CDial GPT
1.0.0
يوفر هذا المشروع مجموعة بيانات محادثة صينية واسعة النطاق ونموذجًا للتدريب المسبق على المحادثة الصينية (نموذج GPT الصيني) في مجموعة البيانات هذه لمزيد من المعلومات، يرجى الرجوع إلى ورقتنا البحثية.
تم تعديل كود هذا المشروع من TransferTransfo ويستخدم إصدار HuggingFace Pytorch من مكتبة Transformers، والذي يمكن استخدامه للتدريب المسبق والضبط الدقيق.
from datasets import load_dataset
dataset = load_dataset ( "lccc" , "base" ) # or "large" تتكون مجموعة البيانات LCCC (المحادثة الصينية النظيفة واسعة النطاق) بشكل أساسي من جزأين: LCCC-base (Baidu Netdisk، Google Drive) و LCCC-large (Baidu Netdisk، Google Drive). تأكد من جودة بيانات المحادثة في مجموعة البيانات هذه. تتضمن عملية تصفية البيانات هذه سلسلة من القواعد اليدوية والعديد من المصنفات بناءً على خوارزميات التعلم الآلي. تشتمل الضوضاء التي نقوم بتصفيتها على: الكلمات البذيئة، والأحرف الخاصة، وتعبيرات الوجه، والجمل غير الصحيحة نحويًا، والحوار الذي لا علاقة له بالسياق، وما إلى ذلك.
يتم عرض إحصائيات مجموعة البيانات هذه في الجدول أدناه. ومن بينها، نسمي الحوار الذي يحتوي على جملتين فقط "الحوار ذو الدورة الواحدة"، ونسمي الحوار الذي يحتوي على أكثر من جملتين "الحوار متعدد الأدوار". استخدم تجزئة الكلمات في Jieba عند حساب حجم قائمة الكلمات.
| قاعدة LCCC (بايدو كلاود ديسك، جوجل درايف) | محادثة ذات دورة واحدة | جولات متعددة من الحوار |
|---|---|---|
| يتحول الحوار الكلي | 3,354,232 | 3,466,274 |
| مجموع جمل الحوار | 6,708,464 | 13,365,256 |
| مجموع الشخصيات | 68,559,367 | 163,690,569 |
| حجم المفردات | 372,063 | 666,931 |
| متوسط عدد الكلمات في جمل المحادثة | 6.79 | 8.32 |
| متوسط عدد الجمل في كل جولة محادثة | 2 | 3.86 |
لاحظ أن عملية التنظيف لمجموعة البيانات الأساسية لـ LCCC أكثر صرامة من تلك الخاصة بـ LCCC الكبيرة، لذا فإن حجمها أصغر أيضًا.
| LCCC-كبير (بايدو كلاود ديسك، جوجل درايف) | محادثة ذات دورة واحدة | جولات متعددة من الحوار |
|---|---|---|
| يتحول الحوار الكلي | 7,273,804 | 4,733,955 |
| مجموع جمل الحوار | 14,547,608 | 18,341,167 |
| مجموع الشخصيات | 162,301,556 | 217,776,649 |
| حجم المفردات | 662,514 | 690,027 |
| عدد كلمات التقييم لجمل المحادثة | 7.45 | 8.14 |
| متوسط عدد الجمل في كل جولة محادثة | 2 | 3.87 |
تأتي بيانات المحادثة الأصلية في مجموعة بيانات LCCC الأساسية من محادثات Weibo، ويتم دمج بيانات المحادثة الأصلية في مجموعة بيانات LCCC الكبيرة مع مجموعات بيانات محادثة مفتوحة المصدر أخرى بناءً على محادثات Weibo هذه:
| مجموعة البيانات | يتحول الحوار الكلي | مثال المحادثة |
|---|---|---|
| ويبو كوربوس | 79 م | س: تناولت وعاءً ساخنًا سبع أو ثماني مرات في تشنغدو، تشونغتشينغ ج: هاهاهاها! ثم قد يتعفن فمي! |
| PTT النميمة كوربوس | 0.4 م | س: لماذا يقوم القرويون دائمًا بالتنمر على طلاب المدارس الثانوية؟ س: ج: إذا كنت تعتقد أنك إذا اخترت مادة جيدة، فسوف تصبح بيل جيتس، فمن الأفضل أن تترك المدرسة. |
| مجموعة الترجمة | 2.74 م | س: الناس في أوبرا بكين ليسوا أحرارا. ج: إنهم يضعون الناس في أقفاص. |
| مجموعة شياو هوانغجي | 0.45 م | س: هل سبق لك أن وقعت في الحب؟ ج: هل سبق لك أن وقعت في الحب؟ |
| تيبا كوربوس | 2.32 م | س: الصف الأمامي، جميع مشجعي لو يستيقظون، أليس كذلك؟ ج: العنوان يقول أنه يساعد، ولكن بعد مشاهدة تلك الكرة، إنها حقًا مفارقة حية. |
