EasyEdit
1.0.0

إطار تحرير معرفي سهل الاستخدام لنماذج اللغات الكبيرة.
التثبيت • التشغيل السريع • المستند • الورق • العرض التوضيحي • المعيار القياسي • المساهمون • الشرائح • الفيديو • المميز بواسطة AK
23/10/2024، يدمج EasyEdit طرق فك التشفير المقيدة من التحرير التوجيهي للتخفيف من الهلوسة في LLM وMLLM، مع معلومات مفصلة متاحة في DoLa وDeCo.
2024-09-26,؟؟ لقد تم قبول بحثنا "WISE: إعادة التفكير في ذاكرة المعرفة لتحرير النماذج مدى الحياة لنماذج اللغات الكبيرة" من قبل NeurIPS 2024 .
2024-09-20,؟؟ تم قبول أوراقنا البحثية: "آليات المعرفة في نماذج اللغات الكبيرة: مسح ومنظور" و"تحرير المعرفة المفاهيمية لنماذج اللغات الكبيرة" من خلال نتائج EMNLP 2024 .
29-07-2024، أضاف EasyEdit خوارزمية تحرير نموذج جديدة EMMET، والتي تعمل على تعميم ROME على إعداد الدفعة. يسمح هذا بشكل أساسي بإجراء تعديلات مجمعة باستخدام وظيفة فقدان ROME.
23-07-2024، نصدر ورقة بحثية جديدة: "آليات المعرفة في النماذج اللغوية الكبيرة: دراسة ومنظور"، والتي تستعرض كيفية اكتساب المعرفة واستخدامها وتطورها في النماذج اللغوية الكبيرة. قد يوفر هذا الاستطلاع الآليات الأساسية لمعالجة (تحرير) المعرفة بدقة وكفاءة في ماجستير إدارة الأعمال.
2024-06-04,؟؟ لقد تم قبول ورق EasyEdit من خلال المسار التوضيحي لنظام ACL 2024 .
بتاريخ 03-06-2024، أصدرنا ورقة بحثية بعنوان "WISE: إعادة التفكير في ذاكرة المعرفة لتحرير النماذج مدى الحياة لنماذج اللغات الكبيرة" ، إلى جانب تقديم مهمة تحرير جديدة: تحرير المعرفة المستمر وطريقة التحرير مدى الحياة المقابلة التي تسمى WISE.
24-04-2024، أعلنت EasyEdit عن دعم طريقة ROME لـ Llama3-8B . يُنصح المستخدمون بتحديث حزمة المحولات الخاصة بهم إلى الإصدار 4.40.0.
29-03-2024، قدمت EasyEdit دعم التراجع لـ GRACE . للحصول على مقدمة مفصلة، راجع وثائق EasyEdit. ستتضمن التحديثات المستقبلية تدريجيًا دعم التراجع عن الطرق الأخرى.
22-03-2024، تم إصدار ورقة بحثية جديدة بعنوان "إزالة السموم من نماذج اللغات الكبيرة عبر تحرير المعرفة" ، إلى جانب مجموعة بيانات جديدة تسمى SafeEdit وطريقة جديدة لإزالة السموم تسمى DINM.
12-03-2024، تم إصدار ورقة بحثية أخرى بعنوان "تحرير المعرفة المفاهيمية لنماذج اللغات الكبيرة" ، مقدمة مجموعة بيانات جديدة تسمى ConceptEdit.
01-03-2024، أضاف EasyEdit دعمًا لطريقة جديدة تسمى FT-M . تتضمن هذه الطريقة تدريب طبقة MLP محددة باستخدام فقدان الإنتروبيا المتقاطعة على الإجابة المستهدفة وإخفاء النص الأصلي . إنه يتفوق على تنفيذ FT-L في روما. والشكر لمؤلف العدد رقم 173 على نصائحه.
27-02-2024، أضاف EasyEdit دعمًا لطريقة جديدة تسمى InstructEdit، مع التفاصيل الفنية المقدمة في المقالة "InstructEdit: تحرير المعرفة القائم على التعليمات لنماذج اللغات الكبيرة" .
