

روبوت جديد في المدينة: SO-100

لقد أضفنا للتو برنامجًا تعليميًا جديدًا حول كيفية بناء روبوت بأسعار معقولة، بسعر 110 دولارات للذراع!
قم بتعليمه مهارات جديدة من خلال عرض بعض الحركات عليه باستخدام جهاز كمبيوتر محمول فقط.
ثم شاهد الروبوت المنزلي الخاص بك وهو يتصرف بشكل مستقل؟
اتبع الرابط إلى البرنامج التعليمي الكامل لـ SO-100.
LeRobot: أحدث تقنيات الذكاء الاصطناعي للروبوتات في العالم الحقيقي
؟ يهدف LeRobot إلى توفير النماذج ومجموعات البيانات والأدوات للروبوتات في العالم الحقيقي في PyTorch. الهدف هو تقليل حاجز الدخول إلى الروبوتات حتى يتمكن الجميع من المساهمة والاستفادة من مشاركة مجموعات البيانات والنماذج المدربة مسبقًا.
؟ يحتوي LeRobot على أحدث الأساليب التي ثبت أنها تنتقل إلى العالم الحقيقي مع التركيز على التعلم بالتقليد والتعلم المعزز.
؟ يوفر LeRobot بالفعل مجموعة من النماذج المدربة مسبقًا، ومجموعات البيانات مع العروض التوضيحية التي تم جمعها بواسطة الإنسان، وبيئات المحاكاة للبدء دون تجميع الروبوت. في الأسابيع المقبلة، تتمثل الخطة في إضافة المزيد والمزيد من الدعم للروبوتات في العالم الحقيقي على الروبوتات ذات الأسعار المعقولة والأكثر قدرة.
؟ يستضيف LeRobot نماذج ومجموعات بيانات مُدربة مسبقًا على صفحة مجتمع Hugging Face: Huggingface.co/lerobot
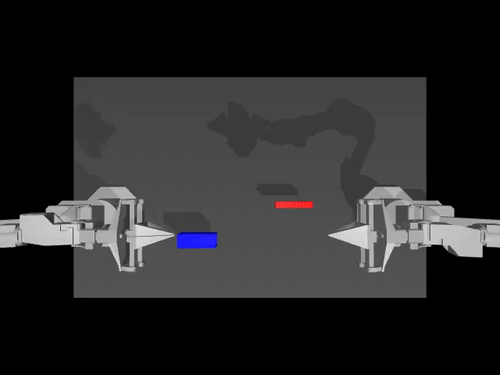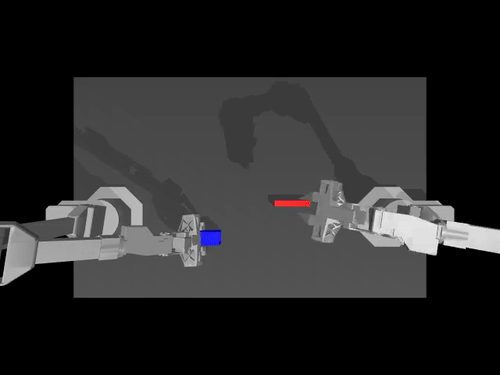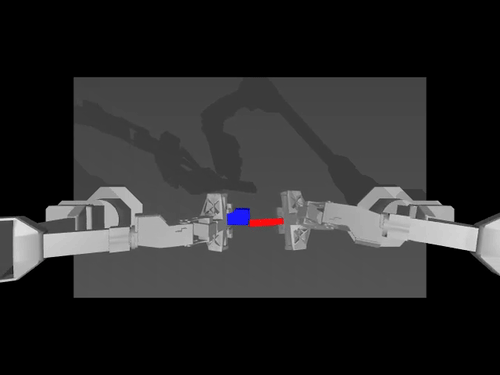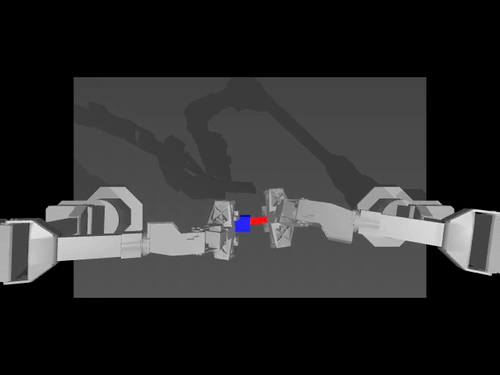 |  |  |
| سياسة ACT بشأن ALOHA env | سياسة TDMPC على SimXArm env | سياسة الانتشار على بيئة PushT |
قم بتنزيل كود المصدر الخاص بنا:
git clone https://github.com/huggingface/lerobot.git
cd lerobot أنشئ بيئة افتراضية باستخدام Python 3.10 وقم بتنشيطها، على سبيل المثال باستخدام miniconda :
conda create -y -n lerobot python=3.10
conda activate lerobotثَبَّتَ ؟ ليروبوت:
pip install -e .ملاحظة: اعتمادًا على نظامك الأساسي، إذا واجهت أي أخطاء في البناء أثناء هذه الخطوة، فقد تحتاج إلى تثبيت
cmakeوbuild-essentialلبناء بعض التبعيات لدينا. على نظام التشغيل Linux:sudo apt-get install cmake build-essential
للمحاكاة،؟ يأتي LeRobot مع بيئات صالة للألعاب الرياضية يمكن تثبيتها كإضافات:
