دورة نموذج اللغة الكبيرة
؟ تابعوني على X • ? معانقة الوجه • المدونة • ? التدريب العملي على GNN
تنقسم دورة LLM إلى ثلاثة أجزاء:
- ؟ يغطي LLM Fundamentals المعرفة الأساسية حول الرياضيات وPython والشبكات العصبية.
- ?? يركز LLM Scientist على بناء أفضل LLMs الممكنة باستخدام أحدث التقنيات.
- ؟ يركز مهندس LLM على إنشاء التطبيقات المستندة إلى LLM ونشرها.
للحصول على نسخة تفاعلية من هذه الدورة، قمت بإنشاء اثنين من مساعدي LLM الذين سيجيبون على الأسئلة ويختبرون معرفتك بطريقة شخصية:
- ؟ HuggingChat Assistant : نسخة مجانية باستخدام Mixtral-8x7B.
- ؟ مساعد ChatGPT : يتطلب حسابًا متميزًا.
دفاتر الملاحظات
قائمة الدفاتر والمقالات المتعلقة بنماذج اللغات الكبيرة.
أدوات
| دفتر الملاحظات | وصف | دفتر الملاحظات |
|---|
| ؟ التقييم التلقائي للماجستير في القانون | قم بتقييم LLMs الخاص بك تلقائيًا باستخدام RunPod | |
| ؟ LazyMergekit | يمكنك دمج النماذج بسهولة باستخدام MergeKit بنقرة واحدة. | |
| ؟ LazyAxolotl | قم بضبط النماذج في السحابة باستخدام Axolotl بنقرة واحدة. | |
| ⚡الكمية التلقائية | قم بقياس LLMs بتنسيقات GGUF وGPTQ وEXL2 وAWQ وHQQ بنقرة واحدة. | |
| ؟ شجرة العائلة النموذجية | تصور شجرة العائلة للنماذج المدمجة. | |
| صفر سبيس | قم بإنشاء واجهة دردشة Gradio تلقائيًا باستخدام ZeroGPU المجاني. | |
الكون المثالى
| دفتر الملاحظات | وصف | شرط | دفتر الملاحظات |
|---|
| قم بضبط Llama 2 باستخدام QLoRA | دليل خطوة بخطوة للضبط الدقيق لـ Llama 2 في Google Colab. | شرط | |
| ضبط CodeLlama باستخدام Axolotl | دليل شامل لأحدث الأدوات للضبط الدقيق. | شرط | |
| ضبط ميسترال-7b بدقة مع QLoRA | تم الإشراف على الضبط الدقيق لـ Mistral-7b في Google Colab ذو الطبقة المجانية مع TRL. | | |
| قم بضبط ميسترال-7ب باستخدام DPO | تعزيز أداء النماذج المضبوطة الخاضعة للإشراف باستخدام DPO. | شرط | |
| قم بضبط Llama 3 باستخدام ORPO | ضبط دقيق أرخص وأسرع في مرحلة واحدة باستخدام ORPO. | شرط | |
| قم بضبط Llama 3.1 باستخدام Unsloth | ضبط دقيق فائق الكفاءة تحت الإشراف في Google Colab. | شرط | |
التكميم
| دفتر الملاحظات | وصف | شرط | دفتر الملاحظات |
|---|
| مقدمة في التكميم | تحسين نموذج اللغة الكبير باستخدام التكميم 8 بت. | شرط | |
| تكميم 4 بت باستخدام GPTQ | قم بقياس شهادات LLM مفتوحة المصدر الخاصة بك لتشغيلها على الأجهزة الاستهلاكية. | شرط | |
| التكميم مع GGUF وllama.cpp | قم بقياس نماذج Llama 2 باستخدام llama.cpp وتحميل إصدارات GGUF إلى HF Hub. | شرط | |
| ExLlamaV2: أسرع مكتبة لتشغيل LLMs | قياس وتشغيل نماذج EXL2 وتحميلها على HF Hub. | شرط | |
آخر
| دفتر الملاحظات | وصف | شرط | دفتر الملاحظات |
|---|
| استراتيجيات فك التشفير في نماذج اللغات الكبيرة | دليل لتوليد النص من البحث عن الشعاع إلى أخذ عينات النواة | شرط | |
| تحسين ChatGPT باستخدام الرسوم البيانية المعرفية | قم بتعزيز إجابات ChatGPT باستخدام الرسوم البيانية المعرفية. | شرط | |
| دمج LLMs مع MergeKit | أنشئ نماذجك الخاصة بسهولة، دون الحاجة إلى وحدة معالجة الرسومات! | شرط | |
| إنشاء MoEs باستخدام MergeKit | الجمع بين العديد من الخبراء في FrankenMoE واحد | شرط | |
| قم بإلغاء الرقابة على أي LLM مع الإلغاء | الضبط الدقيق دون إعادة التدريب | شرط | |
؟ أساسيات LLM
يقدم هذا القسم المعرفة الأساسية حول الرياضيات وبايثون والشبكات العصبية. قد لا ترغب في البدء هنا ولكن يمكنك الرجوع إليها حسب الحاجة.
تبديل القسم
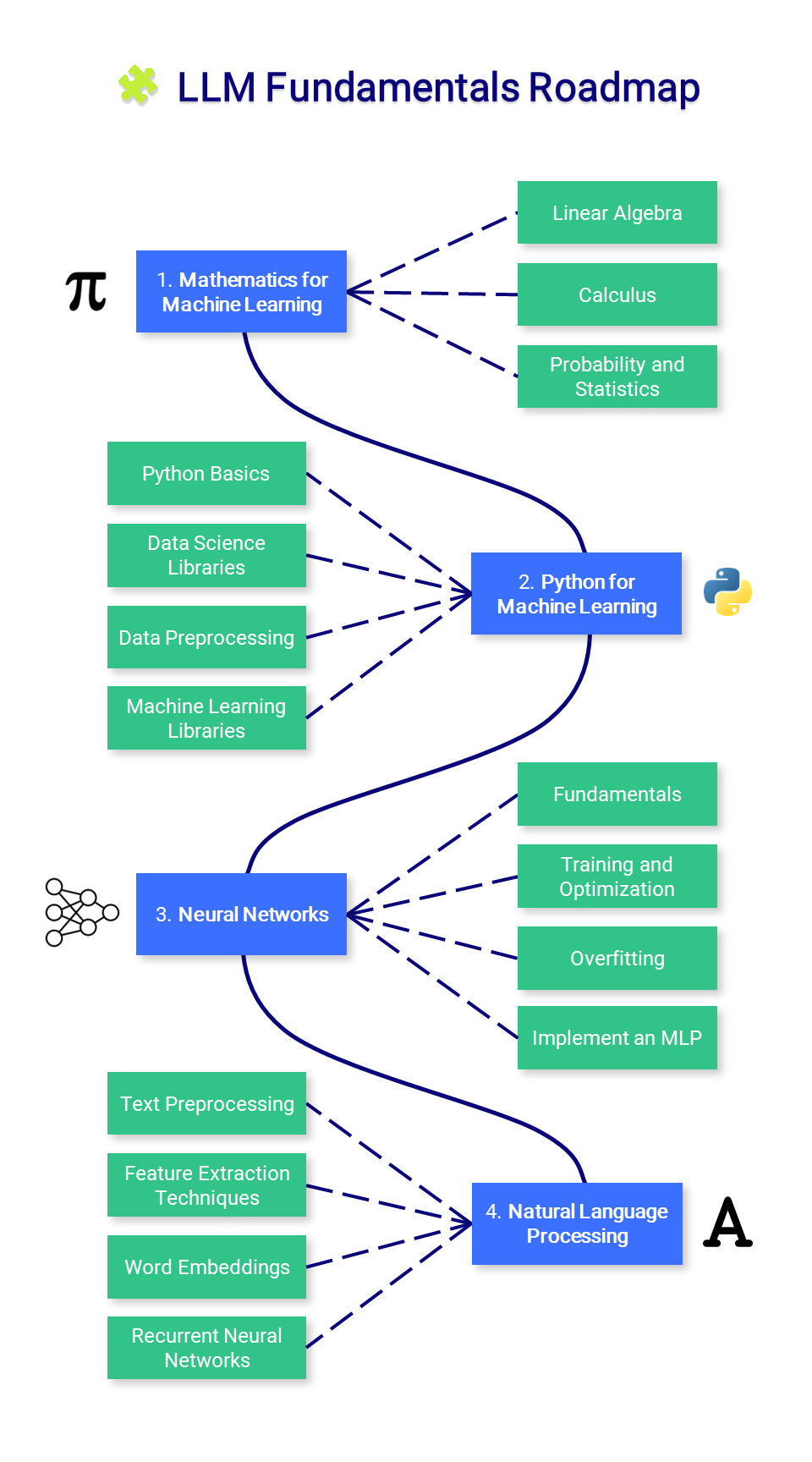
1. الرياضيات للتعلم الآلي
قبل إتقان التعلم الآلي، من المهم فهم المفاهيم الرياضية الأساسية التي تدعم هذه الخوارزميات.
