FasterTransformer
v5.3 release
ملاحظة: انتقل تطوير FasterTransformer إلى TensorRT-LLM. يتم تشجيع جميع المطورين على الاستفادة من TensorRT-LLM للحصول على أحدث التحسينات على LLM Inference. سيبقى مستودع NVIDIA/FasterTransformer قائمًا، لكن لن يكون لديه مزيد من التطوير.
يوفر هذا المستودع برنامجًا نصيًا ووصفة لتشغيل مكون التشفير ووحدة فك التشفير المعتمد على المحولات، ويتم اختباره وصيانته بواسطة NVIDIA.
في البرمجة اللغوية العصبية، يعد التشفير ووحدة فك التشفير عنصرين مهمين، حيث أصبحت طبقة المحولات بنية شائعة لكلا المكونين. يطبق FasterTransformer طبقة محولات محسنة للغاية لكل من جهاز التشفير ووحدة فك التشفير للاستدلال. في وحدات معالجة الرسوميات Volta وTuring وAmpere، يتم استخدام قوة الحوسبة لـ Tensor Cores تلقائيًا عندما تكون دقة البيانات والأوزان FP16.
تم بناء FasterTransformer على أساس CUDA، وcuBLAS، وcuBLASLT، وC++. نحن نقدم واجهة برمجة تطبيقات واحدة على الأقل من الأطر التالية: TensorFlow وPyTorch وTriton backend. يمكن للمستخدمين دمج FasterTransformer في هذه الأطر مباشرة. بالنسبة لأطر العمل الداعمة، نقدم أيضًا رموز أمثلة لتوضيح كيفية الاستخدام وإظهار الأداء على هذه الأطر.
| نماذج | نطاق | FP16 | INT8 (بعد تورينج) | سبارسيتي (بعد الأمبير) | الموتر الموازي | خط الأنابيب موازي | FP8 (بعد هوبر) |
|---|---|---|---|---|---|---|---|
| بيرت | TensorFlow | نعم | نعم | - | - | - | - |
| بيرت | باي تورش | نعم | نعم | نعم | نعم | نعم | - |
| بيرت | تريتون الخلفية | نعم | - | - | نعم | نعم | - |
| بيرت | سي ++ | نعم | نعم | - | - | - | نعم |
| XLNet | سي ++ | نعم | - | - | - | - | - |
| التشفير | TensorFlow | نعم | نعم | - | - | - | - |
| التشفير | باي تورش | نعم | نعم | نعم | - | - | - |
| فك التشفير | TensorFlow | نعم | - | - | - | - | - |
| فك التشفير | باي تورش | نعم | - | - | - | - | - |
| فك التشفير | TensorFlow | نعم | - | - | - | - | - |
| فك التشفير | باي تورش | نعم | - | - | - | - | - |
| جي بي تي | TensorFlow | نعم | - | - | - | - | - |
| جي بي تي/أو بي تي | باي تورش | نعم | - | - | نعم | نعم | نعم |
| جي بي تي/أو بي تي | تريتون الخلفية | نعم | - | - | نعم | نعم | - |
| GPT-وزارة التربية والتعليم | باي تورش | نعم | - | - | نعم | نعم | - |
| يزدهر | باي تورش | نعم | - | - | نعم | نعم | - |
| يزدهر | تريتون الخلفية | نعم | - | - | نعم | نعم | - |
| جي بي تي-ي | تريتون الخلفية | نعم | - | - | نعم | نعم | - |
| منذ فترة طويلة | باي تورش | نعم | - | - | - | - | - |
| T5/UL2 | باي تورش | نعم | - | - | نعم | نعم | - |
| T5 | تدفق Tensor 2 | نعم | - | - | - | - | - |
| T5/UL2 | تريتون الخلفية | نعم | - | - | نعم | نعم | - |
| T5 | TensorRT | نعم | - | - | نعم | نعم | - |
| T5-وزارة البيئة | باي تورش | نعم | - | - | نعم | نعم | - |
| محول سوين | باي تورش | نعم | نعم | - | - | - | - |
| محول سوين | TensorRT | نعم | نعم | - | - | - | - |
| فيتامين | باي تورش | نعم | نعم | - | - | - | - |
| فيتامين | TensorRT | نعم | نعم | - | - | - | - |
| جي بي تي-نيوإكس | باي تورش | نعم | - | - | نعم | نعم | - |
| جي بي تي-نيوإكس | تريتون الخلفية | نعم | - | - | نعم | نعم | - |
| بارت/مبارت | باي تورش | نعم | - | - | نعم | نعم | - |
| وي نت | سي ++ | نعم | - | - | - | - | - |
| ديبيرتا | تدفق Tensor 2 | نعم | - | - | مستمرة | مستمرة | - |
| ديبيرتا | باي تورش | نعم | - | - | مستمرة | مستمرة | - |
تم وضع المزيد من التفاصيل حول نماذج محددة في xxx_guide.md من docs/ ، حيث يعني xxx اسم النموذج. يتم وضع بعض الأسئلة الشائعة والإجابات الخاصة بها في docs/QAList.md . لاحظ أن نموذج Encoder وBERT متشابهان وقمنا بوضع الشرح في bert_guide.md معًا.
