graph gpt
v0.4.0
هذا المستودع هو التطبيق الرسمي لـ "GraphGPT: تعلم الرسم البياني باستخدام المحولات التوليدية المدربة مسبقًا" في PyTorch.
GraphGPT: تعلم الرسم البياني باستخدام المحولات التوليدية المدربة مسبقًا
كيفانغ تشاو، ويدونغ رن، تيانيو لي، شياوكسياو شو، هونغ ليو
13/10/2024
CHANGELOG.md للحصول على التفاصيل.18/08/2024
CHANGELOG.md للحصول على التفاصيل.07/09/2024
19/03/2024
permute_nodes لمجموعة بيانات نمط الخريطة على مستوى الرسم البياني، من أجل زيادة الاختلافات في مسارات Eulerian، مما يؤدي إلى نتائج أفضل وقوية.StackedGSTTokenizer بحيث يمكن تكديس الرموز المميزة للدلالات (على سبيل المثال، العقدة/الحافة) مع الرموز الهيكلية، وسيتم تقليل طول التسلسل كثيرًا.23/01/2024
01/03/2024

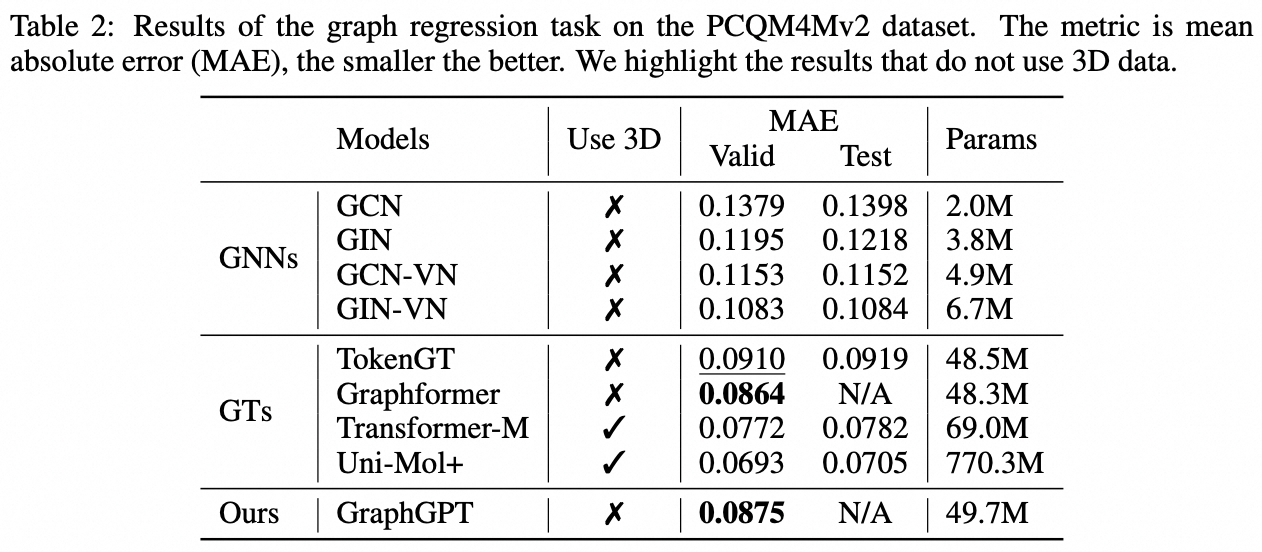
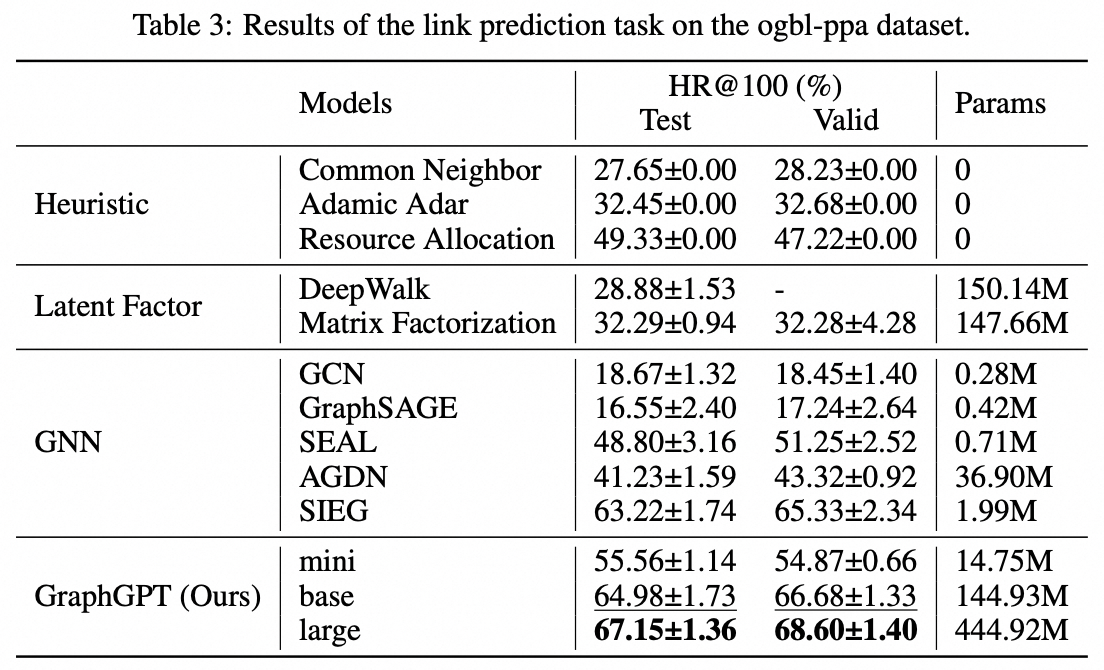
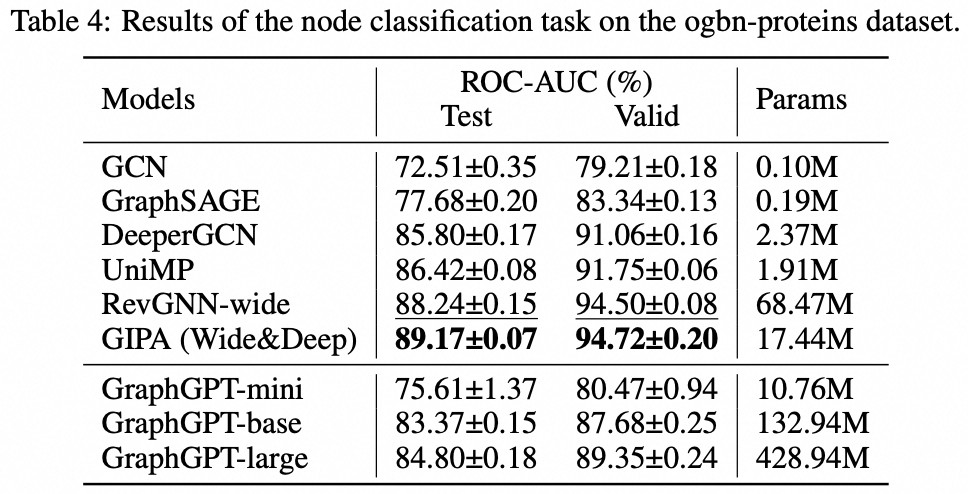
نقترح GraphGPT، وهو نموذج جديد لتعلم الرسم البياني من خلال محولات الرسم البياني التوليدية قبل التدريب الخاضعة للإشراف الذاتي (GET). نقدم أولاً GET، الذي يتكون من العمود الفقري لمشفر/وحدة