تم إنشاء هذا الكود بناءً على نموذج التعلم العميق الموجود مسبقًا من Image to BEV، استنادًا إلى الورقة البحثية Translating Images Into Maps. تمت كتابة هذا الرمز باستخدام بيثون 3.7. وتم تدريبه على مجموعة بيانات nuScenes. يرجى الرجوع إلى الملف التمهيدي الخاص بالمستودع لمعرفة التبعيات ومجموعات البيانات التي سيتم تثبيتها.
الخطوة الأولى هي إنشاء مجلد باسم "translating-images-to-maps-main" وتنزيل كافة الملفات فيه. وبعد ذلك، ونظرًا لحجم الملف الكبير، يمكن تنزيل أحدث نقاط التحقق الخاصة بتدريبنا ومجموعة بيانات nuScenes المصغرة المستخدمة للتحقق من الصحة من Google Drive. يجب إضافة هذه المجلدات مباشرة إلى الدليل "translating-images-to-maps-main".
فيما يلي قائمة المكتبات المطلوبة لهذا الريبو:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
لاستخدام وظائف هذا المستودع، قد يلزم تغيير وسيطات سطر الأوامر التالية:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
أما بالنسبة لتدريب النموذج، فيمكن تعديل وسيطات سطر الأوامر هذه:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
يمكن العثور على مجموعات البيانات NuScenes Mini وFull في المواقع التالية:
نيوسين ميني:
NuScenes كامل الولايات المتحدة:
نظرًا لأن مجموعات البيانات المصغرة والكاملة من NuScene لا تحتوي على نفس تنسيق إدخال الصور (lmdb أو png)، يجب تطبيق بعض التعديلات على الكود لاستخدام أحدهما أو الآخر:
mini إلى خطأ لاستخدام مجموعة البيانات المصغرة بالإضافة إلى مسارات الوسائط والانقسامات في ملفات train.py و validation.py و inference.py . data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')يمكن العثور على نقاط التفتيش المدربة مسبقًا هنا:
يجب الاحتفاظ بنقاط التحقق داخل /pretrained_models/27_04_23_11_08 من الدليل الجذر لهذا المستودع. إذا كنت تريد تحميلها من دليل آخر، يرجى تغيير الوسائط التالية:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"للتدريب على scitas، تحتاج إلى تشغيل البرنامج النصي التالي من الدليل الجذر:
sbatch job.script.sh
للتدريب محليًا على وحدة المعالجة المركزية:
python3 train.py
تأكد من تكييف البرنامج النصي مع وسيطات سطر الأوامر الخاصة بك.
للتحقق من صحة أداء النموذج على scitas:
sbatch job.validate.sh
للتدريب محليًا على وحدة المعالجة المركزية:
python3 validate.py
تأكد من تكييف البرنامج النصي مع وسيطات سطر الأوامر الخاصة بك.
للاستدلال على مقطع فيديو على scitas:
sbatch job.evaluate.sh
للتدريب محليًا على وحدة المعالجة المركزية:
python3 inference.py
تأكد من تكييف البرنامج النصي مع وسيطات سطر الأوامر، خاصة:
--batch-size // 1 for the test videos
--video-name
--video-root
تم إنشاء هذا المشروع في سياق دورة التعلم العميق للمركبات ذاتية القيادة CIVIL-459، التي يدرسها البروفيسور ألكسندر ألاهي في EPFL. لقد أشرف علينا طالب الدكتوراه يوجيانغ ليو. الهدف الرئيسي لمشروع الدورة هو تطوير نموذج التعلم العميق الذي يمكن استخدامه على متن نظام الطيار الآلي تسلا. أما بالنسبة لمجموعتنا، فقد كنا نبحث في التحول من صور الكاميرا الأحادية إلى منظر عين الطير. ويمكن القيام بذلك عن طريق استخدام التجزئة الدلالية لتصنيف عناصر مثل السيارات والرصيف والمشاة والأفق.