يسرد التعليمة البرمجية التالية بنية دليل FasterTransformer:
/src/fastertransformer: source code of FasterTransformer
|--/cutlass_extensions: Implementation of cutlass gemm/kernels.
|--/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.
|--/layers: Implementation of layer modules, like attention layer, ffn layer.
|--/models: Implementation of different models, like BERT, GPT.
|--/tensorrt_plugin: encapluate FasterTransformer into TensorRT plugin.
|--/tf_op: custom Tensorflow OP implementation
|--/th_op: custom PyTorch OP implementation
|--/triton_backend: custom triton backend implementation
|--/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils
/examples: C++, tensorflow and pytorch interface examples
|--/cpp: C++ interface examples
|--/pytorch: PyTorch OP examples
|--/tensorflow: TensorFlow OP examples
|--/tensorrt: TensorRT examples
/docs: Documents to explain the details of implementation of different models, and show the benchmark
/benchmark: Contains the scripts to run the benchmarks of different models
/tests: Unit tests
/templates: Documents to explain how to add a new model/example into FasterTransformer repo
لاحظ أن العديد من المجلدات تحتوي على العديد من المجلدات الفرعية لتقسيم النماذج المختلفة. يتم نقل أدوات التكميم إلى examples ، مثل examples/tensorflow/bert/bert-quantization/ و examples/pytorch/bert/bert-quantization-sparsity/ .
يوفر FasterTransformer بعض متغيرات البيئة الملائمة لتصحيح الأخطاء والاختبار.
FT_LOG_LEVEL : تتحكم هذه البيئة في مستوى السجل لرسائل تصحيح الأخطاء. مزيد من التفاصيل موجودة في src/fastertransformer/utils/logger.h . لاحظ أن البرنامج سيقوم بطباعة الكثير من الرسائل عندما يكون المستوى أقل من DEBUG وسيصبح البرنامج بطيئًا جدًا.FT_NVTX : إذا تم ضبطه على ON مثل FT_NVTX=ON ./bin/gpt_example ، فسيقوم البرنامج بإدراج علامة nvtx للمساعدة في تحديد ملف تعريف البرنامج.FT_DEBUG_LEVEL : إذا تم ضبطه على DEBUG ، فسيقوم البرنامج بتشغيل cudaDeviceSynchronize() بعد كل نواة. وبخلاف ذلك، سيتم تنفيذ النواة بشكل غير متزامن بشكل افتراضي. من المفيد تحديد موقع نقطة الخطأ أثناء التصحيح. لكن هذه العلامة تؤثر على أداء البرنامج بشكل كبير. لذا، يجب استخدامه فقط لتصحيح الأخطاء. إعدادات الأجهزة:
من أجل تشغيل المعيار التالي، نحتاج إلى تثبيت أداة حوسبة يونكس "bc" بواسطة
apt-get install bc تم الحصول على نتائج FP16 لـ TensorFlow عن طريق تشغيل benchmarks/bert/tf_benchmark.sh .
تم الحصول على نتائج INT8 لـ TensorFlow عن طريق تشغيل benchmarks/bert/tf_int8_benchmark.sh .
