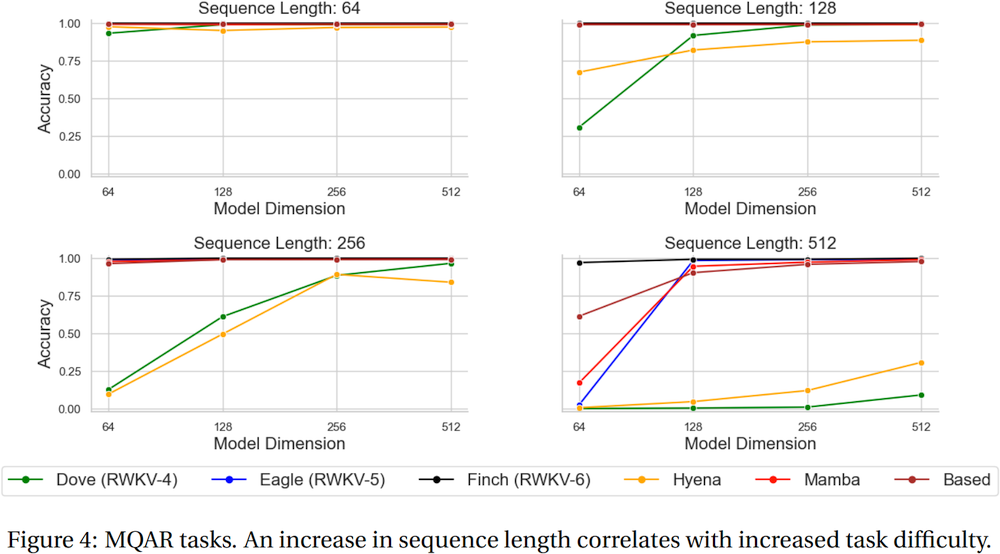
يجب أن يبدو منحنى الخسارة الخاص بك متماثلًا تمامًا مع هذا، مع نفس الصعود والهبوط (إذا كنت تستخدم نفس bsz & config):
يمكنك تشغيل النموذج الخاص بك باستخدام https://pypi.org/project/rwkv/ (استخدم "rwkv_vocab_v20230424" بدلاً من "20B_tokenizer.json")
استخدم https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py لإعداد بيانات binidx من jsonl، وحساب "--my_exit_tokens" و"--magic_prime".
رمز مميز أسرع بكثير للبيانات الكبيرة: https://github.com/cahya-wirawan/json2bin
"العصر" في Train.py هو "عصر صغير" (ليس عصرًا حقيقيًا. فقط من أجل الراحة)، و1 عصر صغير = 40320 * رموز ctx_len.
على سبيل المثال، إذا كان binidx الخاص بك يحتوي على 1498226207 من الرموز المميزة وctxlen=4096، فاضبط "--my_exit_tokens 1498226207" (سيتجاوز هذا عدد Epoch_count)، وسيكون 1498226207/(40320 * 4096) = 9.07 miniepochs. سيخرج المدرب تلقائيًا بعد الرموز المميزة "-my_exit_tokens". اضبط "--magic_prime" على أكبر عدد أولي 3n+2 أصغر من datalen/ctxlen-1 (= 1498226207/4096-1 = 365776)، وهو "-magic_prime 365759" في هذه الحالة.
بسيطة: قم بإعداد SFT jsonl => كرر بيانات SFT الخاصة بك 3 أو 4 مرات في make_data.py. المزيد من التكرار يؤدي إلى الإفراط في التجهيز.
متقدم: كرر بيانات SFT 3 أو 4 مرات في jsonl الخاص بك (لاحظ أن make_data.py سيعمل على تبديل جميع عناصر jsonl) => أضف بعض البيانات الأساسية (مثل Slimpajama) إلى jsonl => وكرر مرة واحدة فقط في make_data.py.
إصلاح مسامير التدريب : راجع الجزء "إصلاح مسامير RWKV-6" في هذه الصفحة.
استنتاج بسيط لـ RWKV-5 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
استنتاج بسيط لـ RWKV-6 : https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
ملاحظة: في [state = kv + w *state] يجب أن يكون كل شيء في fp32 لأن w يمكن أن يكون قريبًا جدًا من 1. لذلك يمكننا الاحتفاظ بالحالة وw في fp32، وتحويل kv إلى fp32.
lm_eval: https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py
عرض الدردشة للمطورين: https://github.com/BlinkDL/ChatRWKV/blob/main/API_DEMO_CHAT.py
نصائح للنموذج الصغير/البيانات الصغيرة : عندما أقوم بتدريب نماذج الموسيقى RWKV، أستخدم الأبعاد العميقة والضيقة (مثل L29-D512)، وأطبق wd والتسرب (مثل wd=2 dropout=0.02). لاحظ أن التسرب من RWKV-LM فعال للغاية - استخدم 1/4 من القيمة المعتادة.
استخدم تنسيق .jsonl لبياناتك (راجع https://huggingface.co/BlinkDL/rwkv-5-world لمعرفة التنسيقات).
استخدم https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v5/make_data.py لترميزه باستخدام الرمز المميز العالمي في binidx، وهو مناسب لضبط النماذج العالمية.
أعد تسمية نقطة التحقق الأساسية في مجلد النموذج الخاص بك إلى rwkv-init.pth، وقم بتغيير أوامر التدريب لاستخدام --n_layer 32 --n_embd 4096 --vocab_size 65536 --lr_init 1e-5 --lr_final 1e-5 لـ 7B.
