WilmerAI
1.0.0
هذا مشروع شخصي قيد التطوير بشكل كبير. من الممكن أن يحتوي، ومن المحتمل أن يحتوي على أخطاء، أو تعليمات برمجية غير مكتملة، أو مشكلات أخرى غير مقصودة. وعلى هذا النحو، يتم توفير البرنامج كما هو، دون أي ضمان من أي نوع.
يعكس WilmerAI عمل مطور واحد وجهود وقته وموارده الشخصية؛ وأي آراء ومنهجيات وما إلى ذلك موجودة فيه هي آراءه الخاصة ويجب ألا تنعكس على صاحب العمل.
WilmerAI هو نظام وسيط متطور مصمم لتلقي المطالبات الواردة وتنفيذ مهام مختلفة عليها قبل إرسالها إلى LLM APIs. يتضمن هذا العمل استخدام نموذج لغة كبير (LLM) لتصنيف الموجه وتوجيهه إلى سير العمل المناسب أو معالجة سياق كبير (أكثر من 200000 رمز مميز) لإنشاء موجه أصغر وأكثر قابلية للإدارة ومناسب لمعظم النماذج المحلية.
يرمز WilmerAI إلى "ماذا لو قامت النماذج اللغوية بتوجيه كل الاستدلالات بخبرة؟"
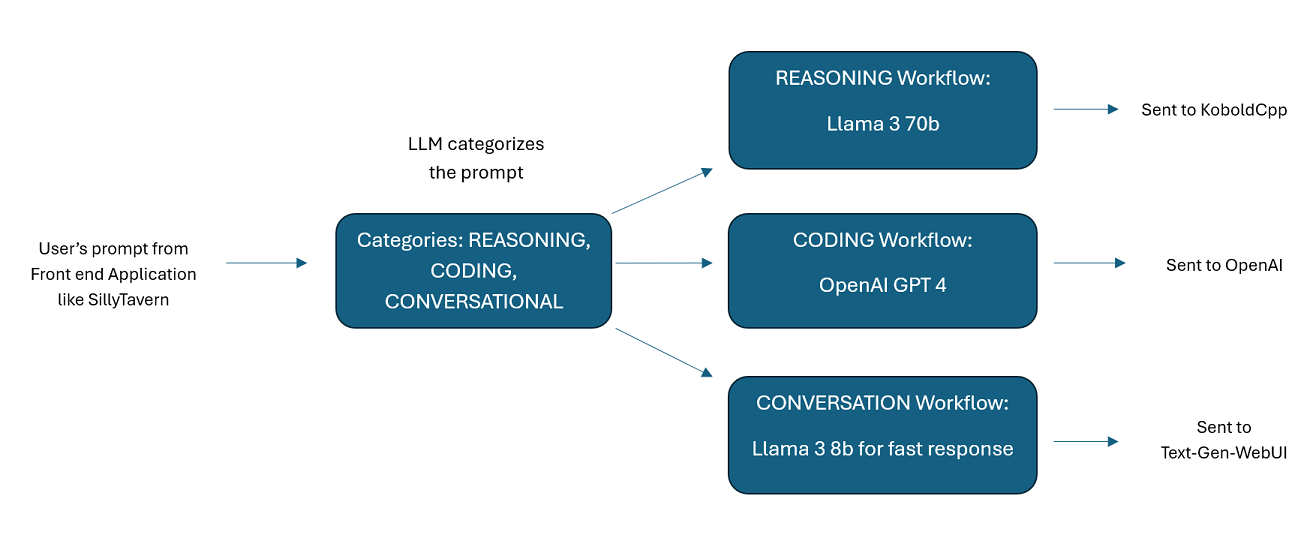
المساعدون الذين يتم تشغيلهم بواسطة العديد من LLMs جنبًا إلى جنب : يمكن توجيه المطالبات الواردة إلى "الفئات"، حيث يتم تشغيل كل فئة بواسطة سير عمل. يمكن أن يحتوي كل سير عمل على العدد الذي تريده من العقد، كل عقدة مدعومة بماجستير إدارة أعمال (LLM) مختلف. على سبيل المثال، إذا سألت مساعدك "هل يمكنك أن تكتب لي لعبة Snake بلغة python؟"، فقد يتم تصنيف ذلك على أنه CODING وينتقل إلى سير عمل البرمجة لديك. قد تطلب العقدة الأولى من سير العمل هذا من Codestral-22b (أو ChatGPT 4o إذا أردت) الإجابة على السؤال. قد تطلب العقدة الثانية من Deepseek V2 أو Claude Sonnet مراجعة التعليمات البرمجية لها. قد تطلب العقدة التالية من Codestral إعطاء قرار نهائي مرة أخرى ثم الرد عليك. سواء كان سير العمل الخاص بك مجرد نموذج واحد يستجيب لأنه أفضل مبرمج لديك، أو ما إذا كانت العقد العديدة الخاصة بـ LLMs المختلفة تعمل معًا لإنشاء استجابة - فالخيار لك.
دعم واجهة برمجة تطبيقات Wikipedia غير المتصلة بالإنترنت : لدى WilmerAI عقدة يمكنها إجراء مكالمات إلى OfflineWikipediaTextApi. هذا يعني أنه يمكن أن يكون لديك فئة، على سبيل المثال "FACTUAL"، التي تنظر إلى رسالتك الواردة، وتولد استعلامًا منها، وتستعلم عن واجهة برمجة تطبيقات ويكيبيديا لمقالة ذات صلة، وتستخدم تلك المقالة كإدخال سياق RAG للرد.