| تشينغيون كوربوس | 0.1 م | س: يبدو أنك تحب المال كثيراً. ج: أوه، حقاً؟ ثم أنت تقريبا هناك |
| مجموعة محادثة دوبان | 0.5 م | س: تعلم اللغة الإنجليزية النقية من خلال مشاهدة الأفلام الإنجليزية الأصلية ج: أحب مسلسل Friends وقد شاهدته عدة مرات س: لقد سئمت تقريبًا من مشاهدة نفس القرص المضغوط ج: إذًا يجب أن تكون لغتك الإنجليزية جيدة جدًا الآن |
| مجموعة المحادثة التجارية الإلكترونية | 0.5 م | س: هل ستكون هذه صفقة جيدة؟ ج: ليس بعد. س: هل ستكون متاحة في المستقبل؟ ج: يرجى الانتباه إلينا. |
| مجموعة الدردشة الصينية | 0.5 م | س: ساقاي عديمة الفائدة اليوم، أنتم تحتفلون بالعيد، لذا سأقوم بنقل الطوب. ج: لقد ذهبت لكسب الكثير من المال في عيد الميلاد ليس لدي صديق، لذا فإن أي عطلة هي نفسها. |
كما نقوم بتوفير سلسلة من نماذج التدريب المسبق الصينية (نماذج GPT الصينية) وتنقسم عملية التدريب المسبق لهذه النماذج إلى خطوتين، أولاً التدريب المسبق على البيانات الصينية الجديدة، ومن ثم التدريب المسبق على بيانات LCCC. تعيين.
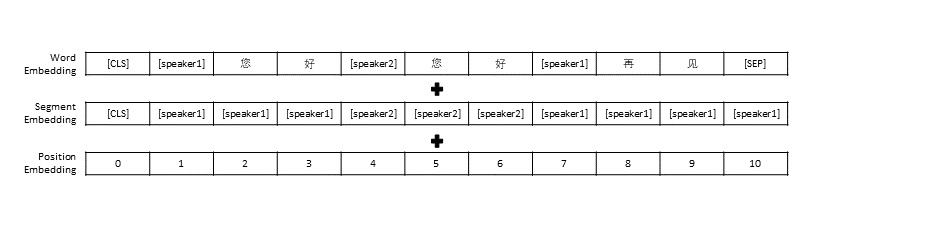
لقد اتبعنا إعدادات المعالجة المسبقة للبيانات في TransferTransfo، والتي قسمت كل سجل المحادثة إلى جملة واحدة، ثم استخدمنا هذه الجملة كمدخل للنموذج للتنبؤ برد المحادثة. بالإضافة إلى التمثيل المتجه لكل كلمة، يتضمن مدخل نموذجنا أيضًا تمثيل متجه المتحدث وتمثيل متجه الموضع.
| نموذج تم تدريبه مسبقًا | عدد المعلمات | البيانات المستخدمة للتدريب المسبق | يصف |
|---|---|---|---|
| رواية جي بي تي | 95.5 م | بيانات الرواية الصينية | نموذج GPT صيني تم تدريبه مسبقًا بناءً على بيانات صينية جديدة (تتضمن البيانات الجديدة إجمالي 1.3 مليار كلمة) |
| قاعدة CDial-GPT LCCC | 95.5 م | قاعدة LCCC | استنادًا إلى GPT Novel ، استخدم نموذج GPT الصيني المدرب مسبقًا والذي تم تدريبه بواسطة قاعدة LCCC |
| قاعدة CDial-GPT2 LCCC | 95.5 م | قاعدة LCCC | استنادًا إلى GPT Novel ، استخدم نموذج GPT2 الصيني المُدرب مسبقًا والمُدرب بقاعدة LCCC |
| CDial-GPT LCCC-كبير | 95.5 م | LCCC-كبير | استنادًا إلى GPT Novel ، استخدم نموذج GPT الصيني المدرب مسبقًا والذي تم تدريبه بواسطة LCCC-large |
التثبيت مباشرة من المصدر:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
الخطوة 1: إعداد مجموعة البيانات المطلوبة لنموذج ما قبل التدريب والضبط الدقيق (مثل مجموعة بيانات STC أو بيانات اللعبة "data/toy_data.json" في دليل المشروع. يرجى ملاحظة أنه إذا كانت البيانات تحتوي على اللغة الإنجليزية، فيجب فصلها بالحروف مثل: مرحباً)
# 下载 STC 数据集 中的训练集和验证集 并将其解压至 "data_path" 目录 (如果微调所使用的数据集为 STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # 您可自行下载模型或者OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ملاحظة: يمكنك استخدام الروابط التالية لتنزيل مجموعة التدريب ومجموعة التحقق من STC (Baidu Cloud Disk، Google Drive)
الخطوة 2: تدريب النموذج
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 使用单个GPU进行训练
أو
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # 以分布式的方式在8块GPU上训练
يتم توفير المعلمة train_path أيضًا في برنامجنا التدريبي، والذي يسمح للمستخدمين بقراءة الملفات النصية العادية في شرائح. إذا كنت تستخدم نظامًا ذا ذاكرة محدودة، ففكر في استخدام هذه المعلمة لقراءة بيانات التدريب. إذا كنت تستخدم train_path فأنت بحاجة إلى ترك data_path فارغًا.