Accelerate .دراسة شاملة لتحرير المعرفة لنماذج اللغات الكبيرة [ورقة] [معيار] [كود]
IJCAI 2024 البرنامج التعليمي جوجل درايف
COLING 2024 البرنامج التعليمي جوجل درايف
AAAI 2024 البرنامج التعليمي جوجل درايف
البرنامج التعليمي لـ AACL 2023 [Google Drive] [Baidu Pan]
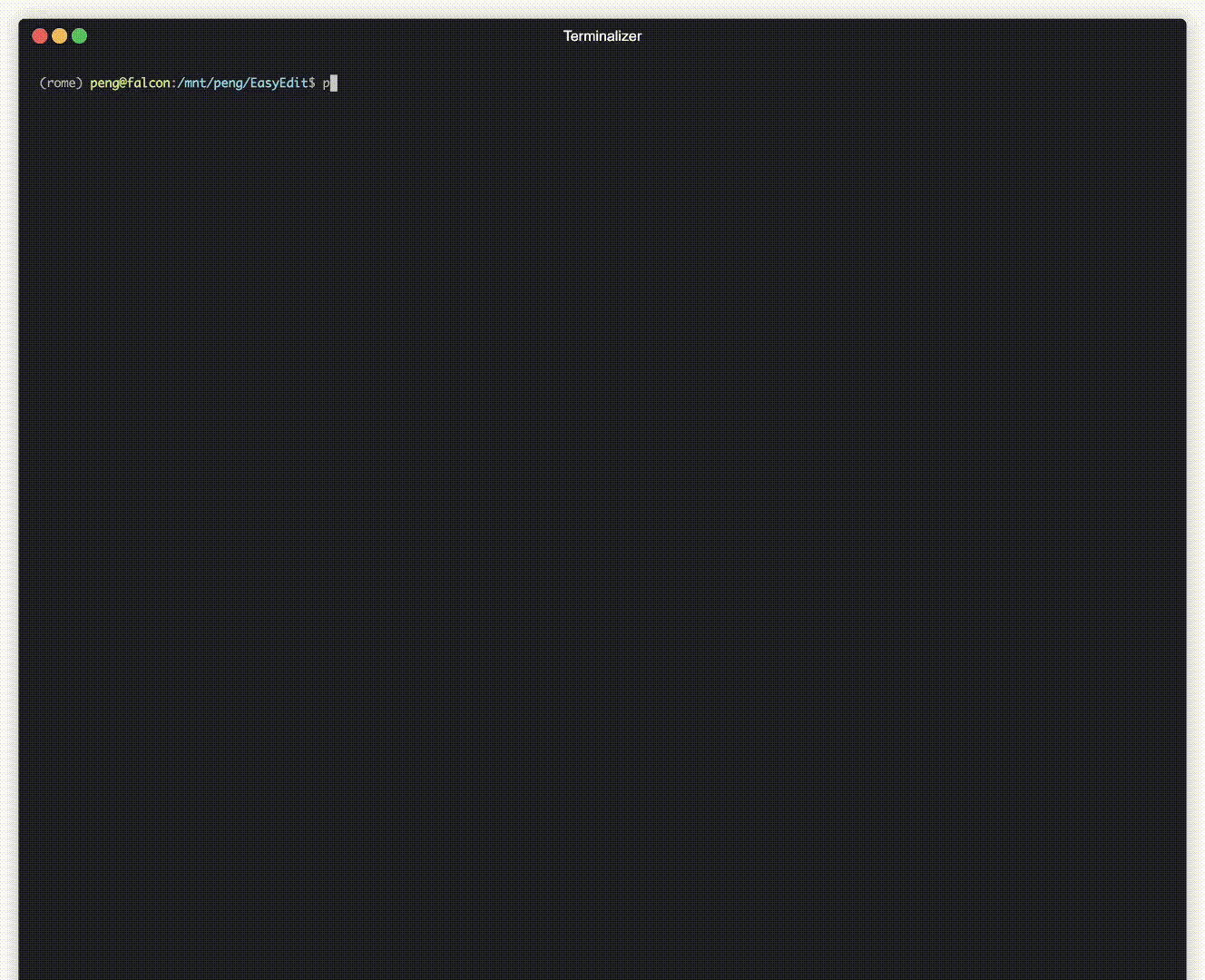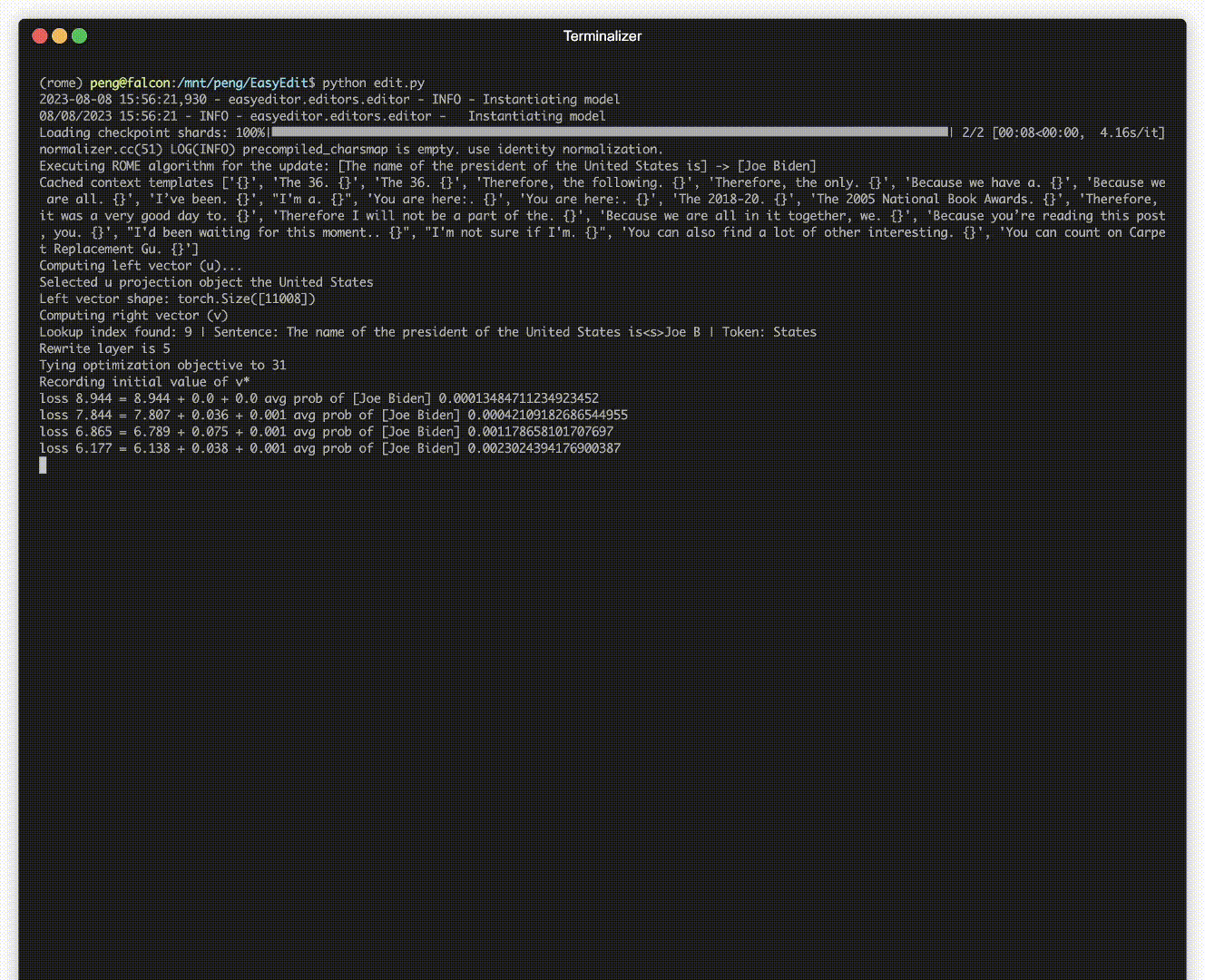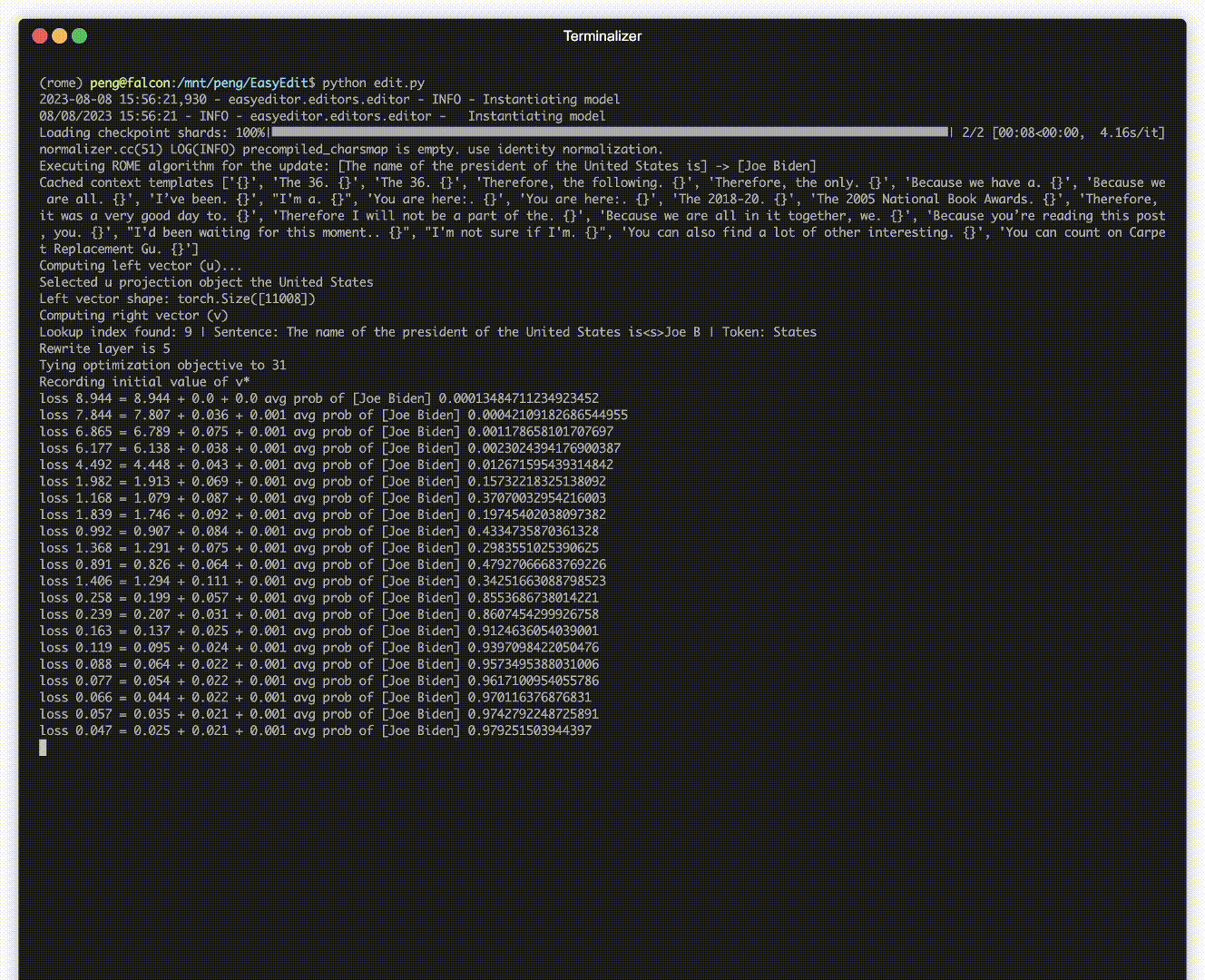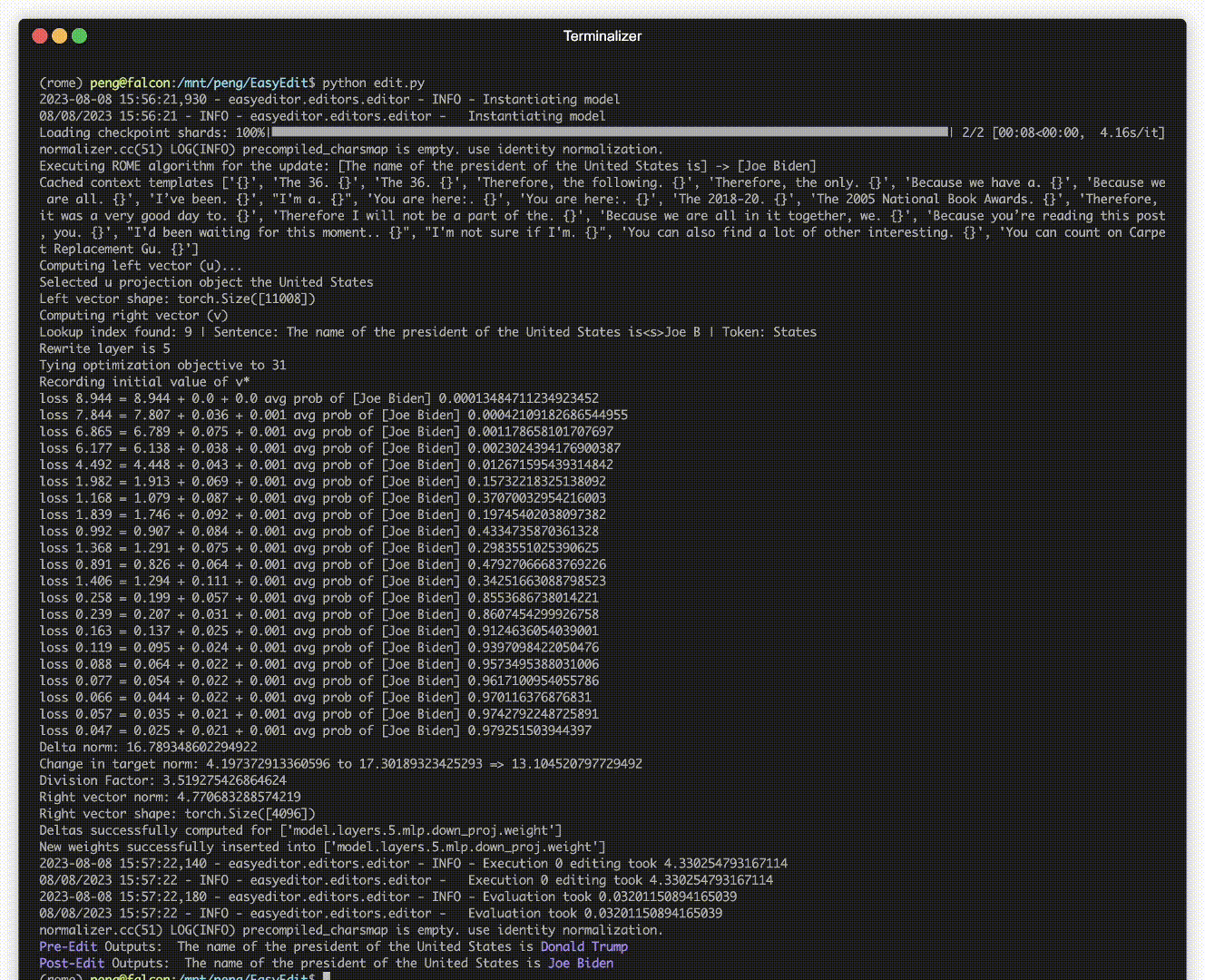
هناك مظاهرة للتحرير. يتم إنشاء ملف GIF بواسطة Terminalizer.
نحن نقدم دفتر Jupyter سهل الاستخدام! فهو يسمح لك بتعديل معرفة LLM بالرئيس الأمريكي، والتحول من بايدن إلى ترامب وحتى العودة إلى بايدن. يتضمن ذلك طرقًا مثل WISE وAlphaEdit وAdaLoRA والتحرير المستند إلى المطالبة.
