QuillGPT
1.0.0

QuillGPT هو تطبيق لكتلة وحدة فك ترميز GPT استنادًا إلى البنية المأخوذة من ورقة Attention is All You Need التي أعدها Vaswani et. آل. تنفيذها في PyTorch. بالإضافة إلى ذلك، يحتوي هذا المستودع على نموذجين مدربين مسبقًا — Shakespearean GPT وHarpoon GPT — بالإضافة إلى أوزانهما المدربة. ولتسهيل التجريب والنشر، يتم توفير Streamlit Playground للاستكشاف التفاعلي لهذه النماذج وخدمة FastAPI الصغيرة التي يتم تنفيذها باستخدام حاوية Docker للنشر القابل للتطوير. ستجد أيضًا نصوص Python لتدريب نماذج GPT الجديدة وإجراء الاستدلال عليها، بالإضافة إلى دفاتر ملاحظات تعرض النماذج المدربة. لتسهيل تشفير النص وفك تشفيره، يتم تنفيذ أداة رمزية بسيطة. استكشف QuillGPT للاستفادة من هذه الأدوات وتحسين مشاريع معالجة اللغة الطبيعية لديك!
يوجد نموذجان وأوزان مدربة مسبقًا في هذا المستودع.
| ميزة | شكسبير جي بي تي | هاربون جي بي تي |