- الجبر الخطي : هذا أمر بالغ الأهمية لفهم العديد من الخوارزميات، وخاصة تلك المستخدمة في التعلم العميق. تشمل المفاهيم الأساسية المتجهات والمصفوفات والمحددات والقيم الذاتية والمتجهات الذاتية والمساحات المتجهة والتحويلات الخطية.
- حساب التفاضل والتكامل : تتضمن العديد من خوارزميات التعلم الآلي تحسين الوظائف المستمرة، الأمر الذي يتطلب فهم المشتقات والتكاملات والحدود والمتسلسلات. حساب التفاضل والتكامل متعدد المتغيرات ومفهوم التدرجات مهمة أيضًا.
- الاحتمالات والإحصائيات : تعتبر هذه العناصر ضرورية لفهم كيفية تعلم النماذج من البيانات وإجراء التنبؤات. تشمل المفاهيم الأساسية نظرية الاحتمالات، والمتغيرات العشوائية، والتوزيعات الاحتمالية، والتوقعات، والتباين، والتباين المشترك، والارتباط، واختبار الفرضيات، وفترات الثقة، وتقدير الاحتمالية القصوى، والاستدلال البايزي.
موارد:
- 3Blue1Brown - جوهر الجبر الخطي: سلسلة من مقاطع الفيديو التي تعطي حدسًا هندسيًا لهذه المفاهيم.
- StatQuest مع جوش ستارمر - أساسيات الإحصاء: يقدم تفسيرات بسيطة وواضحة للعديد من المفاهيم الإحصائية.
- الحدس الإحصائي AP بقلم السيدة إيرين: قائمة بالمقالات المتوسطة التي توفر الحدس وراء كل توزيع احتمالي.
- الجبر الخطي الغامر: تفسير مرئي آخر للجبر الخطي.
- أكاديمية خان - الجبر الخطي: رائعة للمبتدئين لأنها تشرح المفاهيم بطريقة بديهية للغاية.
- أكاديمية خان - حساب التفاضل والتكامل: دورة تفاعلية تغطي جميع أساسيات حساب التفاضل والتكامل.
- أكاديمية خان - الاحتمالات والإحصاء: تقدم المواد بتنسيق سهل الفهم.
2. بايثون للتعلم الآلي
Python هي لغة برمجة قوية ومرنة، وهي مفيدة بشكل خاص للتعلم الآلي، وذلك بفضل سهولة قراءتها واتساقها ونظامها البيئي القوي لمكتبات علوم البيانات.
- أساسيات بايثون : تتطلب برمجة بايثون فهمًا جيدًا لبناء الجملة الأساسي وأنواع البيانات ومعالجة الأخطاء والبرمجة الموجهة للكائنات.
- مكتبات علوم البيانات : تتضمن الإلمام بـ NumPy للعمليات الرقمية، وPandas لمعالجة البيانات وتحليلها، وMatplotlib وSeaborn لتصور البيانات.
- المعالجة المسبقة للبيانات : يتضمن ذلك قياس الميزات وتطبيعها، ومعالجة البيانات المفقودة، والكشف عن البيانات الخارجية، وترميز البيانات الفئوية، وتقسيم البيانات إلى مجموعات تدريب، والتحقق من الصحة، والاختبار.
- مكتبات التعلم الآلي : يعد إتقان استخدام Scikit-learn، وهي مكتبة توفر مجموعة واسعة من خوارزميات التعلم الخاضعة للإشراف وغير الخاضعة للإشراف، أمرًا حيويًا. من المهم فهم كيفية تنفيذ الخوارزميات مثل الانحدار الخطي، والانحدار اللوجستي، وأشجار القرار، والغابات العشوائية، وأقرب جيران (K-NN)، وتجميع وسائل K. تعد تقنيات تقليل الأبعاد مثل PCA وt-SNE مفيدة أيضًا لتصور البيانات عالية الأبعاد.
موارد:
- Real Python: مورد شامل يحتوي على مقالات ودروس تعليمية لكل من مفاهيم Python المبتدئة والمتقدمة.
- freeCodeCamp - تعلم لغة Python: فيديو طويل يقدم مقدمة كاملة لجميع المفاهيم الأساسية في لغة Python.
- دليل علم بيانات بايثون: كتاب رقمي مجاني يعد مصدرًا رائعًا لتعلم الباندا، وNumPy، وMatplotlib، وSeaborn.
- freeCodeCamp - التعلم الآلي للجميع: مقدمة عملية لخوارزميات التعلم الآلي المختلفة للمبتدئين.
- Udacity - مقدمة إلى التعلم الآلي: دورة مجانية تغطي PCA والعديد من مفاهيم التعلم الآلي الأخرى.
3. الشبكات العصبية
تعد الشبكات العصبية جزءًا أساسيًا من العديد من نماذج التعلم الآلي، خاصة في مجال التعلم العميق. للاستفادة منها بفعالية، يعد الفهم الشامل لتصميمها وميكانيكاها أمرًا ضروريًا.
- الأساسيات : يتضمن ذلك فهم بنية الشبكة العصبية مثل الطبقات والأوزان والتحيزات ووظائف التنشيط (السيني، tanh، ReLU، إلخ).
- التدريب والتحسين : تعرف على الانتشار العكسي والأنواع المختلفة من وظائف الخسارة، مثل متوسط الخطأ التربيعي (MSE) والإنتروبيا المتقاطعة. فهم خوارزميات التحسين المختلفة مثل Gradient Descent وStochastic Gradient Descent وRMSprop وAdam.
- التجهيز الزائد : فهم مفهوم التجهيز الزائد (حيث يعمل النموذج بشكل جيد على بيانات التدريب ولكن بشكل سيئ على البيانات غير المرئية) وتعلم تقنيات التنظيم المختلفة (التسرب، تنظيم L1/L2، التوقف المبكر، زيادة البيانات) لمنع ذلك.
