self instruct
1.0.0
يحتوي هذا المستودع على تعليمات برمجية وبيانات لمقالة Self-Instruct، وهي طريقة لمواءمة نماذج اللغة المدربة مسبقًا مع التعليمات.
إن Self-Instruct عبارة عن إطار عمل يساعد نماذج اللغة على تحسين قدرتها على اتباع تعليمات اللغة الطبيعية. ويقوم بذلك عن طريق استخدام أجيال النموذج الخاصة لإنشاء مجموعة كبيرة من البيانات التعليمية. باستخدام التوجيه الذاتي، من الممكن تحسين قدرات متابعة التعليمات لنماذج اللغة دون الاعتماد على التعليقات التوضيحية اليدوية الشاملة.
في السنوات الأخيرة، كان هناك اهتمام متزايد ببناء نماذج يمكنها اتباع تعليمات اللغة الطبيعية لأداء مجموعة واسعة من المهام. وقد أظهرت هذه النماذج، المعروفة باسم نماذج اللغة "المضبوطة للتعليمات"، القدرة على التعميم على المهام الجديدة. ومع ذلك، فإن أدائهم يعتمد بشكل كبير على جودة وكمية بيانات التعليمات المكتوبة بواسطة الإنسان والمستخدمة لتدريبهم، والتي يمكن أن تكون محدودة في التنوع والإبداع. للتغلب على هذه القيود، من المهم تطوير أساليب بديلة للإشراف على النماذج المضبوطة للتعليمات وتحسين قدراتها على متابعة التعليمات.
عملية التوجيه الذاتي عبارة عن خوارزمية تمهيدية متكررة تبدأ بمجموعة أولية من التعليمات المكتوبة يدويًا وتستخدمها لمطالبة نموذج اللغة بإنشاء تعليمات جديدة ومثيلات الإدخال والإخراج المقابلة. تتم بعد ذلك تصفية هذه الأجيال لإزالة الأجيال ذات الجودة المنخفضة أو المشابهة، وتتم إضافة البيانات الناتجة مرة أخرى إلى مجمع المهام. يمكن تكرار هذه العملية عدة مرات، مما يؤدي إلى مجموعة كبيرة من البيانات التعليمية التي يمكن استخدامها لضبط نموذج اللغة لمتابعة التعليمات بشكل أكثر فعالية.
فيما يلي نظرة عامة على التوجيه الذاتي:
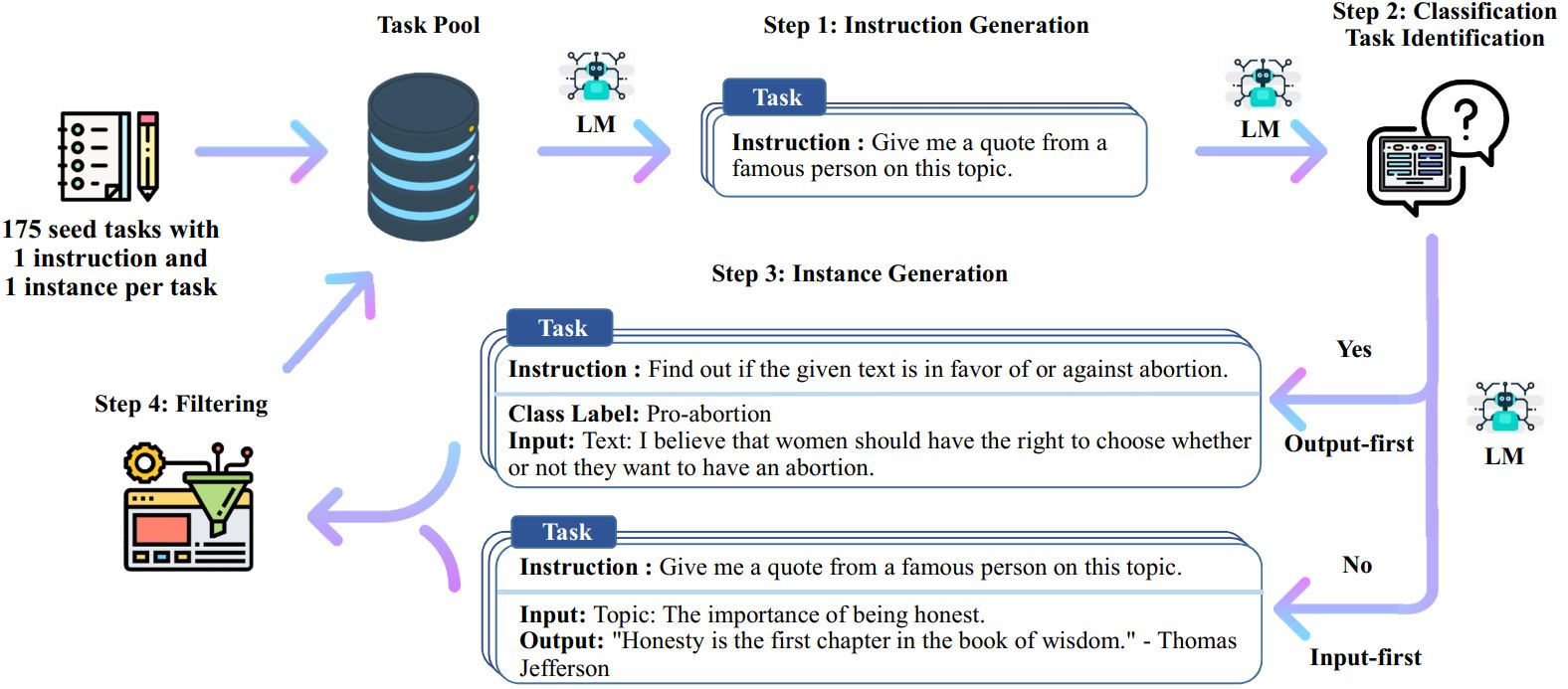
* ولا يزال هذا العمل قيد التنفيذ. قد نقوم بتحديث الكود والبيانات مع تقدمنا. يرجى توخي الحذر بشأن التحكم في الإصدار.
