tiny cuda nn
Version 1.6
هذا إطار صغير قائم بذاته للتدريب والاستعلام عن الشبكات العصبية. وعلى وجه الخصوص، فهو يحتوي على إدراك سريع متعدد الطبقات "مندمج بالكامل" (ورقة تقنية)، وترميز تجزئة متعدد الحلول (ورقة تقنية)، بالإضافة إلى دعم العديد من ترميزات الإدخال الأخرى، والخسائر، والمحسنات.
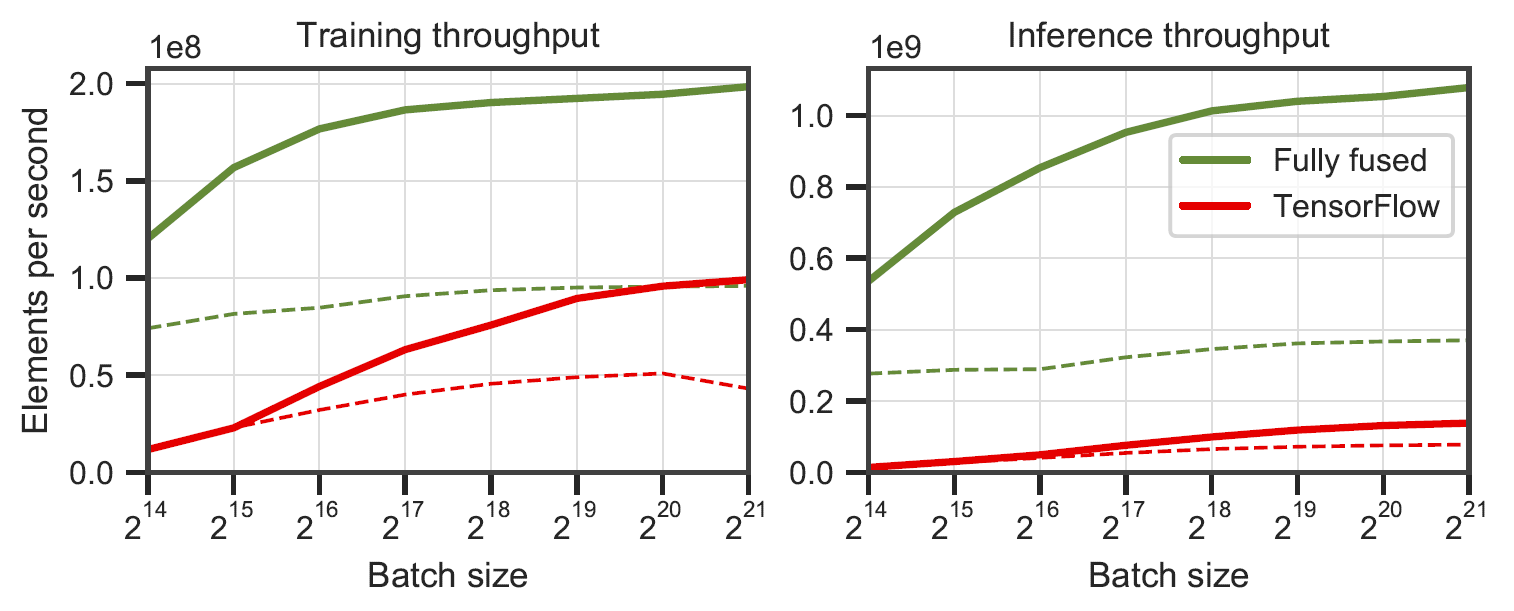 الشبكات المدمجة بالكامل مقابل TensorFlow v2.5.0 w/ XLA. تم قياسها على 64 (خط متصل) و128 (خط متقطع) من الخلايا العصبية واسعة النطاق متعددة الطبقات على RTX 3090. تم إنشاؤها بواسطة
الشبكات المدمجة بالكامل مقابل TensorFlow v2.5.0 w/ XLA. تم قياسها على 64 (خط متصل) و128 (خط متقطع) من الخلايا العصبية واسعة النطاق متعددة الطبقات على RTX 3090. تم إنشاؤها بواسطة benchmarks/bench_ours.cu و benchmarks/bench_tensorflow.py باستخدام data/config_oneblob.json .