|---|---|---|
| حدود | 10.7 م | 226 م |
| الأوزان | الأوزان | الأوزان |
| تكوين النموذج | التكوين | التكوين |
| بيانات التدريب | نص من مسرحيات شكسبير (input.txt) | نص عشوائي من الكتب (corpus.txt) |
| نوع التضمين | تضمينات الأحرف | تضمينات الأحرف |
| دفتر التدريب | دفتر الملاحظات | دفتر الملاحظات |
| الأجهزة | نفيديا T4 | نفيديا A100 |
| فقدان التدريب والتحقق من الصحة | 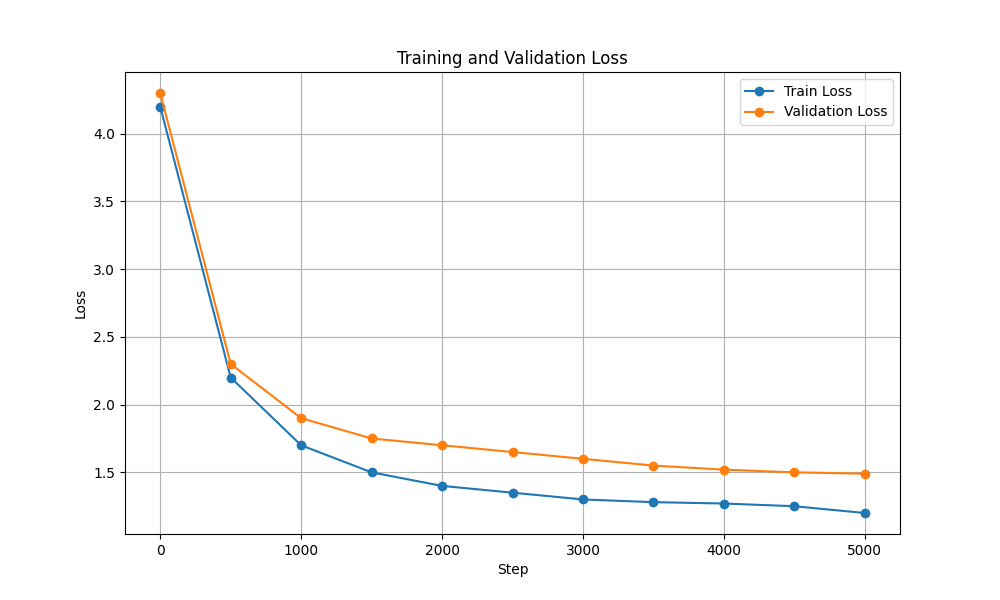 | 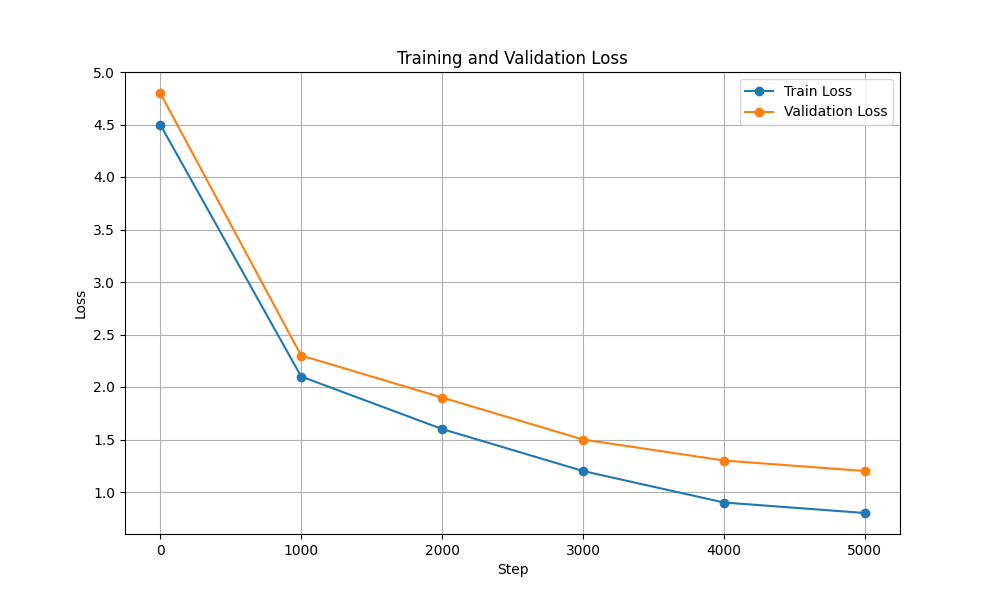 |
لتشغيل البرامج النصية للتدريب والاستدلال، اتبع الخطوات التالية:
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txtتأكد من تنزيل أوزان Harpoon GPT من هنا قبل المتابعة!
يتم استضافته على Streamlit Cloud Service. ويمكنك زيارته من خلال الرابط هنا.
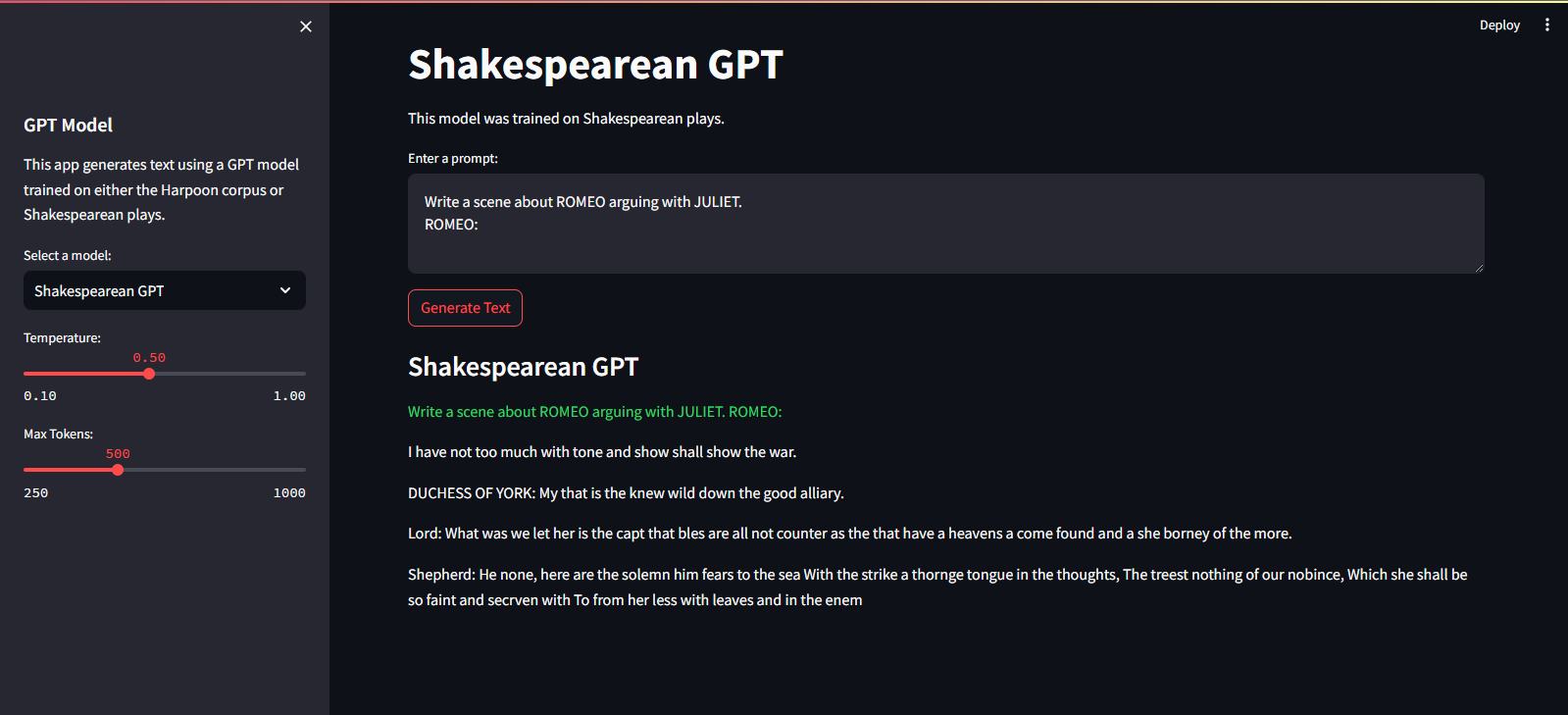
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devلتدريب نموذج GPT، اتبع الخطوات التالية:
