يحتوي هذا المستودع على كود PyTorch الخاص بـ Motif، والذي يقوم بتدريب عملاء الذكاء الاصطناعي على NetHack بوظائف المكافأة المستمدة من تفضيلات LLM.
الحافز: الدافع الجوهري من ردود فعل الذكاء الاصطناعي
بقلم مارتن كليساروف* وبييرلوكا دورو* وشاغون سوداني وروبرتا رايليانو وبيير لوك بيكون وباسكال فنسنت وإيمي تشانغ وميكائيل هيناف
تثير الفكرة تفضيلات نموذج اللغة الكبير (LLM) على أزواج من الملاحظات الموضحة من مجموعة بيانات من التفاعلات التي تم جمعها على NetHack. تلقائيًا، يقوم بتحويل الحس السليم لـ LLM إلى وظيفة مكافأة يتم استخدامها لتدريب العملاء من خلال التعلم المعزز.
لتسهيل المقارنات، نقدم منحنيات تدريبية في ملف المخلل motif_results.pkl ، الذي يحتوي على قاموس يحتوي على المهام كمفاتيح. لكل مهمة، نقدم قائمة بالخطوات الزمنية ومتوسط العائدات للحافز وخطوط الأساس للبذور المتعددة.
كما هو موضح في الشكل التالي، يتميز Motif بثلاث مراحل:
