YAYI2
1.0.0

[الملف التمهيدي] [?HF Repo] [?إصدار الويب]
الصينية | انجليزية
[2024.03.28] يتم تحميل جميع النماذج والبيانات إلى مجتمع Magic Community.
[2023.12.22] أصدرنا التقرير الفني YAYI 2: نماذج اللغات الكبيرة متعددة اللغات مفتوحة المصدر.
YAYI 2 هو جيل جديد من نماذج اللغات الكبيرة مفتوحة المصدر التي طورتها Zhongke Wenge، بما في ذلك الإصدارات الأساسية والدردشة، بحجم معلمة يبلغ 30 بايت. YAYI2-30B هو نموذج لغة كبير يعتمد على Transformer، والذي يستخدم مجموعة عالية الجودة ومتعددة اللغات لأكثر من 2 تريليون رمز للتدريب المسبق. بالنسبة لسيناريوهات التطبيق العامة والخاصة بالمجال، نستخدم الملايين من التعليمات للضبط الدقيق، ونستخدم أساليب التعلم المعززة بالملاحظات البشرية لمواءمة النموذج بشكل أفضل مع القيم الإنسانية.
النموذج مفتوح المصدر هذه المرة هو النموذج الأساسي YAYI2-30B. نأمل في تعزيز تطوير مجتمع النماذج الكبيرة مفتوحة المصدر الصيني المدرب مسبقًا من خلال المصدر المفتوح لنماذج Yayi الكبيرة، والمساهمة بنشاط في ذلك. من خلال المصادر المفتوحة، نعمل مع كل شريك لبناء نموذج النظام البيئي الكبير لشركة Yayi.
لمزيد من التفاصيل الفنية، يرجى قراءة تقريرنا الفني YAYI 2: نماذج اللغات الكبيرة متعددة اللغات مفتوحة المصدر.
| اسم مجموعة البيانات | مقاس | تحديد نموذج التردد العالي | عنوان التحميل | شعار النموذج السحري | عنوان التحميل |
|---|---|---|---|---|---|
| YAYI2 بيانات ما قبل التدريب | 500 جرام | wenge-research/yayi2_pretrain_data | تحميل مجموعة البيانات | wenge-research/yayi2_pretrain_data | تحميل مجموعة البيانات |
| اسم النموذج | طول السياق | تحديد نموذج التردد العالي | عنوان التحميل | شعار النموذج السحري | عنوان التحميل |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | ينجي-الأبحاث/yayi2-30b | تحميل النموذج | ينجي-الأبحاث/yayi2-30b | تحميل النموذج |
| YAYI2-30B-دردشة | 4096 | ينجي-البحث/yayi2-30b-chat | قريباً... |
أجرينا تقييمات على مجموعات بيانات مرجعية متعددة، بما في ذلك C-Eval وMMLU وCMMLU وAGIEval وGAOKAO-Bench وGSM8K وMATH وBBH وHumanEval وMBPP. قمنا بفحص أداء النموذج في فهم اللغة، ومعرفة الموضوع، والتفكير الرياضي، والتفكير المنطقي، وتوليد التعليمات البرمجية. يُظهر نموذج YAYI 2 تحسينات كبيرة في الأداء مقارنة بالنماذج مفتوحة المصدر ذات الحجم المماثل.