الخطوة 3: إنشاء النص
# YOUR_MODEL_PATH: 你要使用的模型的路径,每次微调后的模型目录保存在./runs/中
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # 在测试数据上生成回复
python interact.py --model_checkpoint YOUR_MODEL_PATH # 在命令行中与模型进行交互
ملاحظة: يمكنك استخدام الرابط التالي لتنزيل مجموعة اختبار STC (Baidu Cloud Disk، Google Drive)
معلمات البرنامج النصي للتدريب
| المعلمة | يكتب | القيمة الافتراضية | يصف |
|---|---|---|---|
| model_checkpoint | شارع | "" | المسار أو عنوان URL لملفات النماذج (دليل نموذج التدريب المسبق وملفات التكوين/المفردات) |
| مدربين مسبقا | منطقي | خطأ شنيع | إذا كان خطأ، فقم بتدريب النموذج من الصفر |
| data_path | شارع | "" | مسار مجموعة البيانات |
| dataset_cache | شارع | الافتراضي = "dataset_cache" | المسار أو عنوان url لذاكرة التخزين المؤقت لمجموعة البيانات |
| مسار القطار | شارع | "" | مسار مجموعة التدريب لمجموعة البيانات الموزعة |
| valid_path | شارع | "" | مسار مجموعة التحقق من الصحة لمجموعة البيانات الموزعة |
| log_file | شارع | "" | سجلات الإخراج إلى ملف ضمن هذا المسار |
| num_workers | كثافة العمليات | 1 | عدد العمليات الفرعية لتحميل البيانات |
| n_epochs | كثافة العمليات | 70 | عدد فترات التدريب |
| Train_batch_size | كثافة العمليات | 8 | حجم الدفعة للتدريب |
| valid_batch_size | كثافة العمليات | 8 | حجم الدفعة للتحقق من صحتها |
| max_history | كثافة العمليات | 15 | عدد التبادلات السابقة التي يجب الاحتفاظ بها في التاريخ |
| جدولة | شارع | "نعوم" | طريقة المحسن |
| n_emd | كثافة العمليات | 768 | عدد n_emd في ملف التكوين (لـ noam) |
| eval_before_start | منطقي | خطأ شنيع | إذا كان هذا صحيحا، ابدأ التقييم قبل التدريب |
| Warmup_steps | كثافة العمليات | 5000 | خطوات الاحماء |
| valid_steps | كثافة العمليات | 0 | قم بإجراء التحقق من الصحة كل X من الخطوات، إذا لم تكن 0 |
| gradient_accumulation_steps | كثافة العمليات | 64 | تجميع التدرجات على عدة خطوات |
| max_norm | يطفو | 1.0 | لقطة قاعدة التدرج |
| جهاز | شارع | "cuda" إذا كان torch.cuda.is_available() وإلا "cpu" | الجهاز (كودا أو وحدة المعالجة المركزية) |
| fp16 | شارع | "" | اضبط على O0 أو O1 أو O2 أو O3 للتدريب على fp16 (راجع وثائق القمة) |
| local_rank | كثافة العمليات | -1 | الترتيب المحلي للتدريب الموزع (-1: غير موزع) |
قمنا بتقييم نموذج التدريب المسبق للحوار الذي تم ضبطه بدقة باستخدام مجموعة بيانات STC (مجموعة التدريب/مجموعة التحقق (Baidu Netdisk، Google Drive)، مجموعة الاختبار (Baidu Netdisk، Google Drive)). تم أخذ عينات من جميع الاستجابات باستخدام Nucleus Sampling (ع = 0.9، درجة الحرارة = 0.7).