تحتوي الشبكات العصبية الصغيرة CUDA على واجهة برمجة تطبيقات C++/CUDA بسيطة:
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);نحن نقدم نموذج تطبيق حيث يتم تعلم دالة الصورة (x,y) -> (R,G,B) . يمكن تشغيله عن طريق
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.jsonإنتاج صورة في كل خطوتين من خطوات التدريب. يجب أن تستغرق كل 1000 خطوة ما يزيد قليلاً عن ثانية واحدة مع التكوين الافتراضي على RTX 4090.
| 10 خطوات | 100 خطوة | 1000 خطوة | الصورة المرجعية |
|---|---|---|---|
 |  |  |  |
n_neurons أو تستخدم CutlassMLP (توافق أفضل ولكن أبطأ) بدلاً من ذلك.إذا كنت تستخدم Linux، قم بتثبيت الحزم التالية
sudo apt-get install build-essential git نوصي أيضًا بتثبيت CUDA في /usr/local/ وإضافة تثبيت CUDA إلى المسار الخاص بك. على سبيل المثال، إذا كان لديك CUDA 11.4، أضف ما يلي إلى ~/.bashrc الخاص بك
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " ابدأ باستنساخ هذا المستودع وجميع وحداته الفرعية باستخدام الأمر التالي:
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nnثم استخدم CMake لبناء المشروع: (في نظام التشغيل Windows، يجب أن يكون هذا في موجه أوامر المطور)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j إذا فشلت عملية الترجمة لسبب غير مفهوم أو استغرقت وقتًا أطول من ساعة، فقد تكون الذاكرة على وشك النفاد. حاول تشغيل الأمر أعلاه بدون -j في هذه الحالة.
يأتي tiny-cuda-nn مزودًا بامتداد PyTorch الذي يسمح باستخدام MLPs السريع وترميزات الإدخال من داخل سياق Python. يمكن أن تكون هذه الارتباطات أسرع بكثير من تطبيقات بايثون الكاملة؛ على وجه الخصوص لترميز التجزئة متعدد الدقة.
ومع ذلك، يمكن أن تكون النفقات العامة لـ Python/PyTorch واسعة النطاق إذا كان حجم الدفعة صغيرًا. على سبيل المثال، مع حجم دفعة يبلغ 64 كيلو بايت، يكون مثال
mlp_learning_an_imageالمجمّع أبطأ بمقدار 2x تقريبًا من خلال PyTorch مقارنة بـ CUDA الأصلي. مع حجم دفعة يبلغ 256 كيلو بايت وأعلى (افتراضي)، يكون الأداء أقرب بكثير.
ابدأ بإعداد بيئة Python 3.X باستخدام إصدار حديث من PyTorch يدعم CUDA. ثم استدعى
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torchوبدلاً من ذلك، إذا كنت ترغب في التثبيت من نسخة محلية لـ tiny-cuda-nn ، فاستدعِ
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py installعند النجاح، يمكنك استخدام نماذج tiny-cuda-nn كما في المثال التالي:
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) راجع samples/mlp_learning_an_image_pytorch.py للحصول على مثال.
وفيما يلي ملخص لمكونات هذا الإطار. تسرد وثائق JSON خيارات التكوين.