0.1B = --n_layer 12 --n_embd 768 // 0.4B = --n_layer 24 --n_embd 1024 // 1.5B = --n_layer 24 --n_embd 2048 // 3B = --n_layer 32 --n_embd 2560 / / 7ب = --n_layer 32 --n_embd 4096
التنفيذ غير المحسّن حاليًا، يأخذ نفس vram مثل SFT الكامل
--train_type "states" --load_partial 1 --lr_init 1 --lr_final 0.01 --warmup_steps 10 (yes, use very high LR)
استخدم rwkv 0.8.26+ للتحميل التلقائي لـ "time_state" المدربة
عندما تقوم بتدريب RWKV من البداية، حاول التهيئة للحصول على أفضل أداء. تحقق من generator_init_weight() الخاص بـ src/model.py:
emb.weight => nn.init.uniform_(a=-1e-4, b=1e-4)
(Note ln0 of block0 is the layernorm for emb.weight)
head.weight => nn.init.orthogonal_(gain=0.5*sqrt(n_vocab / n_embd))
att.receptance.weight => nn.init.orthogonal_(gain=1)
att.key.weight => nn.init.orthogonal_(gain=0.1)
att.value.weight => nn.init.orthogonal_(gain=1)
att.gate.weight => nn.init.orthogonal_(gain=0.1)
att.output.weight => zero
att.ln_x.weight (groupnorm) => ((1 + layer_id) / total_layers) ** 0.7
ffn.key.weight => nn.init.orthogonal_(gain=1)
ffn.value.weight => zero
ffn.receptance.weight => zero
!!! إذا كنت تستخدم التضمين الموضعي، فربما يكون من الأفضل إزالة block.0.ln0 واستخدام التهيئة الافتراضية لـ emb.weight بدلاً من الزي الرسمي_(a=-1e-4, b=1e-4) !!!
عند التدريب من البداية، أضف "k = k * torch.clamp(w, max=0).exp()" قبل "RUN_CUDA_RWKV6(r, k, v, w, u)"، وتذكر تغيير رمز الاستدلال الخاص بك أيضًا . سترى تقاربًا أسرع.
استخدم "--adam_eps 1e-18"
"--beta2 0.95" إذا رأيت ارتفاعات
في Trainer.py، قم بتنفيذ "lr = lr * (0.01 + 0.99 * Trainer.global_step / w_step)" (في الأصل 0.2 + 0.8)، و"--warmup_steps 20"
يؤدي "-weight_decay 0.1" إلى خسارة نهائية أفضل إذا كنت تقوم بتدريب الكثير من البيانات. اضبط lr_final على 1/100 من lr_init عند القيام بذلك.
RWKV عبارة عن RNN بأداء LLM على مستوى المحولات، والذي يمكن أيضًا تدريبه بشكل مباشر مثل محول GPT (قابل للتوازي). وهي خالية من الاهتمام بنسبة 100%. ما عليك سوى الحالة المخفية عند الموضع t لحساب الحالة عند الموضع t+1. يمكنك استخدام وضع "GPT" لحساب الحالة المخفية لوضع "RNN" بسرعة.
لذلك فهو يجمع بين أفضل ما في RNN والمحولات - الأداء الرائع، والاستدلال السريع، وحفظ VRAM، والتدريب السريع، وctx_len "اللانهائي"، وتضمين الجملة مجانًا (باستخدام الحالة المخفية النهائية).
واجهة المستخدم الرسومية لـ RWKV Runner https://github.com/josStorer/RWKV-Runner مع التثبيت بنقرة واحدة وواجهة برمجة التطبيقات (API)
جميع أوزان RWKV الأحدث: https://huggingface.co/BlinkDL
أوزان RWKV المتوافقة مع HF: https://huggingface.co/RWKV
حزمة نقاط RWKV : https://pypi.org/project/rwkv/
os . environ [ "RWKV_JIT_ON" ] = '1'
os . environ [ "RWKV_CUDA_ON" ] = '0' # if '1' then use CUDA kernel for seq mode (much faster)
from rwkv . model import RWKV # pip install rwkv
model = RWKV ( model = '/fsx/BlinkDL/HF-MODEL/rwkv-4-pile-1b5/RWKV-4-Pile-1B5-20220903-8040' , strategy = 'cuda fp16' )
out , state = model . forward ([ 187 , 510 , 1563 , 310 , 247 ], None ) # use 20B_tokenizer.json
print ( out . detach (). cpu (). numpy ()) # get logits