| نموذج | حجم النموذج | شركته تنوي | بلو-2 | بلو-4 | حي-1 | حي-2 | مطابقة الجشع | متوسط التضمين |
|---|---|---|---|---|---|---|---|---|
| عناية-Seq2seq | 73 م | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| محول | 113 م | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-دردشة | 88 م | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| رواية جي بي تي | 95.5 م | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| قاعدة GPT LCCC | 95.5 م | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| قاعدة GPT2 LCCC | 95.5 م | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-كبير | 95.5 م | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
قمنا بأخذ عينات من 200 رد لكل نموذج ودعونا ثلاثة معلقين على منصة الاستعانة بمصادر خارجية لتقييم هذه الاستجابات يدويًا، وكانت أبعاد التقييم هي طلاقة المحادثة، والأهمية السياقية، وتنوع الاستجابة. نطاق التسجيل لكل بعد هو 2/1/0. يرجى الرجوع إلى ورقتنا لمزيد من التفاصيل.
| نموذج | +2 | +1 | +0 | كابا |
|---|---|---|---|---|
| عناية Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| محول | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-دردشة | 24.3% | 19,1% | 56.6% | 0.3941 |
| قاعدة GPT LCCC | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-كبير | 48.6% | 24.5% | 27.0% | 0.4203 |
لقد قمنا بأخذ عينات عشوائية من 1000 رد على المحادثة وأحصينا الردود السيئة من بين هذه الردود:
| يحتوي على تصريحات متكررة | يحتوي على كلمات بذيئة | ردود سيئة أخرى |
|---|---|---|
| ثلاثة وعشرين | 9 | 2 |
لقد قمنا بضبط معلمات نموذج GPT LCCC الكبير على مجموعة بيانات STC، واستخدمنا هذا النموذج الدقيق لإنشاء مثال المحادثة التالي:
| بريد | إجابة |
|---|---|
| هذه في الواقع بكين وليست هاربين. | يبدو أن الطقس في هاربين أفضل من الطقس في بكين، حيث تهطل أمطار خفيفة هنا وهناك رياح قوية خلال النهار. |
| كانت المنافسة الإعلانية في الحرم الجامعي للمشغل ممتعة للغاية! هاهاها. | اعتقدت أنه كان إعلان جاك ما. |
| فستان زفاف من سلسلة ألوان الحلوى من Delsa S posa، وردي، أزرق، أحمر وأرجواني، مرح ومنعش، هل يعجبك؟ | الأخيرة جميلة جدًا، جميلة جدًا! |
استخدمنا أيضًا النموذج الدقيق أعلاه للحصول على نتائج التفاعل التالية:
| رويل | إجابة |
|---|---|
| مستخدم | لا تحبني دون جدوى |
| بوت | الحب غير المثمر مؤلم جداً. |
| مستخدم | لكن لا بأس إذا كنت قد أحببته |
| بوت | في بعض الأحيان، الحب هو لعبة. |
| مستخدم | أنا دائما أخسر |
| بوت | أحبك بقدر ما أحبك. |
| مستخدم | هل يمكنك سحبها؟ |
| بوت | يمكنك سحبها. |
| مستخدم | لا تقلدني |
| بوت | ما أقوله هو أنك لا تستطيع أن تفعل ذلك. |
| مستخدم | أنت تجبرني على القيام بذلك، أليس كذلك؟ |
| بوت | لا، أنا أجبرك على الكلام، أليس كذلك؟ |
ييدا وانغ، بي كي، يينه تشنغ، كايلي هوانغ، يونغ جيانغ، شياو يان تشو، مينلي هوانغ
زوكسيان يي، ياو وانغ، ييفان بان
مجموعة بيانات LCCC ونموذج الحوار المدرب مسبقًا المقدم من هذا المشروع هي لأغراض البحث العلمي فقط. يتم جمع المحادثات في مجموعة بيانات LCCC من مصادر مختلفة. على الرغم من أننا صممنا عملية تنظيف بيانات صارمة، إلا أننا لا نضمن تصفية كل المحتوى غير المناسب. جميع المحتويات والآراء الواردة في هذه البيانات مستقلة عن مؤلفي هذا المشروع. النموذج والكود المقدم في هذا المشروع ليسا سوى جزء من نظام الحوار الكامل. نصوص فك التشفير التي نقدمها مخصصة لأغراض البحث العلمي فقط. كل محتوى الحوار الذي تم إنشاؤه باستخدام النماذج والبرامج النصية في هذا المشروع ليس له أي علاقة بمؤلفه هذا المشروع.