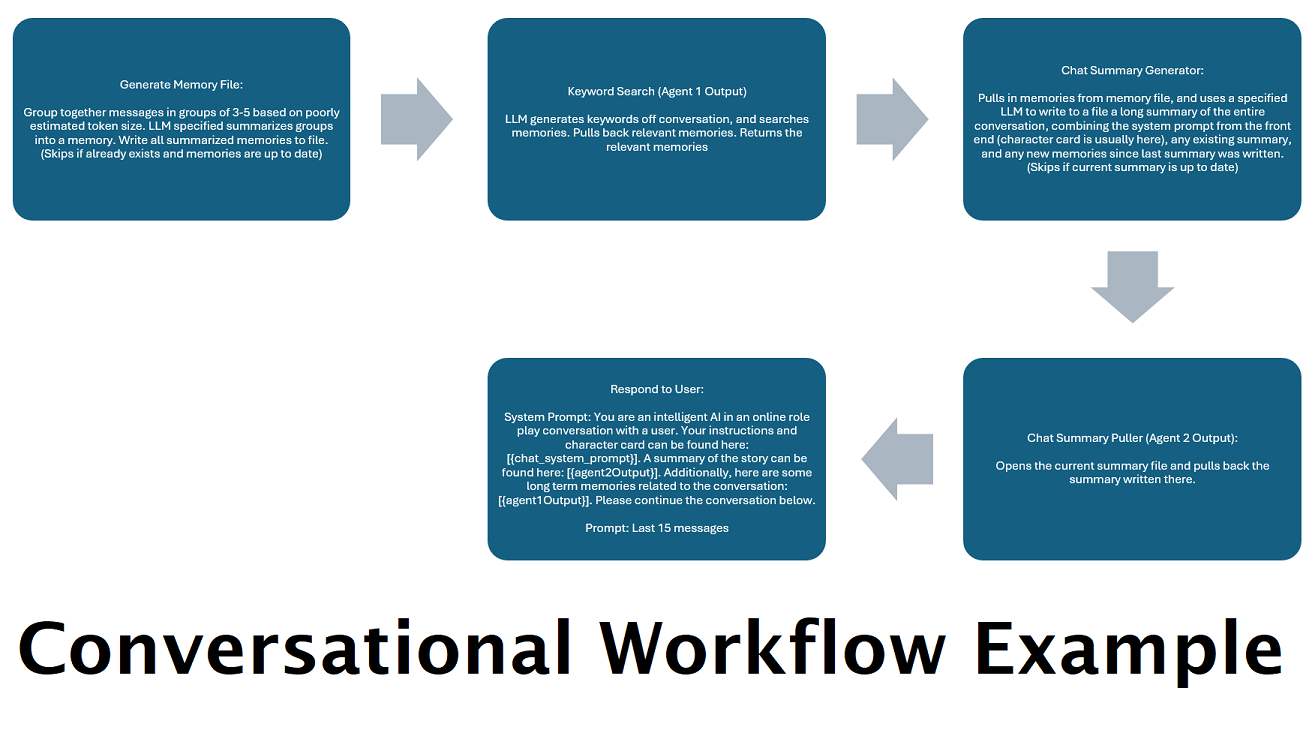
ملخصات الدردشة التي يتم إنشاؤها باستمرار لمحاكاة "الذاكرة" : ستقوم عقدة ملخص الدردشة بإنشاء "ذكريات"، عن طريق تقسيم رسائلك ثم تلخيصها وحفظها في ملف. سيأخذ بعد ذلك تلك الأجزاء الملخصة وينشئ ملخصًا مستمرًا ومحدثًا باستمرار للمحادثة بأكملها، والذي يمكن سحبه واستخدامه في موجه LLM. تتيح لك النتائج إجراء أكثر من 200 ألف محادثة سياقية وتتبع ما قيل حتى عند قصر المطالبات على LLM على سياق 5 آلاف أو أقل.
استخدم أجهزة كمبيوتر متعددة لمزامنة ذكريات واستجابات العمليات : إذا كان لديك جهازي كمبيوتر يمكنه تشغيل LLMs، فيمكنك تعيين أحدهما ليكون "المستجيب" والآخر ليكون مسؤولاً عن إنشاء الذكريات/الملخصات. يتيح لك هذا النوع من سير العمل الاستمرار في التحدث إلى ماجستير إدارة الأعمال الخاص بك أثناء تحديث الذكريات/الملخص، مع الاستمرار في استخدام الذكريات الموجودة. وهذا يعني عدم الحاجة إلى الانتظار حتى يتم تحديث الملخص، حتى إذا قمت بتكليف نموذج كبير وقوي للتعامل مع هذه المهمة بحيث يكون لديك ذكريات ذات جودة أعلى. (راجع مثال المستخدم convo-role-dual-model )
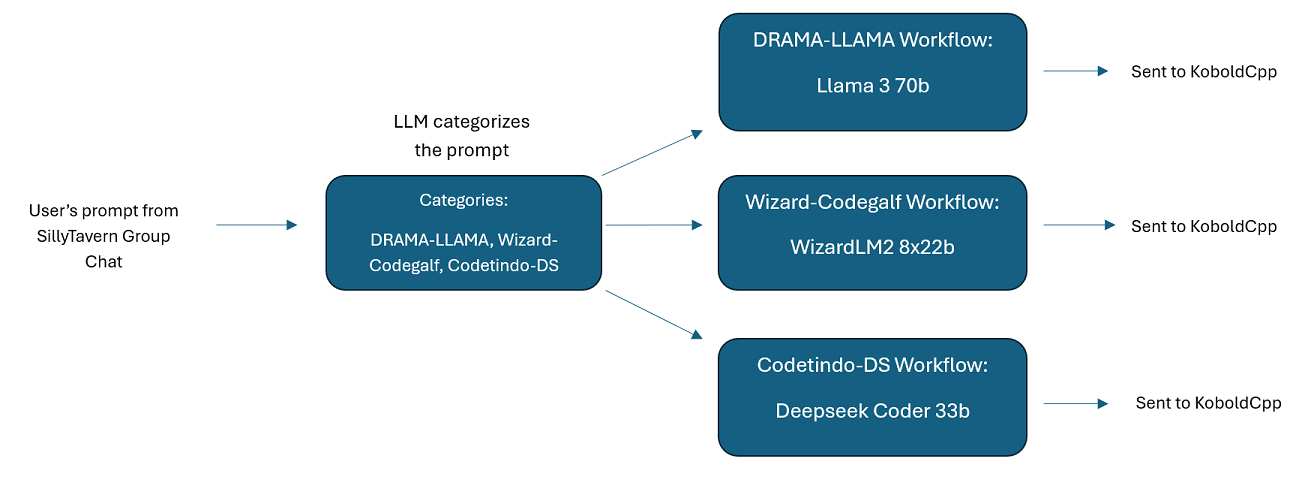
دردشات جماعية متعددة LLM في SillyTavern: من الممكن استخدام Wilmer لإجراء محادثة جماعية في ST حيث كل شخصية هي LLM مختلفة، إذا كنت ترغب في ذلك (يقوم المؤلف بذلك شخصيًا.) هناك أمثلة على الأحرف متاحة في DocsSillyTavern ، انقسموا إلى مجموعتين. هذه الأحرف/المجموعات النموذجية هي مجموعات فرعية من مجموعات أكبر يستخدمها المؤلف.
وظيفة البرامج الوسيطة: يقع WilmerAI بين الواجهة التي تستخدمها للتواصل مع LLM (مثل SillyTavern أو OpenWebUI أو حتى محطة برنامج Python) وواجهة برمجة التطبيقات الخلفية التي تخدم LLM. يمكنه التعامل مع العديد من LLMs الخلفية في وقت واحد.
استخدام LLMs متعددة في وقت واحد: مثال الإعداد: SillyTavern -> WilmerAI -> عدة مثيلات لـ KoboldCpp. على سبيل المثال، يمكن أن يكون Wilmer متصلاً بـ Command-R 35b، وCodestral 22b، وGemma-2-27b، ويستخدم كل ذلك في ردوده على المستخدم. طالما أن برنامج LLM الذي تختاره يتم عرضه عبر نقطة نهاية v1/Completion أو الدردشة/Completion، أو نقطة نهاية الإنشاء الخاصة بـ KoboldCpp، فيمكنك استخدامه.