التثبيت مثلا ؟ LeRobot مع الوها وPusht، استخدم:
pip install -e " .[aloha, pusht] "لاستخدام الأوزان والتحيزات لتتبع التجربة، قم بتسجيل الدخول باستخدام
wandb login(ملاحظة: ستحتاج أيضًا إلى تمكين WandB في التكوين. انظر أدناه.)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
راجع المثال 1 الذي يوضح كيفية استخدام فئة مجموعة البيانات الخاصة بنا والتي تقوم بتنزيل البيانات تلقائيًا من مركز Hugging Face.
يمكنك أيضًا تصور الحلقات محليًا من مجموعة بيانات على المركز عن طريق تنفيذ البرنامج النصي الخاص بنا من سطر الأوامر:
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 أو من مجموعة بيانات في مجلد محلي باستخدام متغير البيئة الجذر DATA_DIR (في الحالة التالية، سيتم البحث عن مجموعة البيانات في ./my_local_data_dir/lerobot/pusht )
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 سيتم فتح rerun.io وعرض تدفقات الكاميرا وحالات الروبوت وإجراءاته، مثل هذا:
يمكن للبرنامج النصي الخاص بنا أيضًا تصور مجموعات البيانات المخزنة على خادم بعيد. راجع python lerobot/scripts/visualize_dataset.py --help لمزيد من الإرشادات.
LeRobotDataset مجموعة البيانات بتنسيق LeRobotDataset سهلة الاستخدام للغاية. يمكن تحميلها من مستودع على مركز Hugging Face أو من مجلد محلي ببساطة باستخدام dataset = LeRobotDataset("lerobot/aloha_static_coffee") ويمكن فهرستها مثل أي مجموعة بيانات Hugging Face وPyTorch. على سبيل المثال، ستسترد dataset[0] إطارًا زمنيًا واحدًا من مجموعة البيانات التي تحتوي على الملاحظة (الملاحظات) وإجراءًا كموترات PyTorch جاهزة لتغذيتها إلى نموذج.
خصوصية LeRobotDataset هي أنه بدلاً من استرداد إطار واحد من خلال فهرسه، يمكننا استرداد عدة إطارات بناءً على علاقتها الزمنية مع الإطار المفهرس، عن طريق تعيين delta_timestamps على قائمة الأوقات النسبية فيما يتعلق بالإطار المفهرس. على سبيل المثال، باستخدام delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} يمكن للمرء استرجاع 4 إطارات لفهرس معين: 3 إطارات "سابقة" ثانية واحدة و0.5 ثانية و 0.2 ثانية قبل الإطار المفهرس والإطار المفهرس نفسه (المناظر للإدخال 0). راجع المثال 1_load_lerobot_dataset.py لمزيد من التفاصيل حول delta_timestamps .
