DiGIT
1.0.0
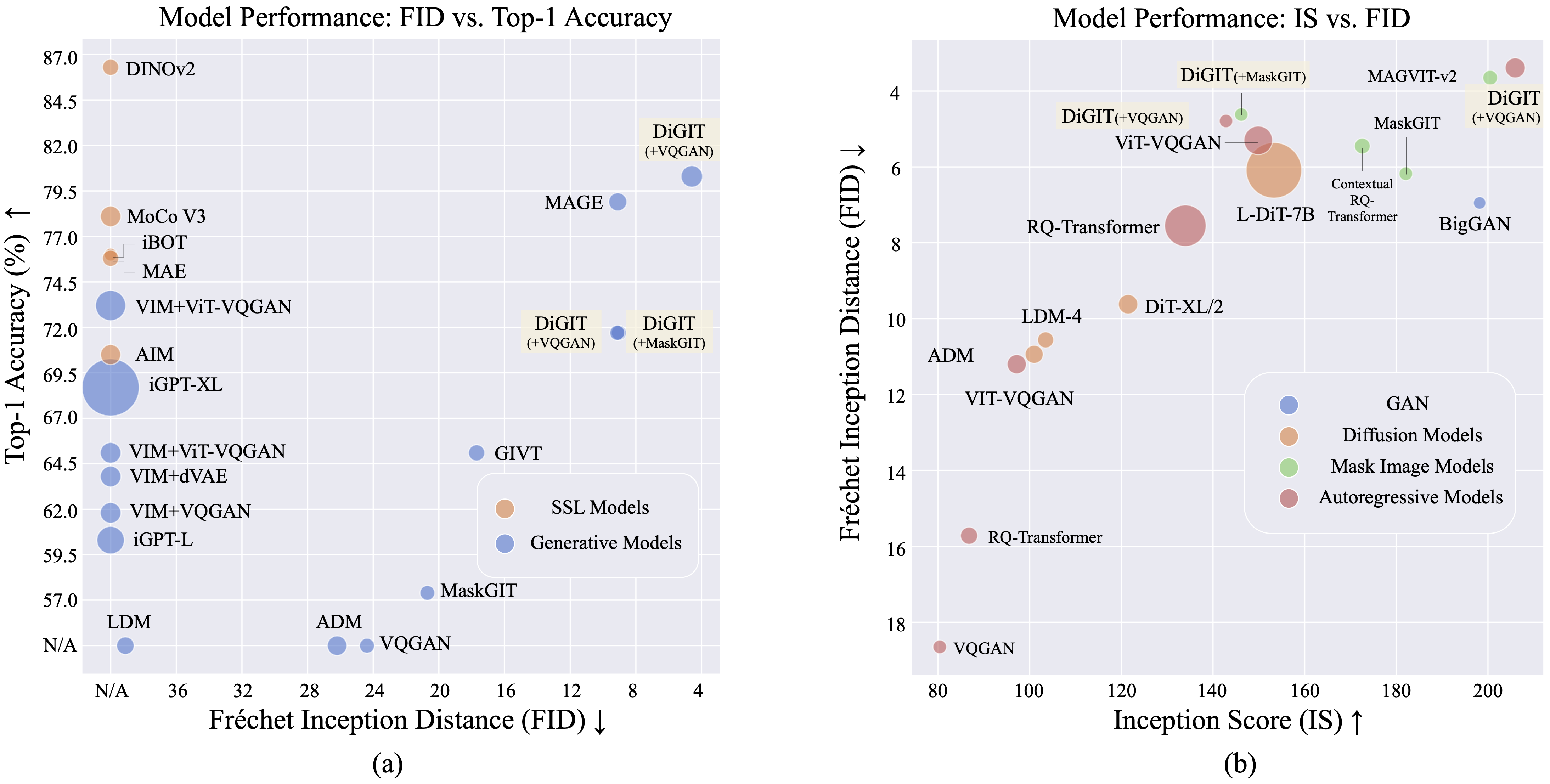
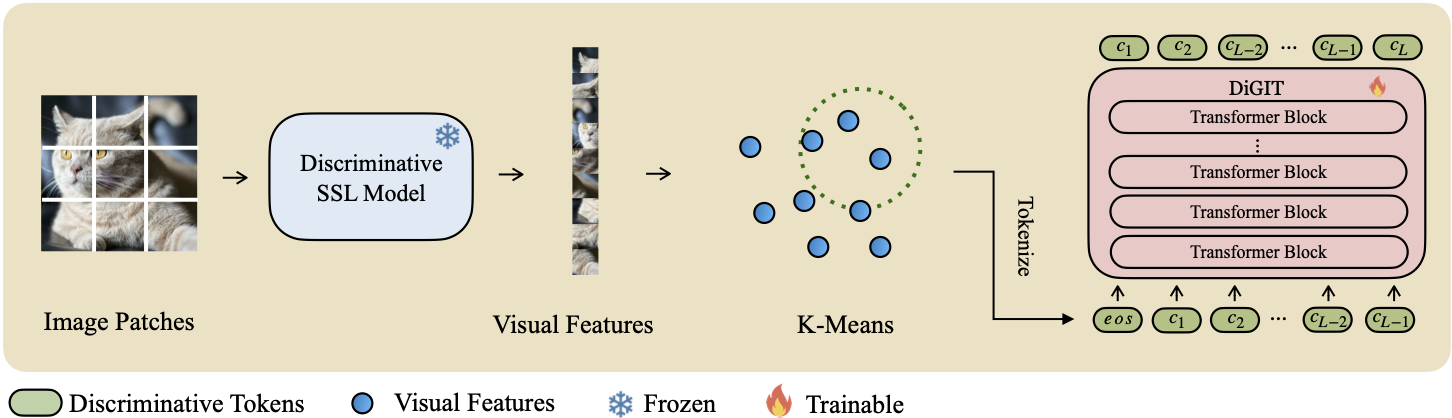
نقدم DiGIT ، وهو نموذج توليدي انحداري تلقائي يقوم بالتنبؤ بالرمز المميز التالي في مساحة كامنة مجردة مستمدة من نماذج التعلم الخاضع للإشراف الذاتي (SSL). من خلال استخدام تجميع K-Means في الحالات المخفية لنموذج DINOv2، فإننا ننشئ بفعالية رمزًا مميزًا منفصلاً جديدًا. تعمل هذه الطريقة على تعزيز أداء إنشاء الصور بشكل كبير على مجموعة بيانات ImageNet، مما يحقق درجة FID تبلغ 4.59 للمهام غير المشروطة و 3.39 للمهام المشروطة للفئة . بالإضافة إلى ذلك، يعزز النموذج فهم الصورة، ويحقق دقة مسبار خطي تبلغ 80.3 .
| طُرق | #الرموز | سمات | #بارامس | أعلى 1 لجنة التنسيق الإدارية. |
|---|---|---|---|---|
| iGPT-L | 32 | 1536 | 1362 م | 60.3 |
| iGPT-XL | 64 | 3072 | 6801 م | 68.7 |
| فيم + فقغان | 32 | 1024 | 650 م | 61.8 |
| فيم+دفاي | 32 | 1024 | 650 م | 63.8 |
| فيم + فيت-VQGAN | 32 | 1024 | 650 م | 65.1 |
| فيم + فيت-VQGAN | 32 | 2048 | 1697 م | 73.2 |
| هدف | 16 | 1536 | 0.6 ب | 70.5 |
| ديجيت (لنا) | 16 | 1024 | 219 م | 71.7 |
| ديجيت (لنا) | 16 | 1536 | 732 م | 80.3 |
| يكتب | طُرق | # بارام | #عصر | FID | يكون |
|---|---|---|---|---|---|
| جان | بيججان | 70 م | - | 38.6 | 24.70 |
| فرق. | LDM | 395 م | - | 39.1 | 22.83 |
| فرق. | ADM | 554 م | - | 26.2 | 39.70 |
| ميم | بركه | 200 م | 1600 | 11.1 | 81.17 |
| ميم | بركه | 463 م | 1600 | 9.10 | 105.1 |
| ميم | MaskGIT | 227 م | 300 | 20.7 | 42.08 |
| ميم | ديجيت (+MaskGIT) | 219 م | 200 | 9.04 | 75.04 |
| AR | VQGAN | 214 م | 200 | 24.38 | 30.93 |
| AR | رقم (+VQGAN) | 219 م | 400 | 9.13 | 73.85 |
| AR | رقم (+VQGAN) | 732 م | 200 | 4.59 | 141.29 |
| يكتب | طُرق | # بارام | #عصر | FID | يكون |
|---|---|---|---|---|---|