خلال بحثنا حول الصور الأحادية لنماذج التعلم العميق BEV، لاحظنا فقدان المعلومات المتعلقة بالمشاة أثناء التجزئة، مما أدى إلى سوء التصنيف. كما هو موضح في الصورة أدناه، عند تقييم النموذج الذي اخترناه، يصل إلى متوسط 25.7% IoU (التقاطع عبر الاتحاد) عبر 14 فئة من الكائنات في مجموعة بيانات nuScenes. تعد دقة التنبؤ بالنسبة للسيارات القابلة للقيادة جيدة (74.5%)، وضعيفة جدًا بالنسبة للدراجات والحواجز والمقطورات. ومع ذلك، فإن دقة التنبؤ بالنسبة للمشاة (9.5%) منخفضة للغاية. يمكن أن تؤدي مثل هذه الدقة المنخفضة إلى وقوع حوادث إذا قام شخص ما بعبور الطريق دون أن يكون على المعبر.

يمكن العثور على مزيد من المعلومات حول أبحاثنا على Drive.
نظرًا لأن ضعف الكشف عن المشاة يبدو أنه المشكلة الأكثر إلحاحًا في النموذج المدرب الحالي، فقد كنا نهدف إلى تحسين الدقة من خلال النظر في وظائف الخسارة الأكثر ملاءمة، وتدريب النموذج الجديد على مجموعة بيانات nuScenes.
تم تدريب النموذج الذي بنينا عليه باستخدام
قضية أخرى مع
ال
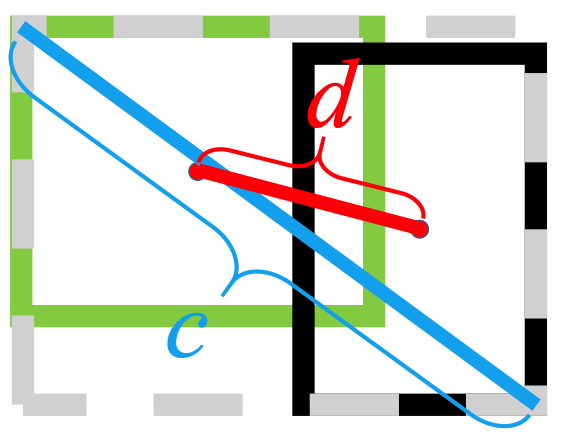
يستخدم معيار L2 لتقليل المسافة بين المربعات المتوقعة والمستهدفة، ويتقارب بشكل أسرع بكثير من

تمتد أفقيا

تمتد عموديا
علاوة على ذلك، فإن خسارة DIoU تقدم مصطلح تنظيم يشجع التقارب السلس.
كما هو واضح في الصورة التالية
بعد مرحلة البحث، قمنا بتنفيذ bbox_overlaps_diou في الملف /src/utils.py ، وذلك باستخدام
ثم يتم استخدام هذه الوظيفة لحساب المقاييس المتعددة compute_multiscale_iou لنفس الملف. لكل فئة، iou ) يتم حسابها على حجم الدفعة. مخرجات الوظيفة عبارة عن قاموس iou_dict يحتوي على المقاييس المتعددة
ثم استخدمنا هذه القيم في train.py ، حيث val-interval . تم استخدام هذه القيم أيضًا في validation.py حيث تم استخدامها لعرض الخسائر و
لقد قمنا بتدريب النموذج على مجموعة بيانات NuScenes بدءًا من checkpoint-008.pth.gz ، مرة واحدة باستخدام
مساهمة أخرى هي التنسيق الجديد للتصور لتمييز الفئات بشكل أفضل مع جميع التسميات المقابلة وقيم IoU. تم تنفيذ ذلك في ملف visualization.py .
وأخيرًا، عملنا على تنفيذ وضع من شأنه أن يأخذ مقاطع فيديو .mp4 كمدخلات ويقوم بتحليلها إلى إطارات صور فردية. سيتم بعد ذلك تقييمها بواسطة النموذج ويمكننا تصور نتيجة التجزئة في ملف inference.py .