تحضير البيانات. ضع بيانات النص بالكامل في ملف .txt واحد واحفظه.
اكتب تكوينات المحول واحفظ الملف.
على سبيل المثال: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
نموذج القطار باستخدام scripts/train_gpt.py
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (يمكنك تغيير config_path و data_path و output_dir وفقًا لمتطلباتك.)
output_dir المحدد في الأمر.بعد التدريب، يمكنك استخدام نموذج GPT المُدرب لإنشاء النص. فيما يلي مثال لاستخدام النموذج المدرّب للاستدلال:
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 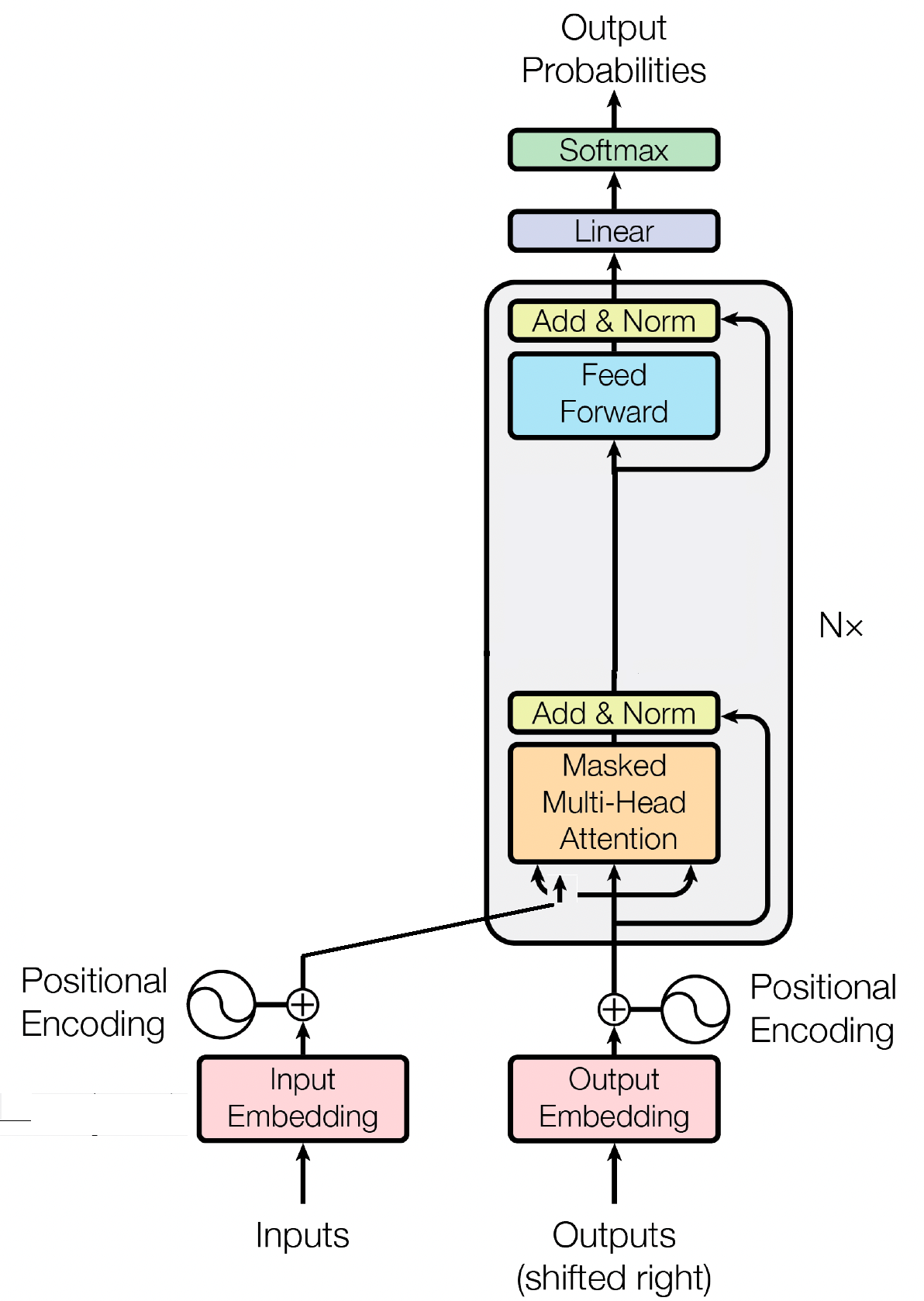
تعد كتلة وحدة فك التشفير مكونًا حاسمًا في نموذج GPT (المحول التوليدي المُدرب مسبقًا)، حيث يقوم GPT بالفعل بإنشاء النص. إنه يعزز آلية الاهتمام الذاتي لمعالجة تسلسل المدخلات وتوليد مخرجات متماسكة. تتكون كل كتلة وحدة فك ترميز من