- تنفيذ متعدد الطبقات Perceptron (MLP) : قم ببناء MLP، المعروف أيضًا باسم الشبكة المتصلة بالكامل، باستخدام PyTorch.
موارد:
- 3Blue1Brown - ولكن ما هي الشبكة العصبية؟: يقدم هذا الفيديو شرحًا بديهيًا للشبكات العصبية وأعمالها الداخلية.
- freeCodeCamp - دورة مكثفة للتعلم العميق: يقدم هذا الفيديو بكفاءة جميع المفاهيم الأكثر أهمية في التعلم العميق.
- Fast.ai - التعلم العميق العملي: دورة مجانية مصممة للأشخاص ذوي الخبرة في البرمجة والذين يرغبون في التعرف على التعلم العميق.
- Patrick Loeber - دروس PyTorch: سلسلة من مقاطع الفيديو للمبتدئين للتعرف على PyTorch.
4. معالجة اللغات الطبيعية (NLP)
البرمجة اللغوية العصبية (NLP) هي فرع رائع من الذكاء الاصطناعي الذي يسد الفجوة بين اللغة البشرية وفهم الآلة. من معالجة النصوص البسيطة إلى فهم الفروق اللغوية، تلعب البرمجة اللغوية العصبية (NLP) دورًا حاسمًا في العديد من التطبيقات مثل الترجمة وتحليل المشاعر وروبوتات الدردشة وغير ذلك الكثير.
- المعالجة المسبقة للنص : تعلم خطوات مختلفة للمعالجة المسبقة للنص مثل الترميز (تقسيم النص إلى كلمات أو جمل)، والأصل (تقليل الكلمات إلى شكلها الجذري)، والتحويل (على غرار الاستخلاص ولكن مع مراعاة السياق)، وإيقاف إزالة الكلمات، وما إلى ذلك.
- تقنيات استخراج الميزات : تعرف على تقنيات تحويل البيانات النصية إلى تنسيق يمكن فهمه بواسطة خوارزميات التعلم الآلي. تتضمن الأساليب الرئيسية استخدام حقيبة الكلمات (BoW)، وتكرار المصطلح-عكس تردد المستند (TF-IDF)، وn-grams.
- تضمينات الكلمات : تضمينات الكلمات هي نوع من تمثيل الكلمات الذي يسمح للكلمات ذات المعاني المتشابهة بأن يكون لها تمثيلات مماثلة. تتضمن الأساليب الأساسية Word2Vec وGloVe وFastText.
- الشبكات العصبية المتكررة (RNNs) : فهم عمل شبكات RNN، وهي نوع من الشبكات العصبية المصممة للعمل مع البيانات التسلسلية. استكشف LSTMs وGRUs، وهما متغيران من RNN قادران على تعلم التبعيات طويلة المدى.
موارد:
- RealPython - البرمجة اللغوية العصبية مع spaCy في Python: دليل شامل حول مكتبة spaCy لمهام البرمجة اللغوية العصبية في Python.
- Kaggle - دليل البرمجة اللغوية العصبية: عدد قليل من دفاتر الملاحظات والموارد للحصول على شرح عملي للبرمجة اللغوية العصبية في بايثون.
- جاي العمار - الرسم التوضيحي Word2Vec: مرجع جيد لفهم بنية Word2Vec الشهيرة.
- Jake Tae - PyTorch RNN من Scratch: تطبيق عملي وبسيط لنماذج RNN وLSTM وGRU في PyTorch.
- مدونة colah - فهم شبكات LSTM: مقالة نظرية أكثر حول شبكة LSTM.
?? عالم LLM
يركز هذا القسم من الدورة على تعلم كيفية بناء أفضل LLMs الممكنة باستخدام أحدث التقنيات.
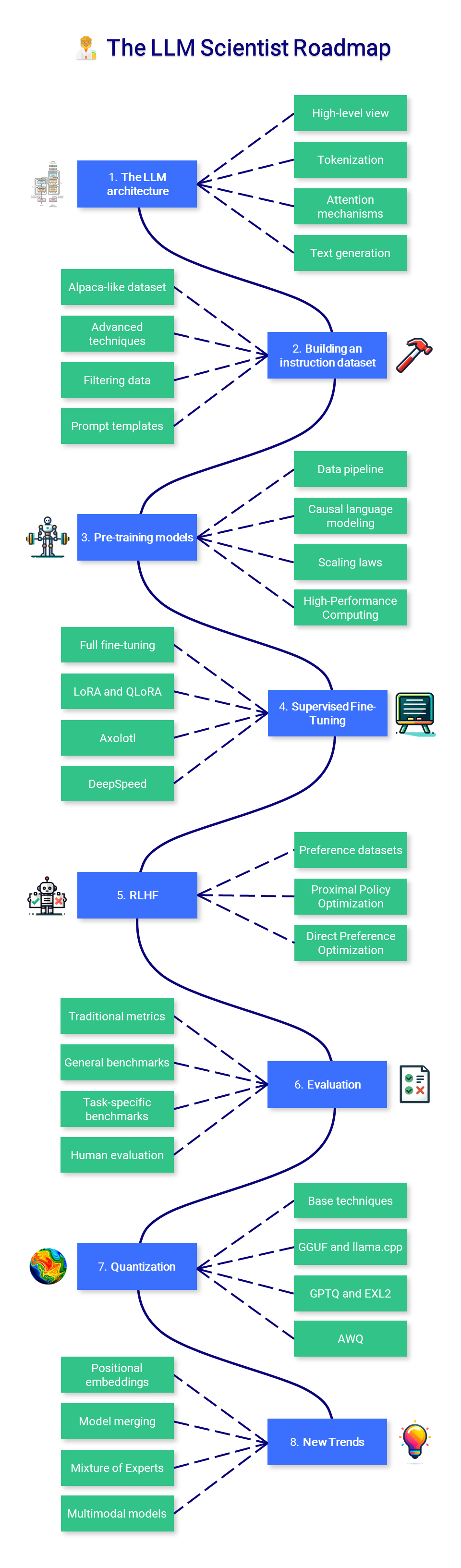
1. هندسة LLM
في حين أن المعرفة المتعمقة حول بنية المحولات ليست مطلوبة، فمن المهم أن يكون لديك فهم جيد لمدخلاتها (الرموز المميزة) ومخرجاتها (السجلات). تعد آلية الانتباه الفانيليا عنصرًا حاسمًا آخر يجب إتقانه، حيث يتم تقديم إصدارات محسنة منها لاحقًا.
- عرض عالي المستوى : قم بإعادة النظر في بنية محول التشفير وفك التشفير، وبشكل أكثر تحديدًا بنية GPT الخاصة بوحدة فك التشفير فقط، والتي يتم استخدامها في كل LLM الحديثة.
- الترميز : فهم كيفية تحويل بيانات النص الخام إلى تنسيق يمكن للنموذج فهمه، والذي يتضمن تقسيم النص إلى رموز مميزة (عادةً كلمات أو كلمات فرعية).
- آليات الانتباه : فهم النظرية الكامنة وراء آليات الانتباه، بما في ذلك الاهتمام الذاتي واهتمام المنتج النقطي المقياس، والذي يسمح للنموذج بالتركيز على أجزاء مختلفة من المدخلات عند إنتاج المخرجات.
- إنشاء النص : تعرف على الطرق المختلفة التي يمكن للنموذج من خلالها إنشاء تسلسلات الإخراج. تشمل الاستراتيجيات الشائعة فك التشفير الجشع، والبحث عن الشعاع، وأخذ العينات من أعلى مستوى، وأخذ العينات النووية.
