airllm
1.0.0

البداية السريعة | التكوينات | ماك | دفاتر الملاحظات النموذجية | التعليمات
تعمل AirLLM على تحسين استخدام ذاكرة الاستدلال، مما يسمح لـ 70B من نماذج اللغات الكبيرة بتشغيل الاستدلال على بطاقة GPU واحدة بسعة 4 جيجابايت دون التكميم والتقطير والتشذيب. ويمكنك تشغيل 405B Llama3.1 على ذاكرة فيديو بسعة 8 جيجابايت الآن.
[2024/08/20] الإصدار 2.11.0: دعم Qwen2.5
[2024/08/18] الإصدار 2.10.1 دعم استنتاج وحدة المعالجة المركزية. دعم النماذج غير المقسمة. شكرًا @NavodPeiris على العمل الرائع!
[2024/07/30] دعم Llama3.1 405B (مثال دفتر ملاحظات). دعم التكميم 8bit/4bit .
[2024/04/20] يدعم AirLLM Llama3 أصلاً بالفعل. قم بتشغيل Llama3 70B على وحدة معالجة رسومات واحدة بسعة 4 جيجابايت.
[2023/12/25] الإصدار 2.8.2: دعم نظام التشغيل MacOS الذي يعمل بنماذج لغات كبيرة تبلغ 70B.
[2023/12/20] الإصدار 2.7: دعم AirLLMMixtral.
[2023/12/20] الإصدار 2.6: تمت إضافة نموذج تلقائي، واكتشاف نوع النموذج تلقائيًا، دون الحاجة إلى توفير فئة النموذج لتهيئة النموذج.
[2023/12/18] الإصدار 2.5: تمت إضافة الجلب المسبق لتداخل تحميل النموذج وحسابه. تحسين السرعة بنسبة 10%.
[2023/12/03] تمت إضافة دعم ChatGLM و QWen و Baichuan و Mistral و InternLM !
[2023/12/02] تمت إضافة دعم لأجهزة الأمان. الآن قم بدعم جميع النماذج العشرة الأولى في لوحة المتصدرين المفتوحة.
[2023/12/01] إيرلم 2.0. دعم الضغطات: تسريع وقت التشغيل بمقدار 3 مرات!
[2023/11/20] الإصدار الأولي من airllm!
أولاً، قم بتثبيت حزمة airllm pip.
pip install airllmبعد ذلك، قم بتهيئة AirLLMLlama2، وقم بتمرير معرف مستودع Huggingface للنموذج المستخدم، أو المسار المحلي، ويمكن إجراء الاستدلال بشكل مشابه لنموذج المحول العادي.
( يمكنك أيضًا تحديد المسار لحفظ نموذج الطبقات المقسم من خلال Layer_shards_ Saving_path عند بدء تشغيل AirLLMLlama2.
from airllm import AutoModel
MAX_LENGTH = 128
# could use hugging face model repo id:
model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" )
# or use model's local path...
#model = AutoModel.from_pretrained("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")
input_text = [
'What is the capital of United States?' ,
#'I like',
]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 20 ,
use_cache = True ,
return_dict_in_generate = True )
output = model . tokenizer . decode ( generation_output . sequences [ 0 ])
print ( output )ملاحظة: أثناء الاستدلال، سيتم أولاً تحليل النموذج الأصلي وحفظه حسب الطبقة. يرجى التأكد من وجود مساحة كافية على القرص في دليل ذاكرة التخزين المؤقت لـ Huggingface.
لقد أضفنا للتو ضغط النموذج استنادًا إلى ضغط النموذج القائم على القياس الكمي. مما قد يؤدي إلى زيادة سرعة الاستدلال بما يصل إلى 3x ، مع فقدان دقة لا يمكن تجاهله تقريبًا! (انظر المزيد من تقييم الأداء ولماذا نستخدم التكميم الحكيم في هذه الورقة)
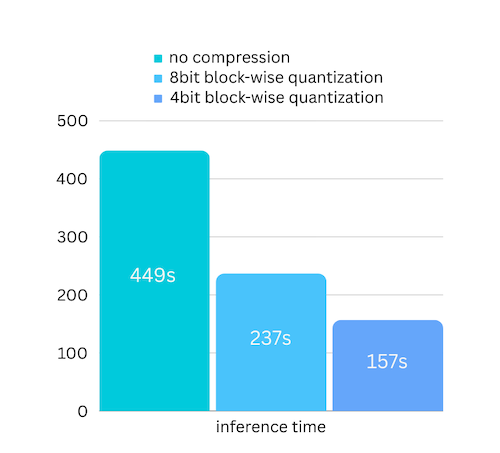
pip install -U bitsandbytespip install -U airllm model = AutoModel . from_pretrained ( "garage-bAInd/Platypus2-70B-instruct" ,
compression = '4bit' # specify '8bit' for 8-bit block-wise quantization
)يحتاج التكميم عادةً إلى تكميم كل من الأوزان والتنشيطات لتسريع الأمور حقًا. مما يجعل من الصعب الحفاظ على الدقة وتجنب تأثير القيم المتطرفة في جميع أنواع المدخلات.
