EasyOCR
v1.7.2
التعرف الضوئي على الحروف (OCR) جاهز للاستخدام مع أكثر من 80 لغة مدعومة وجميع نصوص الكتابة الشائعة بما في ذلك: اللاتينية والصينية والعربية والديفاناغاري والسيريلية وما إلى ذلك.
جرب العرض التوضيحي على موقعنا
متكاملة في مساحات المعانقة؟ باستخدام غراديو. جرب العرض التوضيحي للويب:
24 سبتمبر 2024 - الإصدار 1.7.2
اقرأ جميع ملاحظات الإصدار



التثبيت باستخدام pip
للحصول على أحدث إصدار مستقر:
pip install easyocrللحصول على أحدث إصدار التطوير:
pip install git+https://github.com/JaidedAI/EasyOCR.git ملاحظة 1: بالنسبة لنظام التشغيل Windows، يرجى تثبيت torch وtorchvision أولاً باتباع الإرشادات الرسمية هنا https://pytorch.org. على موقع pytorch، تأكد من تحديد إصدار CUDA المناسب لديك. إذا كنت تنوي التشغيل على وضع وحدة المعالجة المركزية (CPU) فقط، فحدد CUDA = None .
ملاحظة 2: نوفر أيضًا ملف Dockerfile هنا.
import easyocr
reader = easyocr . Reader ([ 'ch_sim' , 'en' ]) # this needs to run only once to load the model into memory
result = reader . readtext ( 'chinese.jpg' )سيكون الإخراج بتنسيق قائمة، ويمثل كل عنصر مربعًا محيطًا، والنص المكتشف والمستوى الواثق، على التوالي.
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路' , 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西' , 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东' , 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], ' 315 ' , 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], ' 309 ' , 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], ' Yuyuan Rd. ' , 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], ' W ' , 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], ' E ' , 0.8405593633651733)] ملاحظة 1: ['ch_sim','en'] هي قائمة اللغات التي تريد قراءتها. يمكنك اجتياز عدة لغات في وقت واحد، ولكن لا يمكن استخدام كل اللغات معًا. اللغة الإنجليزية متوافقة مع كل لغة واللغات التي تشترك في الأحرف المشتركة عادة ما تكون متوافقة مع بعضها البعض.
ملاحظة 2: بدلاً من مسار الملف chinese.jpg ، يمكنك أيضًا تمرير كائن صورة OpenCV (مصفوفة numpy) أو ملف صورة على هيئة بايت. يعد عنوان URL لصورة أولية مقبولًا أيضًا.
ملاحظة 3: reader = easyocr.Reader(['ch_sim','en']) مخصص لتحميل نموذج في الذاكرة. يستغرق الأمر بعض الوقت ولكن يجب تشغيله مرة واحدة فقط.
يمكنك أيضًا تعيين detail=0 لإخراج أبسط.
reader . readtext ( 'chinese.jpg' , detail = 0 )نتيجة:
[ '愚园路' , '西' , '东' , ' 315 ' , ' 309 ' , ' Yuyuan Rd. ' , ' W ' , ' E ' ]سيتم تنزيل أوزان النماذج للغة المختارة تلقائيًا أو يمكنك تنزيلها يدويًا من مركز النماذج ووضعها في المجلد "~/.EasyOCR/model"
في حالة عدم وجود وحدة معالجة رسومات (GPU) لديك، أو أن ذاكرة وحدة معالجة الرسومات (GPU) الخاصة بك منخفضة، يمكنك تشغيل النموذج في وضع وحدة المعالجة المركزية (CPU) فقط عن طريق إضافة gpu=False .
reader = easyocr . Reader ([ 'ch_sim' , 'en' ], gpu = False )لمزيد من المعلومات، اقرأ البرنامج التعليمي ووثائق API.
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=Trueللتعرف على نموذج التعرف، اقرأ هنا.
للتعرف على نموذج الكشف (CRAFT)، اقرأ هنا.
reader = easyocr . Reader ([ 'en' ], detection = 'DB' , recognition = 'Transformer' )الفكرة هي أن تكون قادرًا على توصيل أي نموذج حديث في EasyOCR. هناك الكثير من العباقرة الذين يحاولون إنشاء نماذج كشف/تعرف أفضل، لكننا لا نحاول أن نكون عباقرة هنا. نريد فقط أن نجعل أعمالهم متاحة بسرعة للجمهور ... مجانًا. (حسنًا، نعتقد أن معظم العباقرة يريدون أن يخلق عملهم تأثيرًا إيجابيًا بأسرع ما يمكن/كبيرًا قدر الإمكان) يجب أن يكون خط الأنابيب مشابهًا للرسم البياني أدناه. الفتحات الرمادية عبارة عن عناصر نائبة للوحدات ذات اللون الأزرق الفاتح القابلة للتغيير.