تم الحصول على نتائج FP16 لـ PyTorch عن طريق تشغيل benchmarks/bert/pyt_benchmark.sh .
تم الحصول على نتائج INT8 لـ PyTorch عن طريق تشغيل benchmarks/bert/pyt_int8_benchmark.sh .
يتم وضع المزيد من المعايير في docs/bert_guide.md .
يقارن الشكل التالي أداء الميزات المختلفة لـ FasterTransformer وFasterTransformer ضمن FP16 على T4.
بالنسبة لحجم الدفعة الكبير وطول التسلسل، يحقق كل من EFF-FT وFT-INT8-v2 سرعة مضاعفة. يمكن أن يؤدي استخدام FasterTransformer الفعال وint8v2 في نفس الوقت إلى تسريع 3.5x مقارنة بـ FasterTransformer FP16 للحالة الكبيرة.
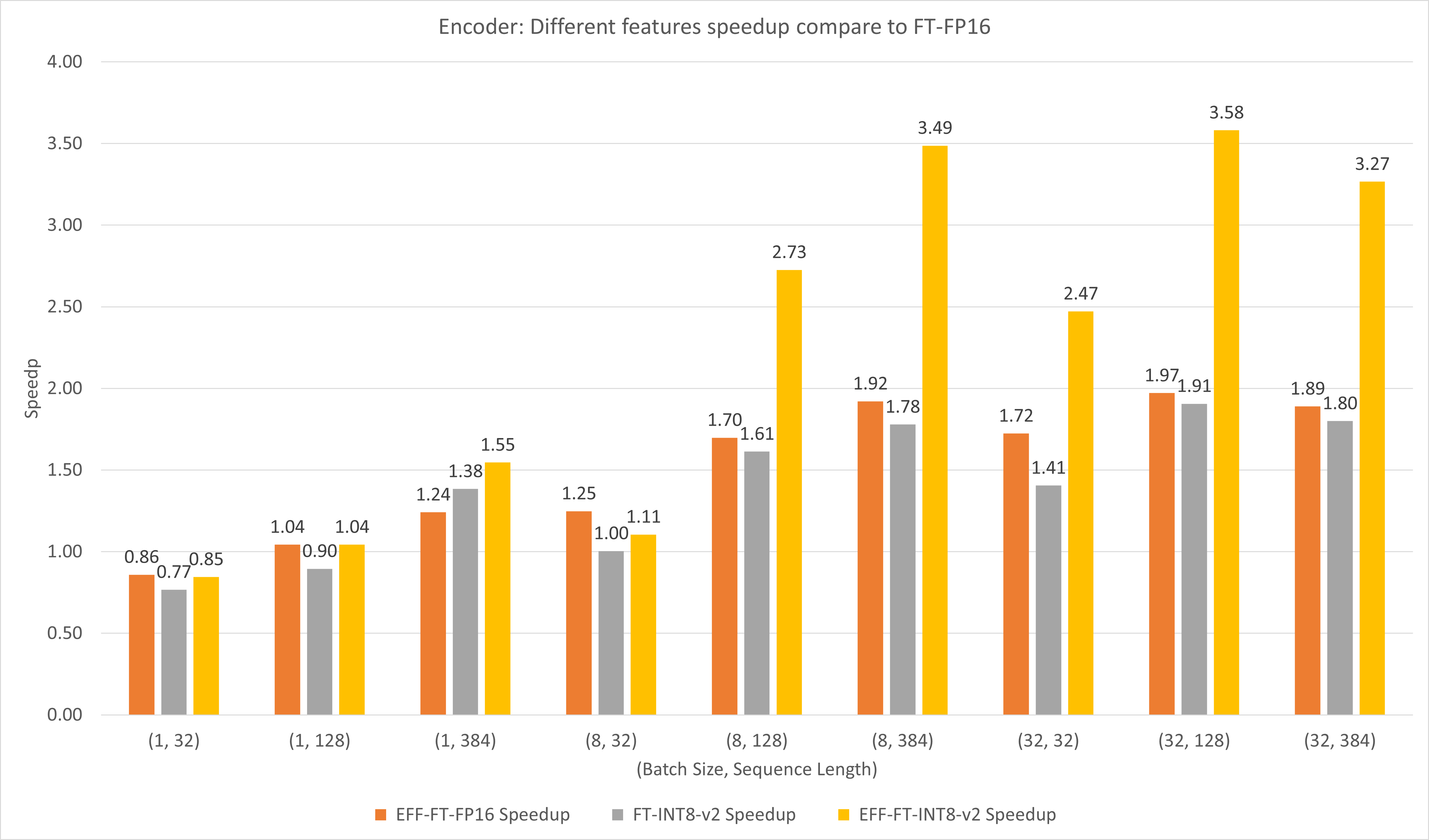
يقارن الشكل التالي أداء الميزات المختلفة لـ FasterTransformer وTensorFlow XLA ضمن FP16 على T4.