إذا وجدت مشروعنا مفيدًا، فيرجى الاستشهاد بمقالتنا:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}
يوفر هذا المشروع مجموعة بيانات محادثة صينية منقحة واسعة النطاق ونموذج GPT صيني تم تدريبه مسبقًا على مجموعة البيانات هذه. يرجى الرجوع إلى ورقتنا لمزيد من التفاصيل.
الكود الخاص بنا المستخدم للتدريب المسبق مقتبس من نموذج TransferTransfo استنادًا إلى مكتبة Transformers. يتم توفير الرموز المستخدمة لكل من التدريب المسبق والضبط الدقيق في هذا المستودع.
نقدم مجموعة محادثات صينية نظيفة واسعة النطاق (LCCC) تحتوي على: LCCC-base (Baidu Netdisk، Google Drive) و LCCC-large (Baidu Netdisk، Google Drive). تم تصميم خط أنابيب صارم لتنظيف البيانات لضمان جودة المحادثة الصينية النظيفة يتضمن هذا المسار مجموعة من القواعد والعديد من المرشحات المستندة إلى التصنيف، مثل الكلمات المسيئة أو الحساسة، والرموز الخاصة، والرموز التعبيرية، والجمل غير الصحيحة نحويًا، والمحادثات غير المتماسكة. تمت تصفيته.
يتم عرض إحصائية مجموعتنا أدناه تعتبر الحوارات التي تحتوي على لفظين فقط بمثابة "دورة واحدة"، والحوارات التي تحتوي على أكثر من ثلاثة أقوال تعتبر "متعددة المنعطفات". يتم استخدام Jieba لتمييز كل عبارة بالكلمات.
| قاعدة LCCC (بايدو نت ديسك، جوجل درايف) | دورة واحدة | متعدد المنعطفات |
|---|---|---|
| الجلسات | 3,354,382 | 3,466,607 |
| أقوال | 6,708,554 | 13,365,268 |
| الشخصيات | 68,559,727 | 163,690,614 |
| مفردات | 372,063 | 666,931 |
| متوسط الكلمات لكل كلام | 6.79 | 8.32 |
| متوسط الكلام لكل جلسة | 2 | 3.86 |
لاحظ أنه يتم تنظيف قاعدة LCCC باستخدام قواعد أكثر صرامة مقارنةً بـ LCCC الكبيرة.
| LCCC-كبير (بايدو نت ديسك، جوجل درايف) | دورة واحدة | متعدد المنعطفات |
|---|---|---|
| الجلسات | 7,273,804 | 4,733,955 |
| أقوال | 14,547,608 | 18,341,167 |
| الشخصيات | 162,301,556 | 217,776,649 |
| مفردات | 662,514 | 690,027 |
| متوسط الكلمات لكل كلام | 7.45 | 8.14 |
| متوسط الكلام لكل جلسة | 2 | 3.87 |
تنشأ الحوارات الأولية لقاعدة LCCC من مجموعة Weibo Corpus التي قمنا بالزحف إليها من Weibo، وتم إنشاء الحوارات الأولية لـ LCCC الكبيرة من خلال الجمع بين العديد من مجموعات بيانات المحادثة بالإضافة إلى مجموعة Weibo Corpus:
| مجموعة البيانات | الجلسات | عينة |
|---|---|---|
| ويبو كوربوس | 79 م | س: لقد تناولت وعاء ساخن سبع أو ثماني مرات في تشنغدو، تشونغتشينغ ج: هاهاهاها! ثم قد يتعفن فمي! |
| PTT النميمة كوربوس | 0.4 م | س: لماذا يقوم القرويون دائمًا بالتنمر على طلاب المدارس الثانوية؟ س: ج: إذا كنت تعتقد أنك إذا اخترت مادة جيدة، فسوف تصبح بيل جيتس، فمن الأفضل أن تترك المدرسة. |
| مجموعة الترجمة | 2.74 م | س: الناس في أوبرا بكين ليسوا أحرارا. ج: إنهم يضعون الناس في أقفاص. |
| مجموعة شياو هوانغجي | 0.45 م | س: هل سبق لك أن وقعت في الحب؟ ج: هل سبق لك أن وقعت في الحب؟ |
| تيبا كوربوس | 2.32 م | س: الصف الأمامي، جميع مشجعي لو يستيقظون، أليس كذلك؟ ج: العنوان يقول أنه يساعد، ولكن بعد مشاهدة تلك الكرة، إنها حقًا مفارقة حية. |
| تشينغيون كوربوس | 0.1 م | س: يبدو أنك تحب المال كثيراً. ج: أوه، حقاً؟ ثم أنت تقريبا هناك |