فك تشفير محولات الفانيليا وتحويل يحول كل رسم بياني أو رسم بياني فرعي تم أخذ عينات منه إلى سلسلة من الرموز المميزة التي تمثل العقدة والحافة والسمات بشكل عكسي باستخدام مسار أويلريان. ثم نقوم بتدريب GET مسبقًا إما بمهمة التنبؤ بالرمز المميز التالي (NTP) أو مهمة التنبؤ بالرمز المميز المقنع (SMTP). وأخيرًا، نقوم بضبط النموذج باستخدام المهام الخاضعة للإشراف. يحقق هذا النموذج البديهي والفعال نتائج متفوقة أو قريبة من أحدث الأساليب للمهام على مستوى الرسم البياني والحافة والعقدة في مجموعة البيانات الجزيئية واسعة النطاق PCQM4Mv2، ومجموعة بيانات رابطة البروتين البروتين ogbl-ppa ومجموعة بيانات شبكة الاقتباس ogbl-citation2 ومجموعة بيانات ogbn-proteins من Open Graph Benchmark (OGB). علاوة على ذلك، يتيح لنا التدريب المسبق التوليدي تدريب GraphGPT حتى 2B+ من المعلمات مع زيادة الأداء باستمرار، وهو ما يتجاوز قدرة شبكات GNN ومحولات الرسم البياني السابقة.
بعد تحويل الرسوم البيانية Eulerized إلى تسلسلات، هناك عدة طرق مختلفة لربط سمات العقدة والحافة بالتسلسلات. نحن نسمي هذه الأساليب short long prolonged .