مراجع :
- المحول المصور بقلم جاي العمار: شرح مرئي وبديهي لنموذج المحول.
- The Illustrated GPT-2 بقلم Jay Alammar: الأهم من المقالة السابقة، أنها تركز على بنية GPT، التي تشبه إلى حد كبير بنية Llama.
- مقدمة مرئية للمحولات من 3Blue1Brown: مقدمة مرئية بسيطة وسهلة الفهم للمحولات
- تصور LLM بواسطة Brendan Bycroft: تصور ثلاثي الأبعاد لا يصدق لما يحدث داخل LLM.
- nanoGPT بواسطة Andrej Karpathy: مقطع فيديو على YouTube مدته ساعتان لإعادة تنفيذ GPT من الصفر (للمبرمجين).
- انتباه؟ انتباه! بقلم ليليان وينج: قدّم الحاجة إلى الاهتمام بطريقة أكثر رسمية.
- استراتيجيات فك التشفير في LLMs: توفير التعليمات البرمجية ومقدمة مرئية لاستراتيجيات فك التشفير المختلفة لإنشاء النص.
2. بناء مجموعة بيانات التعليمات
في حين أنه من السهل العثور على البيانات الأولية من ويكيبيديا ومواقع الويب الأخرى، إلا أنه من الصعب جمع أزواج من التعليمات والإجابات بشكل عام. كما هو الحال في التعلم الآلي التقليدي، ستؤثر جودة مجموعة البيانات بشكل مباشر على جودة النموذج، ولهذا السبب قد تكون العنصر الأكثر أهمية في عملية الضبط الدقيق.
- مجموعة بيانات شبيهة بـ Alpaca : قم بإنشاء بيانات تركيبية من البداية باستخدام OpenAI API (GPT). يمكنك تحديد البذور ومطالبات النظام لإنشاء مجموعة بيانات متنوعة.
- التقنيات المتقدمة : تعرف على كيفية تحسين مجموعات البيانات الحالية باستخدام Evol-Instruct، وكيفية إنشاء بيانات تركيبية عالية الجودة كما هو الحال في أوراق Orca وphi-1.
- تصفية البيانات : التقنيات التقليدية التي تتضمن التعبير العادي، وإزالة التكرارات القريبة، والتركيز على الإجابات التي تحتوي على عدد كبير من الرموز المميزة، وما إلى ذلك.
- القوالب السريعة : لا توجد طريقة قياسية حقيقية لتنسيق التعليمات والإجابات، ولهذا السبب من المهم التعرف على قوالب الدردشة المختلفة، مثل ChatML، وAlpaca، وما إلى ذلك.
مراجع :
- إعداد مجموعة بيانات لضبط التعليمات بواسطة توماس كابيل: استكشاف مجموعات بيانات Alpaca وAlpaca-GPT4 وكيفية تنسيقها.
- إنشاء مجموعة بيانات التعليمات السريرية بواسطة Solano Todeschini: برنامج تعليمي حول كيفية إنشاء مجموعة بيانات تعليمات تركيبية باستخدام GPT-4.
- GPT 3.5 لتصنيف الأخبار بواسطة Kshitiz Sahay: استخدم GPT 3.5 لإنشاء مجموعة بيانات تعليمات لضبط Llama 2 لتصنيف الأخبار.
- إنشاء مجموعة بيانات لضبط LLM: دفتر ملاحظات يحتوي على بعض التقنيات لتصفية مجموعة بيانات وتحميل النتيجة.
- قالب الدردشة بواسطة Matthew Carrigan: صفحة Hugging Face حول القوالب الفورية
3. نماذج ما قبل التدريب
التدريب المسبق هو عملية طويلة ومكلفة للغاية، ولهذا السبب ليس هذا هو محور هذه الدورة. من الجيد أن يكون لديك مستوى معين من الفهم لما يحدث أثناء التدريب المسبق، ولكن الخبرة العملية ليست مطلوبة.
- خط أنابيب البيانات : يتطلب التدريب المسبق مجموعات بيانات ضخمة (على سبيل المثال، تم تدريب Llama 2 على 2 تريليون رمز مميز) والتي تحتاج إلى تصفيتها وتمييزها ومقارنتها بمفردات محددة مسبقًا.
- نمذجة اللغة السببية : تعرف على الفرق بين نمذجة اللغة السببية والمقنعة، بالإضافة إلى دالة الخسارة المستخدمة في هذه الحالة. للحصول على تدريب مسبق فعال، تعرف على المزيد حول Megatron-LM أو gpt-neox.
- قوانين القياس : تصف قوانين القياس أداء النموذج المتوقع استنادًا إلى حجم النموذج وحجم مجموعة البيانات ومقدار الحوسبة المستخدمة للتدريب.
- الحوسبة عالية الأداء : خارج النطاق هنا، ولكن المزيد من المعرفة حول HPC أمر أساسي إذا كنت تخطط لإنشاء ماجستير إدارة الأعمال الخاص بك من البداية (الأجهزة، وعبء العمل الموزع، وما إلى ذلك).
مراجع :
- LLMDataHub بواسطة Junhao Zhao: قائمة منسقة لمجموعات البيانات للتدريب المسبق والضبط الدقيق وRLHF.
- تدريب نموذج اللغة السببية من الصفر عن طريق Hugging Face: التدريب المسبق لنموذج GPT-2 من الصفر باستخدام مكتبة المحولات.
- TinyLlama بواسطة Zhang وآخرون: راجع هذا المشروع للحصول على فهم جيد لكيفية تدريب نموذج اللاما من الصفر.
- نمذجة اللغة السببية عن طريق Hugging Face: اشرح الفرق بين نمذجة اللغة السببية والمقنعة وكيفية ضبط نموذج DistilGPT-2 بسرعة.
- الآثار المترتبة على شينشيلا الجامحة من قبل الحنين إلى الماضي: ناقش قوانين القياس واشرح ما تعنيه بالنسبة إلى LLMs بشكل عام.
- BLOOM من BigScience: صفحة تصورية تصف كيفية بناء نموذج BLOOM، مع الكثير من المعلومات المفيدة حول الجزء الهندسي والمشكلات التي تمت مواجهتها.
- OPT-175 Logbook by Meta: سجلات بحثية توضح الأخطاء التي حدثت والأشياء التي سارت بشكل صحيح. مفيد إذا كنت تخطط للتدريب المسبق لنموذج لغة كبير جدًا (في هذه الحالة، معلمات 175B).
- LLM 360: إطار عمل لـ LLMs مفتوح المصدر مع كود التدريب وإعداد البيانات والبيانات والمقاييس والنماذج.
4. الضبط الدقيق تحت الإشراف
يتم تدريب النماذج المدربة مسبقًا فقط على مهمة التنبؤ بالرمز المميز التالي، ولهذا السبب فهي ليست مساعدين مفيدين. يسمح لك SFT بتعديلها للاستجابة للتعليمات. علاوة على ذلك، فهو يسمح لك بضبط النموذج الخاص بك على أي بيانات (خاصة، لا يراها GPT-4، وما إلى ذلك) واستخدامها دون الحاجة إلى الدفع مقابل واجهة برمجة التطبيقات (API) مثل OpenAI.
- الضبط الدقيق الكامل : يشير الضبط الدقيق الكامل إلى تدريب جميع المعلمات في النموذج. إنها ليست تقنية فعالة، ولكنها تعطي نتائج أفضل قليلاً.
