Tutorbot Spock
1.0.0
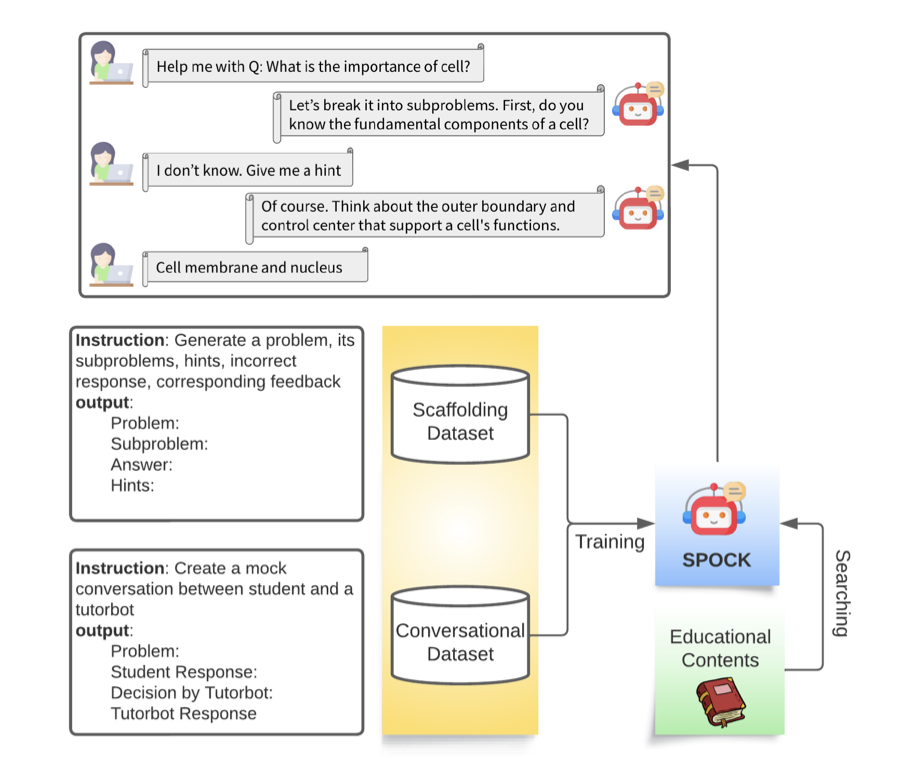
CLASS: إطار تصميم لبناء أنظمة تعليمية ذكية تعتمد على مبادئ تعلم العلوم (EMNLP 2023)
شاشانك سونكار، نايمينغ ليو، ديبشيلا باسو ماليك، ريتشارد جي بارانيوك
الورقة: https://arxiv.org/abs/2305.13272
الفرع: كلاس
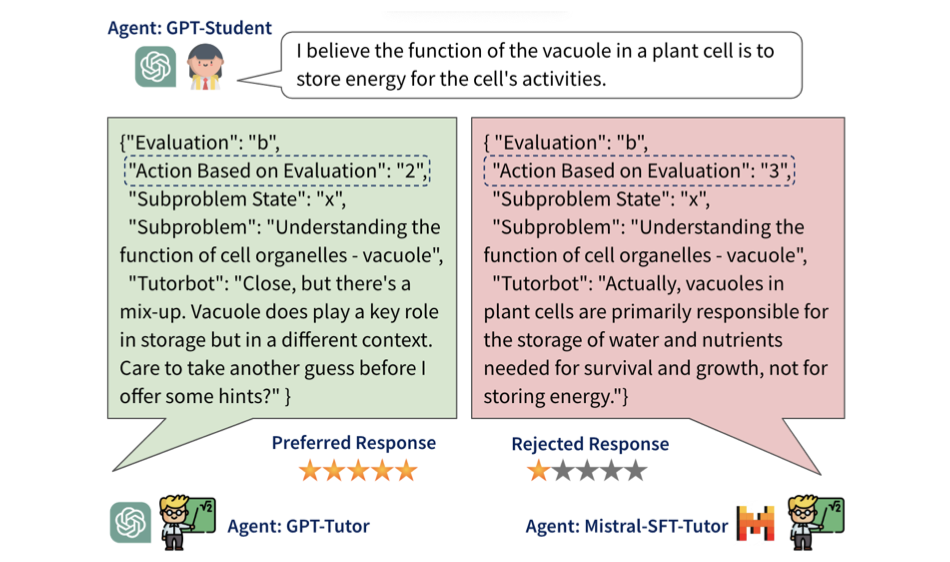
المواءمة التربوية لنماذج اللغات الكبيرة (EMNLP 2024)
شاشانك سونكار*، كانجكي ني*، سابانا تشودري، ريتشارد جي بارانيوك
الورقة: https://arxiv.org/abs/2402.05000
الفرع: الرئيسي
يهدف هذا الريبو إلى تطوير عوامل تعليمية ذكية فعالة تساعد الطلاب على تطوير مهارات التفكير النقدي وحل المشكلات.
يرجى الرجوع إلى scripts/run.sh كمثال، والذي يدير التدريب والتقييم لنموذج محدد باستخدام وحدات معالجة الرسومات 4*A100. لتشغيل هذا المثال بدون تدريب، قم بتنزيل النماذج من القسم أدناه وارجع إلى scripts/run_no-train.sh . تقوم الأقسام الفرعية التالية بتقسيم scripts/run.sh مع شرح أكثر تفصيلاً.
