xcodec
1.0.0
برنامج الترميز الدلالي والصوتي الموحد لنموذج اللغة الصوتية.
العنوان : أهمية برنامج الترميز: استكشاف النقص الدلالي في برنامج الترميز لنموذج اللغة الصوتية
المؤلفون : Zhen Ye، Peiwen Sun، Jiahe Lei، Hongzhan Lin، Xu Tan، Zheqi Dai، Qiuqiang Kong، Jianyi Chen، Jiahao Pan، Qifeng Liu، Yike Guo*، Wei Xue*
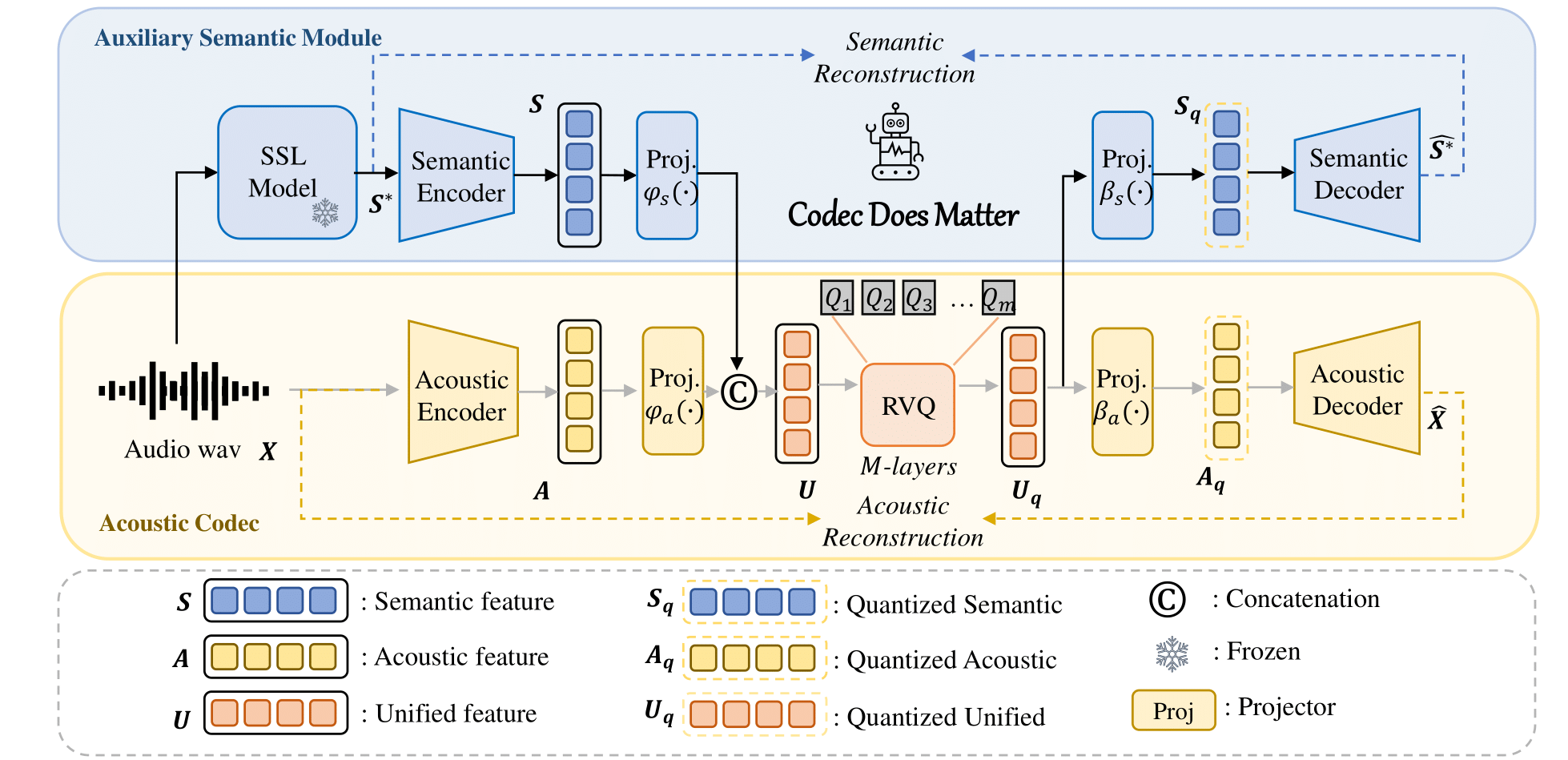
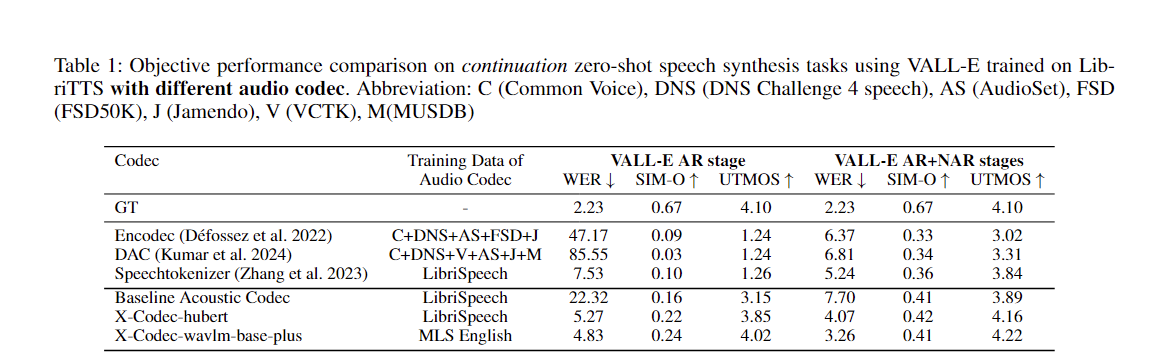
يمكنك بسهولة تطبيق نهجنا لتحسين أي برنامج ترميز صوتي موجود:
على سبيل المثال
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) لمزيد من التفاصيل، يرجى الرجوع إلى الكود الخاص بنا.
؟ روابط إلى مركز نموذج Huggingface.
| اسم النموذج | تعانق الوجه | التكوين | النموذج الدلالي | اِختِصاص | بيانات التدريب |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | ؟ | ؟ | ؟ قاعدة هوبرت | خطاب | خطاب ليبراسي |
| xcodec_wavlm_mls (غير مذكور في الورق) | ؟ | ؟ | ؟ Wavlm-قاعدة زائد | خطاب | إم إل إس إنجليزي |
| xcodec_wavlm_more_data (غير مذكور في الورق) | ؟ | ؟ | ؟ Wavlm-قاعدة زائد | خطاب | اللغة الإنجليزية MLS + البيانات الداخلية |
| xcodec_hubert_general_audio | ؟ | ؟ | ?Hubert-base-general-audio | الصوت العام | 200 ألف ساعة من البيانات الداخلية |
| xcodec_hubert_general_audio_more_data (غير مذكور في الورقة) | ؟ | ؟ | ?Hubert-base-general-audio | الصوت العام | بيانات أكثر توازنا |
لتشغيل الاستدلال، قم أولاً بتنزيل النموذج والتكوين من Hugging Face.
python inference.pyقم بإعداد ملف التدريب وملف التحقق من الصحة في ملف config. يجب أن يسرد الملف المسارات إلى ملفاتك الصوتية:
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...ثم:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.pyأود أن أتقدم بشكر خاص لمؤلفي Uniaudio وDAC، نظرًا لأن قاعدة التعليمات البرمجية الخاصة بنا مستعارة بشكل أساسي من Uniaudio وDAC.
إذا وجدت هذا الريبو مفيدًا، فيرجى التفكير في الاستشهاد بالتنسيق التالي:
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

