أثناء استكشاف التشفير، عثرت على مقطع فيديو خاص بأكاديمية خان والذي زاد اهتمامي بالعيوب الموجودة في تشفير قيصر سيئ السمعة.
عندما تكتب خطابًا طويلًا أو بريدًا إلكترونيًا باللغة الإنجليزية، فإنك تترك بصمة خلفك دون قصد؛ إذا قمت بمسح رسالة كتبتها ضوئيًا وأحصيت تكرار كل حرف، فستجد نمطًا ثابتًا إلى حد ما. من المرجح أن يكون "e" هو الحرف الأكثر تكرارًا في الرسالة بأكملها. أخذت حكاية عشوائية من الإنترنت لاختبار ذلك وكانت النتيجة التي حصلت عليها هي ما كان متوقعًا منها. كان "e" بالفعل هو الحرف الأكثر شعبية. هذه الحقيقة تنطبق على أي رسالة طويلة بما فيه الكفاية.
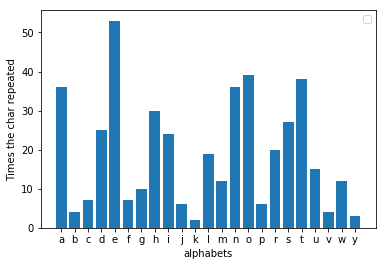
الخلل الذي اكتشفه الكندي هو أنه عندما تقوم بتحليل تكرار الرسالة المشفرة، فإن حرفًا مختلفًا يتكرر الآن أكثر من غيره. إذا قمت بفحص مدى إزاحة الحرف من الرقم ثلاثة، فيمكنك العثور على القيمة التي تم استبدال الرسالة بها. على سبيل المثال، إذا كان الحرف "h" هو الحرف الأكثر شيوعًا في الرسالة المشفرة، فمن المحتمل أن يكون التحول ثلاثة. الآن، من خلال عكس الإزاحة، يمكننا الحصول على الرسالة الأصلية بسهولة. في decoder.py عندما تقوم بإطعامه ملفًا مشفرًا، فإنه يفك تشفير الرسالة ويطبعها. لقد قمت بتشفير نفس الحكاية عن طريق تغيير الحروف الهجائية بثلاثة أحرف وتبين أن "h" هو بالفعل الحرف الأكثر شيوعًا هنا.
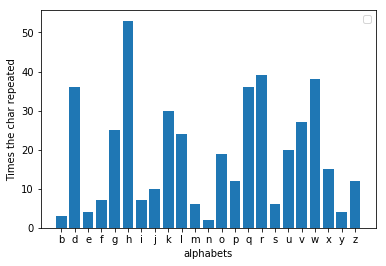
لإعادة إنتاج نتائج التشفير الخاص بي واستكشافها مع رسائل أخرى، بالإضافة إلى لغة بايثون، يجب أن يكون لديك matplotlib مثبتًا.
pip install matplotlibتذكر : وحدة فك التشفير تعمل على مبدأ اللغويات والإحصائيات، لذا فإن الرسالة أطول، والنتيجة أكثر دقة.
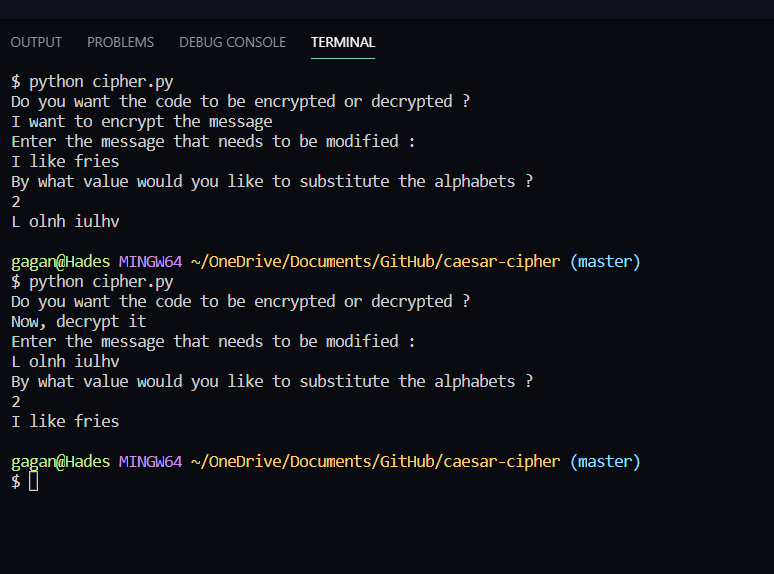
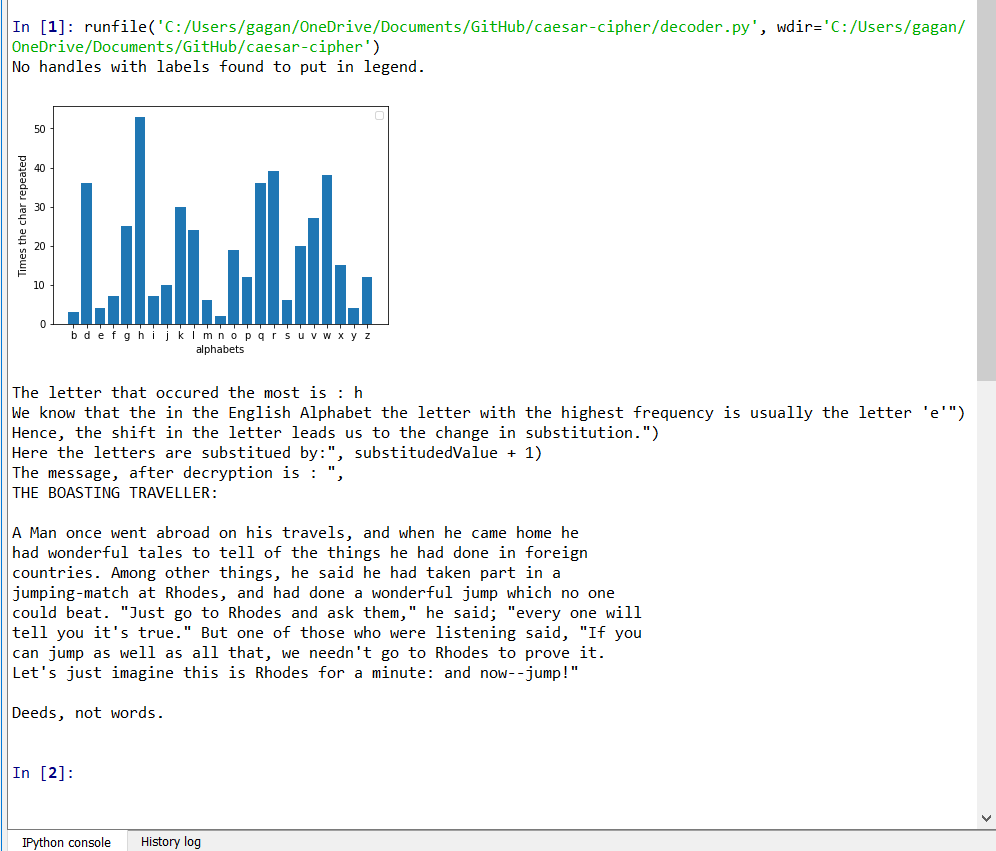
جاجان ديفاجيري © معهد ماساتشوستس للتكنولوجيا