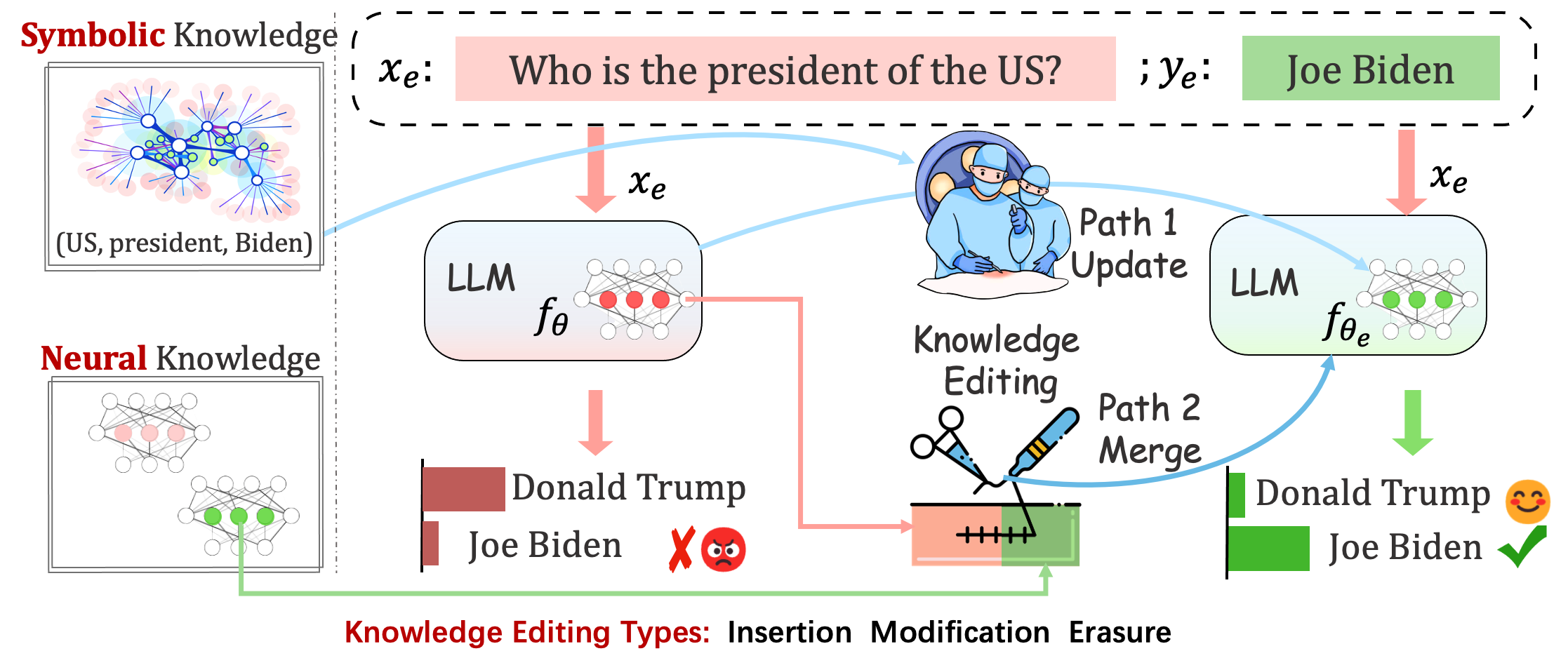
قد تستمر النماذج المنشورة في ارتكاب أخطاء غير متوقعة. على سبيل المثال، من المعروف أن طلاب ماجستير القانون يهلوسون ، ويديمون التحيز ، ويتحللون في الواقع ، لذلك يجب أن نكون قادرين على تعديل سلوكيات محددة للنماذج المدربة مسبقًا.
يهدف تحرير المعرفة إلى ضبط النموذج الأساسي
تقييم أداء النموذج بعد تعديل واحد. يقوم النموذج بإعادة تحميل الأوزان الأصلية (على سبيل المثال، يتجاهل LoRA أوزان المحول) بعد تعديل واحد. يجب عليك تعيين sequential_edit=False
يتطلب هذا التحرير بشكل تسلسلي ، ويتم إجراء التقييم بعد تطبيق كافة التحديثات المعرفية:
يقوم بإجراء تعديلات على المعلمات sequential_edit=True : README (لمزيد من التفاصيل).