بالنسبة لحجم الدفعة الصغيرة وطول التسلسل، يمكن أن يؤدي استخدام FasterTransformer إلى تسريع 3x.
بالنسبة لحجم الدفعة الكبيرة وطول التسلسل، يمكن أن يؤدي استخدام FasterTransformer الفعال مع تكميم INT8-v2 إلى تسريع 5x.
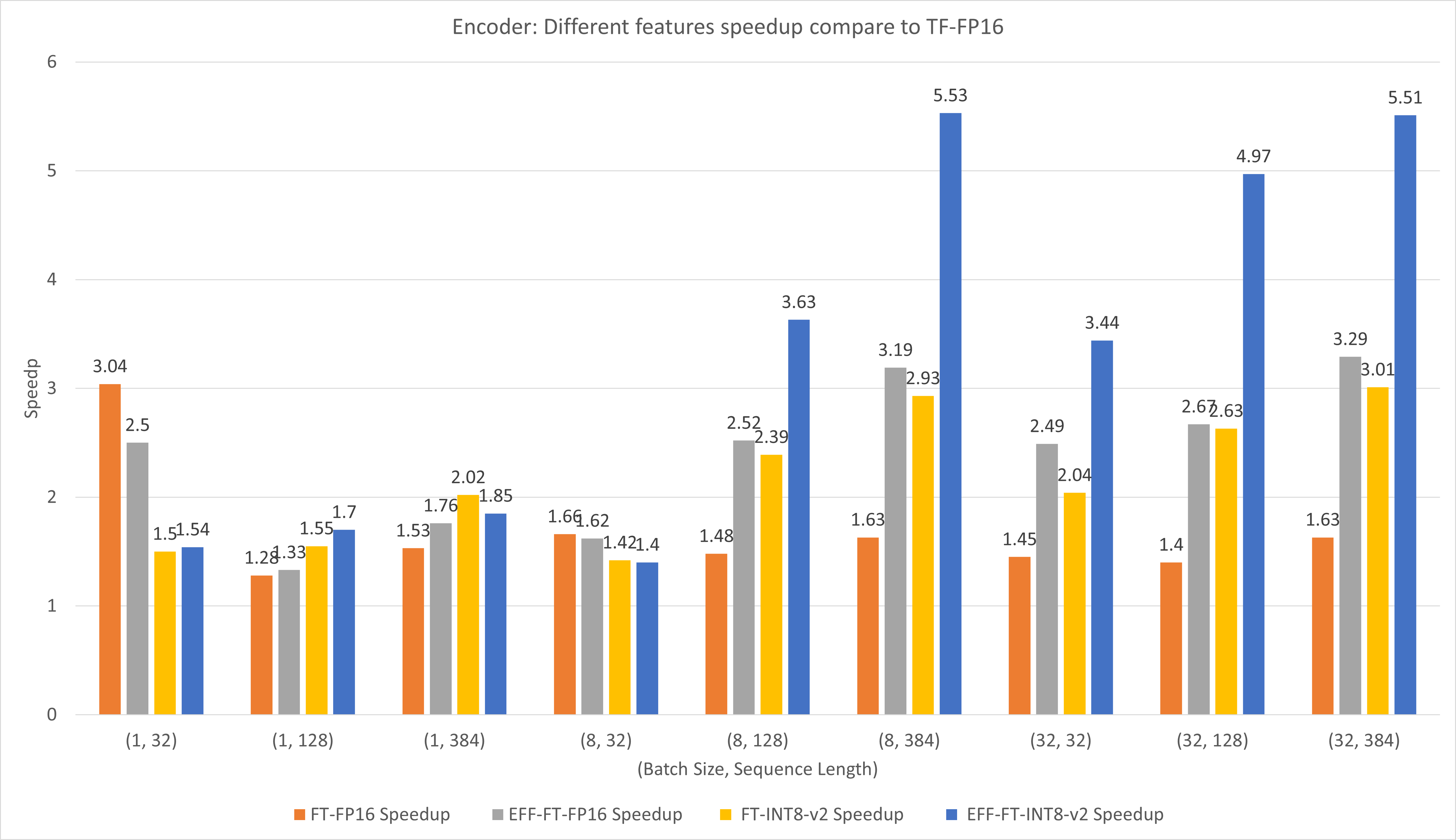
يقارن الشكل التالي أداء الميزات المختلفة لـ FasterTransformer وPyTorch TorchScript ضمن FP16 على T4.