out , state = model . forward ([ 187 , 510 ], None )
out , state = model . forward ([ 1563 ], state ) # RNN has state (use deepcopy if you want to clone it)
out , state = model . forward ([ 310 , 247 ], state )
print ( out . detach (). cpu (). numpy ()) # same result as abovenanoRWKV : https://github.com/BlinkDL/nanoRWKV (لا يتطلب تدريب نواة CUDA، ويعمل مع أي وحدة معالجة رسومات/وحدة معالجة مركزية)
تويتر : https://twitter.com/BlinkDL_AI
الصفحة الرئيسية : https://www.rwkv.com
مشاريع RWKV المجتمعية الرائعة :
جميع مشاريع RWKV (+300): https://github.com/search?o=desc&q=rwkv&s=updated&type=Repositories
https://github.com/OpenGVLab/Vision-RWKV رؤية RWKV
https://github.com/feizc/Diffusion-RWKV نشر RWKV
https://github.com/cgisky1980/ai00_rwkv_server أسرع استنتاج WebGPU (nVidia/AMD/Intel)
https://github.com/cryscan/web-rwkv الواجهة الخلفية لـ ai00_rwkv_server
https://github.com/saharNooby/rwkv.cpp سريع CPU/cuBLAS/CLBlast الاستدلال: int4/int8/fp16/fp32
https://github.com/JL-er/RWKV-PEFT lora/pissa/Qlora/Qpissa/state ضبط
https://github.com/RWKV/RWKV-infctx-trainer مدرب Infctx
https://github.com/daquexian/faster-rwkv
mlc-ai/mlc-llm#1275
https://github.com/TheRamU/Fay/blob/main/README_EN.md المساعد الرقمي مع RWKV
https://github.com/harrisonvanderbyl/rwkv-cpp-cuda استنتاج سريع لوحدة معالجة الرسومات باستخدام cuda/amd/vulkan
RWKV v6 في 250 سطرًا (مع الرمز المميز أيضًا): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v6_demo.py
RWKV v5 في 250 سطرًا (مع الرمز المميز أيضًا): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_v5_demo.py
RWKV v4 في 150 سطرًا (النموذج والاستدلال وإنشاء النص): https://github.com/BlinkDL/ChatRWKV/blob/main/RWKV_in_150_lines.py
النسخة الأولية لـ RWKV v4 https://arxiv.org/abs/2305.13048
مقدمة RWKV v4 وفي 100 سطر من numpy : https://johanwind.github.io/2023/03/23/rwkv_overview.html https://johanwind.github.io/2023/03/23/rwkv_details.html
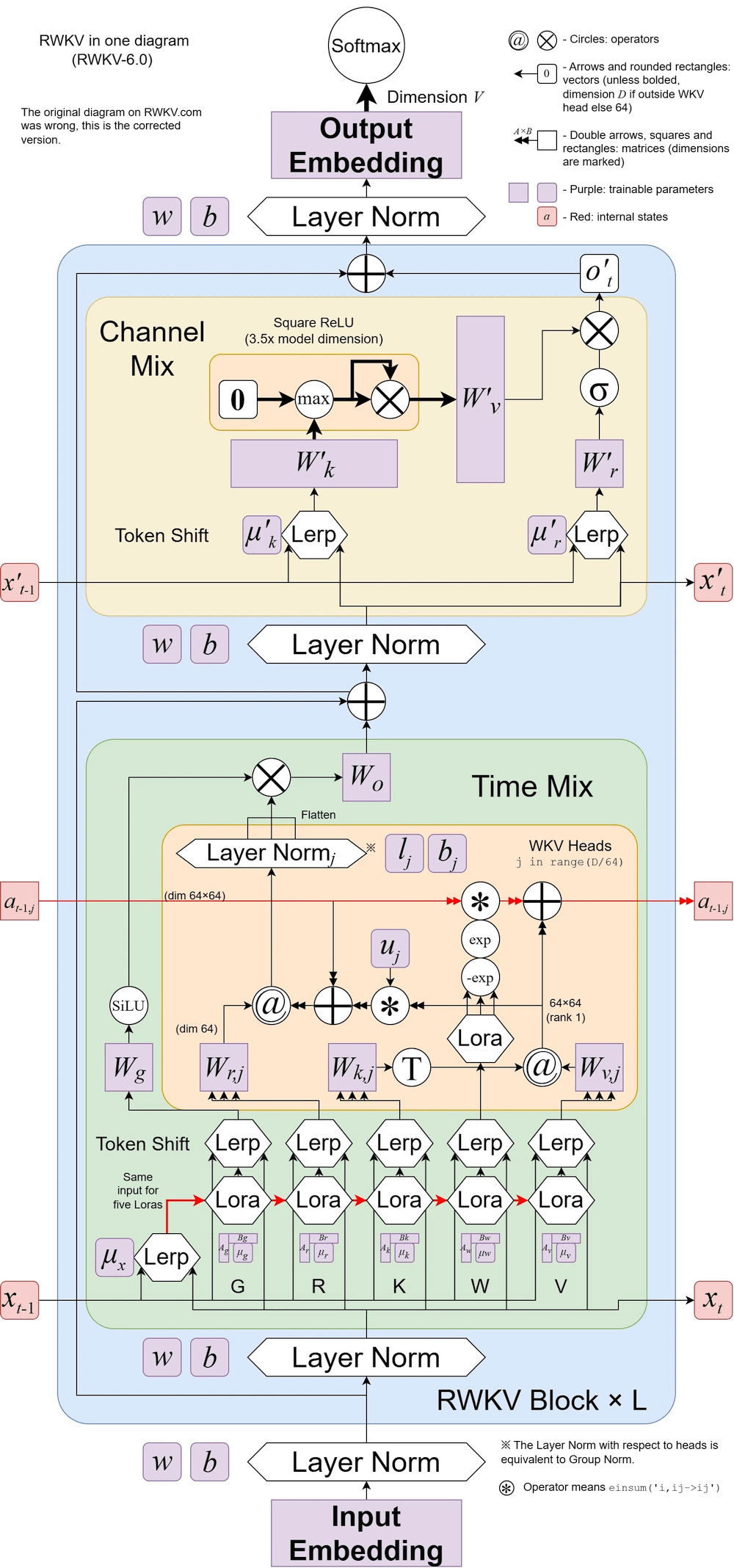
تم توضيح RWKV v6:
ورقة رائعة (Spiking Neural Network) باستخدام RWKV: https://github.com/ridgerchu/SpikeGPT
مرحبًا بك للانضمام إلى RWKV discord https://discord.gg/bDSBUMeFpc للبناء عليه. لدينا الآن الكثير من الحوسبة المحتملة (A100 40Gs) (بفضل Stability وEleutherAI)، لذلك إذا كانت لديك أفكار مثيرة للاهتمام فيمكنني تشغيلها.

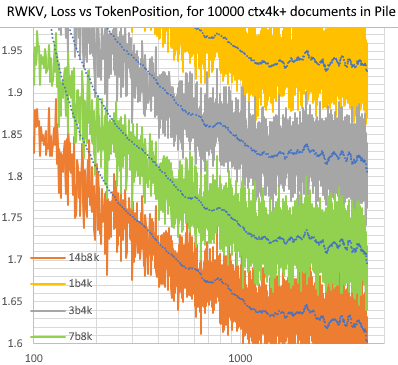
RWKV [الخسارة مقابل موضع الرمز المميز] لـ 10000 مستند ctx4k+ في Pile. يكون RWKV 1B5-4k مسطحًا في الغالب بعد ctx1500، لكن 3B-4k و7B-4k و14B-4k به بعض المنحدرات، وهم يتحسنون. هذا يفضح وجهة النظر القديمة القائلة بأن شبكات RNN لا يمكنها تصميم عدسات ctxlens الطويلة. يمكننا أن نتوقع أن RWKV 100B سيكون رائعًا، وربما يكون RWKV 1T هو كل ما تحتاجه :)
ChatRWKV مع RWKV 14B ctx8192:

أعتقد أن RNN هو المرشح الأفضل للنماذج الأساسية، لأنه: (1) إنه أكثر ملاءمة لـ ASICs (لا توجد ذاكرة تخزين مؤقت لـ kv). (2) إنه أكثر ملاءمة لـ RL. (3) عندما نكتب، يكون دماغنا أكثر شبهًا بـ RNN. (4) الكون يشبه شبكة RNN أيضًا (بسبب الموضع). المحولات نماذج غير محلية.