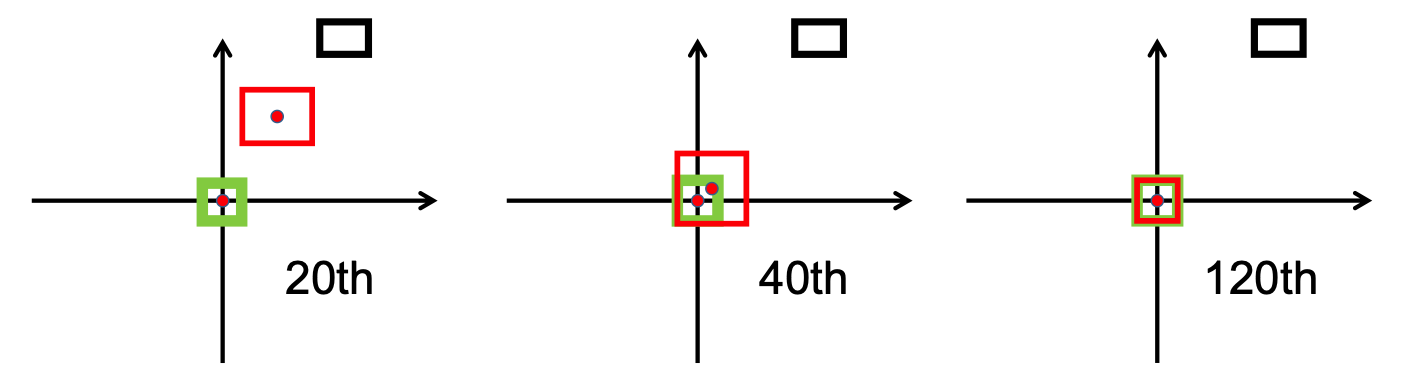
للحصول على فكرة أولية عن استراتيجية التدريب لهذا النموذج، قررنا أولاً تدريبه على مجموعات البيانات المصغرة NuScenes. بدءًا من checkpoint-008.pth.gz ، تمكنا من تدريب نموذجين مختلفين في مقياس IoU المستخدم (IoU لأحدهما وDIoU للآخر). يتم عرض النتائج التي تم الحصول عليها على دفعة NuScenes الصغيرة بعد 10 فترات من التدريب في الجدول أدناه.

وبعد الاطلاع على هذه النتائج لاحظنا أن فئة المشاة التي بنينا عليها فرضيتنا لم تقدم نتائج قاطعة على الإطلاق. ولذلك خلصنا إلى أن مجموعة البيانات المصغرة لم تكن كافية لاحتياجاتنا وقررنا نقل تدريبنا إلى مجموعة البيانات الكاملة على Scitas.
بعد تدريب نماذجنا الجديدة (باستخدام DIoU أو IoU) من checkpoint-008.pth.gz لمدة 8 فترات جديدة، لاحظنا نتائج واعدة. وبهدف مقارنة أداء هذه النماذج المدربة حديثًا، قمنا بخطوة التحقق من صحة مجموعة البيانات المصغرة. ويرد أدناه تصور لنتيجة صورة مجموعة البيانات هذه.