| الشبكات | ||
|---|---|---|
| MLP منصهر بالكامل | src/fully_fused_mlp.cu | تنفيذ سريع للغاية للإدراك الحسي الصغير متعدد الطبقات (MLPs). |
| سيف متقاطع MLP | src/cutlass_mlp.cu | MLP استنادًا إلى إجراءات GEMM الخاصة بـ CUTLASS. أبطأ من المدمج بالكامل، ولكنه يتعامل مع شبكات أكبر ولا يزال سريعًا إلى حد معقول. |
| ترميزات الإدخال | ||
|---|---|---|
| مركب | include/tiny-cuda-nn/encodings/composite.h | يسمح بتأليف ترميزات متعددة. يمكن استخدامه، على سبيل المثال، لتجميع ترميز التخزين المؤقت للإشعاع العصبي [Müller et al. 2021]. |
| تكرار | include/tiny-cuda-nn/encodings/frequency.h | NeRF [ميلدنهال وآخرون. 2020] يتم تطبيق التشفير الموضعي بالتساوي على جميع الأبعاد. |
| شبكة | include/tiny-cuda-nn/encodings/grid.h | التشفير على أساس شبكات متعددة الدقة قابلة للتدريب. يُستخدم في بدايات الرسومات العصبية الفورية [Müller et al. 2022]. يمكن دعم الشبكات بجداول التجزئة أو التخزين الكثيف أو التخزين المبلط. |
| هوية | include/tiny-cuda-nn/encodings/identity.h | يترك القيم دون تغيير. |
| ونبلوب | include/tiny-cuda-nn/encodings/oneblob.h | من أخذ عينات الأهمية العصبية [مولر وآخرون. 2019] ومتغيرات التحكم العصبي [مولر وآخرون. 2020]. |
| التوافقيات الكروية | include/tiny-cuda-nn/encodings/spherical_harmonics.h | تشفير مساحة التردد أكثر ملاءمة لمتجهات الاتجاه من تلك المتعلقة بالمكونات. |
| TriangleWave | include/tiny-cuda-nn/encodings/triangle_wave.h | بديل منخفض التكلفة لترميز NeRF. المستخدمة في التخزين المؤقت للإشعاع العصبي [Müller et al. 2021]. |
| خسائر | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | خسارة L1 القياسية. |
| النسبي L1 | include/tiny-cuda-nn/losses/l1.h | خسارة L1 النسبية التي تم تطبيعها من خلال تنبؤ الشبكة. |
| ماب | include/tiny-cuda-nn/losses/mape.h | يعني النسبة المئوية للخطأ المطلق (MAPE). نفس L1 النسبي، ولكن تم تطبيعه بواسطة الهدف. |
| سماب | include/tiny-cuda-nn/losses/smape.h | المتوسط المتماثل لخطأ النسبة المطلقة (SMAPE). نفس النسبي L1، ولكن تم تطبيعه بواسطة متوسط التنبؤ والهدف. |
| L2 | include/tiny-cuda-nn/losses/l2.h | خسارة L2 القياسية. |
| النسبي L2 | include/tiny-cuda-nn/losses/relative_l2.h | تم تطبيع خسارة L2 النسبية من خلال تنبؤ الشبكة [Lehtinen et al. 2018]. |
| النصوع النسبي L2 | include/tiny-cuda-nn/losses/relative_l2_luminance.h | كما هو مذكور أعلاه، ولكن تم تطبيعه من خلال نصوع تنبؤ الشبكة. ينطبق فقط عندما يكون تنبؤ الشبكة هو RGB. المستخدمة في التخزين المؤقت للإشعاع العصبي [Müller et al. 2021]. |
| عبر الانتروبيا | include/tiny-cuda-nn/losses/cross_entropy.h | خسارة الإنتروبيا القياسية. ينطبق فقط عندما يكون تنبؤ الشبكة بتنسيق PDF. |
| التباين | include/tiny-cuda-nn/losses/variance_is.h | خسارة التباين القياسية. ينطبق فقط عندما يكون تنبؤ الشبكة بتنسيق PDF. |
| محسنات | ||
|---|---|---|
| آدم | include/tiny-cuda-nn/optimizers/adam.h | تنفيذ Adam [Kingma and Ba 2014]، معممًا على AdaBound [Luo et al. 2019]. |
| نوفوغراد | include/tiny-cuda-nn/optimizers/lookahead.h | تنفيذ نوفوغراد [جينسبيرغ وآخرون. 2019]. |