RWKV-3 1.5B على A40 (tf32) = دائمًا 0.015 ثانية/رمز مميز، تم اختباره باستخدام رمز pytorch البسيط (بدون CUDA)، واستخدام وحدة معالجة الرسومات 45%، وVRAM 7823M
GPT2-XL 1.3B على A40 (tf32) = 0.032 ثانية/رمز مميز (لـ ctxlen 1000)، تم اختباره باستخدام HF، واستخدام وحدة معالجة الرسومات 45% أيضًا (مثير للاهتمام)، VRAM 9655M
سرعة التدريب: (كود التدريب الجديد) RWKV-4 14B BF16 ctxlen4096 = 114 ألف رمز/ثانية على 8x8 A100 80G (ZERO2+CP). (رمز التدريب القديم) RWKV-4 1.5B BF16 ctxlen1024 = 106 ألف رمز/ثانية على 8xA100 40G.
أقوم بإجراء تجارب الصور أيضًا (على سبيل المثال: https://huggingface.co/BlinkDL/clip-guided-binary-autoencoder) وسيتمكن RWKV من إجراء نشر txt2img :) فكرتي: صورة 256x256 rgb -> 32x32x13bit الكامنة - > تطبيق RWKV لحساب احتمالية الانتقال لكل شبكة 32 × 32 -> تظاهر بأن الشبكات مستقلة و"منتشرة" باستخدام هذه الاحتمالات.
التدريب السلس - لا توجد طفرات الخسارة! (يتغير lr & bsz حول رموز 15G)
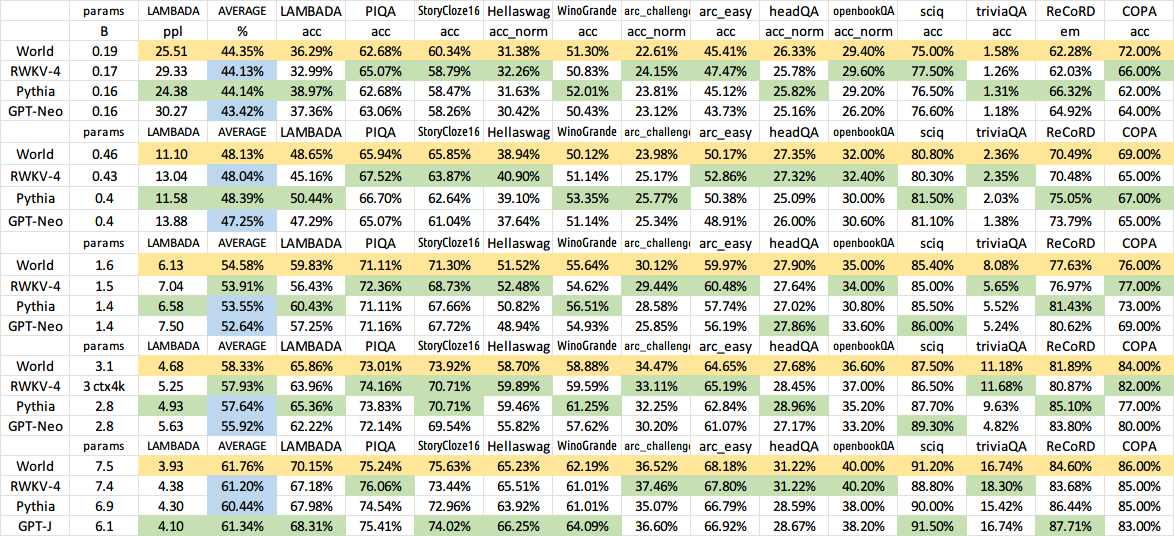
جميع النماذج المدربة ستكون مفتوحة المصدر. الاستدلال سريع جدًا (مضاعفات المصفوفة والمتجهات فقط، ولا توجد مضاعفات المصفوفة والمصفوفة) حتى على وحدات المعالجة المركزية (CPUs)، لذا يمكنك حتى تشغيل LLM على هاتفك.
كيف يعمل: يقوم RWKV بجمع المعلومات إلى عدد من القنوات، والتي تتحلل أيضًا بسرعات مختلفة أثناء انتقالك إلى الرمز المميز التالي. الأمر بسيط للغاية بمجرد أن تفهمه.
RWKV قابل للتوازي لأن الاضمحلال الزمني لكل قناة مستقل عن البيانات (وقابل للتدريب) . على سبيل المثال، في RNN المعتاد، يمكنك ضبط التناقص الزمني للقناة من 0.8 إلى 0.5 (وتسمى هذه "البوابات")، بينما في RWKV يمكنك ببساطة نقل المعلومات من قناة W-0.8 إلى قناة W-0.5 -channel لتحقيق نفس التأثير. علاوة على ذلك، يمكنك ضبط RWKV بشكل دقيق إلى RNN غير قابل للتوازي (ثم يمكنك استخدام مخرجات الطبقات اللاحقة من الرمز المميز السابق) إذا كنت تريد أداءً إضافيًا.

وهنا بعض من TODOs بلدي. دعونا نعمل معا :)
تكامل HuggingFace (تحقق من Huggingface/transformers#17230)، واستدلال محسّن لوحدة المعالجة المركزية (CPU) وiOS وAndroid وWASM وWebGL. RWKV هو RNN وسهل جدًا للأجهزة المتطورة. دعونا نجعل من الممكن تشغيل LLM على هاتفك.
اختبره على المهام ثنائية الاتجاه والامتيازات والرهون البحرية، ورموز الصور والصوت والفيديو. أعتقد أن RWKV يمكنه دعم Encoder-Decoder من خلال هذا: بالنسبة لكل رمز مميز لوحدة فك التشفير، استخدم مزيجًا مكتسبًا من [الحالة المخفية السابقة لوحدة فك التشفير] و[الحالة المخفية النهائية لجهاز التشفير]. ومن ثم سيكون لجميع الرموز المميزة لوحدة فك التشفير إمكانية الوصول إلى مخرجات التشفير.