الإعدادات المسبقة القابلة للتخصيص : يتم حفظ الإعدادات المسبقة في ملف json يمكنك تخصيصه بسهولة. يمكن إدارة كل الإعدادات المسبقة تقريبًا عبر json، بما في ذلك أسماء المعلمات. هذا يعني أنك لست مضطرًا إلى انتظار تحديث Wilmer للاستفادة من شيء جديد. على سبيل المثال، تم طرح DRY مؤخرًا على KoboldCpp. إذا لم يكن ذلك موجودًا في ملف json المُعد مسبقًا لـ Wilmer، فيجب أن تكون قادرًا على إضافته ببساطة والبدء في استخدامه.
نقاط نهاية API: توفر chat/Completions متوافقة مع OpenAI API ونقاط نهاية v1/Completions للاتصال بها عبر الواجهة الأمامية، ويمكن الاتصال بأي نوع في النهاية الخلفية. يسمح هذا بتكوينات معقدة، مثل الاتصال بـ Wilmer باعتباره v1/Completion API، ثم توصيل Wilmer بالدردشة/الإكمال، وv1/Completion KoboldCpp، وإنشاء نقاط النهاية كلها في نفس الوقت.
القوالب السريعة: يدعم القوالب السريعة لنقاط نهاية v1/Completions API. لدى WilmerAI أيضًا قالب المطالبة الخاص به للاتصالات من الواجهة الأمامية عبر v1/Completions . يمكن العثور على القالب في مجلد "Docs" وهو جاهز للتحميل إلى SillyTavern.

يرجى الأخذ في الاعتبار أن سير العمل، بطبيعته، يمكن أن يجري العديد من الاستدعاءات إلى نقطة نهاية واجهة برمجة التطبيقات (API) بناءً على كيفية إعدادها. لا يقوم WilmerAI بتتبع استخدام الرمز المميز، ولا يبلغ عن الاستخدام الدقيق للرمز المميز عبر واجهة برمجة التطبيقات (API) الخاصة به، ولا يقدم أي طريقة قابلة للتطبيق لمراقبة استخدام الرمز المميز. لذلك، إذا كان تتبع استخدام الرمز المميز مهمًا بالنسبة لك لأسباب تتعلق بالتكلفة، فيرجى التأكد من تتبع عدد الرموز المميزة التي تستخدمها عبر أي لوحة معلومات مقدمة لك من خلال واجهات برمجة تطبيقات LLM الخاصة بك، خاصة في وقت مبكر عندما تعتاد على هذا البرنامج.
يؤثر LLM الخاص بك بشكل مباشر على جودة WilmerAI. هذا مشروع يعتمد على LLM، حيث تعتمد التدفقات والمخرجات بشكل كامل تقريبًا على LLMs المتصلة واستجاباتهم. إذا قمت بتوصيل Wilmer بنموذج ينتج مخرجات ذات جودة أقل، أو إذا كانت إعداداتك المسبقة أو قالب المطالبة به عيوب، فستكون جودة Wilmer الإجمالية أقل جودة أيضًا. لا يختلف الأمر كثيرًا عن سير عمل الوكلاء بهذه الطريقة.