| معرفة الموضوع | الرياضيات | المنطق المنطقي | شفرة | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| نموذج | C-التقييم (فال) | MMLU | AGIEval | CMMLU | جاوكاو-مقعد | GSM8K | الرياضيات | بي بي اتش | HumanEval | مبب |
| 5 طلقة | 5 طلقة | 3/0 طلقة | 5 طلقة | 0 طلقة | 8/4 طلقة | 4-طلقة | 3-طلقة | 0 طلقة | 3-طلقة | |
| إم بي تي-30ب | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32.8 |
| فالكون-40ب | - | 55.4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0.6 | 29.8 |
| LLaMA2-34B | - | 62.6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| بايتشوان2-13ب | 59.0 | 59.5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49.0 | 17.1 | 30.8 |
| كوين-14ب | 71.7 | 67.9 | 51.9 | 70.2 | 62.5 | 61.6 | 25.2 | 53.7 | 32.3 | 39.8 |
| إنترLM-20B | 58.8 | 62.1 | 44.6 | 59.0 | 45.5 | 52.6 | 7.9 | 52.5 | 25.6 | 35.6 |
| أكويلا2-34ب | 98.5 | 76.0 | 43.8 | 78.5 | 37.8 | 50.0 | 17.8 | 42.5 | 0.0 | 41.0 |
| يي-34ب | 81.8 | 76.3 | 56.5 | 82.6 | 68.3 | 67.6 | 15.9 | 66.4 | 26.2 | 38.2 |
| YAYI2-30B | 80.9 | 80.5 | 62.0 | 84.0 | 64.4 | 71.2 | 14.8 | 54.5 | 53.1 | 45.8 |