الآن قم بتدريب RWKV-4a باهتمام إضافي واحد صغير (فقط بضعة أسطر إضافية مقارنة بـ RWKV-4) لتحسين بعض المهام الصعبة (مثل LAMBADA) للنماذج الأصغر حجمًا. راجع https://github.com/BlinkDL/RWKV-LM/commit/a268cd2e40351ee31c30c5f8a5d1266d35b41829
تعليقات المستخدم:
لقد قمت حتى الآن بالتلاعب بالنموذج القائم على الشخصية في مجموعة بياناتنا الصغيرة نسبيًا قبل التدريب (حوالي 10 جيجابايت من النص)، وكانت النتائج جيدة للغاية - أشخاص مشابهون للنماذج التي تستغرق وقتًا أطول بكثير للتدريب.
عزيزي الله rwkv سريع. لقد قمت بالتبديل إلى علامة تبويب أخرى بعد أن بدأت التدريب عليها من الصفر وعندما عدت كانت تنبعث منها كلمات إنجليزية وماوري معقولة، غادرت لأضع بعض القهوة في الميكروويف وعندما عدت كانت تنتج جملًا صحيحة نحويًا تمامًا.
تغريدة من سيب هوخريتر (شكرًا لك!): https://twitter.com/HochreiterSepp/status/1524270961314484227
يمكنك أن تجدني (BlinkDL) في EleutherAI Discord أيضًا: https://www.eleuther.ai/get-involved/
هام: استخدم Deepspeed==0.7.0 pytorch-lightning==1.9.5 torch==1.13.1+cu117 وcuda 11.7.1 أو 11.7 (لاحظ أن torch2 + Deepspeed به أخطاء غريبة ويضر بأداء النموذج)
استخدم https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v4neo (أحدث كود، متوافق مع الإصدار 4).
فيما يلي مطالبة رائعة لاختبار الأسئلة والأجوبة الخاصة بـ LLMs. يعمل مع أي طراز: (تم العثور عليه عن طريق تصغير ChatGPT ppls لـ RWKV 1.5B)
prompt = f' n Q & A n n Question: n { qq } n n Detailed Expert Answer: n ' # let the model generate after thisقم بتشغيل نماذج RWKV-4 Pile: قم بتنزيل النماذج من https://huggingface.co/BlinkDL. قم بتعيين TOKEN_MODE = 'pile' في run.py وقم بتشغيله. إنه سريع حتى على وحدة المعالجة المركزية (الوضع الافتراضي).
كولاب لـ RWKV-4 Pile 1.5B : https://colab.research.google.com/drive/1F7tZoPZaWJf1fsCmZ5tjw6sYHiFOYVWM
قم بتشغيل نماذج RWKV-4 Pile في متصفحك (وإصدار onnx): راجع هذا الإصدار رقم 7
العرض التجريبي للويب RWKV-4: https://josephrocca.github.io/rwkv-v4-web/demo/ (ملاحظة: أخذ العينات الجشعة فقط في الوقت الحالي)
بالنسبة إلى RWKV-2 القديم: راجع الإصدار هنا للحصول على نموذج 27 مليون معلمة على enwik8 مع 0.72 BPC(dev). قم بتشغيل run.py في https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v2-RNN. يمكنك أيضًا تشغيله في متصفحك: https://github.com/BlinkDL/AI-Writer/tree/main/docs/eng https://blinkdl.github.io/AI-Writer/eng/ (وهذا يستخدم tf.js WASM وضع الخيط الواحد).
تثبيت النقطة Deepspeed==0.7.0 // تثبيت النقطة pytorch-lightning==1.9.5 // الشعلة 1.13.1+cu117
ملاحظة: أضف تسوس الوزن (0.1 أو 0.01) والتسرب (0.1 أو 0.01) عند التدريب على كمية صغيرة من البيانات. حاول x=x+dropout(att(x)) x=x+dropout(ffn(x)) x=dropout(x+att(x)) x=dropout(x+ffn(x)) إلخ.
تدريب RWKV-4 من البداية: قم بتشغيل Train.py، والذي يستخدم بشكل افتراضي مجموعة بيانات enwik8 (فك ضغط https://data.deepai.org/enwik8.zip).
سوف تقوم بتدريب إصدار "GPT" لأنه قابل للتوازي وأسرع في التدريب. يمكن لـ RWKV-4 الاستقراء، لذا فإن التدريب باستخدام ctxLen 1024 يمكن أن يعمل مع ctxLen الذي يبلغ 2500+. يمكنك ضبط النموذج باستخدام ctxLen الأطول ويمكنه التكيف بسرعة مع ctxLens الأطول.
ضبط نماذج RWKV-4 Pile: استخدم "prepare-data.py" في https://github.com/BlinkDL/RWKV-v2-RNN-Pile/tree/main/RWKV-v3 لتحويل ملف .txt إلى رمز مميز. بيانات npy. ثم استخدم https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v4neo/train.py لتدريبه.
اقرأ رمز الاستدلال في src/model.py وحاول استخدام الحالة المخفية النهائية (.xx .aa .bb) كجملة مضمنة لمهام أخرى. ربما يجب أن تبدأ بـ .xx و.aa/.bb (.aa مقسومًا على .bb).
Colab لضبط نماذج RWKV-4 Pile: https://colab.research.google.com/github/resloved/RWKV-notebooks/blob/master/RWKV_v4_RNN_Pile_Fine_Tuning.ipynb
مجموعة كبيرة: استخدم https://github.com/Abel2076/json2binidx_tool لتحويل .jsonl إلى .bin و.idx
نموذج تنسيق jsonl (سطر واحد لكل مستند):
{"text": "This is the first document."}
{"text": "HellonWorld"}
{"text": "1+1=2n1+2=3n2+2=4"}
تم إنشاؤها بواسطة رمز مثل هذا:
ss = json.dumps({"text": text}, ensure_ascii=False)
out.write(ss + "n")
تدريب ctxlen اللانهائي (WIP): https://github.com/Blealtan/RWKV-LM-LoRA/tree/dev-infctx
النظر في RWKV 14B. تحتوي الحالة على 200 متجه، أي 5 متجهات لكل كتلة: fp16 (xx)، fp32 (aa)، fp32 (bb)، fp32 (pp)، fp16 (xx).