بينما يبذل المؤلف قصارى جهده لصنع شيء مفيد وعالي الجودة، فهذا مشروع منفرد طموح ولا بد أن يواجه مشاكله (خاصة وأن المؤلف ليس مطور بايثون أصلاً، واعتمد بشكل كبير على الذكاء الاصطناعي لمساعدته في الحصول على هذا) بعيد). ومع ذلك، فهو يكتشف ذلك ببطء.
يكشف ويلمر عن كل من OpenAI v1/Completions ونقطة نهاية الدردشة/Completions، مما يجعله متوافقًا مع معظم الواجهات الأمامية. على الرغم من أنني استخدمت هذا بشكل أساسي مع SillyTavern، فقد يعمل أيضًا مع Open-WebUI.
للاتصال بإكمال النص في SillyTavern، اتبع الخطوات التالية (لقطة الشاشة أدناه مأخوذة من SillyTavern):
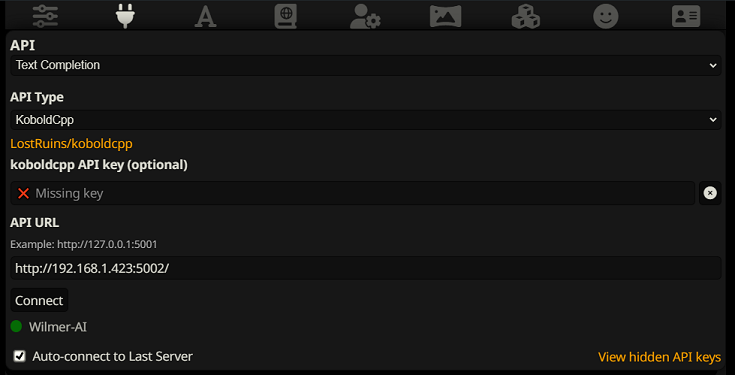
عند استخدام إكمال النص، تحتاج إلى استخدام تنسيق قالب المطالبة الخاص بـ WilmerAI. يمكن العثور على ملف ST قابل للاستيراد داخل Docs/SillyTavern/InstructTemplate . يتم تضمين قالب السياق أيضًا إذا كنت ترغب في استخدامه أيضًا.
يبدو قالب التعليمات كما يلي:
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
من سيلي تافرن:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
لا توجد أسطر جديدة أو أحرف متوقعة بين العلامات.
يرجى التأكد من أن قالب السياق "ممكّن" (مربع الاختيار أعلى القائمة المنسدلة)
للاتصال بإكمالات الدردشة في SillyTavern، اتبع الخطوات التالية (لقطة الشاشة أدناه مأخوذة من SillyTavern):
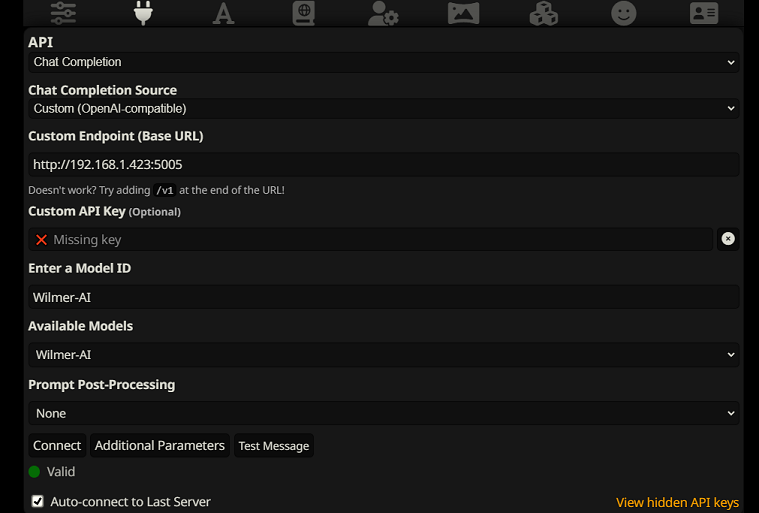
chatCompleteAddUserAssistant على true. (لا أوصي بتعيين كليهما على "صحيح" في نفس الوقت. قم إما بأسماء الشخصيات من SillyTavern، أو المستخدم/المساعد من Wilmer. وقد يرتبك الذكاء الاصطناعي بخلاف ذلك.)بالنسبة لأي من نوعي الاتصال، أوصي بالانتقال إلى الرمز "A" في SillyTavern وتحديد "تضمين الأسماء" و"فرض المجموعات والشخصيات" ضمن وضع التعليمات، ثم الانتقال إلى الرمز الموجود في أقصى اليسار (حيث توجد عينات العينات) والتحقق من " دفق" في أعلى اليسار، ثم في أعلى اليمين، حدد "فتح" ضمن السياق واسحبه إلى 200000+. دع ويلمر يقلق بشأن السياق.
لا يوجد لدى ويلمر حاليًا واجهة مستخدم؛ يتم التحكم في كل شيء عبر ملفات تكوين JSON الموجودة في المجلد "العامة". يحتوي هذا المجلد على كافة التكوينات الأساسية. عند تحديث أو تنزيل نسخة جديدة من WilmerAI، يجب عليك ببساطة نسخ المجلد "العام" الخاص بك إلى التثبيت الجديد للاحتفاظ بإعداداتك.