- LoRA : تقنية فعالة للمعلمات (PEFT) تعتمد على محولات منخفضة الرتبة. بدلاً من تدريب جميع المعلمات، نقوم بتدريب هذه المحولات فقط.
- QLoRA : PEFT آخر يعتمد على LoRA، والذي يقوم أيضًا بقياس أوزان النموذج في 4 بتات وتقديم مُحسِّنات مقسمة إلى صفحات لإدارة ارتفاعات الذاكرة. ادمجها مع Unsloth لتشغيلها بكفاءة على كمبيوتر Colab المحمول المجاني.
- Axolotl : أداة ضبط دقيقة سهلة الاستخدام وقوية تُستخدم في الكثير من النماذج الحديثة مفتوحة المصدر.
- DeepSpeed : تدريب مسبق فعال وضبط LLMs لإعدادات وحدات معالجة الرسومات المتعددة والعقد المتعددة (يتم تنفيذها في Axolotl).
مراجع :
- دليل تدريب LLM للمبتدئ من Alpin: نظرة عامة على المفاهيم والمعايير الرئيسية التي يجب مراعاتها عند ضبط LLMs.
- رؤى LoRA بقلم سيباستيان راشكا: رؤى عملية حول LoRA وكيفية اختيار أفضل المعلمات.
- ضبط نموذج Llama 2 الخاص بك: برنامج تعليمي عملي حول كيفية ضبط نموذج Llama 2 باستخدام مكتبات Hugging Face.
- حشو نماذج اللغة الكبيرة بقلم بنجامين ماري: أفضل الممارسات لتضمين أمثلة تدريبية لماجستير القانون السببي
- دليل المبتدئين إلى الضبط الدقيق لـ LLM: برنامج تعليمي حول كيفية ضبط نموذج CodeLlama باستخدام Axolotl.
5. محاذاة التفضيلات
بعد الضبط الدقيق الخاضع للإشراف، يعد RLHF بمثابة خطوة تستخدم لمواءمة إجابات LLM مع التوقعات البشرية. والفكرة هي تعلم التفضيلات من ردود الفعل البشرية (أو المصطنعة)، والتي يمكن استخدامها للحد من التحيزات، أو نماذج الرقابة، أو جعلها تتصرف بطريقة أكثر فائدة. إنه أكثر تعقيدًا من SFT وغالبًا ما يُنظر إليه على أنه اختياري.
- مجموعات البيانات التفضيلية : تحتوي مجموعات البيانات هذه عادةً على عدة إجابات مع نوع من التصنيف، مما يجعل إنتاجها أكثر صعوبة من مجموعات بيانات التعليمات.
- تحسين السياسة القريبة : تستفيد هذه الخوارزمية من نموذج المكافأة الذي يتنبأ بما إذا كان النص المحدد قد تم تصنيفه بدرجة عالية من قبل البشر. يتم بعد ذلك استخدام هذا التنبؤ لتحسين نموذج SFT بعقوبة تعتمد على تباعد KL.
- تحسين التفضيل المباشر : يعمل DPO على تبسيط العملية عن طريق إعادة صياغتها كمشكلة تصنيف. ويستخدم نموذجًا مرجعيًا بدلاً من نموذج المكافأة (لا حاجة إلى تدريب) ولا يتطلب سوى معلمة تشعبية واحدة، مما يجعله أكثر استقرارًا وفعالية.
مراجع :
- Distilabel by Argilla: أداة ممتازة لإنشاء مجموعات البيانات الخاصة بك. لقد تم تصميمه خصيصًا لمجموعات البيانات المفضلة ولكن يمكنه أيضًا إجراء SFT.
- مقدمة لتدريب LLMs باستخدام RLHF بواسطة Ayush Thakur: اشرح سبب كون RLHF مرغوبًا فيه لتقليل التحيز وزيادة الأداء في LLMs.
- رسم توضيحي لـ RLHF بواسطة Hugging Face: مقدمة إلى RLHF مع التدريب على نموذج المكافأة والضبط الدقيق من خلال التعلم المعزز.
- ضبط التفضيلات LLMs عن طريق عناق الوجه: مقارنة خوارزميات DPO وIPO وKTO لإجراء محاذاة التفضيلات.
- تدريب LLM: RLHF وبدائلها بقلم Sebastian Rashcka: نظرة عامة على عملية RLHF والبدائل مثل RLAIF.
- ضبط Mistral-7b باستخدام DPO: برنامج تعليمي لضبط نموذج Mistral-7b باستخدام DPO وإعادة إنتاج NeuralHermes-2.5.
6. التقييم
يعد تقييم LLMs جزءًا مقومًا بأقل من قيمته الحقيقية، وهو أمر يستغرق وقتًا طويلاً ويمكن الاعتماد عليه إلى حد ما. يجب أن تملي مهمتك النهائية ما تريد تقييمه، ولكن تذكر دائمًا قانون جودهارت: "عندما يصبح المقياس هدفًا، فإنه يتوقف عن أن يكون مقياسًا جيدًا".
- المقاييس التقليدية : المقاييس مثل الحيرة ودرجة BLEU ليست شائعة كما كانت لأنها معيبة في معظم السياقات. لا يزال من المهم فهمها ومتى يمكن تطبيقها.
- المعايير العامة : استنادًا إلى أداة تقييم نموذج اللغة، تعد لوحة المتصدرين Open LLM هي المعيار الرئيسي لمجالس LLM للأغراض العامة (مثل ChatGPT). هناك معايير شعبية أخرى مثل BigBench وMT-Bench وما إلى ذلك.
- معايير محددة للمهام : تحتوي المهام مثل التلخيص والترجمة والإجابة على الأسئلة على معايير ومقاييس وحتى نطاقات فرعية مخصصة (طبية ومالية وما إلى ذلك)، مثل PubMedQA للإجابة على الأسئلة الطبية الحيوية.
- التقييم البشري : التقييم الأكثر موثوقية هو معدل القبول من قبل المستخدمين أو المقارنات التي يتم إجراؤها من قبل البشر. يساعد تسجيل تعليقات المستخدمين بالإضافة إلى آثار الدردشة (على سبيل المثال، باستخدام LangSmith) في تحديد المجالات المحتملة للتحسين.
مراجع :
- حيرة النماذج ذات الطول الثابت بواسطة Hugging Face: نظرة عامة على الحيرة مع الكود لتنفيذها مع مكتبة المحولات.
- BLEU على مسؤوليتك الخاصة بقلم راشيل تاتمان: نظرة عامة على نتيجة BLEU ومشكلاتها العديدة مع الأمثلة.
- دراسة استقصائية حول تقييم LLMs بواسطة Chang et al.: ورقة شاملة حول ما يجب تقييمه، ومكان التقييم، وكيفية التقييم.
- Chatbot Arena Leaderboard من lmsys: تصنيف Elo لمجالات LLM ذات الأغراض العامة، استنادًا إلى المقارنات التي أجراها البشر.
7. التكميم
التكميم هو عملية تحويل الأوزان (والتنشيطات) للنموذج باستخدام دقة أقل. على سبيل المثال، يمكن تحويل الأوزان المخزنة باستخدام 16 بت إلى تمثيل 4 بت. أصبحت هذه التقنية ذات أهمية متزايدة لتقليل التكاليف الحسابية والذاكرة المرتبطة ببرامج LLM.
- التقنيات الأساسية : تعلم مستويات الدقة المختلفة (FP32، FP16، INT8، وما إلى ذلك) وكيفية إجراء القياس الكمي الساذج باستخدام تقنيات absmax ونقطة الصفر.
