PatrickStar
v0.4.6

راجع CHANGE_LOG.md.
أصبحت النماذج المدربة مسبقًا (PTM) هي النقطة الساخنة لكل من أبحاث البرمجة اللغوية العصبية وتطبيقات الصناعة. ومع ذلك، يتطلب تدريب أجهزة PTM موارد هائلة من الأجهزة، مما يجعلها في متناول جزء صغير فقط من الأشخاص في مجتمع الذكاء الاصطناعي. الآن، سيجعل PatrickStar تدريب PTM متاحًا للجميع!
يعد خطأ نفاد الذاكرة (OOM) بمثابة كابوس لكل مهندس يقوم بتدريب أجهزة PTM. غالبًا ما يتعين علينا تقديم المزيد من وحدات معالجة الرسومات لتخزين معلمات النموذج لمنع مثل هذه الأخطاء. يقدم PatrickStar حلاً أفضل لمثل هذه المشكلة. من خلال التدريب غير المتجانس (يستخدمه DeepSpeed Zero Stage 3 أيضًا)، يمكن لـ PatrickStar استخدام كل من ذاكرة وحدة المعالجة المركزية ووحدة معالجة الرسومات بشكل كامل بحيث يمكنك استخدام عدد أقل من وحدات معالجة الرسومات لتدريب نماذج أكبر.
فكرة باتريك هي مثل هذا. تختلف البيانات غير النموذجية (عمليات التنشيط بشكل أساسي) أثناء التدريب، لكن حلول التدريب غير المتجانسة الحالية تقوم بتقسيم بيانات النموذج بشكل ثابت إلى وحدة المعالجة المركزية ووحدة معالجة الرسومات. لاستخدام وحدة معالجة الرسومات بشكل أفضل، يقترح PatrickStar جدولة ديناميكية للذاكرة بمساعدة وحدة إدارة الذاكرة القائمة على القطع. تدعم إدارة الذاكرة في PatrickStar تفريغ كل شيء باستثناء جزء الحوسبة الحالي من النموذج إلى وحدة المعالجة المركزية لحفظ وحدة معالجة الرسومات. بالإضافة إلى ذلك، تعد إدارة الذاكرة المبنية على القطع فعالة للاتصال الجماعي عند التوسع في وحدات معالجة الرسومات المتعددة. راجع الورقة وهذا المستند للتعرف على الفكرة وراء PatrickStar.
في التجربة، يستطيع Patrickstar v0.4.3 تدريب نموذج معلمي يبلغ 18 مليار (18B) باستخدام وحدة معالجة الرسومات 8xTesla V100 وذاكرة وحدة معالجة الرسومات سعة 240 جيجابايت في عقدة مركز بيانات WeChat، التي تكون طوبولوجيا شبكتها على هذا النحو. يبلغ حجم PatrickStar ضعف حجم DeepSpeed. وأداء PatrickStar أفضل بالنسبة للموديلات ذات الحجم نفسه أيضًا. النجم هو PatrickStar v0.4.3. تشير الأعماق إلى أداء DeepSpeed v0.4.3 باستخدام المثال الرسمي DeepSpeed، مثال المرحلة Zero3 مع فتح تحسينات التنشيط افتراضيًا.

قمنا أيضًا بتقييم PatrickStar v0.4.3 على عقدة واحدة من A100 SuperPod. يمكنه تدريب طراز 68B على 8xA100 مع ذاكرة وحدة المعالجة المركزية سعة 1 تيرابايت، وهي أكبر بمقدار 6 مرات من DeepSpeed v0.5.7. إلى جانب مقياس النموذج، يعد PatrickStar أكثر كفاءة من DeepSpeed. البرامج النصية القياسية موجودة هنا.

يتم نشر نتائج الأداء التفصيلية حول مركز بيانات WeChat AI وNVIDIA SuperPod على مستند Google هذا.
قم بتوسيع نطاق PatrickStar إلى أجهزة متعددة (عقدة) على SuperPod. لقد نجحنا في تدريب GPT3-175B على 32 GPU. على حد علمنا، هذا هو أول عمل يتم فيه تشغيل GPT3 على مجموعة GPU الصغيرة هذه. استخدمت Microsoft 10000 V100 لـ GPT3. يمكنك الآن ضبطه أو حتى تدريبه مسبقًا على وحدة معالجة الرسومات 32 A100، وهو أمر مذهل!