بالنظر إلى الرسم البياني، نقوم بتحليله أولًا، ثم نحوله إلى تسلسل مكافئ. وبعد ذلك، نقوم بإعادة فهرسة العقد بشكل دوري.
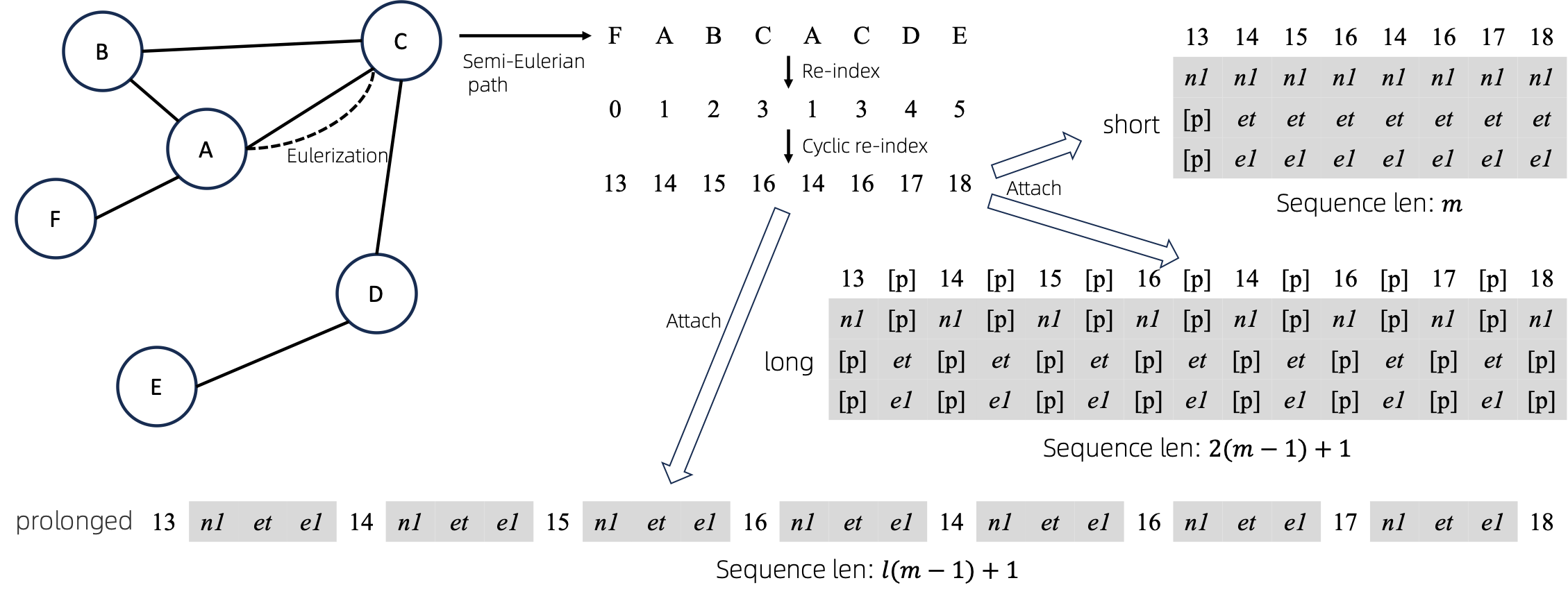
افترض أن الرسم البياني يحتوي على سمات عقدة واحدة وسمات حافة واحدة، ثم يتم عرض الطريقة short long prolong أعلاه.
في الأشكال أعلاه، يمثل n1 و n2 و e1 الرموز المميزة لسمات العقدة والحافة، ويمثل [p] رمز الحشو.