سيرشدك هذا القسم خلال عملية إعداد Wilmer. لقد قسمت الأقسام إلى خطوات؛ قد أوصي بنسخ كل خطوة، 1 × 1، في LLM وأطلب منها مساعدتك في إعداد القسم. وهذا قد يجعل الأمر أسهل بكثير.
ملاحظات هامة
من المهم ملاحظة ثلاثة أشياء حول إعداد ويلمر.
أ) الملفات المعدة مسبقًا قابلة للتخصيص بنسبة 100%. ما هو موجود في هذا الملف يذهب إلى llm API. وذلك لأن واجهات برمجة التطبيقات السحابية لا تتعامل مع بعض الإعدادات المسبقة المتنوعة التي تتعامل معها واجهات برمجة تطبيقات LLM المحلية. على هذا النحو، إذا كنت تستخدم OpenAI API أو خدمات سحابية أخرى، فمن المحتمل أن تفشل المكالمات إذا كنت تستخدم أحد إعدادات الذكاء الاصطناعي المحلية المعتادة. يرجى الاطلاع على الإعداد المسبق "OpenAI-API" للحصول على مثال لما يقبله openAI.
ب) لقد قمت مؤخرًا باستبدال جميع المطالبات في Wilmer للانتقال من استخدام ضمير الغائب إلى ضمير الغائب. لقد كان لهذا نتائج جيدة جدًا بالنسبة لي، وآمل أن يكون الأمر كذلك بالنسبة لك أيضًا.
ج) افتراضيًا، يتم تعيين جميع ملفات المستخدم لتشغيل استجابات التدفق. تحتاج إما إلى تمكين هذا في الواجهة الأمامية التي تتصل بـ Wilmer بحيث يتطابق كلاهما، أو تحتاج إلى الانتقال إلى Users/username.json وتعيين Stream على "false". إذا كان لديك عدم تطابق، حيث تتوقع/لا تتوقع الواجهة الأمامية البث ويتوقع ويلمر العكس، فمن المحتمل ألا يظهر أي شيء على الواجهة الأمامية.
تثبيت Wilmer بسيط ومباشر. تأكد من تثبيت بايثون؛ يستخدم المؤلف البرنامج مع Python 3.10 و3.12، وكلاهما يعمل بشكل جيد.
الخيار 1: استخدام البرامج النصية المتوفرة
للراحة، يتضمن Wilmer ملف BAT لنظام التشغيل Windows وملف .sh لنظام التشغيل macOS. ستقوم هذه البرامج النصية بإنشاء بيئة افتراضية، وتثبيت الحزم المطلوبة من requirements.txt ، ثم تشغيل Wilmer. يمكنك استخدام هذه البرامج النصية لبدء Wilmer في كل مرة.
.bat المتوفر..sh المتوفر.هام: لا تقم مطلقًا بتشغيل ملف BAT أو SH دون فحصه أولاً، لأن ذلك قد يكون محفوفًا بالمخاطر. إذا لم تكن متأكدًا من أمان مثل هذا الملف، فافتحه في Notepad/TextEdit، وانسخ المحتويات ثم اطلب من LLM مراجعته بحثًا عن أي مشكلات محتملة.
الخيار 2: التثبيت اليدوي
وبدلاً من ذلك، يمكنك تثبيت التبعيات يدويًا وتشغيل Wilmer من خلال الخطوات التالية:
تثبيت الحزم المطلوبة:
pip install -r requirements.txtابدأ البرنامج:
python server.pyتم تصميم البرامج النصية المتوفرة لتبسيط العملية من خلال إعداد بيئة افتراضية. ومع ذلك، يمكنك تجاهلها بأمان إذا كنت تفضل التثبيت اليدوي.
ملاحظة : عند تشغيل ملف Bat أو ملف sh أو ملف python، تقبل الملفات الثلاثة الآن الوسيطات الاختيارية التالية:
لذلك، على سبيل المثال، النظر في عمليات التشغيل المحتملة التالية:
bash run_macos.sh (سيستخدم المستخدم المحدد في _current-user.json، والتكوينات في "عام"، والسجلات في "السجلات")bash run_macos.sh --User "single-model-assistant" (سيكون افتراضيًا عامًا للتكوينات و"السجل" للسجلات)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" (سيستخدم فقط الإعداد الافتراضي لـ "logs"bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"تسمح هذه الوسيطات الاختيارية للمستخدمين بتدوير مثيلات متعددة من WilmerAI، كل مثيل يستخدم ملف تعريف مستخدم مختلف، وتسجيل الدخول إلى مكان مختلف، وتحديد التكوينات في موقع مختلف، إذا رغبت في ذلك.
ستجد ضمن Public/Configs سلسلة من المجلدات التي تحتوي على ملفات json. المجلدان الأكثر اهتمامًا بهما هما مجلد Endpoints ومجلد Users .
ملاحظة: ستحاول عقد سير العمل الفعلية لمستخدمي assistant-single-model assistant-multi-model group-chat-example الاستفادة من مشروع OfflineWikipediaTextApi لسحب مقالات ويكيبيديا الكاملة إلى RAG مقابلها. إذا لم يكن لديك واجهة برمجة التطبيقات هذه، فمن المفترض ألا يواجه سير العمل أية مشكلات، ولكنني شخصيًا أستخدم واجهة برمجة التطبيقات هذه للمساعدة في تحسين الاستجابات الواقعية التي أحصل عليها. يمكنك تحديد عنوان IP لواجهة برمجة التطبيقات (API) الخاصة بك في المستخدم json الذي تختاره.