بالنسبة لحجم الدفعة الصغيرة وطول التسلسل، يمكن أن يؤدي استخدام FasterTransformer CustomExt إلى تسريع 4x ~ 6x.
بالنسبة لحجم الدفعة الكبيرة وطول التسلسل، يمكن أن يؤدي استخدام FasterTransformer الفعال مع تكميم INT8-v2 إلى تسريع 5x.
تم الحصول على نتائج TensorFlow عن طريق تشغيل benchmarks/decoding/tf_decoding_beamsearch_benchmark.sh و benchmarks/decoding/tf_decoding_sampling_benchmark.sh
تم الحصول على نتائج PyTorch عن طريق تشغيل benchmarks/decoding/pyt_decoding_beamsearch_benchmark.sh .
في تجارب فك التشفير قمنا بتحديث المعلمات التالية:
يتم وضع المزيد من المعايير في docs/decoder_guide.md .
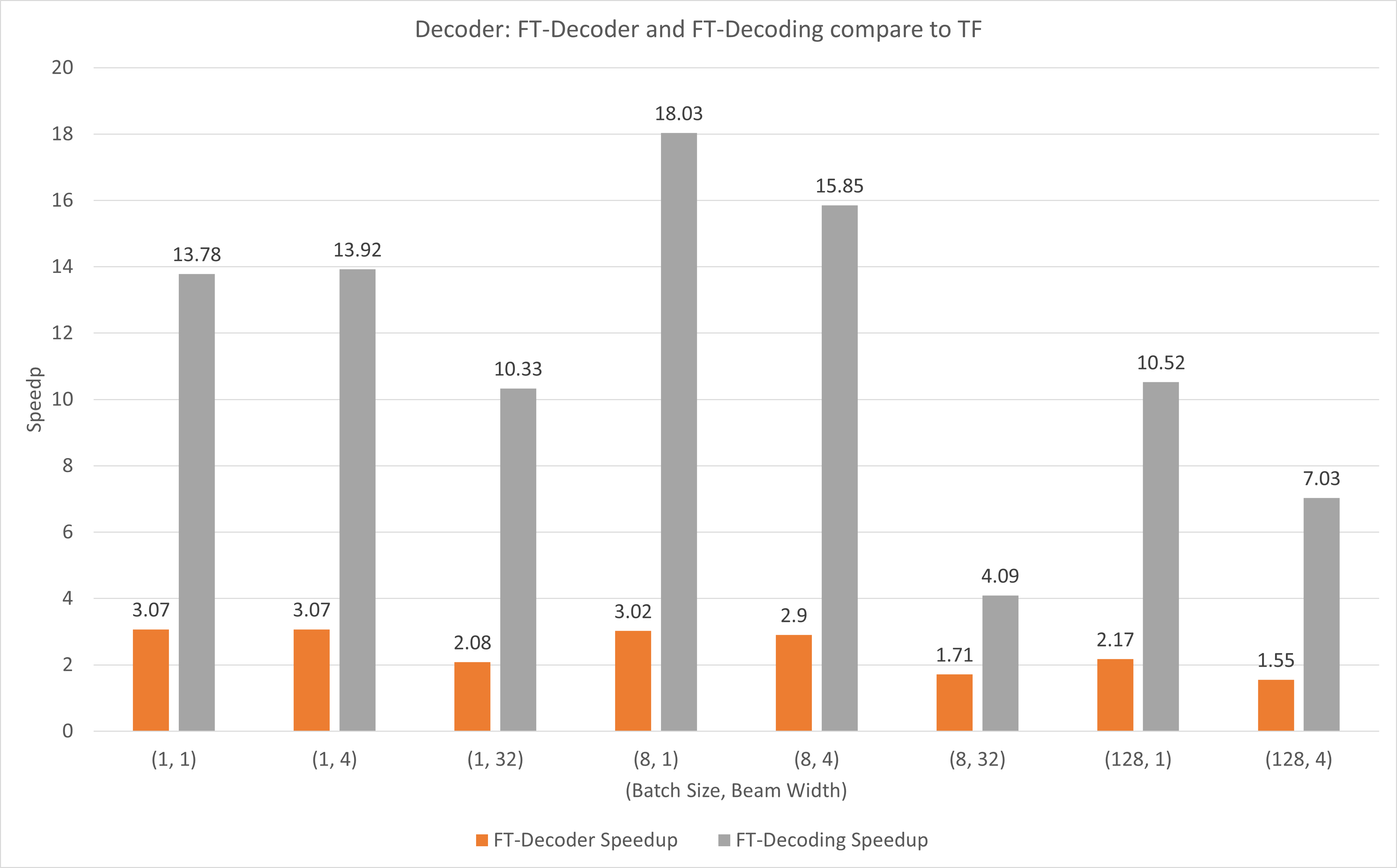