| دولار سنغافوري | include/tiny-cuda-nn/optimizers/sgd.h | النسب التدرج العشوائي القياسي (SGD). |
| شامبو | include/tiny-cuda-nn/optimizers/shampoo.h | تنفيذ مُحسِّن الشامبو من الدرجة الثانية [Gupta et al. 2018] مع التحسينات المحلية وكذلك تلك التي أجراها Anil et al. [2020]. |
| متوسط | include/tiny-cuda-nn/optimizers/average.h | يلتف مُحسِّن آخر ويحسب المتوسط الخطي للأوزان خلال التكرارات N الأخيرة. يتم استخدام المتوسط للاستدلال فقط (لا يعود بالفائدة على التدريب). |
| دفعة | include/tiny-cuda-nn/optimizers/batched.h | يلتف محسن آخر، ويستدعي المحسن المتداخل مرة واحدة كل N خطوة على التدرج المتوسط. له نفس تأثير زيادة حجم الدفعة ولكنه يتطلب فقط مقدارًا ثابتًا من الذاكرة. |
| مركب | include/tiny-cuda-nn/optimizers/composite.h | يسمح باستخدام العديد من أدوات تحسين الأداء على معلمات مختلفة. |
| إما | include/tiny-cuda-nn/optimizers/average.h | يلتف محسن آخر ويحسب المتوسط المتحرك الأسي للأوزان. يتم استخدام المتوسط للاستدلال فقط (لا يعود بالفائدة على التدريب). |
| الاضمحلال الأسي | include/tiny-cuda-nn/optimizers/exponential_decay.h | يلتف مُحسِّن آخر ويؤدي إلى انخفاض معدل التعلم الأسي بشكل ثابت. |
| نظرة إلى الأمام | include/tiny-cuda-nn/optimizers/lookahead.h | يلتف مُحسِّن آخر، وينفذ خوارزمية البحث الأمامي [Zhang et al. 2019]. |
تم ترخيص إطار العمل هذا بموجب ترخيص BSD المكون من 3 فقرات. الرجاء مراجعة LICENSE.txt للحصول على التفاصيل.
إذا كنت تستخدمه في بحثك، فإننا نقدر الاستشهاد عبر
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}للاستفسارات التجارية، يرجى زيارة موقعنا على الإنترنت وإرسال النموذج: NVIDIA Research Licensing
ومن بين أمور أخرى، يعمل هذا الإطار على تشغيل المنشورات التالية:
بدايات الرسومات العصبية الفورية مع ترميز التجزئة متعدد الحلول
توماس مولر، أليكس إيفانز، كريستوف شيد، ألكسندر كيلر
معاملات ACM على الرسومات ( SIGGRAPH )، يوليو 2022
الموقع الإلكتروني / الورق / الكود / الفيديو / BibTeX
استخراج النماذج الثلاثية الأبعاد والمواد والإضاءة من الصور
جاكوب مونكبيرج، جون هاسيلجرين، تيانتشانج شين، جون جاو، وينزينج تشين، أليكس إيفانز، توماس مولر، سانجا فيدلر
CVPR (عن طريق الفم) ، يونيو 2022
الموقع الإلكتروني / الورق / الفيديو / BibTeX
التخزين المؤقت للإشعاع العصبي في الوقت الفعلي لتتبع المسار
توماس مولر، فابريس روسيل، جان نوفاك، ألكسندر كيلر
معاملات ACM على الرسومات ( SIGGRAPH )، أغسطس 2021
ورقة / GTC talk / فيديو / عارض النتائج التفاعلية / BibTeX
وكذلك البرامج التالية:
NerfAcc: مجموعة أدوات تسريع NeRF العامة
رويلونج لي، ماثيو تانسيك، أنجو كانازاوا
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio: إطار لتطوير مجال الإشعاع العصبي
ماثيو تانسيك*، إيثان ويبر*، إيفون نج*، رويلونج لي، برنت يي، تيرانس وانج، ألكسندر كريستوفرسن، جيك أوستن، كاميار صلاحي، أبهيك أهوجا، ديفيد مكاليستر، أنجو كانازاوا
https://github.com/nerfstudio-project/nerfstudio
لا تتردد في تقديم طلب سحب إذا لم يكن المنشور أو البرنامج الخاص بك مدرجًا.
نتوجه بالشكر الخاص إلى مؤلفي NRC على المناقشات المفيدة وإلى نيكولاس بيندر لتوفير جزء من البنية التحتية لهذا الإطار، وكذلك للمساعدة في استخدام TensorCores من داخل CUDA.