| جان | بيججان | 160 م | - | 6.95 | 198.2 |
| فرق. | ADM | 554 م | - | 10.94 | 101.0 |
| فرق. | إل دي إم-4 | 400 م | - | 10.56 | 103.5 |
| فرق. | ديت-XL/2 | 675 م | - | 9.62 | 121.50 |
| فرق. | إل-ديت-7ب | 7 ب | - | 6.09 | 153.32 |
| ميم | CQR-ترانس | 371 م | 300 | 5.45 | 172.6 |
| ميم + ع | حكم الفيديو المساعد | 310 م | 200 | 4.64 | - |
| ميم + ع | حكم الفيديو المساعد | 310 م | 200 | 3.60* | 257.5* |
| ميم + ع | حكم الفيديو المساعد | 600 م | 250 | 2.95* | 306.1* |
| ميم | ماجفيت-v2 | 307 م | 1080 | 3.65 | 200.5 |
| AR | فQVAE-2 | 13.5 ب | - | 31.11 | 45 |
| AR | RQ-ترانس | 480 م | - | 15.72 | 86.8 |
| AR | RQ-ترانس | 3.8 ب | - | 7.55 | 134.0 |
| AR | ViTVQGAN | 650 م | 360 | 11.20 | 97.2 |
| AR | ViTVQGAN | 1.7 ب | 360 | 5.3 | 149.9 |
| ميم | MaskGIT | 227 م | 300 | 6.18 | 182.1 |
| ميم | ديجيت (+MaskGIT) | 219 م | 200 | 4.62 | 146.19 |
| AR | VQGAN | 227 م | 300 | 18.65 | 80.4 |
| AR | رقم (+VQGAN) | 219 م | 400 | 4.79 | 142.87 |
| AR | رقم (+VQGAN) | 732 م | 200 | 3.39 | 205.96 |
*: تم تدريب تقنية VAR بتوجيهات خالية من المصنفات بينما لم يتم تدريب جميع النماذج الأخرى.
يمكن تنزيل ملف K-Means npy ونقاط التفتيش النموذجية من:
| نموذج | وصلة |
|---|---|
| أوزان عالية التردد؟ | معانقة |
بالنسبة للنموذج الأساسي، نستخدم DINOv2-base وDINOv2-large للنموذج كبير الحجم. إن VQGAN الذي نستخدمه هو نفس MAGE.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITfairseq عبر pip install fairseq . قم بتنزيل مجموعة بيانات ImageNet، وضعها في مجموعة البيانات الخاصة بك dir $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 .
قم باستخراج ميزات SSL وحفظها كملفات .npy. استخدم خوارزمية K-Means مع faiss لحساب النقط الوسطى. يمكنك أيضًا الاستفادة من النقط الوسطى المدربة مسبقًا والمتوفرة على Huggingface.