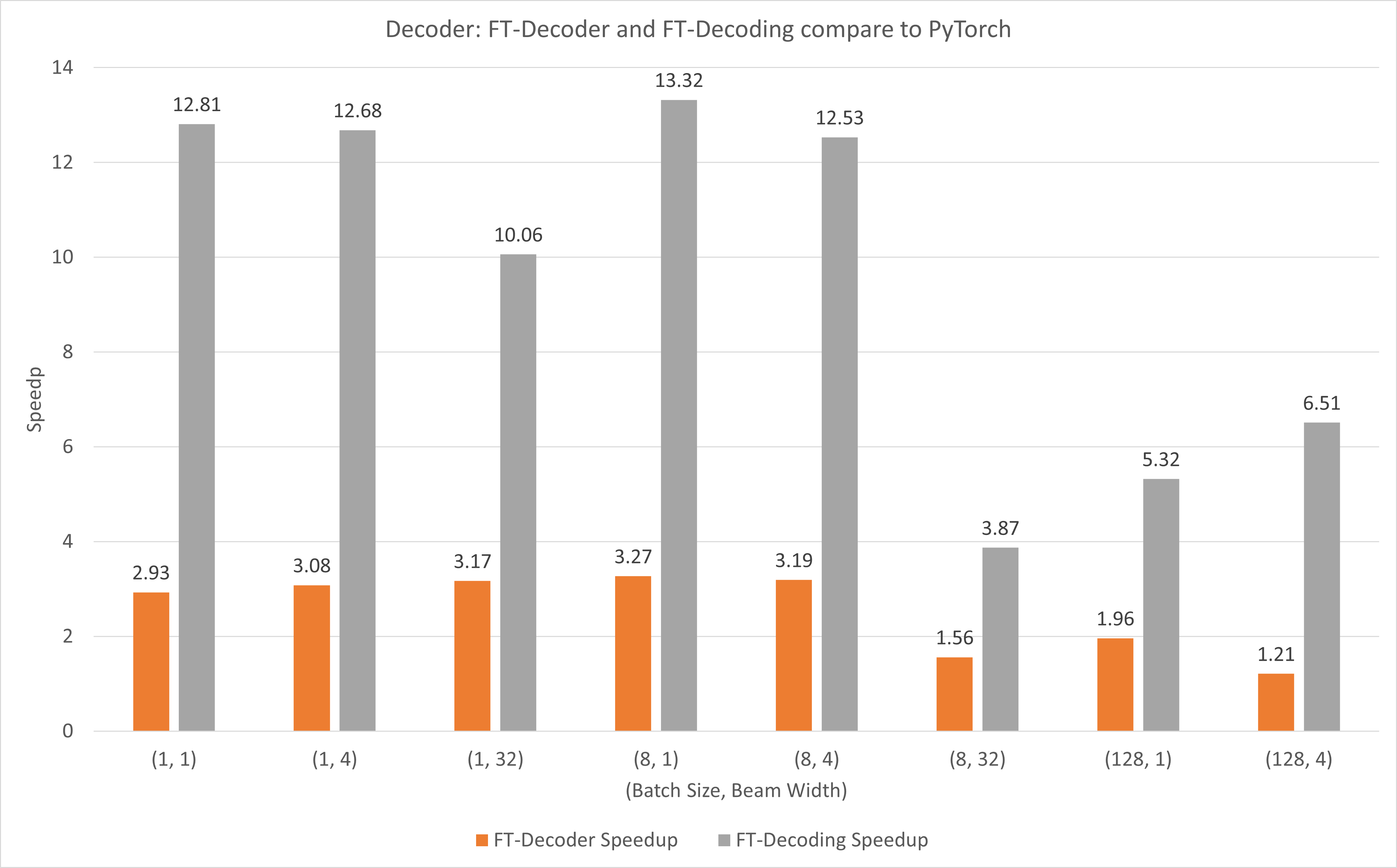
يوضح الشكل التالي مدى سرعة عمليتي FT-Decoder و FT-Decoding مقارنة بـ TensorFlow تحت FP16 مع T4. هنا، نستخدم إنتاجية ترجمة مجموعة اختبار لمنع اختلاف الرموز المميزة لكل طريقة. بالمقارنة مع TensorFlow، يوفر FT-Decoder سرعة 1.5x ~ 3x؛ بينما يوفر FT-Decoding سرعة تصل إلى 4x ~ 18x.
يوضح الشكل التالي مدى سرعة عمليتي FT-Decoder وFT-Decoding مقارنة بـ PyTorch تحت FP16 مع T4. هنا، نستخدم إنتاجية ترجمة مجموعة اختبار لمنع اختلاف الرموز المميزة لكل طريقة. بالمقارنة مع PyTorch، يوفر FT-Decoder سرعة تصل إلى 1.2x ~ 3x؛ بينما يوفر FT-Decoding سرعة تصل إلى 3.8x ~ 13x.
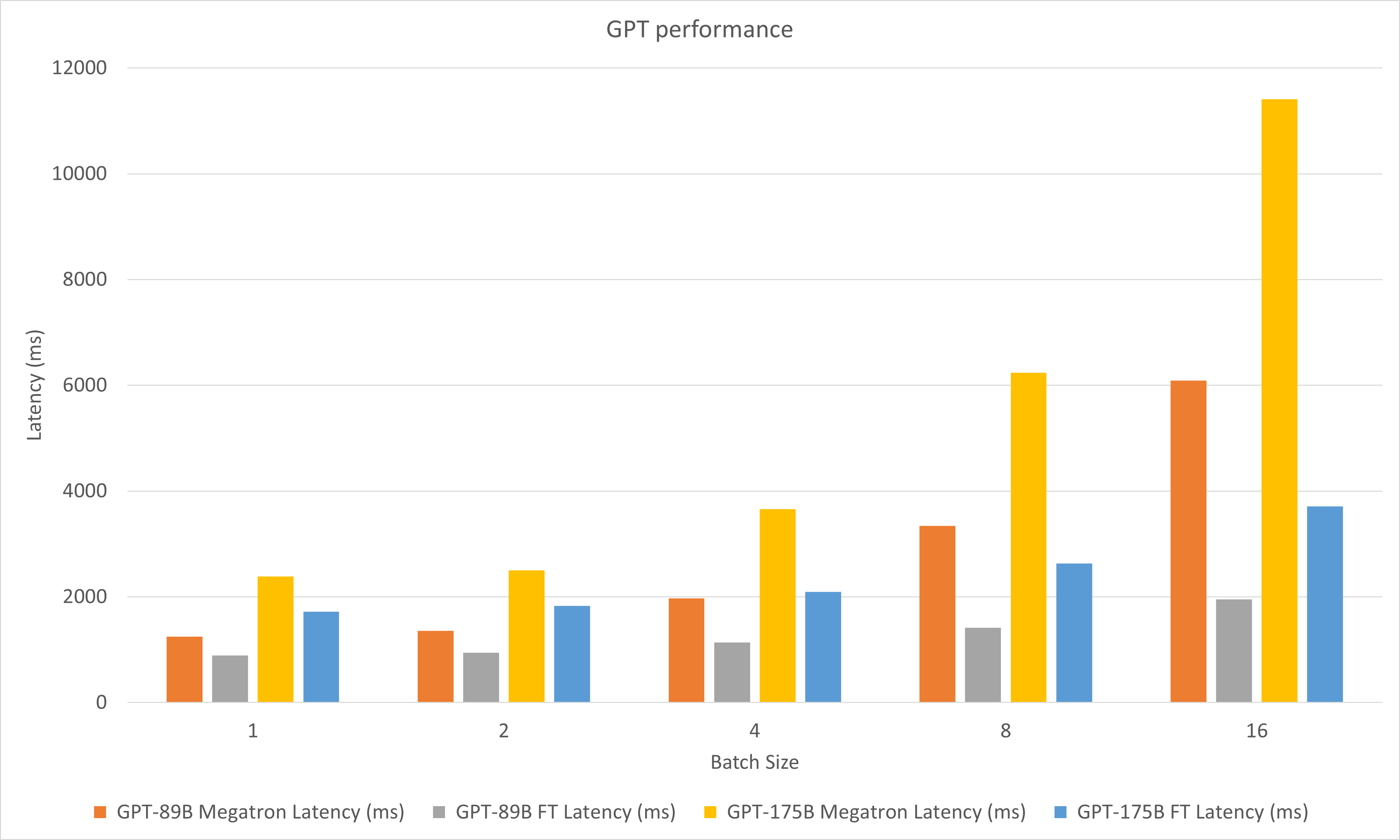