دون التأثير على سلوك النموذج على عينات غير ذات صلة، فإن الهدف النهائي هو إنشاء نموذج محرر
مهمة التحرير للتسمية التوضيحية للصورة والإجابة على الأسئلة المرئية . التمهيدي
تأخذ المهمة المقترحة المحاولة الأولية لتحرير شخصيات LLMs من خلال تحرير آرائهم حول موضوعات محددة، نظرًا لأن آراء الفرد يمكن أن تعكس جوانب من سمات شخصيتهم. نحن نعتمد على نظرية الخمسة الكبار الراسخة كأساس لبناء مجموعة البيانات الخاصة بنا وتقييم تعبيرات شخصية حاملي شهادة الماجستير في القانون. التمهيدي
تقييم
على أساس اللوجيستات
على أساس الجيل
أثناء تقييم Acc و TPEI ، يمكنك تنزيل المصنف المدرّب من هنا.
تؤثر عملية تحرير المعرفة بشكل عام على التنبؤات الخاصة بمجموعة واسعة من المدخلات المرتبطة بشكل وثيق بمثال التحرير، والتي تسمى نطاق التحرير .
يجب أن يقوم التحرير الناجح بضبط سلوك النموذج ضمن نطاق التحرير مع بقاء المدخلات غير ذات الصلة:
Reliability : معدل نجاح التحرير باستخدام واصف تحرير معينGeneralization : معدل نجاح التحرير ضمن نطاق التحريرLocality : ما إذا كانت مخرجات النموذج تتغير بعد تحرير المدخلات غير ذات الصلةPortability : معدل نجاح التحرير للاستدلال/التطبيق (قفزة واحدة، مرادف، تعميم منطقي)Efficiency : استهلاك الوقت والذاكرة EasyEdit عبارة عن حزمة Python لتحرير نماذج اللغات الكبيرة (LLM) مثل GPT-J و Llama و GPT-NEO و GPT2 و T5 (نماذج الدعم من 1B إلى 65B )، والهدف منها هو تغيير سلوك LLMs بكفاءة ضمن نطاق مجال معين دون التأثير سلبًا على الأداء عبر المدخلات الأخرى. لقد تم تصميمه ليكون سهل الاستخدام وسهل التوسيع.