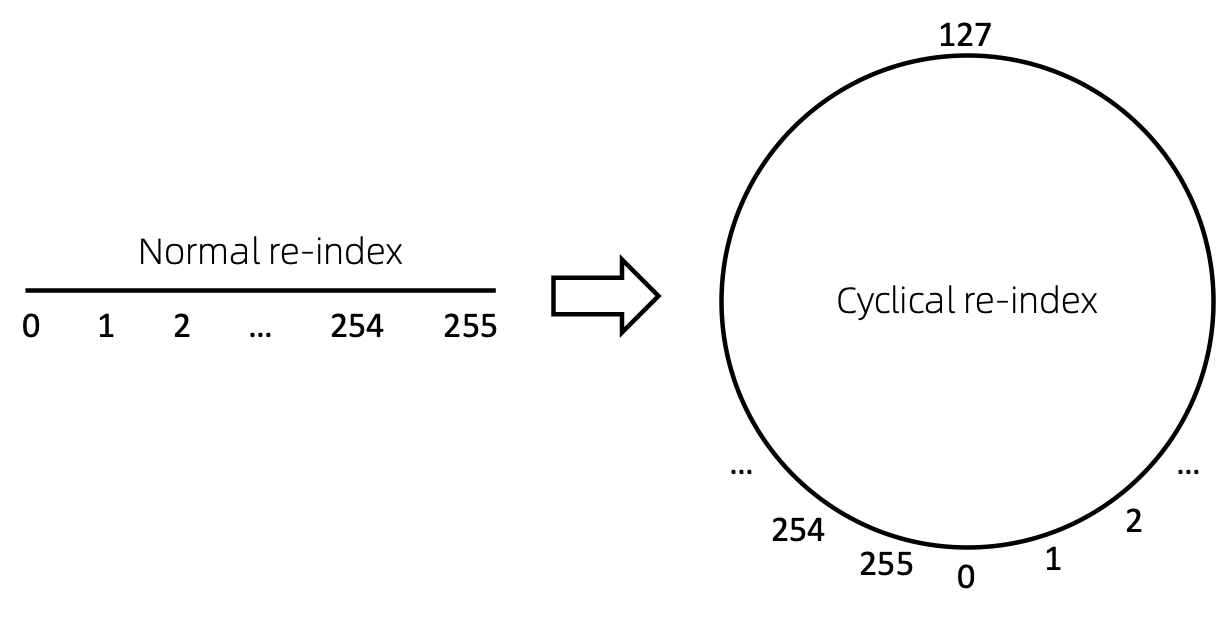
الطريقة المباشرة لإعادة فهرسة تسلسل العقد هي البدء بالرقم 0 وإضافة 1 بشكل تدريجي. بهذه الطريقة، سيتم تدريب الرموز المميزة للمؤشرات الصغيرة بشكل كافٍ، ولن يتم تدريب المؤشرات الكبيرة. للتغلب على ذلك، نقترح cyclical re-index ، والتي تبدأ برقم عشوائي في النطاق المحدد، على سبيل المثال [0, 255] ، وتزيد بمقدار 1. بعد الوصول إلى الحد، على سبيل المثال، 255 ، سيكون فهرس العقدة التالي 0 .
عفا عليها الزمن. ليتم تحديثها قريبا.
git clone https://github.com/alibaba/graph-gpt.gitconda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bcيتم تنزيل مجموعات البيانات باستخدام حزمة python ogb.
عند تشغيل البرامج النصية في ./examples ، سيتم تنزيل مجموعة البيانات تلقائيًا.
ومع ذلك، فإن مجموعة البيانات PCQM4M-v2 ضخمة، وقد يكون التنزيل والمعالجة المسبقة مشكلة. نقترح تنزيل cd ./src/utils/ و python dataset_utils.py لتنزيل مجموعة البيانات ومعالجتها مسبقًا بشكل منفصل.
./examples/graph_lvl/pcqm4m_v2_pretrain.sh ، على سبيل المثال، dataset_name و model_name و batch_size و workerCount وما إلى ذلك، ثم قم بتشغيل ./examples/graph_lvl/pcqm4m_v2_pretrain.sh للتدريب المسبق للنموذج باستخدام PCQM4M-v2 dataset../examples/toy_examples/reddit_pretrain.sh مباشرةً../examples/graph_lvl/pcqm4m_v2_supervised.sh ، على سبيل المثال، dataset_name و model_name و batch_size و workerCount و pretrain_cpt وما إلى ذلك، ثم قم بتشغيل ./examples/graph_lvl/pcqm4m_v2_supervised.sh لضبط المهام النهائية ../examples/toy_examples/reddit_supervised.sh مباشرة. .pre-commit-config.yaml : قم بإنشاء الملف بالمحتوى التالي لـ python repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : blackpre-commit install : تثبيت الالتزام المسبق في خطافات git الخاصة بك.pre-commit install أول شيء تفعله دائمًا.pre-commit run --all-files : تشغيل جميع خطافات الالتزام المسبق في المستودعpre-commit autoupdate : قم بتحديث خطافاتك إلى الإصدار الأحدث تلقائيًاgit commit -n : يمكن تعطيل عمليات التحقق المسبق لالتزام معين باستخدام الأمر إذا وجدت هذا العمل مفيدا، يرجى التكرم بذكر الأوراق التالية:
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}كيفانغ تشاو ([email protected])
نقدر بصدق اقتراحاتكم بشأن عملنا!
تم إصداره بموجب ترخيص MIT (انظر LICENSE ):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