لا تجمع متوسطًا لأن المتجهات المختلفة (xx aa bb pp xx) في الحالة لها معاني ونطاقات مختلفة جدًا. ربما يمكنك إزالة ص.
أقترح أولاً جمع متوسط + إحصائيات stdev لكل قناة لكل ناقل، وتطبيعها جميعًا (ملاحظة: يجب أن تكون التسوية مستقلة عن البيانات ويتم جمعها من نصوص مختلفة). ثم قم بتدريب المصنف الخطي.
RWKV-5 متعدد الرؤوس وهنا يظهر رأس واحد. يوجد أيضًا LayerNorm لكل رأس (وبالتالي GroupNorm فعليًا).
المزيج الديناميكي والاضمحلال الديناميكي. مثال (افعل ذلك لكل من TimeMix وChannelMix):
TIME_MIX_EXTRA_DIM = 32
self.time_mix_k_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_k_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_v_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_v_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_r_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_r_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
self.time_mix_g_w1 = nn.Parameter(torch.empty(args.n_embd, TIME_MIX_EXTRA_DIM).uniform_(-0.01, 0.01))
self.time_mix_g_w2 = nn.Parameter(torch.zeros(TIME_MIX_EXTRA_DIM, args.n_embd))
...
time_mix_k = self.time_mix_k.view(1,1,-1) + (x @ self.time_mix_k_w1) @ self.time_mix_k_w2
time_mix_v = self.time_mix_v.view(1,1,-1) + (x @ self.time_mix_v_w1) @ self.time_mix_v_w2
time_mix_r = self.time_mix_r.view(1,1,-1) + (x @ self.time_mix_r_w1) @ self.time_mix_r_w2
time_mix_g = self.time_mix_g.view(1,1,-1) + (x @ self.time_mix_g_w1) @ self.time_mix_g_w2
xx = self.time_shift(x)
xk = x * time_mix_k + xx * (1 - time_mix_k)
xv = x * time_mix_v + xx * (1 - time_mix_v)
xr = x * time_mix_r + xx * (1 - time_mix_r)
xg = x * time_mix_g + xx * (1 - time_mix_g)

استخدم الوضع المتوازي لإنشاء الحالة بسرعة، ثم استخدم RNN كاملًا مضبوطًا (يمكن لطبقات الرمز المميز n استخدام مخرجات جميع طبقات الرمز المميز n-1) للتوليد المتسلسل.
الآن أصبح تسوس الوقت مثل 0.999^T (0.999 قابل للتعلم). قم بتغييره إلى شيء مثل (0.999^T + 0.1) حيث يمكن تعلم 0.1 أيضًا. سيتم الاحتفاظ بالجزء 0.1 إلى الأبد. أو A^T + B^T + C = اضمحلال سريع + اضمحلال بطيء + ثابت. يمكن أيضًا استخدام صيغ مختلفة (على سبيل المثال، K^2 بدلاً من e^K لمكون الاضمحلال، أو بدون تسوية).
استخدم الاضمحلال ذو القيمة المعقدة (أي التدوير بدلاً من الاضمحلال) في بعض القنوات.
حقن بعض الترميز الموضعي القابل للتدريب والاستقراء؟
بصرف النظر عن التدوير ثنائي الأبعاد، يمكننا تجربة مجموعات Lie أخرى مثل التدوير ثلاثي الأبعاد ( SO(3) ). RWKV غير أبيليان لول.
قد يكون RWKV رائعًا على الأجهزة التناظرية (ابحث عن مضاعفة ناقل المصفوفة التناظرية وضرب ناقل المصفوفة الضوئية). يعد وضع RNN صديقًا جدًا للأجهزة (المعالجة في الذاكرة). يمكن أن يكون SNN أيضًا (https://github.com/ridgerchu/SpikeGPT). أتساءل عما إذا كان من الممكن تحسينه للحساب الكمي.
الحالة المخفية الأولية القابلة للتدريب (xx aa bb pp xx).
Layerwise (أو حتى الصف/العمود، العنصر) LR، واختبار مُحسِّن Lion.
self.pos_emb_x = nn.Parameter(torch.zeros((1,args.my_pos_emb,args.n_embd)))
self.pos_emb_y = nn.Parameter(torch.zeros((args.my_pos_emb,1,args.n_embd)))
...
x = x + pos_emb_x + pos_emb_y
ربما يمكننا تحسين الحفظ بمجرد تكرار السياق (أعتقد أن مرتين كافية). مثال: مرجع -> مرجع (مرة أخرى) -> سؤال -> إجابة
تكمن الفكرة في التأكد من أن كل رمز مميز في المفردات يفهم طوله وبايتات UTF-8 الأولية.
دع a = max(len(token)) لجميع الرموز المميزة في المفردات. تحديد AA: تعويم [a] [d_emb]
Let b = max(len_in_utf8_bytes(token)) لجميع الرموز المميزة في vocab. تحديد BB: تعويم [ب] [256] [d_emb]
لكل رمز X في المفردات، اجعل [x0, x1,..., xn] هي بايتات UTF-8 الأولية. سنضيف بعض القيم الإضافية إلى تضمينها EMB(X):
EMB(X) += AA[len(X)] + BB[0][x0] + BB[1][x1] + ... + BB[n][xn] (ملاحظة: AA BB هي أوزان قابلة للتعلم)
لدي فكرة لتحسين الترميز. يمكننا ترميز بعض القنوات ليكون لها معاني. مثال:
القناة 0 = "الفضاء"
القناة 1 = "تكبير الحرف الأول"
القناة 2 = "كتابة جميع الحروف بالأحرف الكبيرة"
لذلك:
تضمين "abc": [0, 0, 0, x0, x1, x2 , ..]
تضمين "abc": [1, 0, 0, x0, x1, x2, ..]
تضمين "ABC": [1, 1, 0, x0, x1, x2, ..]
تضمين "ABC": [0، 0، 1، x0، x1، x2، ...]
......
لذلك سوف يتشاركون في معظم التضمين. ويمكننا حساب احتمالية الإخراج لجميع أشكال "abc" بسرعة.