| مجموعة محادثة دوبان | 0.5 م | س: تعلم اللغة الإنجليزية النقية من خلال مشاهدة الأفلام الإنجليزية الأصلية ج: أحب مسلسل Friends وقد شاهدته عدة مرات س: لقد سئمت تقريبًا من مشاهدة نفس القرص المضغوط ج: إذًا يجب أن تكون لغتك الإنجليزية جيدة جدًا الآن |
| مجموعة المحادثة التجارية الإلكترونية | 0.5 م | س: هل ستكون هذه صفقة جيدة؟ ج: ليس بعد. س: هل ستكون متاحة في المستقبل؟ ج: غير متأكد. |
| مجموعة الدردشة الصينية | 0.5 م | س: ساقاي عديمة الفائدة اليوم، أنتم تحتفلون بالعيد، لذا سأقوم بنقل الطوب. ج: لقد ذهبت لكسب الكثير من المال في عيد الميلاد ليس لدي صديق، لذا فإن أي عطلة هي نفسها. |
نقدم أيضًا سلسلة من نماذج GPT الصينية التي تم تدريبها مسبقًا أولاً على مجموعة بيانات صينية جديدة ثم تم تدريبها بعد ذلك على مجموعة بيانات LCCC الخاصة بنا.
على غرار TransferTransfo، نقوم بجمع جميع تواريخ الحوار في جملة سياقية واحدة، ونستخدم هذه الجملة للتنبؤ بالاستجابة. يتكون مدخل نموذجنا من تضمين الكلمات، وتضمين المتحدث، والتضمين الموضعي لكل كلمة.
| نماذج | حجم المعلمة | مجموعة بيانات ما قبل التدريب | وصف |
|---|---|---|---|
| رواية جي بي تي | 95.5 م | رواية صينية | نموذج GPT تم تدريبه مسبقًا على مجموعة بيانات الرواية الصينية (1.3 مليار كلمة، لاحظ أننا لا نقدم تفاصيل هذا النموذج) |
| قاعدة CDial-GPT LCCC | 95.5 م | قاعدة LCCC | نموذج GPT تم تدريبه لاحقًا على مجموعة بيانات LCCC من GPT Novel |
| قاعدة CDial-GPT2 LCCC | 95.5 م | قاعدة LCCC | نموذج GPT2 تم تدريبه لاحقًا على مجموعة بيانات LCCC من GPT Novel |
| CDial-GPT LCCC-كبير | 95.5 م | LCCC-كبير | نموذج GPT تم تدريبه لاحقًا على مجموعة بيانات LCCC الكبيرة من GPT Novel |
التثبيت من رموز المصدر:
git clone https://github.com/thu-coai/CDial-GPT.git
cd CDial-GPT
pip install -r requirements.txt
الخطوة 1: إعداد البيانات للضبط الدقيق (على سبيل المثال، مجموعة بيانات STC أو "data/toy_data.json" في مستودعنا) والنموذج الذي تم اختباره مسبقًا:
# Download the STC dataset and unzip into "data_path" dir (fine-tuning on STC)
git lfs install
git clone https://huggingface.co/thu-coai/CDial-GPT_LCCC-large # or OpenAIGPTLMHeadModel.from_pretrained("thu-coai/CDial-GPT_LCCC-large")
ملاحظة: يمكنك تحميل القطار وتقسيم صالح لشركة STC من الروابط التالية: (Baidu Netdisk، Google Drive)
الخطوة 2: تدريب النموذج
python train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Single GPU training
أو
python -m torch.distributed.launch --nproc_per_node=8 train.py --pretrained --model_checkpoint thu-coai/CDial-GPT_LCCC-large --data_path data/STC.json --scheduler linear # Training on 8 GPUs
ملاحظة: لقد قدمنا أيضًا وسيطة train_path في البرنامج النصي للتدريب لقراءة مجموعة البيانات بنص عادي، والتي سيتم تقسيمها ومعالجتها بشكل توزيعي. يمكنك التفكير في استخدام هذه الوسيطة إذا كانت مجموعة البيانات كبيرة جدًا بالنسبة لذاكرة نظامك (أيضًا. تذكر أن تترك الوسيطة data_path فارغة إذا كنت تستخدم train_path ).
