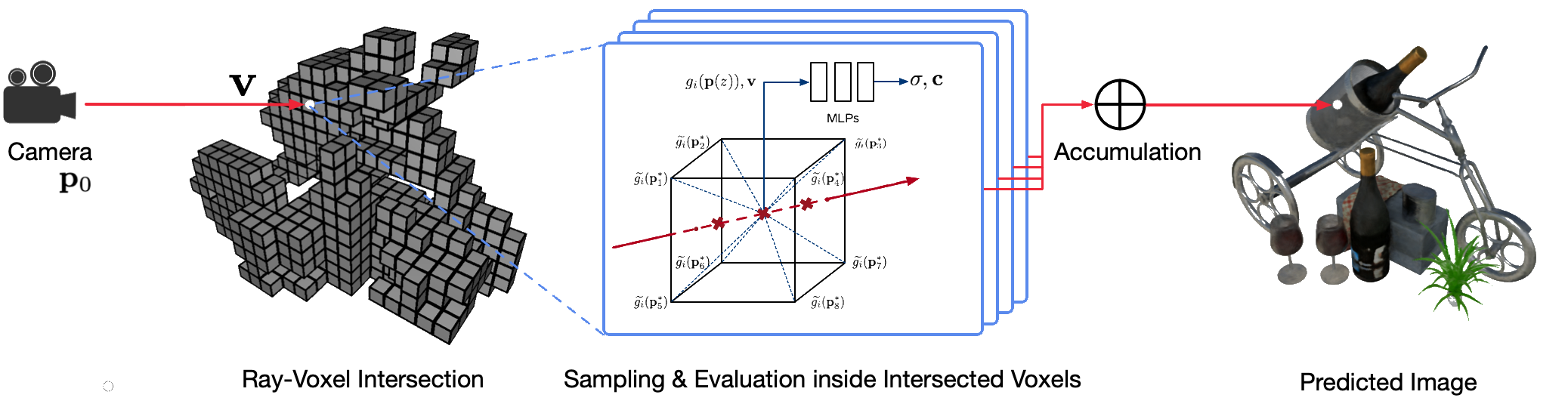
يمثل العرض الحر لوجهة النظر الواقعية لمشاهد من العالم الحقيقي باستخدام تقنيات رسومات الكمبيوتر الكلاسيكية مشكلة صعبة لأنه يتطلب الخطوة الصعبة المتمثلة في التقاط نماذج تفصيلية للمظهر والهندسة. يعد العرض العصبي مجالًا ناشئًا يستخدم شبكات عصبية عميقة للتعلم ضمنيًا تمثيلات المشهد التي تغلف كلاً من الهندسة والمظهر من الملاحظات ثنائية الأبعاد مع أو بدون هندسة خشنة. ومع ذلك، فإن الأساليب الحالية في هذا المجال غالبًا ما تظهر عروضًا ضبابية أو تعاني من عملية عرض بطيئة. نقترح حقول فوكسل العصبية المتفرقة (NSVF)، وهو تمثيل مشهد عصبي جديد لعرض وجهة نظر حرة سريعة وعالية الجودة.
هنا الريبو الرسمي للورقة:
نحن نقدم أيضًا تطبيقنا غير الرسمي لـ:
يتم تنفيذ هذا الكود في PyTorch باستخدام إطار عمل fairseq.
تم اختبار الكود على النظام التالي:
يتم دعم التعلم والعرض على وحدات معالجة الرسومات فقط.
للتثبيت، قم أولاً باستنساخ هذا الريبو وتثبيت جميع التبعيات:
pip install -r requirements.txtثم اركض
pip install --editable ./أو إذا كنت تريد تثبيت الكود محليًا، قم بتشغيل:
python setup.py build_ext --inplaceيمكنك تنزيل مجموعات البيانات الاصطناعية والحقيقية المعالجة مسبقًا والمستخدمة في ورقتنا. ويرجى أيضًا ذكر الأوراق الأصلية إذا كنت تستخدم أيًا منها في عملك.
| مجموعة البيانات | رابط التحميل | ملاحظات حول تقسيم مجموعة البيانات |
|---|---|---|
| الاصطناعية-NSVF | تنزيل (.zip) | 0_* (تدريب) 1_* (التحقق من الصحة) 2_* (اختبار) |
| الاصطناعية-NeRF | تنزيل (.zip) | 0_* (تدريب) 1_* (التحقق من الصحة) 2_* (اختبار) |
| BlendedMVS | تنزيل (.zip) | 0_* (تدريب) 1_* (اختبار) |
| الدبابات والمعابد | تنزيل (.zip) | 0_* (تدريب) 1_* (اختبار) |
لإعداد مجموعة بيانات جديدة لمشهد واحد للتدريب والاختبار، يرجى اتباع بنية البيانات:
< dataset_name >
| -- bbox.txt # bounding-box file
| -- intrinsics.txt # 4x4 camera intrinsics
| -- rgb
| -- 0.png # target image for each view
| -- 1.png
...
| -- pose
| -- 0.txt # camera pose for each view (4x4 matrices)
| -- 1.txt
...