لقد أجرينا تقييمنا باستخدام كود المصدر المقدم من مستودع OpenCompass Github. بالنسبة لنماذج المقارنة، ندرج نتائج تقييمها في قائمة OpenCompass اعتبارًا من 15 ديسمبر 2023. بالنسبة للنماذج الأخرى التي لم تشارك في التقييم على منصة OpenCompass، بما في ذلك MPT وFalcon وLLaMa 2، اعتمدنا النتائج التي أبلغت عنها LLaMA 2.
نحن نقدم أمثلة بسيطة لتوضيح كيفية استخدام YAYI2-30B بسرعة للاستدلال. يمكن تشغيل هذا المثال على هاتف A100/A800 واحد.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_envيرجى ملاحظة أن هذا المشروع يتطلب Python 3.8 أو أعلى.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))عند زيارتك لأول مرة، يجب تنزيل النموذج وتحميله، الأمر الذي قد يستغرق بعض الوقت.
يدعم هذا المشروع الضبط الدقيق للتعليمات بناءً على السرعة العميقة لإطار التدريب الموزع، وتكوين البيئة وتنفيذ البرنامج النصي المقابل لبدء الضبط الدقيق للمعلمات الكاملة أو الضبط الدقيق لـ LoRA.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps تنسيق البيانات: راجع data/yayi_train_example.json ، وهو ملف JSON قياسي. تتكون كل قطعة من البيانات من "system" و "conversations" ، حيث تمثل "system" معلومات إعداد الدور العام ويمكن أن تكون سلسلة فارغة "conversations" . "conversations" عبارة عن جولات متعددة من الحوار بين الشخصيات البشرية وشخصيات الياي.