تحت الغطاء، يستخدم تنسيق LeRobotDataset عدة طرق لتسلسل البيانات التي يمكن أن تكون مفيدة لفهم ما إذا كنت تخطط للعمل بشكل أوثق مع هذا التنسيق. لقد حاولنا إنشاء تنسيق مجموعة بيانات مرن وبسيط من شأنه أن يغطي معظم أنواع الميزات والخصائص الموجودة في التعلم المعزز والروبوتات، في المحاكاة وفي العالم الحقيقي، مع التركيز على الكاميرات وحالات الروبوت ولكن يمتد بسهولة إلى أنواع أخرى من الحسية المدخلات طالما يمكن تمثيلها بواسطة موتر.
فيما يلي التفاصيل المهمة وتنظيم البنية الداخلية لمجموعة LeRobotDataset النموذجية التي تم إنشاؤها باستخدام dataset = LeRobotDataset("lerobot/aloha_static_coffee") . ستتغير الميزات الدقيقة من مجموعة بيانات إلى مجموعة بيانات ولكن ليس الجوانب الرئيسية:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
يتم إجراء تسلسل لـ LeRobotDataset باستخدام العديد من تنسيقات الملفات واسعة الانتشار لكل جزء من أجزائها، وهي:
safetensorsafetensor يمكن تحميل/تنزيل مجموعة البيانات من مركز HuggingFace بسلاسة. للعمل على مجموعة بيانات محلية، يمكنك تعيين متغير البيئة DATA_DIR إلى مجلد مجموعة البيانات الجذر كما هو موضح في القسم أعلاه حول تصور مجموعة البيانات.
راجع المثال 2 الذي يوضح كيفية تنزيل سياسة تم تدريبها مسبقًا من Hugging Face hub، وإجراء تقييم على البيئة المقابلة لها.
كما نقدم أيضًا برنامجًا نصيًا أكثر قدرة على موازنة التقييم عبر بيئات متعددة أثناء عملية الطرح نفسها. فيما يلي مثال لنموذج تم تدريبه مسبقًا ومستضاف على lerobot/diffusion_pusht:
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10ملاحظة: بعد تدريب سياستك الخاصة، يمكنك إعادة تقييم نقاط التفتيش باستخدام:
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model راجع python lerobot/scripts/eval.py --help لمزيد من الإرشادات.
راجع المثال 3 الذي يوضح كيفية تدريب نموذج باستخدام مكتبتنا الأساسية في لغة بايثون، والمثال 4 الذي يوضح كيفية استخدام البرنامج النصي للتدريب من سطر الأوامر.
بشكل عام، يمكنك استخدام البرنامج النصي التدريبي الخاص بنا لتدريب أي سياسة بسهولة. فيما يلي مثال لتدريب سياسة ACT على المسارات التي جمعها البشر في بيئة محاكاة Aloha لمهمة الإدراج:
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human يتم إنشاء دليل التجربة تلقائيًا وسيظهر باللون الأصفر في جهازك. يبدو مثل outputs/train/2024-05-05/20-21-12_aloha_act_default . يمكنك تحديد دليل التجربة يدويًا عن طريق إضافة هذه الوسيطة إلى أمر train.py python:
hydra.run.dir=your/new/experiment/dir سيكون هناك في دليل التجربة مجلد يسمى checkpoints والذي سيكون له البنية التالية:
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step لاستئناف التدريب من نقطة تفتيش، يمكنك إضافة هذه العناصر إلى أمر train.py python:
hydra.run.dir=your/original/experiment/dir resume=trueسيتم تحميل النموذج الذي تم تدريبه مسبقًا والمُحسِّن وحالات الجدولة للتدريب. لمزيد من المعلومات، يرجى الاطلاع على البرنامج التعليمي الخاص بنا حول استئناف التدريب هنا.
لاستخدام wandb لتسجيل منحنيات التدريب والتقييم، تأكد من تشغيل wandb login كخطوة إعداد لمرة واحدة. بعد ذلك، عند تشغيل أمر التدريب أعلاه، قم بتمكين WandB في التكوين عن طريق إضافة:
wandb.enable=trueسيظهر أيضًا رابط لسجلات wandb الخاصة بالتشغيل باللون الأصفر في جهازك الطرفي. فيما يلي مثال لما تبدو عليه في متصفحك. يرجى أيضًا التحقق هنا للحصول على شرح لبعض المقاييس شائعة الاستخدام في السجلات.