أولاً، اختر مستخدم القالب الذي ترغب في استخدامه:
Assistant-single-model : هذا القالب مخصص لنموذج صغير واحد يتم استخدامه على جميع العقد. يحتوي هذا أيضًا على مسارات للعديد من أنواع الفئات المختلفة ويستخدم الإعدادات المسبقة المناسبة لكل عقدة. إذا كنت تتساءل عن سبب وجود مسارات لفئات مختلفة عندما يكون هناك نموذج واحد فقط: فهذا حتى تتمكن من منح كل فئة إعداداتها المسبقة الخاصة بها، وأيضًا حتى تتمكن من إنشاء مهام سير عمل مخصصة لها. ربما تريد من المبرمج أن يقوم بتكرارات متعددة للتحقق من نفسه، أو التفكير في الأشياء في خطوات متعددة.
مساعد متعدد النماذج : هذا القالب مخصص لاستخدام العديد من النماذج جنبًا إلى جنب. بالنظر إلى نقاط النهاية لهذا المستخدم، يمكنك أن ترى أن كل فئة لها نقطة النهاية الخاصة بها. لا يوجد ما يمنعك على الإطلاق من إعادة استخدام نفس واجهة برمجة التطبيقات لفئات متعددة. على سبيل المثال، يمكنك استخدام Llama 3.1 70b للبرمجة والرياضيات والاستدلال، وCommand-R 35b 08-2024 للتصنيف والمحادثة والواقعية. لا تشعر أنك بحاجة إلى 10 نماذج مختلفة. هذا ببساطة للسماح لك بإحضار هذا العدد إذا كنت تريد ذلك. يستخدم هذا المستخدم الإعدادات المسبقة المناسبة لكل عقدة في سير العمل.
convo-roleplay-single-model : يستخدم هذا المستخدم نموذجًا واحدًا بسير عمل مخصص مناسب للمحادثات، ويجب أن يكون جيدًا للعب الأدوار (في انتظار التعليقات للتعديل إذا لزم الأمر). هذا يتجاوز كافة التوجيه.
convo-roleplay-dual-model : يستخدم هذا المستخدم نموذجين مع سير عمل مخصص مناسب للمحادثات، ويجب أن يكون جيدًا للعب الأدوار (في انتظار التعليقات للتعديل إذا لزم الأمر). هذا يتجاوز كافة التوجيه. ملاحظة : يعمل سير العمل هذا بشكل أفضل إذا كان لديك جهازي كمبيوتر يمكنهم تشغيل LLMs. باستخدام الإعداد الحالي لهذا المستخدم، عندما ترسل رسالة إلى Wilmer، سوف يستجيب لك نموذج المستجيب (الكمبيوتر 1). ثم سيطبق سير العمل "تأمين سير العمل" عند هذه النقطة. سيبدأ بعد ذلك نموذج ملخص الذاكرة/الدردشة (الكمبيوتر 2) في تحديث الذكريات وملخص المحادثة حتى الآن، والذي يتم تمريره إلى المستجيب لمساعدته على تذكر الأشياء. إذا كنت سترسل مطالبة أخرى أثناء كتابة الذكريات، فسيقوم المستجيب (الكمبيوتر 1) بالتقاط أي ملخص موجود والمضي قدمًا والرد عليك. سيمنعك قفل سير العمل من إعادة الدخول إلى قسم الذكريات الجديدة. ما يعنيه هذا هو أنه يمكنك الاستمرار في التحدث إلى نموذج المستجيب الخاص بك أثناء كتابة الذكريات الجديدة. هذه زيادة كبيرة في الأداء. لقد قمت بتجربتها، وبالنسبة لي كانت أوقات الاستجابة مذهلة. بدون ذلك، أحصل على ردود خلال 30 ثانية 3-5 مرات، ثم أنتظر فجأة لمدة دقيقتين لتوليد الذكريات. مع هذا، تبلغ مدة كل رسالة 30 ثانية، في كل مرة، على Llama 3.1 70b على جهاز Mac Studio الخاص بي.
مثال للدردشة الجماعية : هذا المستخدم هو مثال لمحادثاتي الجماعية الشخصية. الشخصيات والمجموعات المضمنة هي شخصيات فعلية ومجموعات فعلية أستخدمها. يمكنك العثور على أمثلة الأحرف في مجلد Docs/SillyTavern . هذه هي الأحرف المتوافقة مع SillyTavern والتي يمكنك استيرادها مباشرةً إلى هذا البرنامج أو أي برنامج يدعم أنواع استيراد الأحرف بتنسيق png. تحتوي شخصيات فريق التطوير على عقدة واحدة فقط لكل سير عمل: فهي ببساطة تستجيب لك. تحتوي أحرف المجموعة الاستشارية على عقدتين لكل سير عمل: العقدة الأولى تولد استجابة، والعقدة الثانية تفرض "شخصية" الشخصية (نقطة النهاية المسؤولة عن ذلك هي نقطة نهاية businessgroup-speaker ). تساعد شخصيات الدردشة الجماعية كثيرًا في تنويع الردود التي تحصل عليها، حتى لو كنت تستخدم نموذجًا واحدًا فقط. ومع ذلك، أهدف إلى استخدام نماذج مختلفة لكل شخصية (ولكن إعادة استخدام النماذج بين المجموعات؛ لذلك، على سبيل المثال، لدي شخصية نموذج Llama 3.1 70b في كل مجموعة).
بمجرد تحديد المستخدم الذي تريد استخدامه، هناك خطوتان يجب تنفيذهما:
قم بتحديث نقاط النهاية للمستخدم الخاص بك ضمن Public/Configs/Endpoints. يتم فرز أحرف المثال في مجلدات لكل منها. يتم تحديد مجلد نقطة النهاية الخاص بالمستخدم في أسفل ملف user.json الخاص به. سوف تحتاج إلى ملء كل نقطة نهاية بشكل مناسب لبرامج LLM التي تستخدمها. يمكنك العثور على بعض أمثلة نقاط النهاية ضمن مجلد _example-endpoints .