تعليمات التشغيل: قم بتشغيل الأمر التالي لبدء الضبط الدقيق للمعلمات الكاملة لنموذج Yayi. يدعم هذا الأمر التدريب على الأجهزة المتعددة والبطاقات المتعددة. يوصى باستخدام تكوين الأجهزة 16*A100 (80G) أو أعلى.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True أو ابدأ عبر سطر الأوامر:
bash scripts/start.sh يرجى ملاحظة أنه إذا كنت بحاجة إلى استخدام قالب ChatML لضبط التعليمات، فيمكنك تغيير --module training.trainer_yayi2 في الأمر إلى --module training.trainer_chatml ؛ إذا كنت بحاجة إلى تخصيص قالب الدردشة، فيمكنك تعديله النظام الموجود في قالب الدردشة الخاص بـ Trainer_chatml.py تعريفات رمزية خاصة للأدوار الثلاثة والمستخدم والمساعد. ما يلي هو مثال لقالب ChatML إذا تم استخدام هذا القالب أو القالب المخصص أثناء التدريب، فيجب أيضًا أن يكون متسقًا أثناء الاستدلال.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh في مرحلة ما قبل التدريب، لم نستخدم بيانات الإنترنت لتدريب القدرات اللغوية للنموذج فحسب، بل أضفنا أيضًا بيانات عامة مختارة وبيانات المجال لتعزيز المهارات المهنية للنموذج. توزيع البيانات على النحو التالي: 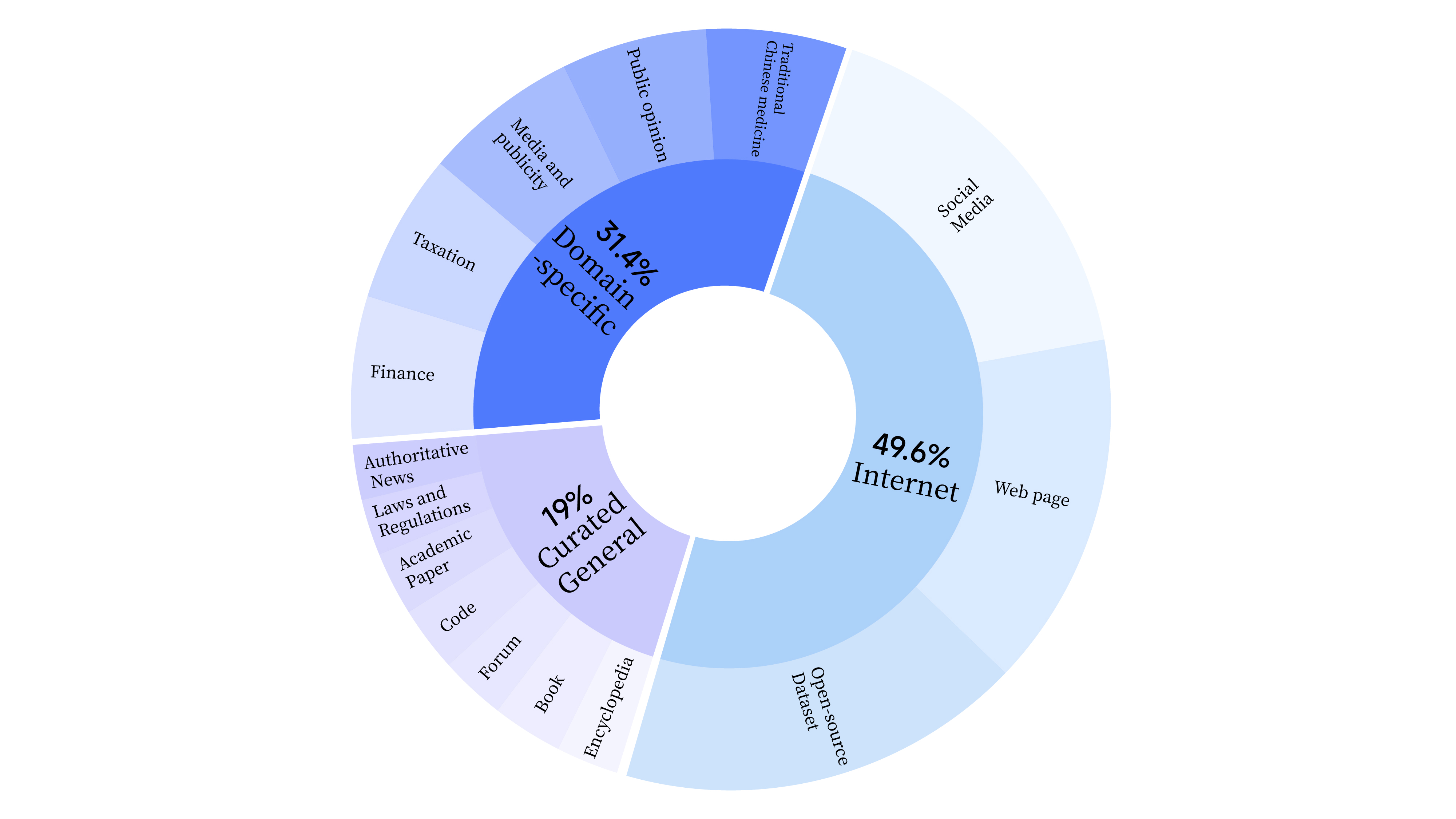
