bertsearch
1.0.0
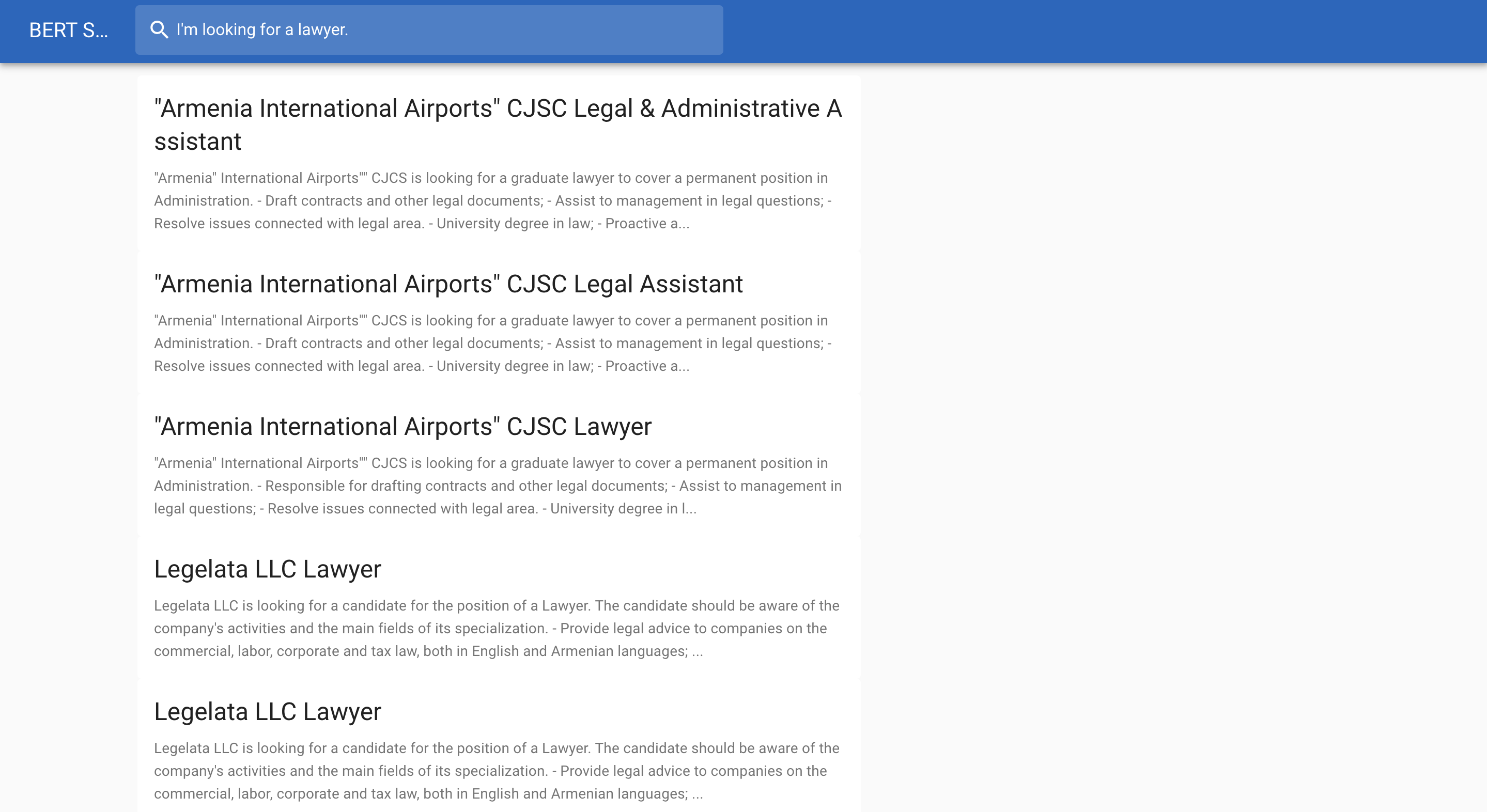
فيما يلي مثال للبحث عن وظيفة:
| قاعدة بيرت، غير مغطاة | 12 طبقة، 768 مخفي، 12 رأس، 110M معلمات |
| بيرت-كبير، غير مغلف | 24 طبقة، 1024 مخفية، 16 رأس، 340 مليون معلمة |
| قاعدة بيرت، معلبة | 12 طبقة، 768 مخفي، 12 رأس، 110 متر معلمات |
| بيرت-كبير، مغلف | 24 طبقة، 1024 مخفية، 16 رأس، 340 مليون معلمة |
| قاعدة BERT، حافظة متعددة اللغات (جديدة) | 104 لغة، 12 طبقة، 768 مخفيًا، 12 رأسًا، 110 مليون معلمة |
| قاعدة BERT، علبة متعددة اللغات (قديمة) | 102 لغة، 12 طبقة، 768 مخفيًا، 12 رأسًا، 110 مليون معلمة |
| قاعدة بيرت، صينية | الصينية المبسطة والتقليدية، 12 طبقة، 768 مخفيًا، 12 رأسًا، 110 مليون معلمة |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zipتحتاج إلى تعيين نموذج BERT مُدرب مسبقًا واسم فهرس Elasticsearch كمتغيرات بيئة:
$ export PATH_MODEL=./cased_L-12_H-768_A-12
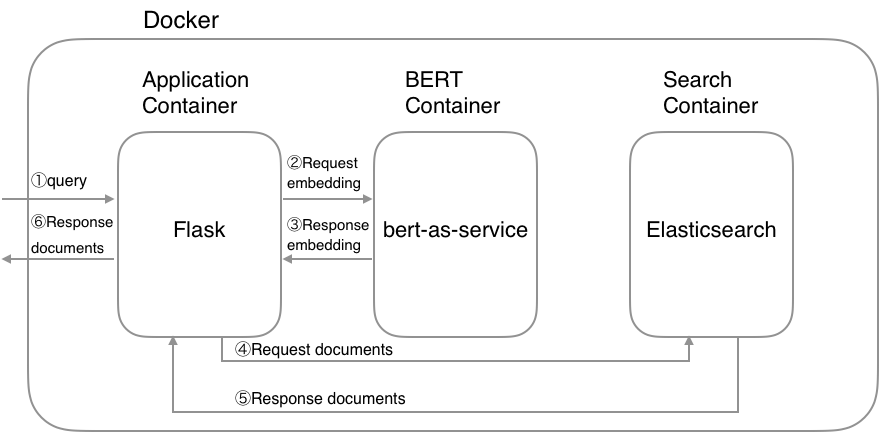
$ export INDEX_NAME=jobsearch$ docker-compose up تنبيه : إذا أمكن، قم بتعيين ذاكرة عالية (أكثر من 8GB ) لتكوين ذاكرة Docker لأن حاوية BERT تحتاج إلى ذاكرة عالية.
يمكنك استخدام واجهة برمجة تطبيقات إنشاء الفهرس لإضافة فهرس جديد إلى مجموعة Elasticsearch. عند إنشاء فهرس، يمكنك تحديد ما يلي:
على سبيل المثال، إذا كنت تريد إنشاء فهرس jobsearch باستخدام حقول title text و text_vector ، فيمكنك إنشاء الفهرس عن طريق الأمر التالي:
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
} تنبيه : يجب أن تتطابق قيمة dims الخاصة بـ text_vector مع قيم dims لنموذج BERT المُدرب مسبقًا.
بمجرد إنشاء فهرس، تصبح جاهزًا لفهرسة بعض المستندات. النقطة هنا هي تحويل المستند الخاص بك إلى متجه باستخدام BERT. يتم تخزين المتجه الناتج في حقل text_vector . دعنا نحول بياناتك إلى مستند JSON:
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "بعد الانتهاء من البرنامج النصي، يمكنك الحصول على مستند JSON كما يلي:
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...بعد تحويل بياناتك إلى ملف JSON، يمكنك إضافة مستند JSON إلى الفهرس المحدد وجعله قابلاً للبحث.
$ python example/index_documents.pyانتقل إلى http://127.0.0.1:5000.