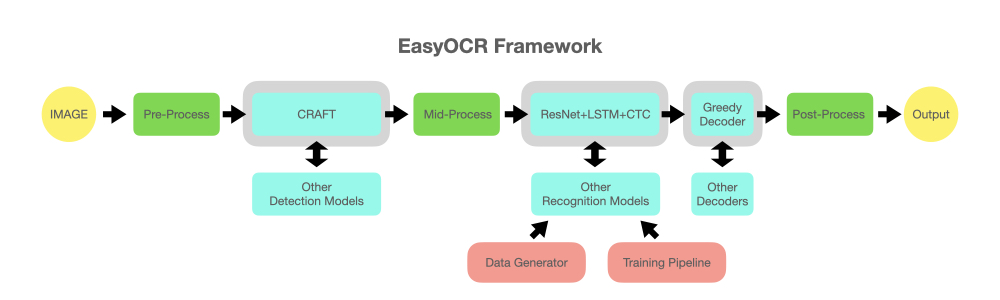
يعتمد هذا المشروع على البحث والتعليمات البرمجية من عدة أوراق ومستودعات مفتوحة المصدر.
تعتمد جميع عمليات تنفيذ التعلم العميق على Pytorch. ❤️
يستخدم تنفيذ الكشف خوارزمية CRAFT من هذا المستودع الرسمي وأوراقهم (شكرًا @YoungminBaek من @clovaai). نحن نستخدم أيضًا نموذجهم المُدرب مسبقًا. يتم توفير البرنامج النصي للتدريب بواسطة @gmuffiness.
نموذج التعرف هو CRNN (ورقة). وهو يتألف من ثلاثة مكونات رئيسية: استخراج الميزات (نستخدم حاليًا Resnet) وVGG ووضع العلامات التسلسلية (LSTM) وفك التشفير (CTC). إن مسار التدريب لتنفيذ التعرف هو نسخة معدلة من الإطار المعياري للتعرف على النص العميق. (شكرًا @ku21fan من @clovaai) هذا المستودع جوهرة تستحق المزيد من التقدير.
يعتمد رمز بحث Beam على هذا المستودع ومدونته. (شكرًا @githubharald)
يعتمد تركيب البيانات على TextRecognitionDataGenerator. (شكرًا @ بلفال)
وقراءة جيدة عن CTC من distill.pub هنا.
دعونا نتقدم الإنسانية معًا من خلال إتاحة الذكاء الاصطناعي للجميع!
3 طرق للمساهمة:
المبرمج: يرجى إرسال العلاقات العامة للأخطاء/التحسينات الصغيرة. بالنسبة للأكبر، ناقش معنا بفتح مشكلة أولاً. توجد قائمة بمشكلات الأخطاء/التحسينات المحتملة التي تحمل علامة "PR WELCOME".
المستخدم: أخبرنا كيف يفيدك EasyOCR أنت/مؤسستك لتشجيع المزيد من التطوير. قم أيضًا بنشر حالات الفشل في قسم المشكلات للمساعدة في تحسين النماذج المستقبلية.
قائد التكنولوجيا/المعلم: إذا وجدت هذه المكتبة مفيدة، يرجى نشر الكلمة! (راجع مشاركة Yann Lecun حول EasyOCR)
لطلب لغة جديدة، نحتاج منك إرسال PR مع الملفين التاليين:
إذا كانت لغتك تحتوي على عناصر فريدة (مثل 1. العربية: يتغير شكل الأحرف عند ربطها ببعضها البعض + الكتابة من اليمين إلى اليسار 2. التايلاندية: يجب أن تكون بعض الأحرف فوق السطر والبعض الآخر أدناه)، يرجى تثقيفنا للأفضل من قدرتك و/أو إعطاء روابط مفيدة. من المهم الاهتمام بالتفاصيل لتحقيق نظام يعمل حقًا.
أخيرًا، يرجى تفهم أن أولويتنا يجب أن تذهب إلى اللغات الشائعة أو مجموعات اللغات التي تتشارك في أجزاء كبيرة من أحرفها مع بعضها البعض (أخبرنا أيضًا إذا كان هذا هو الحال بالنسبة للغتك). يستغرق الأمر منا أسبوعًا على الأقل لتطوير نموذج جديد، لذلك قد تضطر إلى الانتظار بعض الوقت حتى يتم إصدار النموذج الجديد.
راجع قائمة اللغات قيد التطوير
نظرًا لمحدودية الموارد، سيتم إغلاق الإصدار الأقدم من 6 أشهر تلقائيًا. الرجاء فتح الموضوع مرة أخرى إذا كان ضروريا.
بالنسبة لدعم المؤسسات، يقدم Jaided AI خدمة كاملة لأنظمة التعرف الضوئي على الحروف/الذكاء الاصطناعي المخصصة بدءًا من التنفيذ والتدريب/الضبط الدقيق والنشر. انقر هنا للاتصال بنا.