الخطوة 3: وضع الاستدلال
# YOUR_MODEL_PATH: the model path used for generation
python infer.py --model_checkpoint YOUR_MODEL_PATH --datapath data/STC_test.json --out_path STC_result.txt # Do Inference on a corpus
python interact.py --model_checkpoint YOUR_MODEL_PATH # Interact on the terminal
ملاحظة: يمكنك تحميل النسخة التجريبية من STC من الروابط التالية: (Baidu Netdisk، Google Drive)
حجج التدريب
| الحجج | يكتب | القيمة الافتراضية | وصف |
|---|---|---|---|
| model_checkpoint | شارع | "" | المسار أو عنوان URL لملفات النماذج (دليل نموذج التدريب المسبق وملفات التكوين/المفردات) |
| مدربين مسبقا | منطقي | خطأ شنيع | إذا كان خطأ، فقم بتدريب النموذج من الصفر |
| data_path | شارع | "" | مسار مجموعة البيانات |
| dataset_cache | شارع | الافتراضي = "dataset_cache" | المسار أو عنوان url لذاكرة التخزين المؤقت لمجموعة البيانات |
| مسار القطار | شارع | "" | مسار مجموعة التدريب لمجموعة البيانات الموزعة |
| valid_path | شارع | "" | مسار مجموعة التحقق من الصحة لمجموعة البيانات الموزعة |
| log_file | شارع | "" | سجلات الإخراج إلى ملف ضمن هذا المسار |
| num_workers | كثافة العمليات | 1 | عدد العمليات الفرعية لتحميل البيانات |
| n_epochs | كثافة العمليات | 70 | عدد فترات التدريب |
| Train_batch_size | كثافة العمليات | 8 | حجم الدفعة للتدريب |
| valid_batch_size | كثافة العمليات | 8 | حجم الدفعة للتحقق من صحتها |
| max_history | كثافة العمليات | 15 | عدد التبادلات السابقة التي يجب الاحتفاظ بها في التاريخ |
| جدولة | شارع | "نعوم" | طريقة المحسن |
| n_emd | كثافة العمليات | 768 | عدد n_emd في ملف التكوين (لـ noam) |
| eval_before_start | منطقي | خطأ شنيع | إذا كان هذا صحيحا، ابدأ التقييم قبل التدريب |
| Warmup_steps | كثافة العمليات | 5000 | خطوات الاحماء |
| valid_steps | كثافة العمليات | 0 | قم بإجراء التحقق من الصحة كل X من الخطوات، إذا لم تكن 0 |
| gradient_accumulation_steps | كثافة العمليات | 64 | تجميع التدرجات على عدة خطوات |
| max_norm | يطفو | 1.0 | لقطة قاعدة التدرج |
| جهاز | شارع | "cuda" إذا كان torch.cuda.is_available() وإلا "cpu" | الجهاز (كودا أو وحدة المعالجة المركزية) |
| fp16 | شارع | "" | اضبط على O0 أو O1 أو O2 أو O3 للتدريب على fp16 (راجع وثائق القمة) |
| local_rank | كثافة العمليات | -1 | الترتيب المحلي للتدريب الموزع (-1: غير موزع) |
يتم إجراء التقييم على النتائج الناتجة عن النماذج المضبوطة بدقة
مجموعة بيانات STC (تقسيم القطار/الصالح (Baidu Netdisk، Google Drive)، تقسيم الاختبار (Baidu Netdisk، Google Drive) يتم إنشاء جميع الاستجابات باستخدام مخطط Nucleus Sampling بحد أدنى 0.9 ودرجة حرارة 0.7.
| نماذج | حجم النموذج | شركته تنوي | بلو-2 | بلو-4 | حي-1 | حي-2 | مطابقة الجشع | متوسط التضمين |
|---|---|---|---|---|---|---|---|---|
| عناية-Seq2seq | 73 م | 34.20 | 3.93 | 0.90 | 8.5 | 11.91 | 65.84 | 83.38 |
| محول | 113 م | 22.10 | 6.72 | 3.14 | 8.8 | 13.97 | 66.06 | 83.55 |
| GPT2-دردشة | 88 م | - | 2.28 | 0.54 | 10.3 | 16.25 | 61.54 | 78.94 |
| رواية جي بي تي | 95.5 م | 21.27 | 5.96 | 2.71 | 8.0 | 11.72 | 66.12 | 83.34 |
| قاعدة GPT LCCC | 95.5 م | 18.38 | 6.48 | 3.08 | 8.3 | 12.68 | 66.21 | 83.54 |
| قاعدة GPT2 LCCC | 95.5 م | 22.76 | 5.69 | 2.50 | 7.7 | 10.87 | 66.24 | 83.46 |
| GPT LCCC-كبير | 95.5 م | 18.23 | 6.63 | 3.20 | 8.3 | 12.71 | 66.25 | 83.63 |
لقد استخدمنا أيضًا 3 تعليقات توضيحية من مصادر جماعية لتقييم 200 عينة من كل نموذج حول الطلاقة والملاءمة والتنوع بناءً على مخطط النتيجة 2/1/0، راجع ورقتنا للحصول على مزيد من التفاصيل.