ملاحظة: من أجل الكفاءة، أثناء التدريب، يتم تقييم كل نقطة تفتيش على عدد منخفض من الحلقات. يمكنك استخدام eval.n_episodes=500 لتقييم حلقات أكثر من الحلقة الافتراضية. أو، بعد التدريب، قد ترغب في إعادة تقييم أفضل نقاط التحقق لديك في المزيد من الحلقات أو تغيير إعدادات التقييم. راجع python lerobot/scripts/eval.py --help لمزيد من الإرشادات.
لقد قمنا بتنظيم ملفات التكوين الخاصة بنا (الموجودة ضمن lerobot/configs ) بحيث تقوم بإعادة إنتاج نتائج SOTA من متغير نموذج معين في أعمالها الأصلية. تشغيل ببساطة:
python lerobot/scripts/train.py policy=diffusion env=pushtإعادة إنتاج نتائج SOTA لسياسة النشر في مهمة PushT.
يمكن العثور على السياسات المُدربة مسبقًا، إلى جانب تفاصيل النسخ، ضمن قسم "النماذج" في https://huggingface.co/lerobot.
إذا كنت ترغب في المساهمة في؟ LeRobot، يرجى مراجعة دليل المساهمة الخاص بنا.
لإضافة مجموعة بيانات إلى المركز، تحتاج إلى تسجيل الدخول باستخدام رمز الوصول للكتابة، والذي يمكن إنشاؤه من إعدادات Hugging Face:
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential ثم أشر إلى مجلد مجموعة البيانات الأولية (على سبيل المثال data/aloha_static_pingpong_test_raw )، وادفع مجموعة البيانات الخاصة بك إلى المركز باستخدام:
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 راجع python lerobot/scripts/push_dataset_to_hub.py --help لمزيد من الإرشادات.
إذا كان تنسيق مجموعة البيانات الخاص بك غير مدعوم، فقم بتنفيذ تنسيقك الخاص في lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py عن طريق نسخ أمثلة مثل Pusht_zarr، أو umi_zarr، أو aloha_hdf5، أو xarm_pkl.
بمجرد تدريبك على السياسة، يمكنك تحميلها إلى مركز Hugging Face باستخدام معرف المركز الذي يشبه ${hf_user}/${repo_name} (على سبيل المثال، lerobot/diffusion_pusht).
تحتاج أولاً إلى العثور على مجلد نقاط التفتيش الموجود داخل دليل تجربتك (على سبيل المثال، outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). يوجد ضمن ذلك دليل pretrained_model والذي يجب أن يحتوي على:
config.json : نسخة متسلسلة من تكوين السياسة (تتبع تكوين فئة بيانات السياسة).model.safetensors : مجموعة من معلمات torch.nn.Module ، المحفوظة بتنسيق Hugging Face Safetensors.config.yaml : تكوين تدريب Hydra موحد يحتوي على تكوينات السياسة والبيئة ومجموعة البيانات. يجب أن يتطابق تكوين السياسة مع config.json تمامًا. يعد تكوين البيئة مفيدًا لأي شخص يريد تقييم سياستك. يعمل تكوين مجموعة البيانات فقط كمسار ورقي لإمكانية التكرار.لتحميلها إلى المركز، قم بتشغيل ما يلي:
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_modelراجع eval.py للحصول على مثال حول كيفية استخدام الأشخاص الآخرين لسياستك.
مثال على مقتطف التعليمات البرمجية لملف تقييم السياسة:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function إذا أردت، يمكنك الاستشهاد بهذا العمل مع:
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}بالإضافة إلى ذلك، إذا كنت تستخدم أيًا من هياكل السياسات أو النماذج أو مجموعات البيانات المعدة مسبقًا، فمن المستحسن الاستشهاد بالمؤلفين الأصليين للعمل كما يظهرون أدناه:
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