طبقات متعددة، بما في ذلك طبقات الاهتمام الذاتي، والشبكات العصبية ذات التغذية الأمامية، وتطبيع الطبقة. تسمح طبقات الاهتمام الذاتي للنموذج بتقييم أهمية الكلمات المختلفة في التسلسل، والتقاط السياق والتبعيات بغض النظر عن مواقعها. يتيح ذلك لنموذج GPT إنشاء نص ذي صلة بالسياق.
تلعب عمليات تضمين الإدخال دورًا حاسمًا في النماذج القائمة على المحولات مثل GPT عن طريق تحويل رموز الإدخال إلى تمثيلات رقمية ذات معنى. تعمل هذه التضمينات كمدخل أولي للنموذج، حيث تلتقط المعلومات الدلالية حول الكلمات الموجودة في التسلسل. تتضمن العملية تعيين كل رمز مميز في تسلسل الإدخال إلى مساحة متجهة عالية الأبعاد، حيث يتم وضع الرموز المميزة المتشابهة بالقرب من بعضها البعض. يتيح ذلك للنموذج فهم العلاقات بين الكلمات المختلفة والتعلم بشكل فعال من البيانات المدخلة. يتم بعد ذلك إدخال تضمينات الإدخال في الطبقات اللاحقة من النموذج لمزيد من المعالجة.