- GGUF وllama.cpp : تم تصميمهما في الأصل للتشغيل على وحدات المعالجة المركزية (CPUs)، وأصبح llama.cpp وتنسيق GGUF من الأدوات الأكثر شيوعًا لتشغيل LLMs على الأجهزة المخصصة للمستهلكين.
- GPTQ وEXL2 : يوفر GPTQ، وبشكل أكثر تحديدًا تنسيق EXL2، سرعة مذهلة ولكن لا يمكن تشغيله إلا على وحدات معالجة الرسومات. تستغرق النماذج أيضًا وقتًا طويلاً حتى يتم قياسها كميًا.
- AWQ : هذا التنسيق الجديد أكثر دقة من GPTQ (أقل حيرة) ولكنه يستخدم الكثير من VRAM وليس بالضرورة أسرع.
مراجع :
- مقدمة إلى التكميم: نظرة عامة على التكميم، وabsmax، وتكميم نقطة الصفر، وLLM.int8() مع التعليمات البرمجية.
- تحديد كمية نماذج Llama باستخدام llama.cpp: برنامج تعليمي حول كيفية تحديد كمية نموذج Llama 2 باستخدام llama.cpp وتنسيق GGUF.
- تكميم LLM 4 بت مع GPTQ: برنامج تعليمي حول كيفية تكميم LLM باستخدام خوارزمية GPTQ مع AutoGPTQ.
- ExLlamaV2: أسرع مكتبة لتشغيل LLMs: دليل حول كيفية تحديد حجم نموذج ميسترال باستخدام تنسيق EXL2 وتشغيله باستخدام مكتبة ExLlamaV2.
- فهم تكميم الوزن المدرك للتنشيط بواسطة FriendliAI: نظرة عامة على تقنية AWQ وفوائدها.
8. الاتجاهات الجديدة
- التضمين الموضعي : تعرف على كيفية تشفير LLM للمواضع، وخاصة أنظمة التشفير الموضعي النسبي مثل RoPE. قم بتنفيذ YaRN (ضرب مصفوفة الانتباه بعامل درجة الحرارة) أو ALiBi (عقوبة الانتباه بناءً على مسافة الرمز المميز) لتمديد طول السياق.
- دمج النماذج : أصبح دمج النماذج المدربة طريقة شائعة لإنشاء نماذج عالية الأداء دون أي ضبط دقيق. تطبق مكتبة mergekit الشهيرة طرق الدمج الأكثر شيوعًا، مثل SLERP وDARE وTIES.
- مزيج من الخبراء : قامت شركة Mixtral بإعادة تعميم بنية وزارة التربية والتعليم بفضل أدائها الممتاز. بالتوازي، ظهر نوع من FrankenMoE في مجتمع OSS من خلال دمج نماذج مثل Phixtral، وهو خيار أرخص وأكثر أداءً.
- نماذج متعددة الوسائط : تقوم هذه النماذج (مثل CLIP أو Stable Diffusion أو LLaVA) بمعالجة أنواع متعددة من المدخلات (النص والصور والصوت وما إلى ذلك) بمساحة تضمين موحدة، والتي تفتح التطبيقات القوية مثل تحويل النص إلى صورة.
مراجع :
- توسيع الحبل بواسطة EleutherAI: مقال يلخص تقنيات ترميز الموضع المختلفة.
- فهم الغزل بقلم راجات تشاولا: مقدمة إلى الغزل.
- دمج LLMs مع mergekit: برنامج تعليمي حول دمج النماذج باستخدام mergekit.
- مزيج من الخبراء يشرحون عن طريق العناق: دليل شامل حول وزارات التربية والتعليم وكيفية عملها.
- نماذج كبيرة متعددة الوسائط بقلم تشيب هوين: نظرة عامة على أنظمة الوسائط المتعددة والتاريخ الحديث لهذا المجال.
؟ مهندس LLM
يركز هذا القسم من الدورة على تعلم كيفية بناء التطبيقات التي تدعم LLM والتي يمكن استخدامها في الإنتاج، مع التركيز على زيادة النماذج ونشرها.
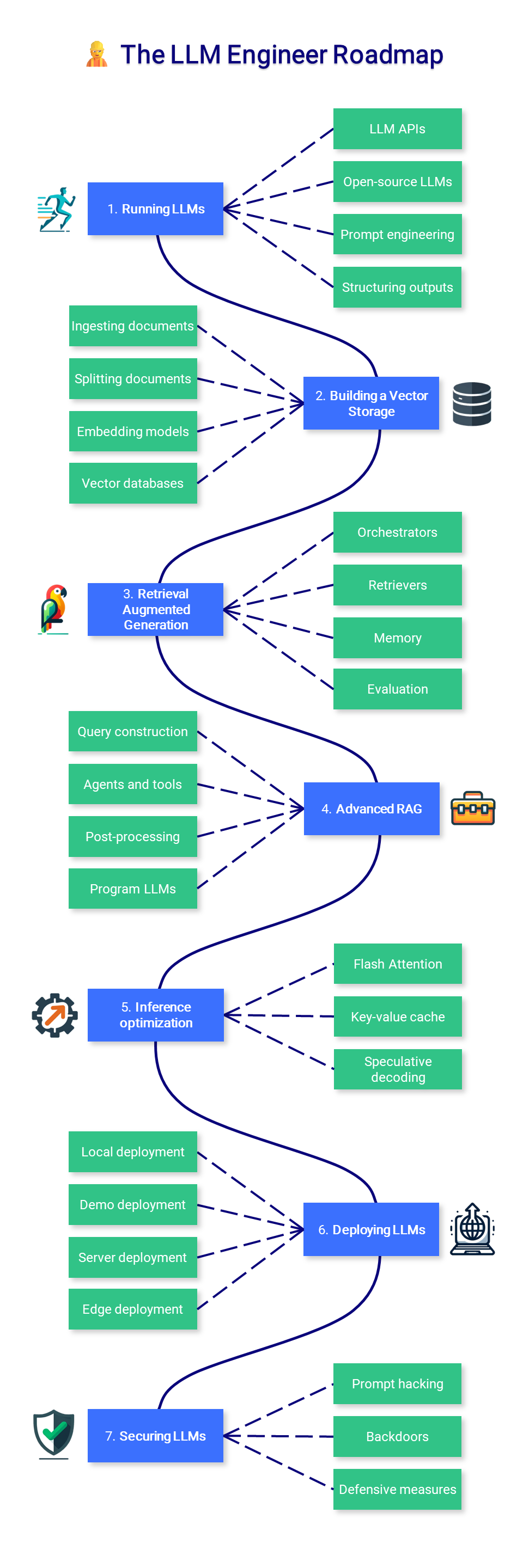
1. تشغيل LLMs
قد يكون تشغيل LLMs أمرًا صعبًا نظرًا لمتطلبات الأجهزة العالية. اعتمادًا على حالة الاستخدام الخاصة بك، قد ترغب ببساطة في استهلاك نموذج من خلال واجهة برمجة التطبيقات (مثل GPT-4) أو تشغيله محليًا. على أية حال، يمكن لتقنيات التحفيز والتوجيه الإضافية تحسين وتقييد مخرجات تطبيقاتك.
- واجهات برمجة تطبيقات LLM : تعد واجهات برمجة التطبيقات طريقة ملائمة لنشر LLMs. تنقسم هذه المساحة بين دورات LLM خاصة (OpenAI، Google، Anthropic، Cohere، وما إلى ذلك) وLLMs مفتوحة المصدر (OpenRouter، Hugging Face، Together AI، وما إلى ذلك).
