mengzi retrieval lm
1.0.0
في شركة Langboat Technology، نركز على تعزيز النماذج المدربة مسبقًا لجعلها أخف وزنًا لتلبية احتياجات الصناعة الحقيقية. يعد النهج القائم على الاسترجاع (مثل RETRO وREALM وRAG) أمرًا بالغ الأهمية لتحقيق هذا الهدف.
يعد هذا المستودع تطبيقًا تجريبيًا لنموذج اللغة المحسّن للاسترجاع. حاليًا، يدعم فقط تركيب الاسترجاع على GPT-Neo.
لقد قمنا بتشكيل Huggingface Transformers وأداة تقييم lm لإضافة دعم الاسترجاع. يتم تنفيذ جزء الفهرسة كخادم HTTP لفصل الاسترجاع والتدريب بشكل أفضل.
يتم نسخ معظم تنفيذ النموذج من RETRO-pytorch وGPT-Neo. نستخدم transformers-cli لإضافة نموذج جديد اسمه Re_gptForCausalLM مبني على GPT-Neo، ثم نضيف إليه جزء الاسترجاع.
لقد قمنا بتحميل النموذج المجهز على EleutherAI/gpt-neo-125M باستخدام مكتبة استرجاع 200G.
يمكنك تهيئة نموذج مثل هذا:
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )وتقييم النموذج مثل هذا:
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1نحن نحسب التشابه باستخدام تضمينجملة_المحولات كتمثيل نصي. يمكنك تهيئة نموذج Sentence-BERT مثل هذا:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )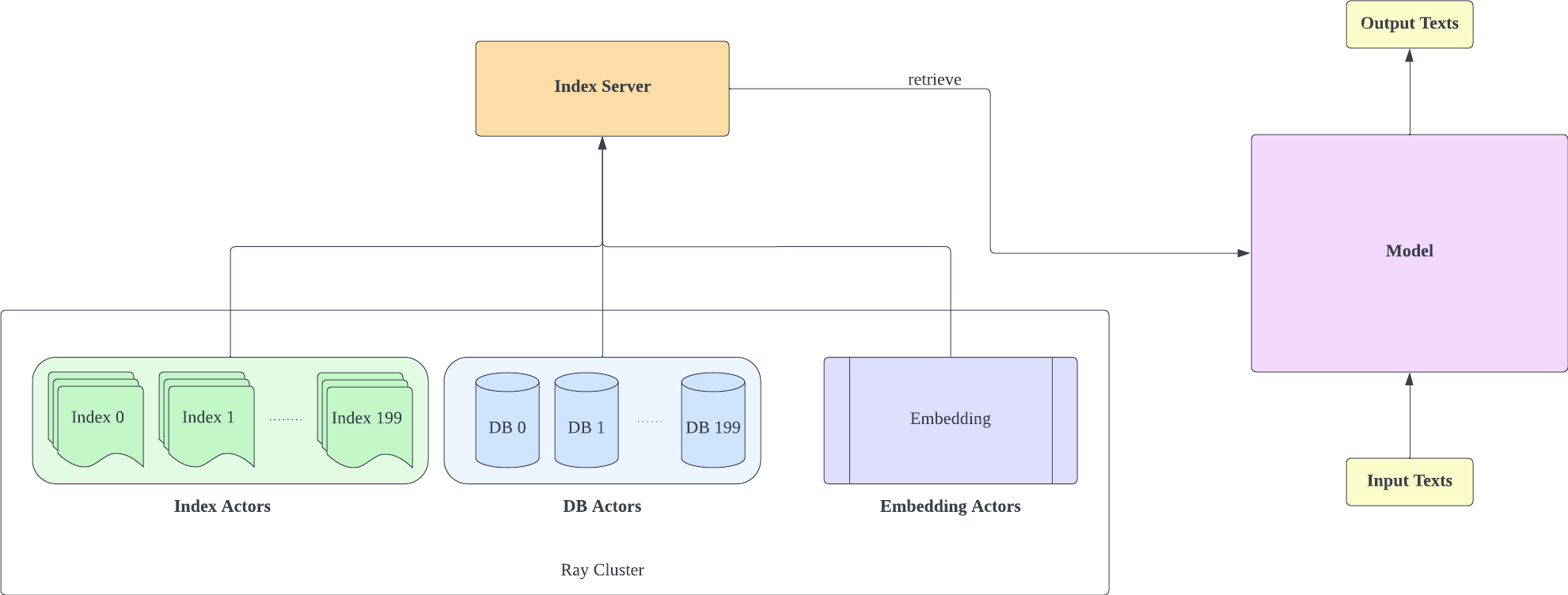
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " باستخدام IVF1024PQ48 كمصنع فهرس faiss، قمنا بتحميل الفهرس وقاعدة البيانات إلى مركز نموذج Huggingface، والذي يمكن تنزيله باستخدام الأمر التالي.