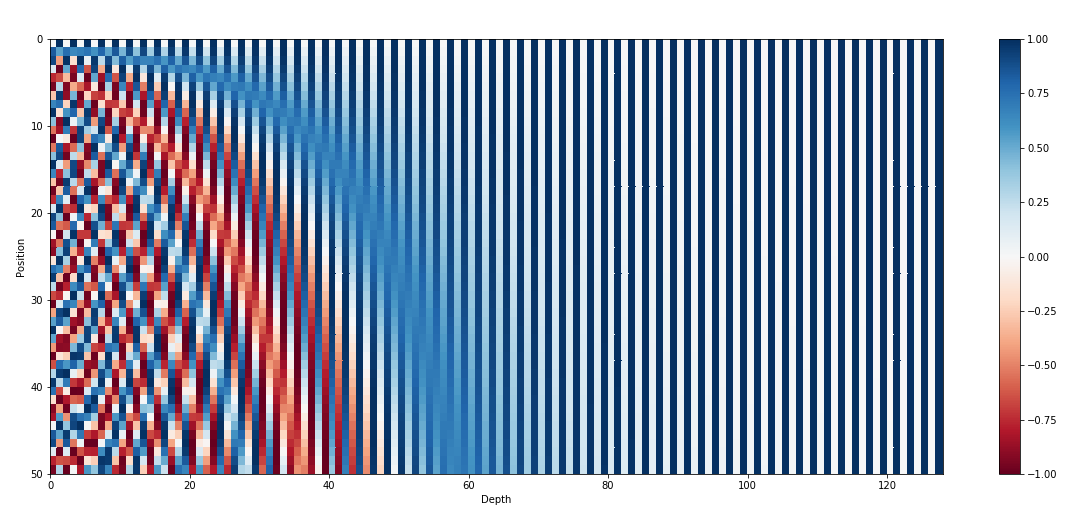
بالإضافة إلى تضمينات المدخلات، تعد التضمينات الموضعية مكونًا حيويًا آخر في معماريات المحولات مثل GPT. نظرًا لأن المحولات تفتقر إلى المعلومات المتأصلة حول ترتيب الرموز المميزة في التسلسل، يتم تقديم التضمينات الموضعية لتزويد النموذج بالمعلومات الموضعية. تقوم هذه التضمينات بتشفير موضع كل رمز مميز ضمن التسلسل، مما يسمح للنموذج بالتمييز بين الرموز المميزة بناءً على مواقعها. من خلال دمج التضمينات الموضعية، يمكن للمحولات مثل GPT التقاط الطبيعة التسلسلية للبيانات بشكل فعال وإنشاء مخرجات متماسكة تحافظ على الترتيب الصحيح للكلمات في النص الذي تم إنشاؤه.

الانتباه الذاتي، وهو آلية أساسية في النماذج القائمة على المحولات مثل GPT، يعمل عن طريق تعيين درجات الأهمية لكلمات مختلفة في التسلسل. تتضمن هذه العملية ثلاث خطوات رئيسية: حساب درجات الاهتمام، وتطبيق softmax للحصول على أوزان الانتباه، وأخيرًا دمج هذه الأوزان مع تضمينات المدخلات لإنشاء تمثيلات مستنيرة للسياق. في جوهره، يسمح الاهتمام الذاتي للنموذج بالتركيز بشكل أكبر على الكلمات ذات الصلة مع تقليل التركيز على الكلمات الأقل أهمية، مما يسهل التعلم الفعال للتبعيات السياقية ضمن بيانات الإدخال. تعتبر هذه الآلية محورية في التقاط التبعيات طويلة المدى والفروق الدقيقة في السياق، مما يتيح لنماذج المحولات إنشاء تسلسلات طويلة من النص.
معهد ماساتشوستس للتكنولوجيا © شيريرانج ماهاجان
لا تتردد في إرسال طلبات السحب أو إنشاء مشكلات أو نشر الكلمة!
ادعمني ببساطة عن طريق تمييز هذا المستودع بنجمة!