يقارن الشكل التالي أداء Megatron و FasterTransformer تحت FP16 على A100.
في تجارب فك التشفير قمنا بتحديث المعلمات التالية:
مايو 2023
يناير 2023
ديسمبر 2022
نوفمبر 2022
أكتوبر 2022
سبتمبر 2022
أغسطس 2022
يوليو 2022
يونيو 2022
مايو 2022
أبريل 2022
مارس 2022
stop_ids و ban_bad_ids في GPT-J.start_id الديناميكي و end_id في GPT-J وGPT وT5 وفك التشفير.فبراير 2022
ديسمبر 2021
نوفمبر 2021
أغسطس 2021
layer_para إلى pipeline_para .size_per_head 96، 160، 192، 224، 256 لطراز GPT.يونيو 2021
أبريل 2021
ديسمبر 2020
نوفمبر 2020
سبتمبر 2020
أغسطس 2020
يونيو 2020
مايو 2020
translate_sample.py .أبريل 2020
decoding_opennmt.h إلى decoding_beamsearch.hdecoding_sampling.hbert_transformer_op.h و bert_transformer_op.cu.cc في bert_transformer_op.ccdecoder.h و decoder.cu.cc في decoder.ccdecoding_beamsearch.h و decoding_beamsearch.cu.cc في decoding_beamsearch.ccbleu_score.py إلى utils . لاحظ أن نتيجة BLEU تتطلب python3.مارس 2020
translate_sample.py لتوضيح كيفية ترجمة جملة من خلال استعادة نموذج OpenNMT-tf المُدرب مسبقًا.فبراير 2020
يوليو 2019
import torch أولا. إذا حدث ذلك، فهذا يرجع إلى عدم توافق C++ ABI. قد تحتاج إلى التحقق من أن PyTorch المستخدم أثناء التجميع والتنفيذ هو نفسه، أو تحتاج إلى التحقق من كيفية تجميع PyTorch الخاص بك، أو إصدار مجلس التعاون الخليجي الخاص بك، وما إلى ذلك.