في download_index_db.py، يمكنك تحديد عدد الفهارس وقواعد البيانات التي تريد تنزيلها.
python -u download_index_db.py --num 200يمكنك تنزيل النموذج المجهز يدويًا من هنا: https://huggingface.co/Langboat/ReGPT-125M-200G
يعتمد خادم الفهرس على FastAPI وRay. مع Ray's Actor، يتم تغليف المهام الحسابية المكثفة بشكل غير متزامن، مما يسمح لنا باستخدام موارد وحدة المعالجة المركزية ووحدة معالجة الرسومات بكفاءة من خلال مثيل خادم FastAPI واحد فقط. يمكنك تهيئة خادم الفهرس مثل هذا:
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- ضع في اعتبارك أن عدد أجزاء التكوين IVF1024PQ48.json يجب أن يتطابق مع عدد الفهارس التي تم تنزيلها. يمكنك عرض رقم الفهرس الذي تم تنزيله حاليًا ضمن db_path
- تم اختبار هذا التكوين على A100-40G، لذا إذا كان لديك وحدة معالجة رسومات مختلفة، فنوصي بتعديله ليناسب أجهزتك.
- بعد نشر خادم الفهرس، تحتاج إلى تعديل request_server في lm-evaluation-harness/config.json وtrain/config.json .
- يمكنك تقليل عدد encoder_actor_count في config_IVF1024PQ48.json لتقليل موارد الذاكرة المطلوبة.
· db_path: موقع تنزيل قاعدة البيانات من Huggingface. "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966" مثال على ذلك.
سيقوم هذا الأمر بتنزيل قاعدة البيانات وبيانات الفهرس من Huggingface.
قم بتغيير مجلد الفهرس في ملف التكوين (التكوين IVF1024PQ48) للإشارة إلى مسار مجلد الفهرس، وأرسل لقطات مجلد قاعدة البيانات كمسار قاعدة بيانات إلى البرنامج النصي api.py.
أوقف خادم الفهرس باستخدام الأمر التالي
ray stop
- ضع في اعتبارك أنك تحتاج إلى الحفاظ على تمكين خادم الفهرس أثناء التدريب والتقييم والاستدلال
استخدم Train/train.py لتنفيذ التدريب؛ يمكن تعديل Train/config.json لتغيير معلمات التدريب.
يمكنك تهيئة التدريب مثل هذا:
cd train
python -u train.py
- نظرًا لأن خادم الفهرس يحتاج إلى استخدام موارد الذاكرة، فمن الأفضل نشر خادم الفهرس والتدريب النموذجي على وحدات معالجة الرسومات المختلفة
استخدم Train/inference.py كاستدلال لتحديد فقدان النص وحيرته.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- إن test_data.json وtrain_data.json الموجودين في مجلد البيانات هما تنسيقات ملفات مدعومة حاليًا، ويمكنك تعديل بياناتك إلى هذا التنسيق.
استخدم lm-evaluation-harness كوسيلة للتقييم
قمنا بتعيين seq_len لأداة تقييم lm على 1025 كإعداد أولي لمقارنة النماذج لأن seq_len لتدريب النموذج الخاص بنا هو 1025.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path: مسار النموذج المناسب
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1نتائج التقييم هي كما يلي
| نموذج | نص ويكي word_perplexity |
|---|---|
| إليوثيرAI/gpt-neo-125M | 35.8774 |
| لانجبوت/ReGPT-125M-200G | 22.115 |
| إليوثيرAI/gpt-neo-1.3B | 17.6979 |
| لانجبوت/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