في حين أن عنق الزجاجة في حالتنا هو بشكل أساسي عند تحميل القرص، نحتاج فقط إلى تقليل حجم تحميل النموذج. لذلك، علينا فقط تحديد كمية جزء الأوزان، وهو أمر أسهل لضمان الدقة.
عند تهيئة النموذج، ندعم التكوينات التالية:
ما عليك سوى تثبيت airllm وتشغيل الكود كما هو الحال في Linux. شاهد المزيد في البداية السريعة.
مثال [دفتر ملاحظات بايثون] (https://github.com/lyogavin/airllm/blob/main/air_llm/examples/run_on_macos.ipynb)
مثال colabs هنا:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "THUDM/chatglm3-6b-base" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = True )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "Qwen/Qwen-7B" )
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ]) from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel . from_pretrained ( "baichuan-inc/Baichuan2-7B-Base" )
#model = AutoModel.from_pretrained("internlm/internlm-20b")
#model = AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
input_text = [ 'What is the capital of China?' ,]
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH )
generation_output = model . generate (
input_tokens [ 'input_ids' ]. cuda (),
max_new_tokens = 5 ,
use_cache = True ,
return_dict_in_generate = True )
model . tokenizer . decode ( generation_output . sequences [ 0 ])يعتمد الكثير من التعليمات البرمجية على العمل الرائع الذي قام به SimJeg في مسابقة اختبار Kaggle. تحية كبيرة لـ SimJeg:
حساب GitHubSimJeg، الكود الموجود على Kaggle، المناقشة المرتبطة به.
safetensors_rust.SafetensorError: خطأ أثناء إلغاء تسلسل الرأس: MetadataIncompleteBuffer
إذا واجهت هذا الخطأ، فالسبب المحتمل هو نفاد مساحة القرص. عملية تقسيم النموذج تستهلك الكثير من القرص. انظر هذا. قد تحتاج إلى توسيع مساحة القرص لديك، ومسح ذاكرة التخزين المؤقت لـ Huggingface وإعادة التشغيل.
على الأرجح أنك تقوم بتحميل نموذج QWen أو ChatGLM بفئة Llama2. جرب ما يلي:
لنموذج QWen:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)لنموذج ChatGLM:
from airllm import AutoModel #<----- instead of AirLLMLlama2
AutoModel . from_pretrained (...)بعض النماذج عبارة عن نماذج مسورة، وتحتاج إلى رمز واجهة برمجة التطبيقات المعانقة. يمكنك توفير hf_token:
model = AutoModel . from_pretrained ( "meta-llama/Llama-2-7b-hf" , #hf_token='HF_API_TOKEN')لا يحتوي رمز بعض النماذج على رمز الحشو، لذا يمكنك تعيين رمز الحشو أو ببساطة إيقاف تشغيل تكوين الحشو:
input_tokens = model . tokenizer ( input_text ,
return_tensors = "pt" ,
return_attention_mask = False ,
truncation = True ,
max_length = MAX_LENGTH ,
padding = False #<----------- turn off padding
)إذا وجدت AirLLM مفيدًا في بحثك وترغب في الاستشهاد به، فيرجى استخدام إدخال BibTex التالي:
@software{airllm2023,
author = {Gavin Li},
title = {AirLLM: scaling large language models on low-end commodity computers},
url = {https://github.com/lyogavin/airllm/},
version = {0.0},
year = {2023},
}
رحب بالمساهمات والأفكار والمناقشات!
إذا وجدت أنه مفيد، من فضلك أو اشتر لي قهوة!