[optional]
| -- test_traj.txt # camera pose for free-view rendering demonstration (4N x 4) حيث يحتوي ملف bbox.txt على سطر يصف المربع المحيط الأولي وحجم فوكسل:
x_min y_min z_min x_max y_max z_max initial_voxel_size لاحظ أن أسماء ملفات الصور المستهدفة وأسماء ملفات الكاميرا المقابلة ليس من الضروري أن تكون متماثلة تمامًا. ومع ذلك، يجب أن يتطابق ترتيب هذين النوعين من الملفات (المرتبة حسب السلسلة). يتم تقسيم مجموعات البيانات مع مؤشرات العرض. على سبيل المثال، " train (0..100) valid (100..200) test (200..400) " يعني أول 100 مشاهدة للتدريب، والمشاهدات من 100 إلى 199 للتحقق من الصحة، والمشاهدات من 200 إلى 399 للاختبار .
بالنظر إلى مجموعة بيانات مشهد واحد ( {DATASET} )، نستخدم الأمر التالي لتدريب نموذج NSVF لتجميع طرق عرض جديدة بدقة 800x800 بكسل، مع حجم دفعة يبلغ 4 صور لكل وحدة معالجة رسومات و 2048 شعاعًا لكل صورة. افتراضيًا، سيكتشف الكود تلقائيًا جميع وحدات معالجة الرسومات المتاحة.
في المثال التالي، نستخدم بنية محددة مسبقًا nsvf_base مع وسائط محددة:
--no-sampling-at-reader ، يقوم النموذج فقط باختبار وحدات البكسل في منطقة الصورة المسقطة ذات وحدات فوكسل متفرقة للتدريب.1/8 (0.125) من حجم فوكسل الذي يتم وصفه عادةً في ملف bbox.txt .--use-octree اختياريًا. سيتم بناء ثماني فوكسل متفرق لتسريع تقاطع راي فوكسل خاصة عندما يكون عدد فوكسل أكبر من 10000 .--pruning-every-steps على 2500 ، يقوم النموذج بإجراء التقليم الذاتي في كل 2500 خطوة.--half-voxel-size-at و --reduce-step-size-at على 5000,25000,75000 ، يتم تقليل حجم voxel وحجم الخطوة إلى النصف عند 5k و 25k و 75k على التوالي.لاحظ أنه على الرغم من استخدام إعدادات المعلمات أعلاه لمعظم التجارب في الورقة، فمن الممكن ضبط هذه المعلمات لتحقيق جودة أفضل. إلى جانب المعلمات المذكورة أعلاه، يمكن لمعلمات أخرى أيضًا استخدام الإعدادات الافتراضية.
بالإضافة إلى البنية nsvf_base ، يمكنك التحقق من البنيات الأخرى أو تعريف البنيات الخاصة بك في الملف fairnr/models/nsvf.py .
python -u train.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--train-views " 0..100 " --view-resolution " 800x800 "
--max-sentences 1 --view-per-batch 4 --pixel-per-view 2048
--no-preload
--sampling-on-mask 1.0 --no-sampling-at-reader
--valid-views " 100..200 " --valid-view-resolution " 400x400 "
--valid-view-per-batch 1
--transparent-background " 1.0,1.0,1.0 " --background-stop-gradient
--arch nsvf_base
--initial-boundingbox ${DATASET} /bbox.txt
--use-octree
--raymarching-stepsize-ratio 0.125
--discrete-regularization
--color-weight 128.0 --alpha-weight 1.0
--optimizer " adam " --adam-betas " (0.9, 0.999) "
--lr 0.001 --lr-scheduler " polynomial_decay " --total-num-update 150000
--criterion " srn_loss " --clip-norm 0.0
--num-workers 0
--seed 2
--save-interval-updates 500 --max-update 150000
--virtual-epoch-steps 5000 --save-interval 1
--half-voxel-size-at " 5000,25000,75000 "
--reduce-step-size-at " 5000,25000,75000 "
--pruning-every-steps 2500
--keep-interval-updates 5 --keep-last-epochs 5
--log-format simple --log-interval 1
--save-dir ${SAVE}
--tensorboard-logdir ${SAVE} /tensorboard
| tee -a $SAVE /train.log يتم حفظ نقاط التفتيش في {SAVE} . يمكنك تشغيل Tensorboard للتحقق من تقدم التدريب:
tensorboard --logdir= ${SAVE} /tensorboard --port=10000هناك المزيد من الأمثلة على النصوص التدريبية لإعادة إنتاج نتائج ورقتنا تحت الأمثلة.
