CAMEL
1.0.0

نحن فخورون بتقديم أسكليبيوس ، وهو نموذج لغة سريري كبير أكثر تقدمًا. وبما أن هذا النموذج تم تدريبه على الملاحظات السريرية الاصطناعية، فإنه يمكن الوصول إليه بشكل عام عبر Huggingface. إذا كنت تفكر في استخدام CAMEL، فإننا نوصي بشدة بالتبديل إلى Asclepius بدلاً من ذلك. لمزيد من المعلومات، يرجى زيارة هذا الرابط.
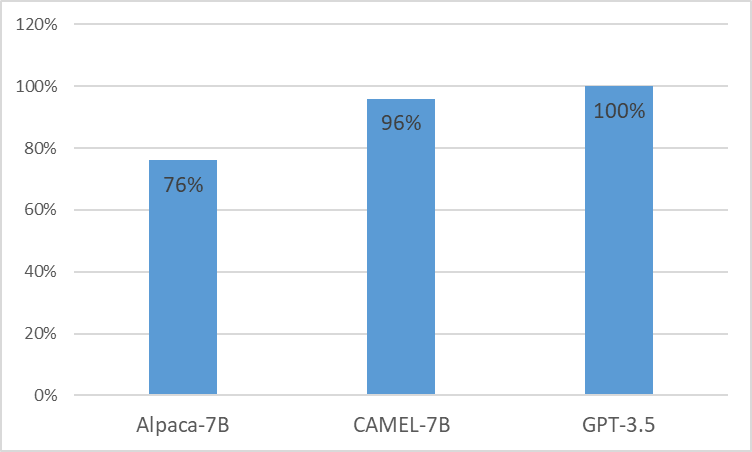
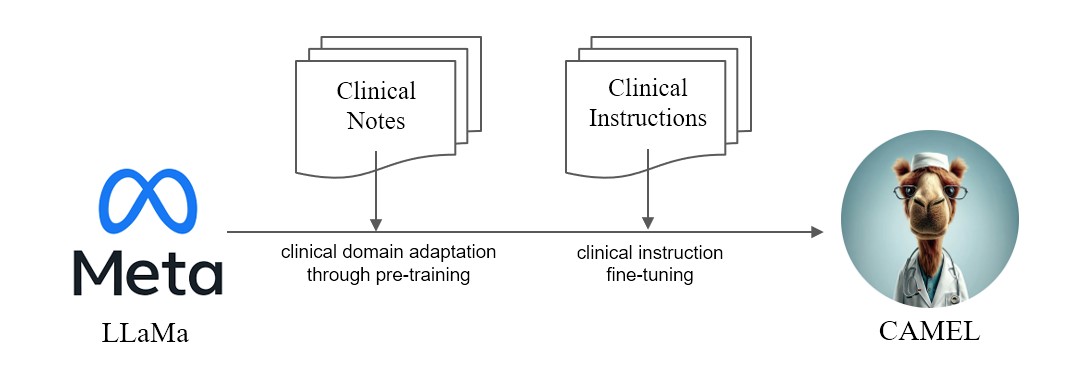
نقدم CAMEL ، النموذج المُعدل سريريًا المُحسّن من LLaMA. نظرًا لأن LLaMA هو أساس تأسيسه، فقد تم تدريب CAMEL مسبقًا على الملاحظات السريرية MIMIC-III وMIMIC-IV، وتم ضبطه وفقًا للتعليمات السريرية (الشكل 2). يوضح تقييمنا الأولي مع تقييم GPT-4 أن CAMEL تحقق أكثر من 96% من جودة GPT-3.5 الخاصة بـ OpenAI (الشكل 1). وفقًا لسياسات استخدام البيانات الخاصة ببيانات المصدر الخاصة بنا، سيتم نشر كل من مجموعة بيانات التعليمات والنموذج على PhysioNet مع إمكانية الوصول المعتمدة. لتسهيل التكرار، سنقوم أيضًا بإصدار جميع التعليمات البرمجية، مما يسمح لمؤسسات الرعاية الصحية الفردية بإعادة إنتاج نموذجنا باستخدام الملاحظات السريرية الخاصة بها. لمزيد من التفاصيل، يرجى الرجوع إلى منشور المدونة الخاص بنا.
نظرًا لإصدار ترخيص مجموعات بيانات MIMIC وi2b2، لا يمكننا نشر مجموعة بيانات التعليمات ونقاط التفتيش. سنقوم بنشر نموذجنا وبياناتنا عبر Physionet في غضون أسابيع قليلة.
conda create -n camel python=3.9 -y
conda activate camel
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia -y
pip install pandarallel pandas jupyter numpy datasets sentencepiece openai fire
pip install git+https://github.com/huggingface/transformers.git@871598be552c38537bc047a409b4a6840ba1c1e4
<eos> .$ python pretraining_preprocess/mimiciii_preproc.py --mimiciii_note_path {MIMICIII_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/mimiciv_preproc.py --discharge_note_path {DISCHAGE_NOTE_PATH} --radiology_note_path {RADIOLOGY_NOTE_PATH} --output_path {OUTPUT_PATH}$ python pretraining_preprocess/tokenize_data.py --data_path {DATA_PATH} --save_path {SAVE_PATH} $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/train.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {DATA_FILE}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 1
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
ملاحظة: لإنشاء التعليمات، يجب عليك استخدام Azure Openai API المعتمد.
جيل التعليمات
OPENAI_API_KEYOPENAI_API_BASEOPENAI_DEPLOYMENT_NAME$ python instructino/preprocess_note.py$ python instruction/de_id_gen.py --input {PREPROCESSED_NOTES} --output {OUTPUT_FILE_1} --mode inst$ python instruction/de_id_postprocess.py --input {OUTPUT_FILE_1} --output {OUTPUT_FILE_2}$ python instruction/de_id_gen.py --input {OUTPUT__FILE_2} --output {inst_output/OUTPUT_FILE_deid} --mode ans$ python instruction/instructtion_gen.py --input {PREPROCESSED_NOTES} --output {inst_output/OUTPUT_FILE} --source {mimiciii, mimiciv, i2b2}$ python instruction/merge_data.py --data_path {inst_output} --output {OUTPUT_FILE_FINAL}قم بتشغيل التعليمات الدقيقة
nproc_per_node وخطوة gradient accumulate step لتناسب أجهزتك (حجم الدفعة العالمي = 128). $ torchrun --nproc_per_node=8 --master_port={YOUR_PORT}
src/instruction_ft.py
--model_name_or_path "decapoda-research/llama-7b-hf"
--data_path {OUTPUT_FILE_FINAL}
--bf16 True
--output_dir ./checkpoints
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "epoch"
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
--ddp_timeout 18000
تشغيل النموذج على MTSamples
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py
--model_name {MODEL_PATH}
--data_path eval/mtsamples_instructions.json
--output_path {OUTPUT_PATH}
mtsamples_results.json في مجلد eval .قم بتشغيل GPT-4 للتقييم
python eval/gpt4_evaluate.py --input {INPUT_PATH} --output {OUTPUT_PATH}
@misc{CAMEL,
title = {CAMEL : Clinically Adapted Model Enhanced from LLaMA},
author = {Sunjun Kweon and Junu Kim and Seongsu Bae and Eunbyeol Cho and Sujeong Im and Jiyoun Kim and Gyubok Lee and JongHak Moon and JeongWoo Oh and Edward Choi},
month = {May},
year = {2023}
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/starmpcc/CAMEL}},
}