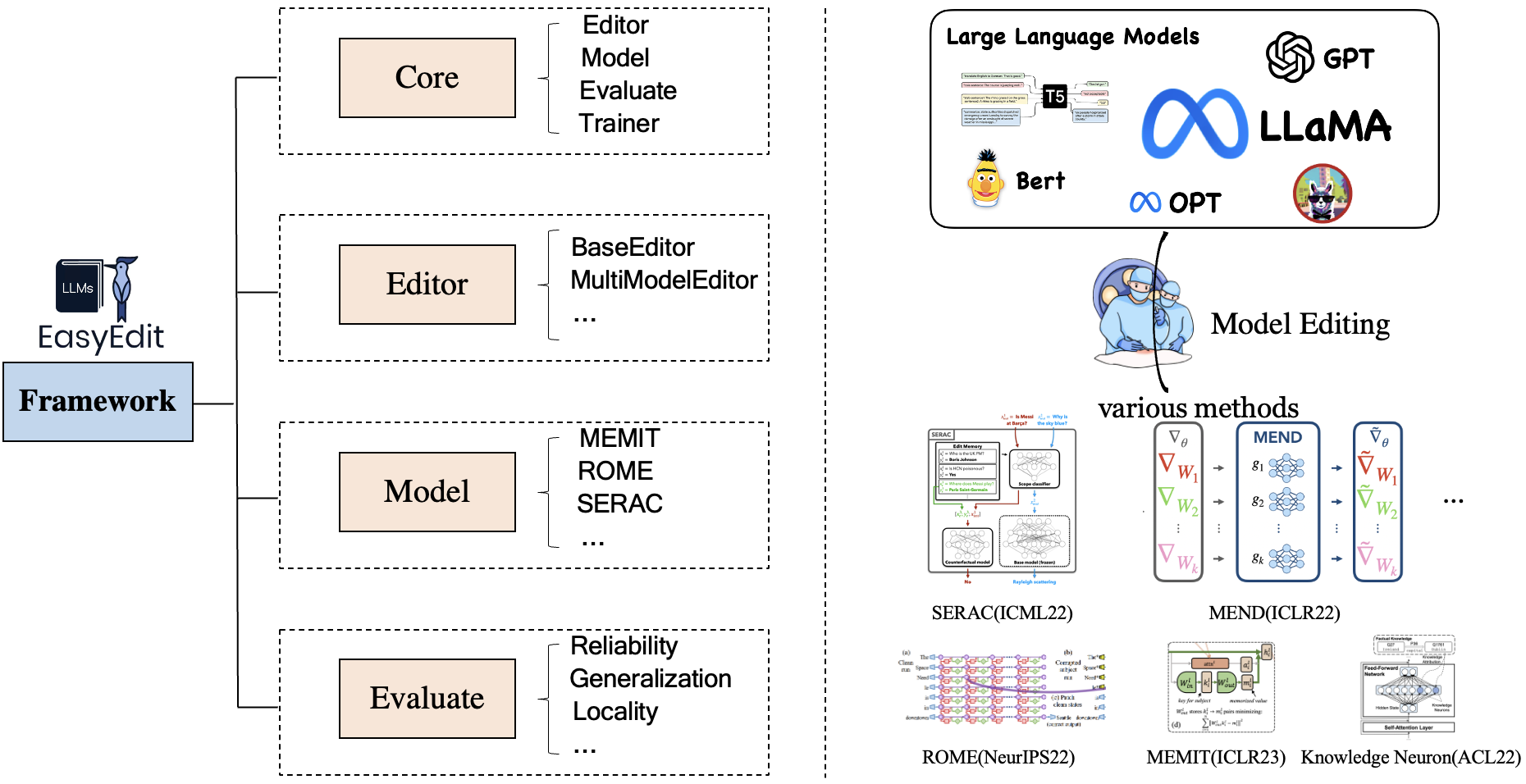
يحتوي EasyEdit على إطار عمل موحد للمحرر والطريقة والتقييم ، والذي يمثل على التوالي سيناريو التحرير وتقنية التحرير وطريقة التقييم.
يتكون كل سيناريو لتحرير المعرفة من ثلاثة مكونات:
Editor : مثل BaseEditor ( المعرفة الواقعية ومحرر الإنشاء ) لـ LM وMultiModalEditor ( المعرفة المتعددة الوسائط ).Method : تقنية تحرير المعرفة المحددة المستخدمة (مثل ROME ، MEND ، ..).Evaluate : مقاييس لتقييم أداء تحرير المعرفة.Reliability Generalization Locality Portabilityتقنيات تحرير المعرفة المدعومة حاليًا هي كما يلي:
ملاحظة 1: نظرًا للتوافق المحدود لمجموعة الأدوات هذه، فإن بعض طرق تحرير المعرفة بما في ذلك T-Patcher وKE وCaliNet غير مدعومة.
ملاحظة 2: وبالمثل، فإن طريقة MALMEN مدعومة جزئيًا فقط لنفس الأسباب وسيستمر تحسينها.
يمكنك اختيار طرق تحرير مختلفة وفقًا لاحتياجاتك الخاصة.
| طريقة | T5 | جي بي تي-2 | جي بي تي-ي | جي بي تي-نيو | اللاما | بايتشوان | ChatGLM | المتدربLM | كوين | ميسترال |
|---|---|---|---|---|---|---|---|---|---|---|
| قدم | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| أدالورا | ✅ | ✅ | ||||||||
| سيراك | ✅ | ✅ | ✅ | ✅ | ||||||
| آيك | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| إصلاح | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| كن | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| روما | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ص-روما | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| ميت | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| إيميت | ✅ | ✅ | ✅ | |||||||
| جمال | ✅ | ✅ | ✅ | |||||||
| ميلو | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| تحرير | ✅ | ✅ | ||||||||
| دينم | ✅ | ✅ | ✅ | |||||||
| حكيم | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| تحرير ألفا | ✅ | ✅ | ✅ |
❗️❗️ إذا كنت تنوي استخدام ميسترال، يرجى تحديث مكتبة
transformersإلى الإصدار 4.34.0 يدويًا. يمكنك استخدام الكود التالي:pip install transformers==4.34.0.