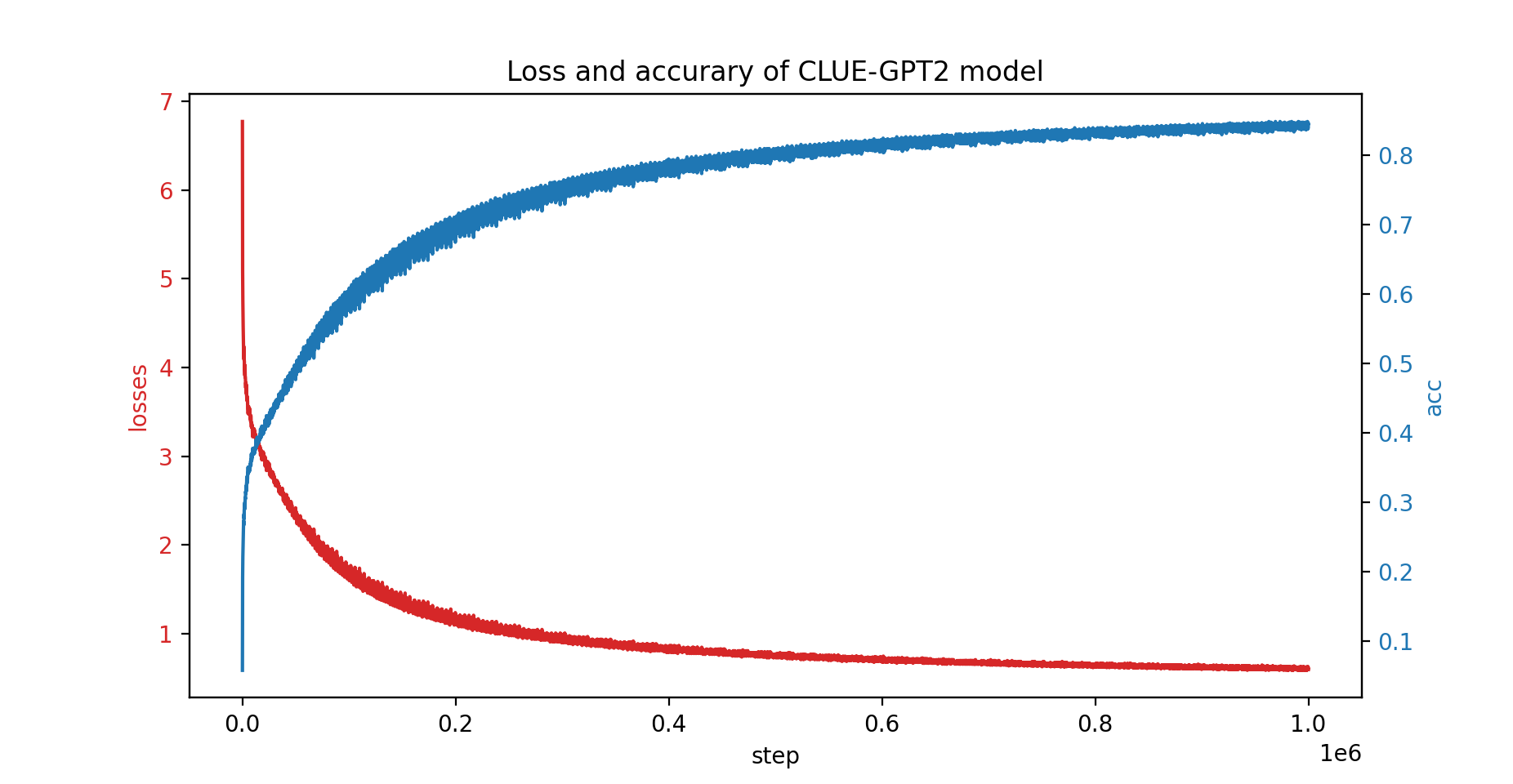
لقد قمنا أيضًا بتدريب نموذج CLUE-GPT2 باستخدام PatrickStar، ويظهر منحنى الخسارة والدقة أدناه:
pip install .لاحظ أن PatrickStar يتطلب إصدار gcc 7 أو أعلى. يمكنك أيضًا استخدام صور NVIDIA NGC، حيث تم اختبار الصورة التالية:
docker pull nvcr.io/nvidia/pytorch:21.06-py3يعتمد PatrickStar على PyTorch، مما يجعل من السهل ترحيل مشروع pytorch. فيما يلي مثال على PatrickStar:
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () نحن نستخدم نفس تنسيق config مثل تكوين DeepSpeed JSON، والذي يتضمن بشكل أساسي معلمات المحسن ومقياس الخسارة وبعض التكوينات الخاصة بـ PatrickStar.
للحصول على شرح تفصيلي للمثال أعلاه، يرجى مراجعة الدليل هنا
لمزيد من الأمثلة، يرجى التحقق هنا.
يتوفر هنا البرنامج النصي القياسي للبدء السريع. يتم تنفيذه باستخدام البيانات التي تم إنشاؤها بشكل عشوائي. لذلك لا تحتاج إلى إعداد البيانات الحقيقية. كما أظهر أيضًا جميع تقنيات التحسين لـ patrickstar. لمزيد من حيل التحسين التي تعمل على تشغيل المعيار، راجع خيارات التحسين.
ترخيص BSD 3-بنود
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{جيارويفانغ، زيلينزو، جوزفيو}@tencent.com
مدعوم من فريق WeChat AI، فريق Tencent NLP Oteam.