سوف تحتاج إلى تعيين المستخدم الحالي الخاص بك. يمكنك القيام بذلك عند تشغيل ملف Bat/sh/py باستخدام وسيطة --User، أو يمكنك القيام بذلك في Public/Configs/Users/_current-user.json. ما عليك سوى وضع اسم المستخدم باعتباره المستخدم الحالي وحفظه.
ستحتاج إلى فتح ملف json الخاص بالمستخدم وإلقاء نظرة خاطفة على الخيارات. هنا يمكنك تعيين ما إذا كنت تريد البث أم لا، ويمكنك تعيين عنوان IP لواجهة برمجة تطبيقات wiki غير المتصلة بالإنترنت (إذا كنت تستخدمها)، وتحديد المكان الذي تريد أن تنتقل إليه ذكرياتك/ملفاتك الموجزة أثناء تدفقات معرف المناقشة، وكذلك تحديد المكان الذي تريد نقله إليه. تريد استخدام sqllite db إذا كنت تستخدم Workflow Locks.
هذا كل شيء! قم بتشغيل ويلمر، واتصل به، ويجب أن تكون جاهزًا للانطلاق.
أولاً، سنقوم بإعداد نقاط النهاية والنماذج. ضمن المجلد Public/Configs، من المفترض أن تشاهد المجلدات الفرعية التالية. دعنا نتعرف على ما تحتاجه.
تمثل ملفات التكوين هذه نقاط نهاية LLM API التي تتصل بها. على سبيل المثال، يحدد ملف JSON التالي، SmallModelEndpoint.json ، نقطة النهاية:
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}تمثل ملفات التكوين هذه أنواع واجهات برمجة التطبيقات المختلفة التي قد تصل إليها عند استخدام Wilmer.
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
} تحدد هذه الملفات قالب المطالبة للنموذج. خذ بعين الاعتبار المثال التالي، llama3.json :
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
} يتم تطبيق هذه القوالب على جميع استدعاءات نقطة النهاية v1/Completion. إذا كنت تفضل عدم استخدام قالب، فهناك ملف يسمى _chatonly.json يقوم بتقسيم الرسائل ذات الأسطر الجديدة فقط.
يتضمن إنشاء مستخدم وتنشيطه أربع خطوات رئيسية. اتبع الإرشادات أدناه لإعداد مستخدم جديد.
أولاً، داخل مجلد Users ، قم بإنشاء ملف JSON للمستخدم الجديد. أسهل طريقة للقيام بذلك هي نسخ ملف JSON مستخدم موجود، ولصقه كنسخة مكررة، ثم إعادة تسميته. فيما يلي مثال لملف JSON للمستخدم:
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0 ، مما يجعله مرئيًا على شبكتك إذا تم تشغيله على كمبيوتر آخر. يتم دعم تشغيل مثيلات متعددة من Wilmer على منافذ مختلفة.true ، يتم تعطيل جهاز التوجيه، وتنتقل كافة المطالبات إلى سير العمل المحدد فقط، مما يجعله مثيلًا واحدًا لسير عمل Wilmer.customWorkflowOverride true .Routing ، بدون الامتداد .json .DiscussionId .chatCompleteAddUserAssistant true .DataFinder الخاصة بمجموعة الأمثلة. بعد ذلك، قم بتحديث الملف _current-user.json لتحديد المستخدم الذي تريد استخدامه. قم بمطابقة اسم ملف JSON للمستخدم الجديد، بدون الامتداد .json .
ملاحظة : يمكنك تجاهل هذا إذا كنت تريد استخدام الوسيطة --User عند تشغيل Wilmer بدلاً من ذلك.
قم بإنشاء ملف JSON للتوجيه في مجلد Routing . يمكن تسمية هذا الملف بأي شيء تريده. قم بتحديث خاصية routingConfig في ملف JSON للمستخدم الخاص بك بهذا الاسم، بدون الامتداد .json . فيما يلي مثال لملف تكوين التوجيه:
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json ، الذي يتم تشغيله إذا تم اختيار الفئة. في مجلد Workflow ، قم بإنشاء مجلد جديد يطابق اسم المستخدم من مجلد Users . أسرع طريقة للقيام بذلك هي نسخ مجلد مستخدم موجود، وتكراره، وإعادة تسميته.
إذا اخترت عدم إجراء أي تغييرات أخرى، فستحتاج إلى مراجعة سير العمل وتحديث نقاط النهاية للإشارة إلى نقطة النهاية التي تريدها. إذا كنت تستخدم نموذجًا لسير عمل تمت إضافته مع Wilmer، فيجب أن تكون على ما يرام هنا بالفعل.
ضمن المجلد "العامة" يجب أن يكون لديك:
يتم تعديل سير العمل في هذا المشروع والتحكم فيه في المجلد Public/Workflows ، داخل مجلد سير العمل الخاص بالمستخدم الخاص بك. على سبيل المثال، إذا كان اسم المستخدم الخاص بك socg وكان لديك ملف socg.json في مجلد Users ، فيجب أن يكون لديك مجلد Workflows/socg ضمن مهام سير العمل.