| عمل | وصف | طريق |
|---|---|---|
| تحرير | InstructEdit: تحرير المعرفة القائم على التعليمات لنماذج اللغات الكبيرة | بداية سريعة |
| دينم | إزالة السموم من نماذج اللغة الكبيرة عن طريق تحرير المعرفة | بداية سريعة |
| حكيم | WISE: إعادة التفكير في ذاكرة المعرفة لتحرير النماذج مدى الحياة لنماذج اللغات الكبيرة | بداية سريعة |
| تحرير المفهوم | تحرير المعرفة المفاهيمية لنماذج اللغات الكبيرة | بداية سريعة |
| MMEdit | هل يمكننا تحرير نماذج اللغات الكبيرة متعددة الوسائط؟ | بداية سريعة |
| تحرير الشخصية | تحرير الشخصية لنماذج اللغات الكبيرة | بداية سريعة |
| اِسْتَدْعَى | أساليب تحرير المعرفة المبنية على PROMPT | بداية سريعة |
المعيار: KnowEdit [احتضان الوجه] [WiseModel] [ModelScope]
❗️❗️ تجدر الإشارة إلى أنه تم إنشاء KnowEdit من خلال إعادة تنظيم وتوسيع مجموعات البيانات الموجودة بما في ذلك WikiBio و ZsRE و WikiData Counterfact و WikiData حديث و convsent و Sanitation لإجراء تقييم شامل لتحرير المعرفة. شكر خاص لبناة ومشرفي مجموعات البيانات تلك.
يرجى ملاحظة أن Counterfact وWikiData Counterfact ليسا نفس مجموعة البيانات.
| مهمة | إدراج المعرفة | تعديل المعرفة | محو المعرفة | |||
|---|---|---|---|---|---|---|
| مجموعات البيانات | ويكي الأخيرة | ZsRE | ويكيبيو | ويكي بيانات مضادة | موافق | الصرف الصحي |
| يكتب | حقيقة | إجابة السؤال | هلوسة | حقيقة مضادة | المشاعر | معلومات غير مرغوب فيها |
| # يدرب | 570 | 10.000 | 592 | 1,455 | 14,390 | 80 |
| # امتحان | 1,266 | 1301 | 1,392 | 885 | 800 | 80 |
نحن نقدم نصوصًا تفصيلية للمستخدم لاستخدام KnowEdit بسهولة، يرجى الرجوع إلى الأمثلة.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| dataset | HuggingFace | نموذج حكيم | ModelScope | وصف |
|---|---|---|---|---|
| CKnowEdit | [المعانقة الوجه] | [النموذج الحكيم] | [موديلسكوب] | مجموعة بيانات لتحرير المعرفة الصينية |
CKnowEdit هي مجموعة بيانات عالية الجودة باللغة الصينية لتحرير المعرفة والتي تتميز بدرجة عالية باللغة الصينية، حيث يتم الحصول على جميع البيانات من قواعد المعرفة الصينية. لقد تم تصميمه بدقة لتمييز الفروق الدقيقة والتحديات الكامنة في فهم اللغة الصينية من خلال LLMs الحاليين، مما يوفر موردًا قويًا لتحسين المعرفة الخاصة باللغة الصينية داخل LLMs.
أوصاف الحقول للبيانات في CKnowEdit هي كما يلي:
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| dataset | جوجل درايف | بايدونيتديسك | وصف |
|---|---|---|---|
| ZsRE زائد | [جوجل درايف] | [بايدونيت ديسك] | الإجابة على الأسئلة في مجموعة البيانات باستخدام إعادة صياغة الأسئلة |
| مضاد زائد | [جوجل درايف] | [بايدونيت ديسك] | مجموعة بيانات مضادة باستخدام استبدال الكيان |
نحن نقدم مجموعات بيانات zsre وcounterfact للتحقق من فعالية تحرير المعرفة. يمكنك تنزيلها هنا. [جوجل درايف]، [بايدونيت ديسك].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse| dataset | جوجل درايف | مجموعة بيانات HuggingFace | وصف |
|---|---|---|---|
| تحرير المفهوم | [جوجل درايف] | [مجموعة بيانات HuggingFace] | مجموعة بيانات لتحرير المعرفة المفاهيمية |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
مفهوم مقاييس التقييم المحددة
Instance Change : التقاط تعقيدات هذه التغييرات على مستوى المثيلConcept Consistency : التشابه الدلالي لتعريف المفهوم الناتج | dataset | جوجل درايف | بايدونيتديسك | وصف |
|---|---|---|---|
| إي آي سي | [جوجل درايف] | [بايدونيت ديسك] | مجموعة بيانات لتحرير التسميات التوضيحية للصورة |
| E-VQA | [جوجل درايف] | [بايدونيت ديسك] | مجموعة بيانات لتحرير الإجابة على الأسئلة المرئية |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| dataset | مجموعة بيانات HuggingFace | وصف |
|---|---|---|
| تحرير آمن | [مجموعة بيانات HuggingFace] | مجموعة بيانات لإزالة السموم من LLMs |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
إزالة السموم مقاييس التقييم المحددة
Defense Duccess (DS) : معدل نجاح إزالة السموم من ماجستير إدارة الأعمال المحرر لإدخال الخصومة (موجه الهجوم + سؤال ضار)، والذي يستخدم لتعديل ماجستير إدارة الأعمال.Defense Generalization (DG) : معدل نجاح إزالة السموم من LLM المحرر للمدخلات الضارة خارج المجال.General Performance : الآثار الجانبية لأداء المهام غير ذات الصلة. | طريقة | وصف | جي بي تي-2 | اللاما |