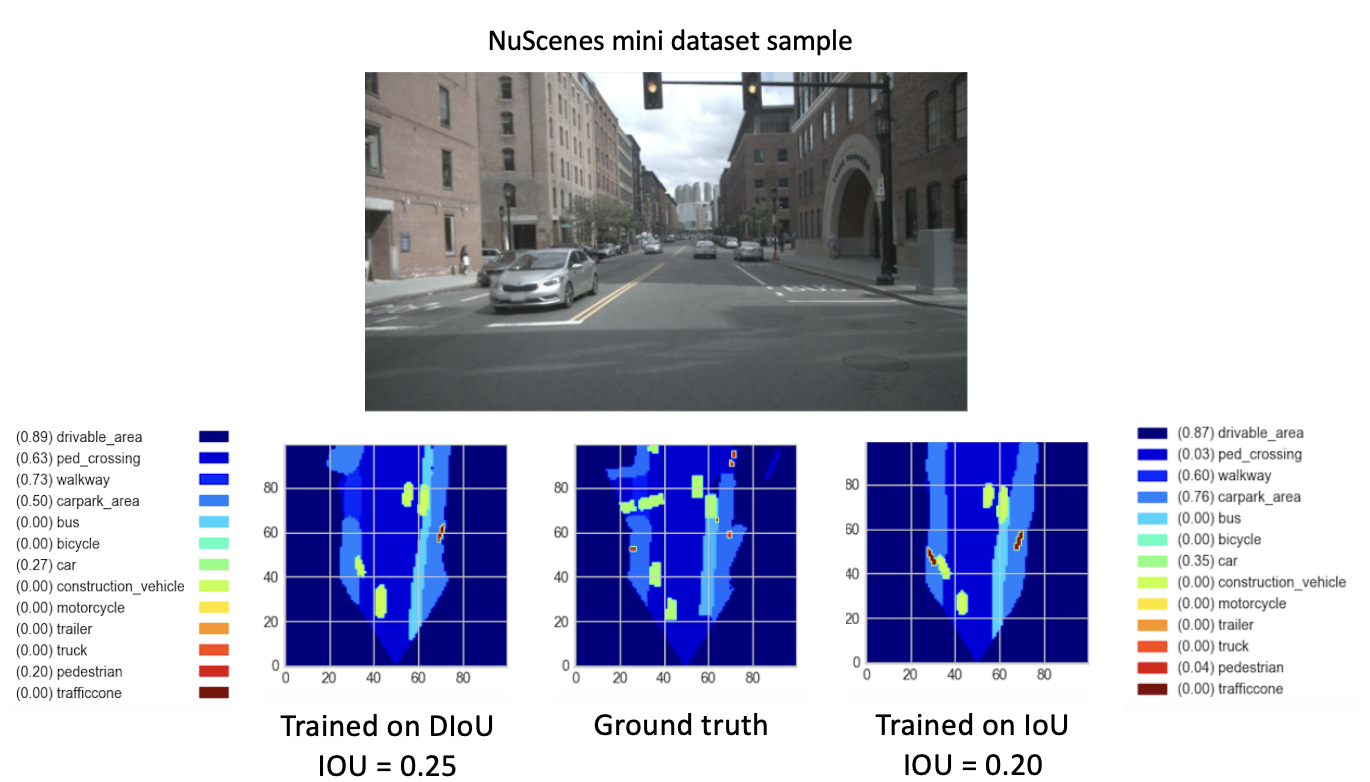
هنا،

تظهر هذه النتائج أخيرا أداء أفضل لل
والآن بعد أن أصبح لدينا نموذج مُدرب، يمكننا استخدامه للتنبؤ بـ BEV باستخدام أي صور أو مقاطع فيديو مُدخلة. بينما كان طموحنا هو تنفيذ طريقتنا في العرض التوضيحي النهائي للدورة، إلا أن خرائط الرؤية الشاملة المستنتجة لم تكن للأسف ذات أداء كافٍ. يوضح الشكل أدناه نتيجة الاستدلال على أحد مقاطع الفيديو الاختبارية المتوفرة (انظر مقاطع الفيديو الاختبارية).