| نماذج | +2 | +1 | +0 | كابا |
|---|---|---|---|---|
| عناية Seq2Seq | 27.1% | 21.4% | 51.4% | 0.4544 |
| محول | 42.4% | 23.6% | 34.0% | 0.4429 |
| GPT2-دردشة | 24.3% | 19,1% | 56.6% | 0.3941 |
| قاعدة GPT LCCC | 46.7% | 21.8% | 31.5% | 0.3954 |
| GPT LCCC-كبير | 48.6% | 24.5% | 27.0% | 0.4203 |
نختار بشكل عشوائي 1000 عينة، ونجري إحصائية حول توليد المواد السامة:
| تكرار | كلمة قذرة | حالات سيئة أخرى |
|---|---|---|
| ثلاثة وعشرين | 9 | 2 |
أمثلة تم إنشاؤها بدورة واحدة من مجموعة بيانات STC (تم ضبطها بدقة على STC):
| بريد | إجابة |
|---|---|
| هذه في الواقع بكين وليست هاربين. | يبدو أن الطقس في هاربين أفضل من الطقس في بكين، حيث تهطل أمطار خفيفة هنا وهناك رياح قوية خلال النهار. |
| كانت المنافسة الإعلانية في الحرم الجامعي للمشغل ممتعة للغاية! هاهاها. | اعتقدت أنه كان إعلان جاك ما. |
| فستان زفاف من سلسلة Delsa S posa كاندي كولور، وردي، أزرق، أحمر وأرجواني، مرح ومنعش، هل يعجبك؟ | الأخيرة جميلة جدًا، جميلة جدًا! |
أمثلة متعددة المنعطفات تم إنشاؤها باستخدام البرنامج النصي التفاعلي:
| رويل | إجابة |
|---|---|
| مستخدم | لا تحبني دون جدوى |
| بوت | الحب غير المثمر مؤلم جداً. |
| مستخدم | لكن لا بأس إذا كنت قد أحببته |
| بوت | في بعض الأحيان، الحب هو لعبة. |
| مستخدم | أنا دائما أخسر |
| بوت | أحبك بقدر ما أحبك. |
| مستخدم | هل يمكنك سحبها؟ |
| بوت | يمكنك سحبها. |
| مستخدم | لا تقلدني |
| بوت | ما أقوله هو أنك لا تستطيع أن تفعل ذلك. |
| مستخدم | أنت تجبرني على القيام بذلك، أليس كذلك؟ |
| بوت | لا، أنا أجبرك على الكلام، أليس كذلك؟ |
ييدا وانغ، بي كي، ينه تشنغ، كايلي هوانغ، يونغ جيانغ، شياو يان تشو، مينلي هوانغ
زوكسيان يي، ياو وانغ، ييفان بان
تهدف مجموعة بيانات LCCC والنماذج المدربة مسبقًا إلى تسهيل البحث من أجل توليد المحادثة. تأتي مجموعة بيانات LCCC المتوفرة في هذا المستودع من مصادر مختلفة. على الرغم من إجراء عملية تنظيف صارمة، ليس هناك ما يضمن وجود جميع المحتويات غير المناسبة تم تصفيتها بالكامل. لا تمثل جميع المحتويات الموجودة في مجموعة البيانات هذه رأي المؤلفين. يحتوي هذا المستودع على جزء فقط من آلية النمذجة اللازمة لإنتاج نموذج حوار فعليًا نحن لسنا مسؤولين عن أي محتويات تم إنشاؤها باستخدام نموذجنا.
يرجى التكرم بالاستشهاد بورقتنا البحثية إذا كنت تستخدم مجموعات البيانات أو النماذج في بحثك:
@inproceedings{wang2020chinese,
title={A Large-Scale Chinese Short-Text Conversation Dataset},
author={Wang, Yida and Ke, Pei and Zheng, Yinhe and Huang, Kaili and Jiang, Yong and Zhu, Xiaoyan and Huang, Minlie},
booktitle={NLPCC},
year={2020},
url={https://arxiv.org/abs/2008.03946}
}