- LLMs مفتوحة المصدر : يعد Hugging Face Hub مكانًا رائعًا للعثور على LLMs. يمكنك تشغيل بعضها مباشرة في Hugging Face Spaces، أو تنزيلها وتشغيلها محليًا في تطبيقات مثل LM Studio أو من خلال CLI باستخدام llama.cpp أو Ollama.
- الهندسة السريعة : تشمل التقنيات الشائعة المطالبة بدون طلقة، والدفع بعدد قليل من الطلقات، وسلسلة الأفكار، وReAct. إنها تعمل بشكل أفضل مع النماذج الأكبر حجمًا، ولكن يمكن تكييفها مع النماذج الأصغر حجمًا.
- هيكلة المخرجات : تتطلب العديد من المهام مخرجات منظمة، مثل قالب صارم أو تنسيق JSON. يمكن استخدام مكتبات مثل LMQL، والمخططات التفصيلية، والإرشاد، وما إلى ذلك لتوجيه الجيل واحترام بنية معينة.
مراجع :
- قم بتشغيل LLM محليًا باستخدام LM Studio بقلم Nisha Arya: دليل مختصر حول كيفية استخدام LM Studio.
- دليل هندسي سريع من DAIR.AI: قائمة شاملة للتقنيات السريعة مع أمثلة
- الخطوط العريضة - البدء السريع: قائمة بتقنيات الإنشاء الموجهة التي تم تمكينها بواسطة الخطوط العريضة.
- LMQL - نظرة عامة: مقدمة إلى لغة LMQL.
2. بناء مخزن المتجهات
يعد إنشاء مخزن متجه هو الخطوة الأولى لإنشاء خط أنابيب إنشاء الاسترجاع المعزز (RAG). يتم تحميل المستندات وتقسيمها واستخدام الأجزاء ذات الصلة لإنتاج تمثيلات متجهة (تضمينات) يتم تخزينها للاستخدام المستقبلي أثناء الاستدلال.
- استيعاب المستندات : أدوات تحميل المستندات عبارة عن أغلفة ملائمة يمكنها التعامل مع العديد من التنسيقات: PDF وJSON وHTML وMarkdown وما إلى ذلك. ويمكنها أيضًا استرداد البيانات مباشرة من بعض قواعد البيانات وواجهات برمجة التطبيقات (GitHub وReddit وGoogle Drive وما إلى ذلك).
- تقسيم المستندات : تقوم أدوات تقسيم النص بتقسيم المستندات إلى أجزاء أصغر ذات معنى دلالي. بدلاً من تقسيم النص بعد عدد n من الأحرف، من الأفضل غالبًا التقسيم حسب الرأس أو بشكل متكرر، مع بعض البيانات الوصفية الإضافية.
- نماذج التضمين : تعمل نماذج التضمين على تحويل النص إلى تمثيلات متجهة. فهو يسمح بفهم أعمق وأكثر دقة للغة، وهو أمر ضروري لإجراء البحث الدلالي.
- قواعد بيانات المتجهات : تم تصميم قواعد بيانات المتجهات (مثل Chroma وPinecone وMilvus وFAISS وAnnoy وما إلى ذلك) لتخزين ناقلات التضمين. إنها تتيح الاسترداد الفعال للبيانات "الأكثر تشابهًا" مع الاستعلام بناءً على تشابه المتجهات.
مراجع :
- LangChain - مقسمات النص: قائمة بمقسمات النص المختلفة المطبقة في LangChain.
- مكتبة محولات الجملة: مكتبة شعبية لتضمين النماذج.
- MTEB Leaderboard: لوحة المتصدرين لتضمين النماذج.
- أفضل 5 قواعد بيانات متجهة بقلم معز علي: مقارنة بين أفضل قواعد بيانات المتجهات وأكثرها شيوعًا.
3. استرجاع الجيل المعزز
باستخدام RAG، يسترد LLM المستندات السياقية من قاعدة بيانات لتحسين دقة إجاباتهم. RAG هي طريقة شائعة لزيادة معرفة النموذج دون أي ضبط دقيق.
- المنسقون : المنسقون (مثل LangChain، وLlamaIndex، وFastRAG، وما إلى ذلك) هم أطر عمل شائعة لربط طلاب LLM بالأدوات وقواعد البيانات والذكريات وما إلى ذلك وزيادة قدراتهم.
- المستردون : لم يتم تحسين تعليمات المستخدم للاسترجاع. يمكن تطبيق تقنيات مختلفة (على سبيل المثال، المسترد متعدد الاستعلامات، HyDE، وما إلى ذلك) لإعادة صياغتها/توسيعها وتحسين الأداء.
- الذاكرة : لتذكر التعليمات والإجابات السابقة، تضيف برامج LLM وبرامج الدردشة مثل ChatGPT هذا السجل إلى نافذة السياق الخاصة بها. يمكن تحسين هذا المخزن المؤقت من خلال التلخيص (على سبيل المثال، باستخدام LLM أصغر)، ومخزن المتجهات + RAG، وما إلى ذلك.
- التقييم : نحن بحاجة إلى تقييم كل من استرجاع الوثيقة (دقة السياق والتذكير) ومراحل الإنشاء (الإخلاص وملاءمة الإجابة). ويمكن تبسيطه باستخدام أدوات Ragas وDeepEval.
مراجع :
- Llamindex - مفاهيم عالية المستوى: المفاهيم الرئيسية التي يجب معرفتها عند بناء خطوط أنابيب RAG.
- كوز الصنوبر - زيادة الاسترجاع: نظرة عامة على عملية زيادة الاسترجاع.
- LangChain - أسئلة وأجوبة مع RAG: برنامج تعليمي خطوة بخطوة لإنشاء خط أنابيب RAG نموذجي.
- LangChain - أنواع الذاكرة: قائمة بأنواع مختلفة من الذكريات مع الاستخدام المناسب.
- خط أنابيب RAG - المقاييس: نظرة عامة على المقاييس الرئيسية المستخدمة لتقييم خطوط أنابيب RAG.
4. RAG المتقدم
يمكن أن تتطلب التطبيقات الواقعية خطوط أنابيب معقدة، بما في ذلك قواعد بيانات SQL أو الرسم البياني، بالإضافة إلى التحديد التلقائي للأدوات وواجهات برمجة التطبيقات ذات الصلة. يمكن لهذه التقنيات المتقدمة تحسين الحل الأساسي وتوفير ميزات إضافية.
- بناء الاستعلام : تتطلب البيانات المنظمة المخزنة في قواعد البيانات التقليدية لغة استعلام محددة مثل SQL وCypher والبيانات الوصفية وما إلى ذلك. يمكننا ترجمة تعليمات المستخدم مباشرة إلى استعلام للوصول إلى البيانات من خلال بناء الاستعلام.
- الوكلاء والأدوات : يقوم الوكلاء بتعزيز LLMs عن طريق تحديد الأدوات الأكثر صلة تلقائيًا لتقديم إجابة. يمكن أن تكون هذه الأدوات بسيطة مثل استخدام Google أو Wikipedia، أو أكثر تعقيدًا مثل مترجم Python أو Jira.
- مرحلة ما بعد المعالجة : الخطوة النهائية التي تعالج المدخلات التي يتم تغذيتها إلى LLM. إنه يعزز أهمية وتنوع الوثائق التي تم استردادها من خلال إعادة التصنيف، ودمج RAG، والتصنيف.