لقد قمنا ببناء مجموعة من مسارات معالجة البيانات لتحسين جودة البيانات في جميع الجوانب، بما في ذلك أربع وحدات: التوحيد القياسي، والتنظيف الإرشادي، وإلغاء البيانات المكررة متعدد المستويات، وتصفية السمية. لقد جمعنا إجمالي 240 تيرابايت من البيانات الأولية، ولم يبق سوى 10.6 تيرابايت من البيانات عالية الجودة بعد المعالجة المسبقة. العملية الشاملة هي كما يلي: 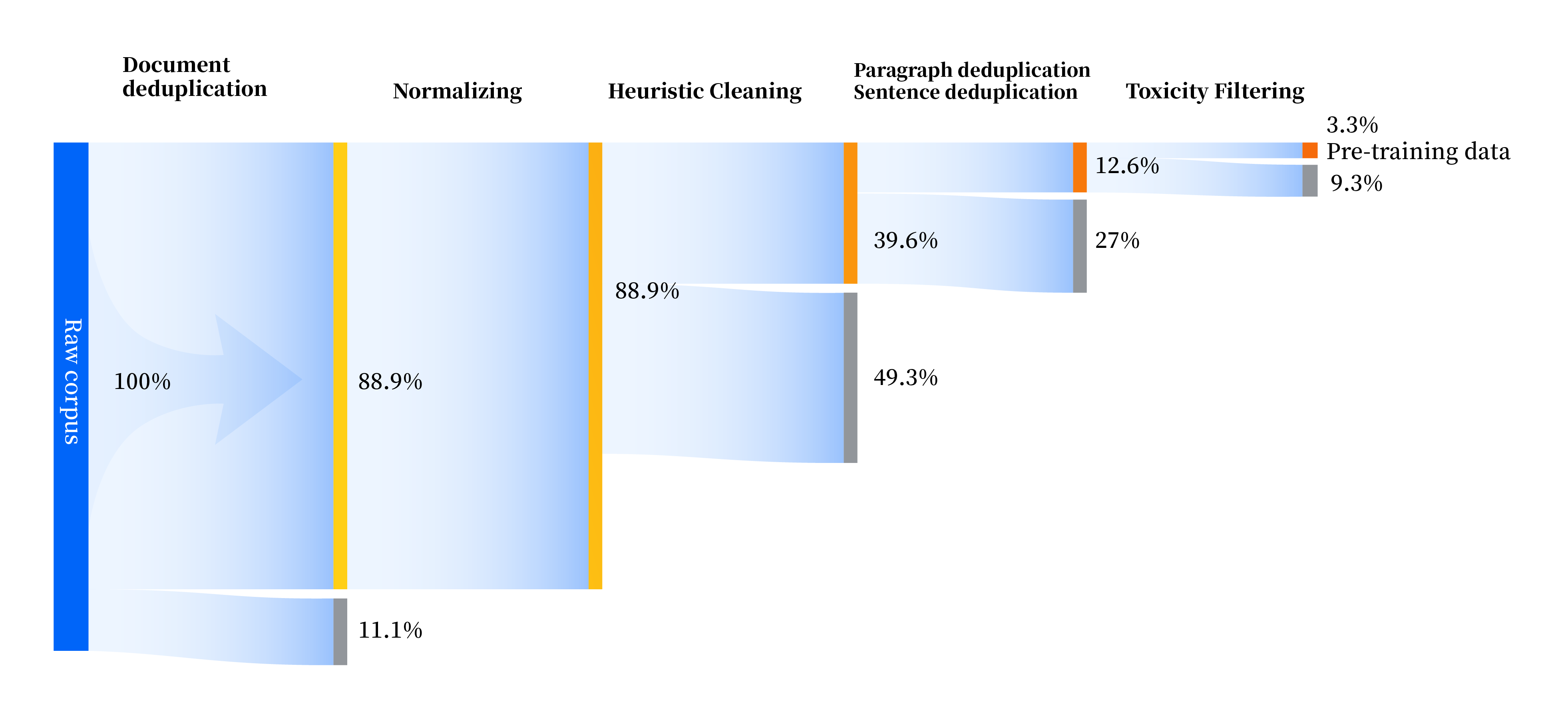

يظهر منحنى الخسارة لنموذج YAYI 2 في الشكل أدناه: 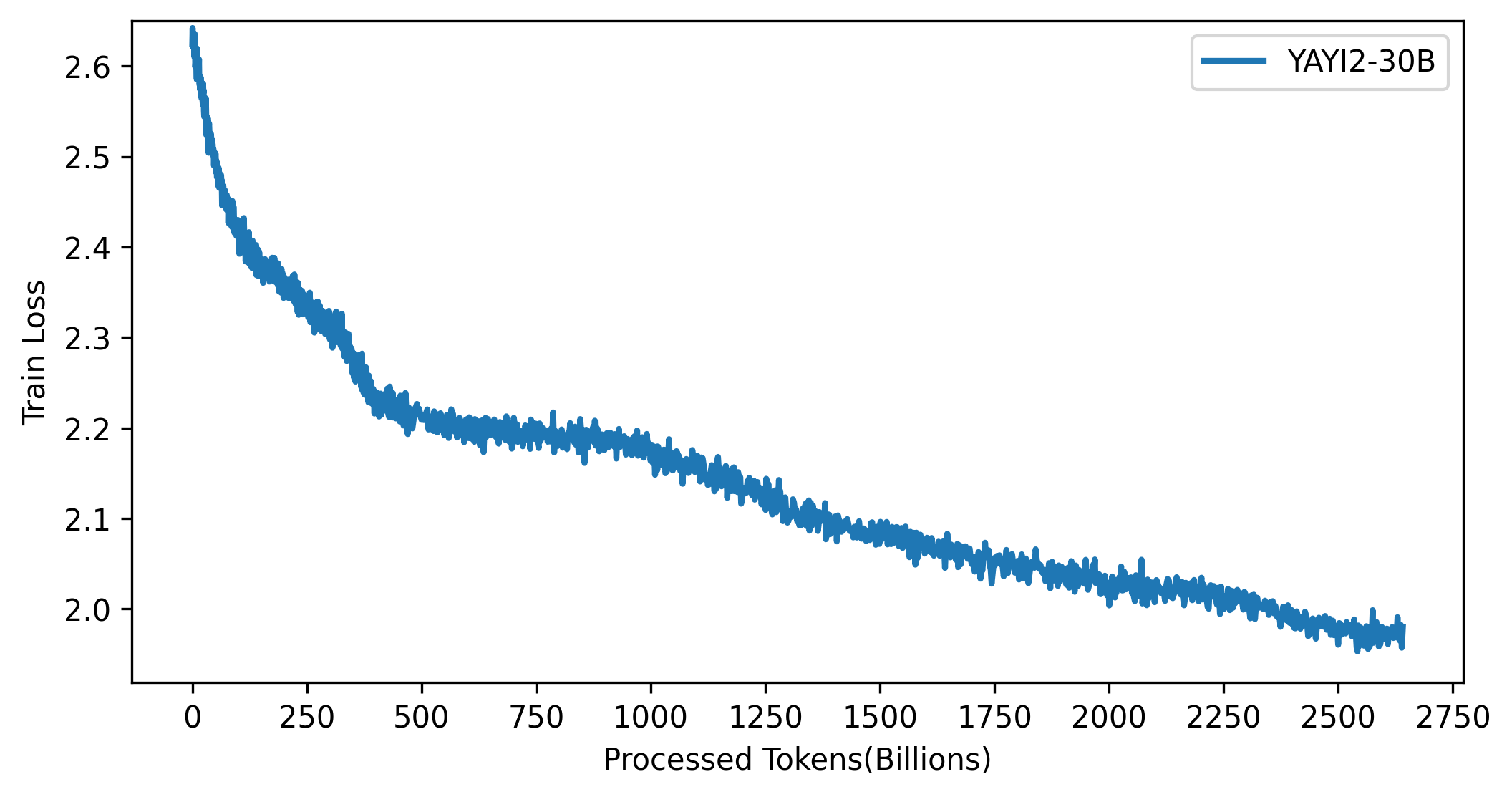
الكود الموجود في هذا المشروع مفتوح المصدر وفقًا لبروتوكول Apache-2.0، ويجب أن يتوافق استخدام المجتمع لنموذج YAYI 2 والبيانات مع "اتفاقية ترخيص مجتمع Yayi YAYI 2 النموذجية". إذا كنت بحاجة إلى استخدام نماذج سلسلة YAYI 2 أو مشتقاتها لأغراض تجارية، فيرجى إكمال "معلومات التسجيل التجاري لنموذج YAYI 2" وإرسالها إلى [email protected] وسوف نتصل بك في غضون 3 أيام عمل بعد تلقي البريد الإلكتروني سيتم إجراء المراجعة يوميًا. بعد اجتياز المراجعة، ستتلقى ترخيصًا تجاريًا. يرجى الالتزام الصارم بالمحتوى ذي الصلة في "اتفاقية الترخيص التجاري النموذجية YAYI 2" أثناء الاستخدام.
إذا كنت تستخدم نموذجنا في عملك، يرجى الاستشهاد بمقالتنا:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