بمجرد تدريب النموذج، يتم استخدام الأمر التالي لتقييم جودة العرض في طرق العرض الاختبارية المعطاة {MODEL_PATH} .
python validate.py ${DATASET}
--user-dir fairnr
--valid-views " 200..400 "
--valid-view-resolution " 800x800 "
--no-preload
--task single_object_rendering
--max-sentences 1
--valid-view-per-batch 1
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01,"tensorboard_logdir":"","eval_lpips":True} ' لاحظ أننا تجاوزنا raymarching_tolerance إلى 0.01 لتمكين الإنهاء المبكر لتسريع العرض.
يمكن تحقيق عرض وجهة نظر حرة بمجرد تدريب النموذج وتحديد مسار العرض. على سبيل المثال، الأمر التالي مخصص للعرض بمسار دائرة (السرعة الزاوية 3 درجات/إطار، 15 إطارًا لكل وحدة معالجة رسومات). يؤدي هذا إلى إخراج الصور المعروضة لكل عرض ودمج الصور في فيديو .mp4 بتنسيق ${SAVE}/output كما يلي:

افتراضيًا، يمكن للكود اكتشاف جميع وحدات معالجة الرسومات المتاحة.
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-beam 1 --render-angular-speed 3 --render-num-frames 15
--render-save-fps 24
--render-resolution " 800x800 "
--render-path-style " circle "
--render-path-args " {'radius': 3, 'h': 2, 'axis': 'z', 't0': -2, 'r':-1} "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " يدعم الكود الخاص بنا أيضًا العرض لأوضاع معينة للكاميرا. على سبيل المثال، الأمر التالي مخصص للعرض باستخدام أوضاع الكاميرا المحددة في الملفات من 200 إلى 399 ضمن المجلد ${DATASET}/pose :
python render.py ${DATASET}
--user-dir fairnr
--task single_object_rendering
--path ${MODEL_PATH}
--model-overrides ' {"chunk_size":512,"raymarching_tolerance":0.01} '
--render-save-fps 24
--render-resolution " 800x800 "
--render-camera-poses ${DATASET} /pose
--render-views " 200..400 "
--render-output ${SAVE} /output
--render-output-types " color " " depth " " voxel " " normal " --render-combine-output
--log-format " simple " يدعم الكود أيضًا العرض باستخدام أوضاع الكاميرا المحددة في ملف .txt . يرجى الرجوع إلى هذا المثال.
نحن ندعم أيضًا تشغيل المكعبات المتحركة لاستخراج الأسطح المتساوية كشبكات مثلثية من نموذج NSVF المُدرب وحفظها باسم {SAVE}/{NAME}.ply .
python extract.py
--user-dir fairnr
--path ${MODEL_PATH}
--output ${SAVE}
--name ${NAME}
--format ' mc_mesh '
--mc-threshold 0.5
--mc-num-samples-per-halfvoxel 5 من الممكن أيضًا تصدير وحدات البكسل المتفرقة التي تم تعلمها عن طريق الإعداد --format 'voxel_mesh' . يمكن فتح ملف الإخراج .ply باستخدام أي برنامج عرض ثلاثي الأبعاد مثل MeshLab.

NSVF مرخص من معهد ماساتشوستس للتكنولوجيا. ينطبق الترخيص على النماذج المدربة مسبقًا أيضًا.
يرجى ذكر كما
@article { liu2020neural ,
title = { Neural Sparse Voxel Fields } ,
author = { Liu, Lingjie and Gu, Jiatao and Lin, Kyaw Zaw and Chua, Tat-Seng and Theobalt, Christian } ,
journal = { NeurIPS } ,
year = { 2020 }
}

