nmt
1.0.0
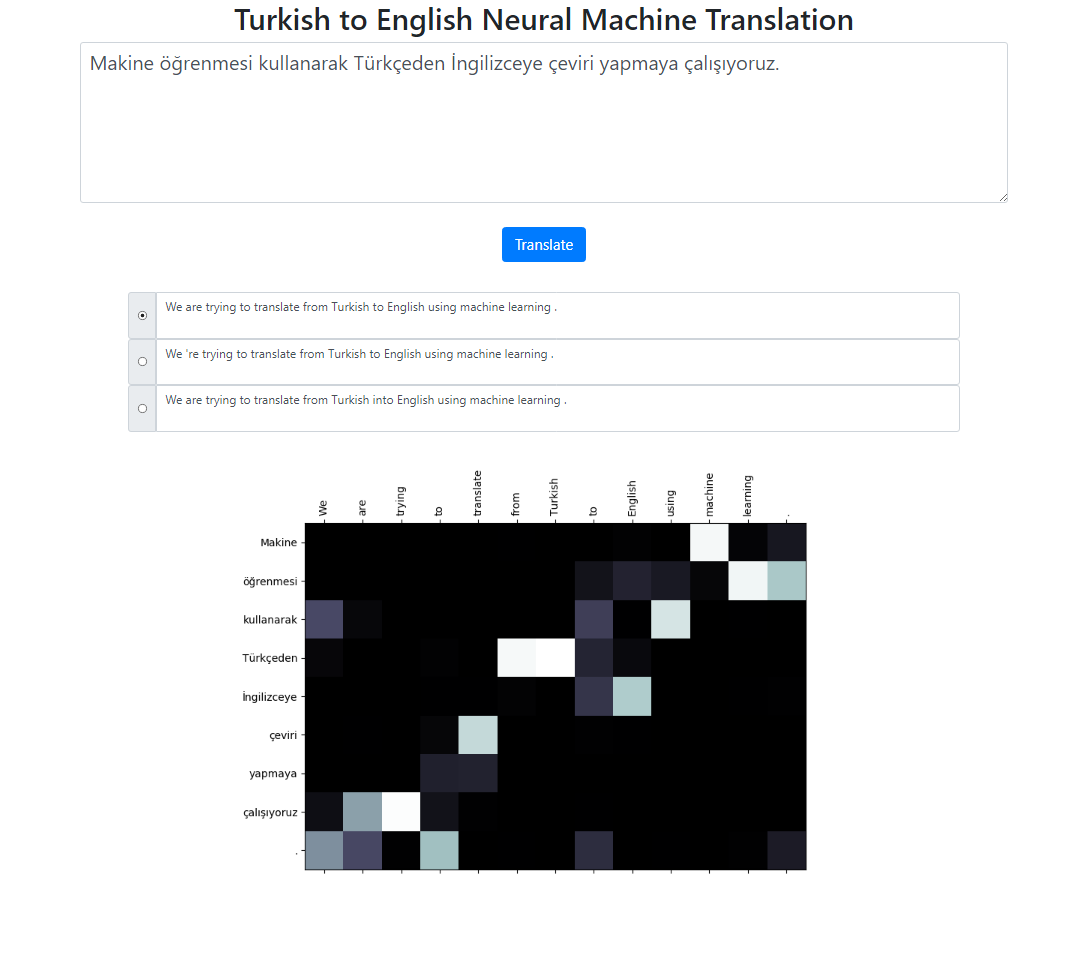
يطبق هذا المستودع نظام الترجمة الآلية العصبية من التركية إلى الإنجليزية باستخدام نموذج Seq2Seq + Global Attention. يوجد أيضًا تطبيق Flask الذي يمكنك تشغيله محليًا. يمكنك إدخال النص وترجمته وفحص النتائج بالإضافة إلى تصور الانتباه. نقوم بتشغيل بحث الشعاع بحجم الشعاع 3 في الخلفية ونعيد التسلسلات الأكثر احتمالاً مرتبة حسب درجاتها النسبية.
مجموعة البيانات لهذا المشروع مأخوذة من هنا. لقد استخدمت مجموعة تتويبا. لقد قمت بحذف بعض التكرارات الموجودة في البيانات. لقد قمت أيضًا بترميز مجموعة البيانات مسبقًا. يمكن العثور على النسخة النهائية في مجلد البيانات.
لترميز الجمل التركية، استخدمت RegexpTokenizer الخاص بـ nltk.
puncts_except_apostrofe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_except_apostrofe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "تيتانيك 15 نيسان/أبريل في الساعة 02:20."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# الإخراج: تيتانيك 15 نيسان في الساعة 02 : 20' في الساعة .# خاصية التقسيم هذه على "02 : 20" يختلف عن الرمز المميز باللغة الإنجليزية.# يمكننا التعامل مع هذه المواقف ولكن أردت أن أبقي الأمر بسيطًا وأرى ما إذا كان توزيع الانتباه على هذه الكلمات يتوافق مع الرموز الإنجليزية.# هناك حالات مماثلة في الغالب في التواريخ أيضًا كما في هذا المثال: 02/09/2019من أجل ترميز الجمل الإنجليزية، استخدمت نموذج سباسي الإنجليزي.
en_nlp = spacy.load('en_core_web_sm')text = "غرقت السفينة تيتانيك في الساعة 02:20 يوم الاثنين، 15 أبريل."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text ]))#النتيجة: غرقت سفينة تايتانيك الساعة 02:20 يوم الاثنين 15 أبريل .ومن المتوقع أن تكون الجمل التركية والإنجليزية في ملفين مختلفين.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
الرجاء تشغيل python train.py -h للحصول على القائمة الكاملة للوسائط.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
لحساب الدرجة الزرقاء على مستوى الجسم.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
لتشغيل التطبيق محليًا، قم بتشغيل:
python app.py
تأكد من تحديد مسارات النموذج في ملف config.py بشكل صحيح.
ملف النموذج
ملف المفردات
استخدام وحدات الكلمات الفرعية (باللغتين التركية والإنجليزية)
آليات انتباه مختلفة (تعلم معايير مختلفة للانتباه)
رمز الهيكل العظمي لهذا المشروع مأخوذ من دورة البرمجة اللغوية العصبية في جامعة ستانفورد: CS224n