ملاحظة: الطريقة المذكورة أعلاه تفترض أن p("xyz") / p("xyz") هو نفسه بالنسبة لأي "xyz"، وهو ما قد يكون خاطئًا.
الأفضل: حدد emb_space emb_capitalize_first emb_capitalize_all لتكون وظيفة emb.
ربما الأفضل: السماح لـ 'abc' 'abc' وما إلى ذلك بمشاركة آخر 90% من التضمينات الخاصة بهم.
في هذه اللحظة، تنفق جميع أدوات الرموز المميزة لدينا عددًا كبيرًا جدًا من العناصر لتمثيل جميع أشكال "abc" و"abc" و"Abc" وما إلى ذلك. علاوة على ذلك، لا يمكن للنموذج اكتشاف أن هذه الاختلافات متشابهة بالفعل إذا كانت بعض هذه الاختلافات نادرة في مجموعة البيانات. الطريقة هنا يمكن أن تحسن هذا. أخطط لاختبار ذلك في إصدار جديد من RWKV.
مثال (أسئلة وأجوبة أحادية الجولة):
قم بإنشاء الحالة النهائية لجميع مستندات الويكي.
بالنسبة لأي مستخدم Q، ابحث عن أفضل مستند wiki، واستخدم حالته النهائية كحالة أولية.
تدريب نموذج لتوليد الحالة الأولية المثلى مباشرة لأي مستخدم س.
ومع ذلك، قد يكون هذا أكثر صعوبة بعض الشيء بالنسبة للأسئلة والأجوبة متعددة الجولات :)
RWKV مستوحى من AFT من Apple (https://arxiv.org/abs/2105.14103).
علاوة على ذلك، فهو يستخدم عددًا من حيلتي، مثل:
SmallInitEmb: https://github.com/BlinkDL/SmallInitEmb (ينطبق على جميع المحولات) مما يساعد على جودة التضمين، ويعمل على استقرار Post-LN (وهو ما أستخدمه).
Token-shift: https://github.com/BlinkDL/RWKV-LM#token-shift-time-shift-mixing (ينطبق على جميع المحولات)، وهو مفيد بشكل خاص للنماذج على مستوى الحرف.
Head-QK: https://github.com/BlinkDL/RWKV-LM#the-head-qk-trick-learning-to-copy-and-avoid-tokens (ينطبق على جميع المحولات). ملاحظة: إنه مفيد، لكنني قمت بتعطيله في نموذج Pile لإبقائه بنسبة 100% RNN.
بوابة R إضافية في FFN (تنطبق على جميع المحولات). أنا أستخدم أيضًا reluSquared من Primer.
تهيئة أفضل: أقوم بتهيئة معظم المصفوفات إلى الصفر (راجع RWKV_Init في https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v2-RNN/src/model.py).
يمكنك نقل بعض المعلمات من نموذج صغير إلى نموذج كبير (ملاحظة: أقوم بفرزها وتنعيمها أيضًا)، لتحقيق تقارب أسرع وأفضل (راجع https://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with /).
نواة CUDA الخاصة بي: https://github.com/BlinkDL/RWKV-CUDA لتسريع التدريب.

تعمل عوامل ABCD معًا لبناء منحنى الاضمحلال الزمني: [X, 1, W, W^2, W^3, ...].
اكتب صيغ "الرمز المميز في pos 2" و"الرمز المميز في pos 3" وستحصل على الفكرة:
kv / k هي آلية الذاكرة. يمكن تذكر الرمز المميز ذو k العالي لمدة طويلة، إذا كان W قريبًا من 1 في القناة.
بوابة R مهمة للأداء. k = قوة معلومات هذا الرمز المميز (ليتم تمريرها إلى الرموز المستقبلية). r = ما إذا كان سيتم تطبيق المعلومات على هذا الرمز المميز.
استخدم عوامل TimeMix مختلفة قابلة للتدريب لـ R / K / V في طبقات SA وFF. مثال:
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )استخدم preLN بدلاً من postLN (تقارب أكثر استقرارًا وأسرع):
if self . layer_id == 0 :
x = self . ln0 ( x )
x = x + self . att ( self . ln1 ( x ))
x = x + self . ffn ( self . ln2 ( x ))تتشابه العناصر الأساسية لوضع RWKV-3 GPT مع تلك الموجودة في وضع preLN GPT المعتاد.
والفرق الوحيد هو LN إضافي بعد التضمين. لاحظ أنه يمكنك استيعاب LN هذا في التضمين بعد الانتهاء من التدريب.
x = self . emb ( idx ) # input: idx = token indices
x = self . ln_emb ( x ) # extra LN after embedding
x = x + self . att_0 ( self . ln_att_0 ( x )) # preLN
x = x + self . ffn_0 ( self . ln_ffn_0 ( x ))
...
x = x + self . att_n ( self . ln_att_n ( x ))
x = x + self . ffn_n ( self . ln_ffn_n ( x ))
x = self . ln_head ( x ) # final LN before projection
x = self . head ( x ) # output: x = logitsمن المهم تهيئة emb إلى قيم صغيرة، مثل nn.init.uniform_(a=-1e-4, b=1e-4)، للاستفادة من خدعتي https://github.com/BlinkDL/SmallInitEmb.
بالنسبة لـ 1.5B RWKV-3، أستخدم مُحسِّن Adam (بدون wd، بدون تسرب) على 8 * A100 40G.
BatchSz = 32 * 896، ctxLen = 896. أنا أستخدم tf32 لذا فإن BatchSz صغير بعض الشيء.
بالنسبة لأول 15 مليار رمز، تم تثبيت LR عند 3e-4، وbeta=(0.9، 0.99).
ثم قمت بتعيين beta=(0.9, 0.999)، وقمت بإجراء تحلل أسي لـ LR، حيث وصلت إلى 1e-5 عند 332B من الرموز المميزة.
لا يحظى RWKV-3 بأي اهتمام بالمعنى المعتاد، ولكننا سنسمي هذه الكتلة ATT على أي حال.