فيما يلي مثال لما قد يبدو عليه سير العمل JSON:
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
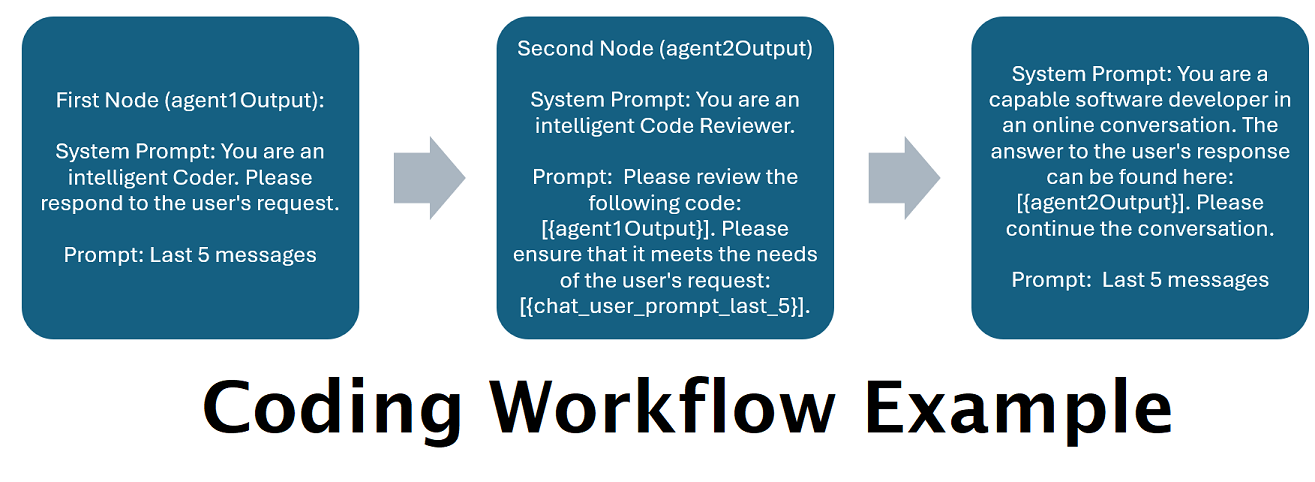
]يتكون سير العمل أعلاه من عقد محادثة. تقوم كلتا العقدتين بشيء واحد بسيط: إرسال رسالة إلى LLM المحدد عند نقطة النهاية.
title . من المفيد تسمية هذه النهايات بـ "واحد"، "اثنين"، وما إلى ذلك، لتتبع مخرجات الوكيل. يتم حفظ مخرجات العقدة الأولى في {agent1Output} ، والثانية في {agent2Output} ، وهكذا.Endpoints ، بدون الامتداد .json .Presets ، بدون الامتداد .json .false (راجع المثال الأول للعقدة أعلاه). إذا قمت بإرسال مطالبة، فاضبط هذا على أنه true (راجع عقدة المثال الثاني أعلاه). NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
يمكنك استخدام العديد من المتغيرات ضمن هذه المطالبات. سيتم استبدالها بشكل مناسب في وقت التشغيل:
{chat_user_prompt_last_one} : الرسالة الأخيرة في المحادثة ، دون أن يلفت علامات قالب موجه الرسالة.{templated_user_prompt_last_one} : الرسالة الأخيرة في المحادثة ، ملفوفة في علامات قالب المستخدم/المساعد المناسبة.{chat_system_prompt} : تم إرسال موجه النظام من الواجهة الأمامية. غالبًا ما يحتوي على بطاقة حرف ومعلومات مهمة أخرى.{templated_system_prompt} : موجه النظام من الواجهة الأمامية ، ملفوفة في علامة قالب مطالبة النظام المناسبة.{agent#Output} : يتم استبدال # بالرقم الذي تريده. كل عقدة تولد إخراج الوكيل. العقدة الأولى هي دائمًا {agent2Output} ، وكل زيادات عقدة لاحقة {agent1Output} 1.{category_colon_descriptions} : يسحب الفئات والأوصاف من ملف JSON Routing .{categoriesSeparatedByOr} : يسحب أسماء الفئات ، مفصولة بـ "أو".[TextChunk] : متغير خاص فريد للمعالج الموازي ، على الأرجح لم يتم استخدامه كثيرًا.ملاحظة: لفهم أعمق لكيفية عمل الذكريات ، يرجى الاطلاع على قسم ذكريات التفاهم
ستقوم هذه العقدة بسحب عدد الذكريات (أو أحدث الرسائل في حالة عدم وجود مناقشة) وإضافة محدد مخصص بينهما. لذا ، إذا كان لديك ملف ذاكرة يحتوي على 3 ذكريات ، واختر محدد " n --------- n" فيمكنك الحصول على ما يلي:
This is the first memory
---------
This is the second memory
---------
This is the third memory
يمكن أن يسمح الجمع بين هذه العقدة وملخص الدردشة لـ LLM ليس فقط لتلقي التفاصيل الملخص للمحادثة بأكملها ككل ، ولكن أيضًا قائمة بجميع الذكريات التي تم بناؤها الملخص ، والتي قد تحتوي هو - هي. يمكن أن يؤدي إرسال كل من هؤلاء معًا ، إلى جانب آخر 15-20 ، إلى إنشاء انطباع بذاكرة مستمرة ومستمرة للدردشة بأكملها إلى أحدث الرسائل. يمكن أن تساعد الرعاية الخاصة في صياغة مطالبات جيدة لتوليد الذكريات في ضمان التقاط التفاصيل التي تهتم بها ، بينما يتم تجاهل التفاصيل الأقل صلة.
هذه العقدة لن تولد ذكريات جديدة. هذا بحيث يمكن احترام أقفال سير العمل إذا كنت تستخدمها على إعداد متعدد الحواس. حاليًا أفضل طريقة لتوليد الذكريات هي العقدة الكاملة.