يستخدم التدريب والتقييم bio-dataset-1.json، وbio-dataset-2.json، وbio-dataset-3.json، وbio-dataset-ppl.json من مجلد مجموعات البيانات. يحتوي كل منها على محادثات وهمية بين الطالب والمعلم بناءً على مفاهيم علم الأحياء الناتجة عن OpenAI's GPT-4. تتم بعد ذلك معالجة هذه البيانات مسبقًا وتحويلها إلى التنسيقات المطلوبة لمجموعات بيانات التدريب والتقييم. يرجى الرجوع إلى فرع CLASS للحصول على إرشادات حول إنشاء هذه البيانات.
ضبط معلمات المستخدم:
FULL_MODEL_PATH="meta-llama/Meta-Llama-3.1-8B-Instruct"
MODEL_DIR="models"
DATA_DIR="datasets"
SFT_OPTION="transformers" # choices: ["transformers", "fastchat"]
ALGO="dpo" # choices: ["dpo", "ipo", "kto"]
BETA=0.1 # choices: [0.0 - 1.0]
بيانات المعالجة المسبقة:
python src/preprocess_sft_data.py --data_dir $DATA_DIR
نحن نقدم خيارين لـ SFT: (1) المحولات (2) FastChat.
(1) تشغيل SFT باستخدام المحولات:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 src/train/train_sft.py
--model_path $FULL_MODEL_PATH
--train_dataset_path $SFT_DATASET_PATH
--eval_dataset_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--max_seq_length 4096
--gradient_checkpointing
(2) تشغيل SFT باستخدام FastChat:
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=20001 FastChat/fastchat/train/train.py
--model_name_or_path $FULL_MODEL_PATH
--data_path $SFT_DATASET_PATH
--eval_data_path ${DATA_DIR}/bio-test.json
--output_dir $SFT_MODEL_PATH
--cache_dir cache
--bf16 True
--num_train_epochs 3
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--gradient_accumulation_steps 2
--evaluation_strategy "epoch"
--eval_accumulation_steps 50
--save_strategy "epoch"
--seed 42
--learning_rate 2e-5
--weight_decay 0.05
--warmup_ratio 0.1
--lr_scheduler_type "cosine"
--logging_steps 1
--tf32 True
--model_max_length 4096
--gradient_checkpointing True
إنشاء بيانات التفضيل:
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-dpo --test_dataset_path $DPO_DATASET_PATH --batch_size 256
python src/preprocess/preprocess_dpo_data.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-dpo/responses.csv --data_file $DPO_PREF_DATASET_PATH
تشغيل محاذاة التفضيلات:
DPO_MODEL_PATH="${MODEL_DIR}_dpo/${MODEL_NAME}_bio-tutor_${ALGO}"
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --config_file=ds_config/deepspeed_zero3.yaml --num_processes=4 train/train_dpo.py
--train_data $DPO_PREF_DATASET_PATH
--model_path $SFT_MODEL_PATH
--output_dir $DPO_MODEL_PATH
--beta $BETA
--loss $ALGO
--gradient_checkpointing
--bf16
--gradient_accumulation_steps 4
--per_device_train_batch_size 2
--num_train_epochs 3
قم بتقييم الدقة ودرجات F1 لنماذج SFT والمحاذاة:
# Generate responses from the SFT model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $SFT_MODEL_PATH --output_dir ${SFT_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Generate responses from the Aligned model
CUDA_VISIBLE_DEVICES=0,1,2,3 python src/evaluate/generate_responses.py --model_path $DPO_MODEL_PATH --output_dir ${DPO_MODEL_PATH}/final_checkpoint-eval --test_dataset_path $TEST_DATASET_PATH --batch_size 256
# Evaluate the SFT model
echo "Metrics of the SFT Model:"
python src/evaluate/evaluate_responses.py --response_file ${SFT_MODEL_PATH}/final_checkpoint-eval/responses.csv
# Evaluate the Aligned model
echo "Metrics of the RL Model:"
python src/evaluate/evaluate_responses.py --response_file ${DPO_MODEL_PATH}/final_checkpoint-eval/responses.csv
تقييم ppl للنماذج SFT والمحاذاة:
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $SFT_MODEL_PATH
CUDA_VISIBLE_DEVICES=0,1 python src/evaluate/evaluate_ppl.py --model_path $DPO_MODEL_PATH
للوصول بسهولة إلى النماذج، قم بتنزيلها من Hugging Face.
نماذج SFT:
النماذج المحاذية:
إذا وجدت عملنا مفيدا، يرجى ذكر:
@misc{sonkar2023classdesignframeworkbuilding,
title={CLASS: A Design Framework for building Intelligent Tutoring Systems based on Learning Science principles},
author={Shashank Sonkar and Naiming Liu and Debshila Basu Mallick and Richard G. Baraniuk},
year={2023},
eprint={2305.13272},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2305.13272},
}
@misc{sonkar2024pedagogical,
title={Pedagogical Alignment of Large Language Models},
author={Shashank Sonkar and Kangqi Ni and Sapana Chaudhary and Richard G. Baraniuk},
year={2024},
eprint={2402.05000},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2402.05000},
}