B , T , C = x . size () # x = (Batch,Time,Channel)
# Mix x with the previous timestep to produce xk, xv, xr
xx = self . time_shift ( x ) # self.time_shift = nn.ZeroPad2d((0,0,1,-1))
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xv = x * self . time_mix_v + xx * ( 1 - self . time_mix_v )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# Use xk, xv, xr to produce k, v, r
k = self . key ( xk ). transpose ( - 1 , - 2 )
v = self . value ( xv ). transpose ( - 1 , - 2 )
r = self . receptance ( xr )
k = torch . clamp ( k , max = 60 ) # clamp k to avoid overflow
k = torch . exp ( k )
kv = k * v
# Compute the W-curve = [e^(-n * e^time_decay), e^(-(n-1) * e^time_decay), ..., 1, e^(time_first)]
self . time_w = torch . cat ([ torch . exp ( self . time_decay ) * self . time_curve . to ( x . device ), self . time_first ], dim = - 1 )
w = torch . exp ( self . time_w )
# Use W to mix kv and k respectively. Add K_EPS to wk to avoid divide-by-zero
if RUN_DEVICE == 'cuda' :
wkv = TimeX . apply ( w , kv , B , C , T , 0 )
wk = TimeX . apply ( w , k , B , C , T , K_EPS )
else :
w = w [:, - T :]. unsqueeze ( 1 )
wkv = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( kv ), w , groups = C )
wk = F . conv1d ( nn . ZeroPad2d (( T - 1 , 0 , 0 , 0 ))( k ), w , groups = C ) + K_EPS
# The RWKV formula
rwkv = torch . sigmoid ( r ) * ( wkv / wk ). transpose ( - 1 , - 2 )
rwkv = self . output ( rwkv ) # final output projectionتتم تهيئة مصفوفات self.key وself.receptance وself.output جميعها إلى الصفر.
يتم نقل المتجهات time_mix وtime_decay وtime_first من نموذج مدرب أصغر (ملاحظة: أقوم بفرزها وتنعيمها أيضًا).
تحتوي كتلة FFN على ثلاث حيل مقارنة بـ GPT المعتاد:
خدعة time_mix الخاصة بي.
sqReLU من الورقة التمهيدية.
بوابة استقبال إضافية (على غرار بوابة الاستقبال في كتلة ATT).
# Mix x with the previous timestep to produce xk, xr
xx = self . time_shift ( x )
xk = x * self . time_mix_k + xx * ( 1 - self . time_mix_k )
xr = x * self . time_mix_r + xx * ( 1 - self . time_mix_r )
# The usual FFN operation
k = self . key ( xk )
k = torch . square ( torch . relu ( k )) # from the Primer paper
kv = self . value ( k )
# Apply an extra receptance-gate to kv
rkv = torch . sigmoid ( self . receptance ( xr )) * kv
return rkvتتم تهيئة مصفوفات القيمة الذاتية والقبول الذاتي جميعها إلى الصفر.

دع F[t] تكون حالة النظام عند t.
دع x[t] يكون المدخل الخارجي الجديد عند t.
في GPT، يتطلب توقع F[t+1] مراعاة F[0]، F[1]، .. F[t]. لذلك يستغرق الأمر O(T^2) لإنشاء تسلسل T بطول.
الصيغة المبسطة لـ GPT:
إنها قادرة جدًا من الناحية النظرية، ولكن هذا لا يعني أنه يمكننا الاستفادة الكاملة من قدرتها مع أدوات التحسين المعتادة . أظن أن مشهد الخسارة صعب للغاية بالنسبة لأساليبنا الحالية.
قارن مع الصيغة المبسطة لـ RWKV (الوضع الموازي يشبه AFT من Apple):
تعتبر R وK وV مصفوفات قابلة للتدريب، وW عبارة عن ناقل قابل للتدريب (عامل اضمحلال الوقت لكل قناة).
في GPT، يتم وزن مساهمة F[i] في F[t+1] بمقدار .
في RWKV-2، يتم ترجيح مساهمة F[i] في F[t+1] بمقدار .
هنا تأتي الجملة النهائية: يمكننا إعادة كتابتها في RNN (صيغة متكررة). ملحوظة:
لذلك من السهل التحقق:
حيث A[t] وB[t] هما بسط ومقام الخطوة السابقة، على التوالي.
أعتقد أن RWKV ذو أداء جيد لأن W يشبه تطبيق مصفوفة قطرية بشكل متكرر. ملاحظة (P^{-1} DP)^n = P^{-1} D^n P، لذا فهو مشابه لتطبيق مصفوفة عامة قابلة للقياس بشكل متكرر.
علاوة على ذلك، من الممكن تحويلها إلى قصيدة ODE مستمرة (تشبه قليلاً نماذج الفضاء الحكومية). سأكتب عنها لاحقا.
لدي فكرة عن [نص --> صورة 32x32 RGB] باستخدام LM (محول، RWKV، وما إلى ذلك). سوف اختباره قريبا.
أولاً، فقدان LM (بدلاً من فقدان L2)، وبالتالي لن تكون الصورة ضبابية.
ثانيا، تكمية اللون. على سبيل المثال، السماح فقط بـ 8 مستويات لـ R/G/B. ثم يكون حجم مفردات الصورة 8x8x8 = 512 (لكل بكسل)، بدلاً من 2^24. لذلك، صورة 32x32 RGB = تسلسل len1024 من vocab512 (رموز الصور)، وهو إدخال نموذجي لـ LM المعتادة. (في وقت لاحق يمكننا استخدام نماذج الانتشار لتكوين صور RGB888 وإنشاءها. وقد نتمكن من استخدام LM لهذا أيضًا.)
ثالثًا، التضمينات الموضعية ثنائية الأبعاد التي يسهل على النموذج فهمها. على سبيل المثال، أضف إحداثيات X وY واحدة ساخنة إلى أول 64 قناة (=32+32). لنفترض أنه إذا كان البكسل عند x=8، y=20، فسنضيف 1 إلى القناة 8 والقناة 52 (=32+20). علاوة على ذلك، ربما يمكننا إضافة إحداثيات X & Y العائمة (المقيسة إلى نطاق 0 ~ 1) إلى قناتين أخريين. وغيرها من المواقف الدورية. قد يساعد الترميز أيضًا (سيتم اختباره).
وأخيرا، RandRound متى