نعتقد أن هذا النقص في أداء الاستدلال يرجع إلى المعلمات التالية:
على الرغم من مرور من
أحد الخيارات هو التنفيذ
ال
علاوة على ذلك، وفقًا للبحث الذي أجرته هذه الورقة [2]، فإن خطأ الانحدار لـ CIoU يتحلل بشكل أسرع من الباقي، وسوف يتقارب إلى
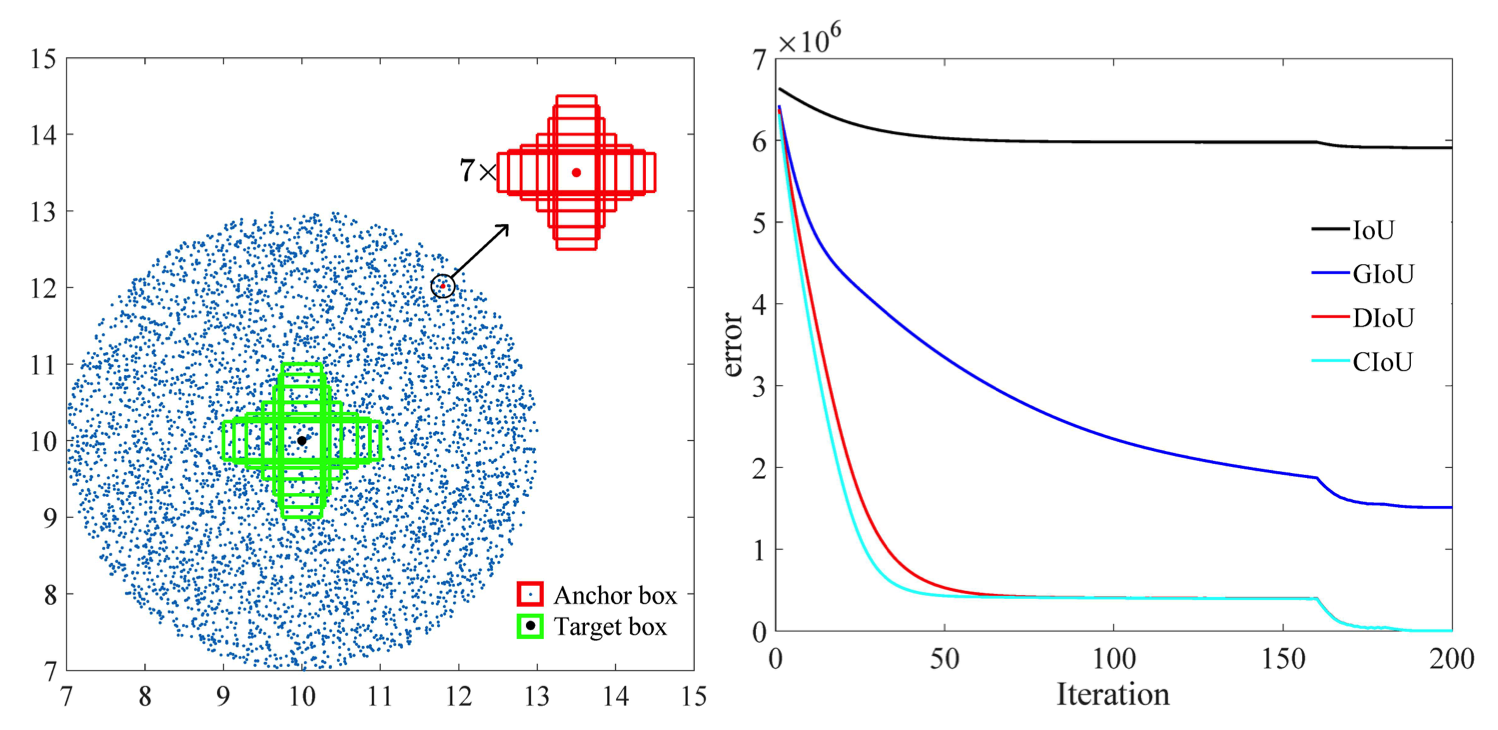
هناك خيار آخر يتمثل في التدريب على مجموعات البيانات الغنية بالبيئات المزدحمة للحصول على تمثيل أفضل للمشاة والدراجات.
أخيرًا، للتحقق من صحة فرضيتنا حقًا، يمكن إجراء عملية التحقق من الصحة على مجموعة بيانات NuScenes الكاملة ويمكن مقارنة وحدات IoU للمشاة في النموذجين.
[1] تشاوهوي تشنغ، بينج وانج، وي ليو، جينز لي، رونجوانج يي، دونجوي رن (2020). فقدان مسافة IoU: تعلم أسرع وأفضل لانحدار الصندوق المحيطي https://arxiv.org/pdf/1911.08287.pdf
[2] تشاوهوي تشنغ، بينج وانج، دونجوي رن، وي ليو، رونجوانج يي، تشينغهوا هو، وانجمينج زو (2021). تعزيز العوامل الهندسية في التعلم النموذجي والاستدلال لاكتشاف الكائنات وتجزئة المثيلات https://arxiv.org/pdf/2005.03572.pdf