قمنا بإصدار مجموعة بيانات تحتوي على 52 ألف تعليمات، مقترنة بمدخلات ومخرجات المثيلات التي يبلغ عددها 82 ألفًا. يمكن استخدام بيانات التعليمات هذه لإجراء ضبط التعليمات لنماذج اللغة وجعل نموذج اللغة يتبع التعليمات بشكل أفضل. يمكن الوصول إلى البيانات التي تم إنشاؤها بواسطة النموذج بالكامل في data/gpt3-generations/batch_221203/all_instances_82K.jsonl . يتم وضع هذه البيانات (+ 175 مهمة أولية) التي تمت إعادة تنسيقها بتنسيق GPT3-finetuning النظيف (موجه + إكمال) في data/finetuning/self_instruct_221203 . يمكنك استخدام البرنامج النصي في ./scripts/finetune_gpt3.sh لضبط GPT3 على هذه البيانات.
ملحوظة : يتم إنشاء هذه البيانات بواسطة نموذج اللغة (GPT3) وتحتوي حتماً على بعض الأخطاء أو التحيزات. قمنا بتحليل جودة البيانات على 200 تعليمات عشوائية في بحثنا، ووجدنا أن 46% من نقاط البيانات قد تكون بها مشكلات. نحن نشجع المستخدمين على استخدام هذه البيانات بحذر ونقترح طرقًا جديدة لتصفية العيوب أو تحسينها.
قمنا أيضًا بإصدار مجموعة جديدة من 252 مهمة كتبها الخبراء وتعليماتها مدفوعة بالتطبيقات الموجهة للمستخدم (بدلاً من مهام البرمجة اللغوية العصبية المدروسة جيدًا). يتم استخدام هذه البيانات في قسم التقييم البشري في ورقة التوجيه الذاتي. يرجى الرجوع إلى الملف التمهيدي للتقييم البشري لمزيد من التفاصيل.
لإنشاء بيانات التوجيه الذاتي باستخدام المهام الأولية الخاصة بك أو النماذج الأخرى، فإننا نفتح مصدر البرامج النصية الخاصة بنا لخط الأنابيب بأكمله هنا. يتم اختبار الكود الحالي الخاص بنا فقط على نموذج GPT3 الذي يمكن الوصول إليه عبر OpenAI API.
فيما يلي البرامج النصية لإنشاء البيانات:
# 1. أنشئ تعليمات من المهام الأولية./scripts/generate_instructions.sh# 2. حدد ما إذا كانت التعليمات تمثل مهمة تصنيف أم لا./scripts/is_clf_or_not.sh# 3. أنشئ مثيلات لكل تعليمات./scripts/generate_instances. sh# 4. التصفية والمعالجة وإعادة التنسيق./scripts/prepare_for_finetuning.sh
إذا كنت تستخدم إطار العمل أو البيانات الخاصة بالتعليم الذاتي، فلا تتردد في الاستشهاد بنا.
@misc{selfinstruct, title={Self-Instruct: محاذاة نموذج اللغة مع التعليمات المولدة ذاتيًا}، المؤلف={Wang, Yizhong and Kordi, Yeganeh and Mishra, Swaroop and Liu, Alisa and Smith, Noah A. and Khashabi, Daniel and حاجشيرزي، حنانه}، مجلة={arXiv preprint arXiv:2212.10560}، العام={2022}} 