|---|---|---|---|
| آيك | تحرير التعلم في السياق (ICL). | [كولاب-gpt2] | [كولاب اللاما] |
| روما | تحديد موقع ثم تحرير الخلايا العصبية | [كولاب-gpt2] | [كولاب اللاما] |
| ميت | تحديد موقع ثم تحرير الخلايا العصبية | [كولاب-gpt2] | [كولاب اللاما] |
ملاحظة: يرجى استخدام Python 3.9+ لـ EasyEdit للبدء، ما عليك سوى تثبيت conda وتشغيل:
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txtتعتمد جميع نتائجنا على التكوين الافتراضي
| اللاما-2-7ب | chatglm2 | جي بي تي-ي-6ب | gpt-xl | |
|---|---|---|---|---|
| قدم | 60 جيجابايت | 58 جيجابايت | 55 جيجابايت | 7 جيجابايت |
| سيراك | 42 جيجابايت | 32 جيجابايت | 31 جيجابايت | 10 جيجابايت |
| آيك | 52 جيجابايت | 38 جيجابايت | 38 جيجابايت | 10 جيجابايت |
| إصلاح | 46 جيجابايت | 37 جيجابايت | 37 جيجابايت | 13 جيجابايت |
| كن | 42 جيجابايت | 39 جيجابايت | 40 جيجابايت | 12 جيجابايت |
| روما | 31 جيجابايت | 29 جيجابايت | 27 جيجابايت | 10 جيجابايت |
| ميت | 33 جيجابايت | 31 جيجابايت | 31 جيجابايت | 11 جيجابايت |
| أدالورا | 29 جيجابايت | 24 جيجابايت | 25 جيجابايت | 8 جيجابايت |
| جمال | 27 جيجابايت | 23 جيجابايت | 6 جيجابايت | |
| حكيم | 34 جيجابايت | 27 جيجابايت | 7 جيجابايت |
قم بتحرير نماذج اللغات الكبيرة (LLMs) في حوالي 5 ثوانٍ
يوضح لك المثال التالي كيفية إجراء التحرير باستخدام EasyEdit. يمكن العثور على المزيد من الأمثلة والبرامج التعليمية في الأمثلة
BaseEditorهو فئة تحرير معرفة طريقة اللغة. يمكنك اختيار طريقة التحرير المناسبة بناءً على احتياجاتك الخاصة.
بفضل نمطية ومرونة EasyEdit ، يمكنك استخدامه بسهولة لتحرير النموذج.
الخطوة 1: حدد PLM باعتباره الكائن المراد تحريره. اختر PLM المراد تحريره. يدعم EasyEdit النماذج الجزئية ( T5 و GPTJ و GPT-NEO و LlaMA حتى الآن) التي يمكن استرجاعها على HuggingFace. دليل ملف التكوين المقابل هو hparams/YUOR_METHOD/YOUR_MODEL.YAML ، مثل hparams/MEND/gpt2-xl.yaml ، قم بتعيين model_name المقابل لتحديد الكائن لتحرير المعرفة.
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editingالخطوة 2: اختر طريقة تحرير المعرفة المناسبة
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )الخطوة 3: قم بتوفير واصف التحرير وهدف التحرير
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] الخطوة 4: دمجها في BaseEditor يوفر EasyEdit طريقة بسيطة وموحدة لبدء Editor ، مثل Huggingface: from_hparams .
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )الخطوة 5: توفير البيانات للتقييم لاحظ أن بيانات قابلية النقل والمحلية اختيارية (اضبط على لا شيء لتقييم معدل نجاح التحرير الأساسي فقط). تنسيق البيانات لكليهما هو إملاء ، لكل بعد قياس، تحتاج إلى توفير الموجه المقابل والحقيقة الأساسية المقابلة له. فيما يلي مثال على البيانات:
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}في المثال أعلاه، قمنا بتقييم أداء أساليب التحرير حول "الجوار" و"التشتيت".
الخطوة 6: تم التحرير والتقييم ! يمكننا إجراء التحرير والتقييم حتى يتم تحرير النموذج الخاص بك. ستعيد وظيفة edit سلسلة من المقاييس المتعلقة بعملية التحرير بالإضافة إلى أوزان النموذج المعدل. [ sequential_edit=True للتحرير المستمر]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelالحد الأقصى لطول الإدخال لـ EasyEdit هو 512. إذا تم تجاوز هذا الطول، فسوف تواجه الخطأ "خطأ CUDA: تم تشغيل التأكيد من جانب الجهاز." يمكنك تعديل الحد الأقصى للطول في الملف التالي:LINK
الخطوة 7: التراجع في التحرير التسلسلي، إذا لم تكن راضيًا عن نتيجة أحد تعديلاتك ولا ترغب في فقدان تعديلاتك السابقة، فيمكنك استخدام ميزة التراجع للتراجع عن تعديلك السابق. حاليًا، نحن ندعم طريقة GRACE فقط. كل ما عليك فعله هو سطر واحد من التعليمات البرمجية، باستخدام مفتاح التحرير للتراجع عن تعديلك.
editor.rolllback('edit_key')
في EasyEdit، نستخدم افتراضيًا استخدام target_new كمفتاح التحرير
نحدد مقاييس الإرجاع بتنسيق dict ، بما في ذلك تقييمات التنبؤ بالنموذج قبل التحرير وبعده. لكل تعديل، سيتضمن المقاييس التالية:
rewrite_acc rephrase_acc locality portablility 