- LLMs الخاصة بالبرنامج : تسمح لك أطر العمل مثل DSPy بتحسين المطالبات والأوزان بناءً على التقييمات الآلية بطريقة برمجية.
مراجع :
- LangChain - إنشاء الاستعلام: منشور مدونة حول الأنواع المختلفة لبناء الاستعلام.
- LangChain - SQL: برنامج تعليمي حول كيفية التفاعل مع قواعد بيانات SQL مع LLMs، بما في ذلك تحويل النص إلى SQL ووكيل SQL اختياري.
- Pinecone - وكلاء LLM: مقدمة للوكلاء والأدوات بأنواع مختلفة.
- الوكلاء المستقلون المدعومون من LLM بقلم Lilian Weng: المزيد من المقالات النظرية حول وكلاء LLM.
- LangChain - RAG لـ OpenAI: نظرة عامة على استراتيجيات RAG التي تستخدمها OpenAI، بما في ذلك المعالجة اللاحقة.
- DSPy في 8 خطوات: دليل للأغراض العامة لـ DSPy يقدم الوحدات والتوقيعات والمحسنات.
5. الاستدلال الأمثل
يعد إنشاء النص عملية مكلفة وتتطلب أجهزة باهظة الثمن. بالإضافة إلى التكميم، تم اقتراح تقنيات مختلفة لزيادة الإنتاجية وتقليل تكاليف الاستدلال.
- انتباه فلاش : تحسين آلية الانتباه لتحويل تعقيدها من الدرجة التربيعية إلى الخطية، وتسريع كل من التدريب والاستدلال.
- ذاكرة التخزين المؤقت لقيمة المفتاح : فهم ذاكرة التخزين المؤقت لقيمة المفتاح والتحسينات المقدمة في تنبيه الاستعلامات المتعددة (MQA) وانتباه الاستعلامات المجمعة (GQA).
- فك التشفير التأملي : استخدم نموذجًا صغيرًا لإنتاج مسودات تتم مراجعتها بعد ذلك بواسطة نموذج أكبر لتسريع عملية إنشاء النص.
مراجع :
- استدلال وحدة معالجة الرسومات عن طريق معانقة الوجه: اشرح كيفية تحسين الاستدلال على وحدات معالجة الرسومات.
- استدلال LLM بواسطة Databricks: أفضل الممارسات لكيفية تحسين استدلال LLM في الإنتاج.
- تحسين LLMs للسرعة والذاكرة عن طريق احتضان الوجه: شرح ثلاث تقنيات رئيسية لتحسين السرعة والذاكرة، وهي تحديد الكميات، وFlash Attention، والابتكارات المعمارية.
- التوليد المدعوم عن طريق عناق الوجه: إصدار HF لفك التشفير التخميني، وهو منشور مدونة مثير للاهتمام حول كيفية عمله مع التعليمات البرمجية لتنفيذه.
6. نشر LLMs
يعد نشر LLMs على نطاق واسع بمثابة إنجاز هندسي يمكن أن يتطلب مجموعات متعددة من وحدات معالجة الرسومات. وفي سيناريوهات أخرى، يمكن تحقيق العروض التوضيحية والتطبيقات المحلية بتعقيد أقل بكثير.
- النشر المحلي : تعد الخصوصية ميزة مهمة تتمتع بها برامج LLM مفتوحة المصدر مقارنة ببرامج LLM الخاصة. تستفيد خوادم LLM المحلية (LM Studio، وOllama، وoobabooga، وkobold.cpp، وما إلى ذلك) من هذه الميزة لتشغيل التطبيقات المحلية.
- النشر التجريبي : تساعد أطر العمل مثل Gradio وStreamlit في إنشاء نماذج أولية للتطبيقات ومشاركة العروض التوضيحية. يمكنك أيضًا استضافتها بسهولة عبر الإنترنت ، على سبيل المثال باستخدام مساحات الوجه المعانقة.
- نشر الخادم : يتطلب نشر LLMs على نطاق السحابة (انظر أيضًا Skypilot) أو البنية التحتية المحلية وغالبًا ما يستفيد من أطراف توليد النص المحسنة مثل TGI ، VLLM ، إلخ.
- نشر الحافة : في البيئات المقيدة ، يمكن للأطر عالية الأداء مثل MLC LLM و MNN-LLM نشر LLM في متصفحات الويب ، Android ، و IOS.
مراجع :
- STREMLIT - قم بإنشاء تطبيق LLM أساسي: البرنامج التعليمي لإنشاء تطبيق أساسي يشبه ChatGPT باستخدام SPEREMLIT.
- حاوية الاستدلال HF LLM: نشر LLMS على Amazon Sagemaker باستخدام حاوية الاستنتاج الخاصة بـ Hugging Face.
- مدونة Philschmid by Philipp Schmid: مجموعة من المقالات عالية الجودة حول نشر LLM باستخدام Amazon Sagemaker.
- تحسين Latence بواسطة Hamel Husain: مقارنة بين TGI و VLLM و CTRANSLATE2 و MLC من حيث الإنتاجية والكمون.
7. تأمين LLMS
بالإضافة إلى مشاكل الأمن التقليدية المرتبطة بالبرمجيات ، فإن LLMs لديها نقاط ضعف فريدة بسبب الطريقة التي يتم بها تدريبها وطرحها.
- القرصنة المطالبة : تقنيات مختلفة تتعلق بالهندسة المطالبة ، بما في ذلك الحقن السريع (تعليمات إضافية لاختطاف إجابة النموذج) ، وتسرب البيانات/المطالبة (استرجاع بياناته/موجه الأصلي) ، وكسر الحماية (المطالبات الحرفية لتجاوز ميزات الأمان).
- Backdoors : يمكن لمتجهات الهجوم أن تستهدف بيانات التدريب نفسها ، من خلال تسمم بيانات التدريب (على سبيل المثال ، بمعلومات خاطئة) أو إنشاء أجهزة خلفية (تُعزى السرية لتغيير سلوك النموذج أثناء الاستدلال).
- التدابير الدفاعية : أفضل طريقة لحماية تطبيقات LLM الخاصة بك هي اختبارها ضد نقاط الضعف هذه (على سبيل المثال ، باستخدام الفريق الأحمر والفحوصات مثل Garak) ومراقبتها في الإنتاج (مع إطار مثل Langfuse).
مراجع :
- OWASP LLM Top 10 by Hego Wiki: قائمة من أكثر 10 نقاط الضعف التي شوهدت في تطبيقات LLM.
- التمهيدي السريع للحقن بواسطة جوزيف ثاكر: دليل قصير مخصص للحقن المطري للمهندسين.
- LLM Security byLM_SEC: قائمة واسعة من الموارد المتعلقة بأمان LLM.
- Red Teaming LLMS بواسطة Microsoft: دليل حول كيفية أداء فريق Red Teaming مع LLMS.
شكر وتقدير
استلهمت خارطة الطريق هذه من خريطة طريق ديفوبس الممتازة من ميلانو ميلانوفيتش ورومانو روث.
شكر خاص ل:
- توماس ثلين لتحفيزني على إنشاء خريطة طريق
- أندريه فرايد لمدخلاته ومراجعته للمسودة الأولى
- Dino Dunn لتوفير الموارد حول أمان LLM
- Magdalena Kuhn لتحسين جزء "التقييم البشري"
- Odoverdose لاقتراح فيديو 3Blue1brown حول المحولات
إخلاء المسئولية: أنا لست تابعًا لأي مصادر مدرجة هنا.