bash preprocess/run.shالخطوة 1
تدريب نموذج GPT باستخدام رمز مميز. يمكنك العثور على نصوص التدريب في scripts/train_stage1_ar.sh والمعلمات الفائقة موجودة في config/stage1/dino_base.yaml . للحصول على تكوين التوليد الشرطي للفئة، راجع scripts/train_stage1_classcond.sh .
الخطوة 2
قم بتدريب وحدة فك ترميز البكسل (إما طراز AR أو طراز NAR) بشرط استخدام الرموز المميزة. يمكنك العثور على نصوص التدريب ذات الانحدار التلقائي في scripts/train_stage2_ar.sh وNAR في scripts/train_stage2_nar.sh .
سيتم إنشاء مجلد باسم outputs/EXP_NAME/checkpoints لحفظ نقاط التفتيش. يتم حفظ ملفات سجل TensorBoard في outputs/EXP_NAME/tb . سيتم تسجيل السجلات في outputs/EXP_NAME/train.log .
يمكنك مراقبة عملية التدريب باستخدام tensorboard --logdir=outputs/EXP_NAME/tb .
أول عينة من الرموز المميزة باستخدام scripts/infer_stage1_ar.sh . بالنسبة لحجم النموذج الأساسي، نوصي بتعيين topk=200، وبالنسبة لحجم النموذج الكبير، استخدم topk=400.
ثم قم بتشغيل scripts/infer_stage2_ar.sh لأخذ عينات من الرموز المميزة VQ استنادًا إلى الرموز المميزة التي تم أخذ عينات منها مسبقًا.
سيتم تخزين الرموز المميزة والصور المركبة في دليل يسمى outputs/EXP_NAME/results .
قم بإعداد مجموعة التحقق من صحة ImageNet لتقييم FID:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val قم بتثبيت أداة التقييم عن طريق تشغيل pip install torch-fidelity .
قم بتنفيذ الأمر التالي لتقييم FID:
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.shهذا المشروع مرخص بموجب ترخيص MIT - راجع ملف الترخيص للحصول على التفاصيل.
إذا وجدت مشروعنا مفيدًا، آمل أن تتمكن من تمييز الريبو الخاص بنا بنجمة والاستشهاد بعملنا على النحو التالي.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