نقوم بتفصيل كل مرحلة من المراحل من خلال توفير مجموعات البيانات والأوامر والنتائج الأولية اللازمة لإعادة إنتاج التجارب في الورقة.
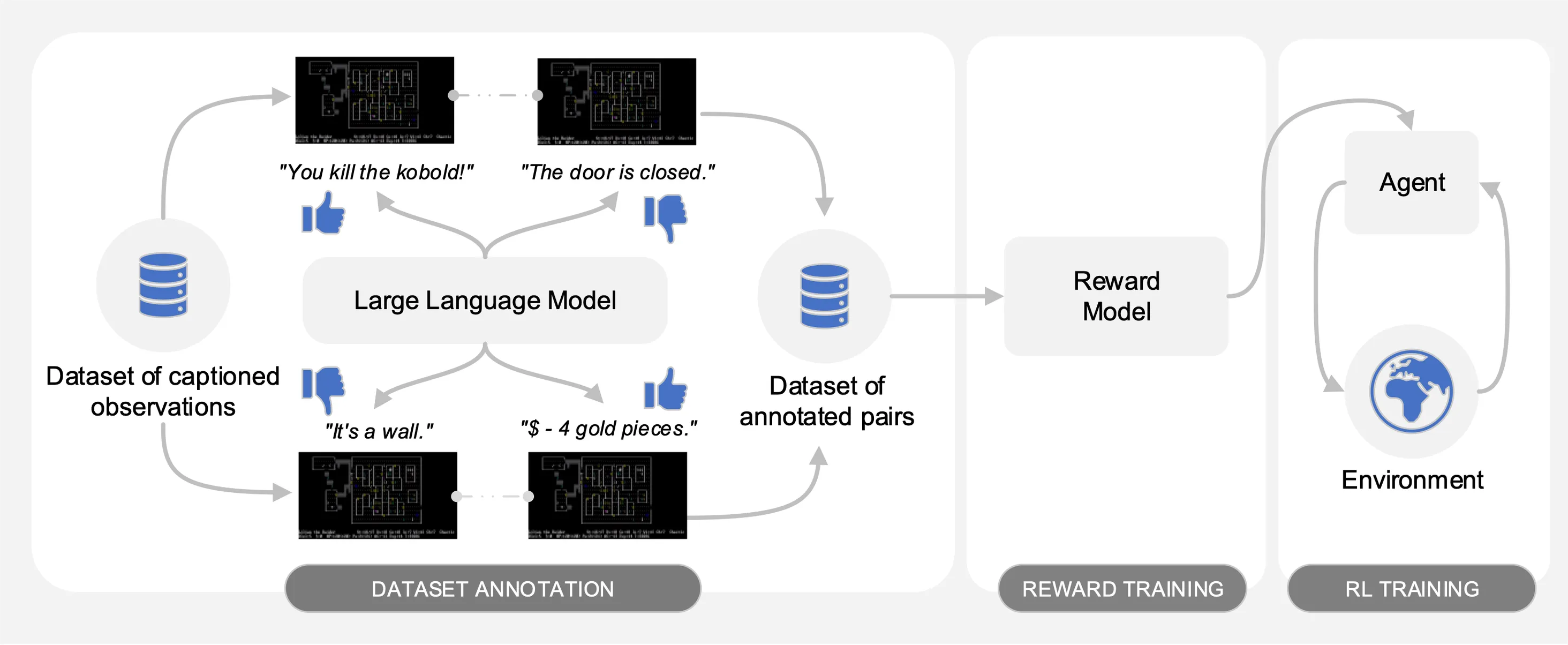
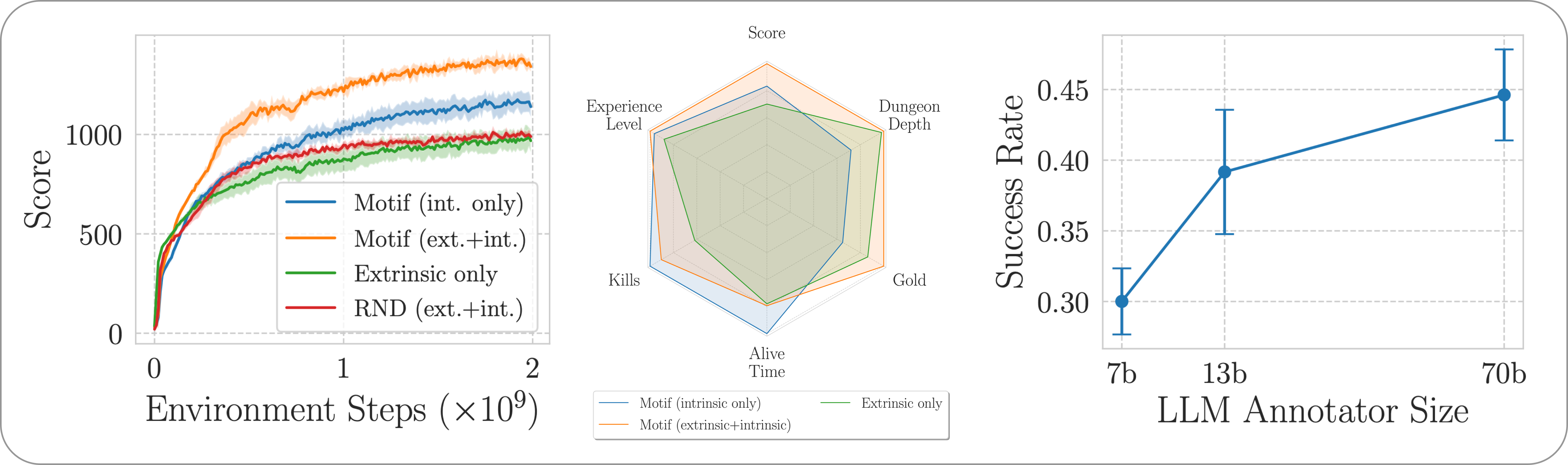
نقوم بتقييم أداء Motif في لعبة NetHack الصعبة والمفتوحة والمولدة إجرائيًا من خلال بيئة التعلم NetHack. نحن نتحقق من كيفية قيام Motif في الغالب بتوليد سلوكيات بديهية متوافقة مع الإنسان، والتي يمكن توجيهها بسهولة من خلال التعديلات السريعة، بالإضافة إلى خصائص القياس الخاصة بها.

لتثبيت التبعيات المطلوبة لخط الأنابيب بالكامل، ما عليك سوى تشغيل pip install -r requirements.txt .
بالنسبة للمرحلة الأولى، نستخدم مجموعة بيانات مكونة من أزواج من الملاحظات مع تسميات توضيحية (على سبيل المثال، رسائل من اللعبة) تم جمعها بواسطة عملاء مدربين على التعلم المعزز لتحقيق أقصى قدر من نقاط اللعبة. نحن نقدم مجموعة البيانات في هذا المستودع. نقوم بتخزين الأجزاء المختلفة في الدليل motif_dataset_zipped ، والذي يمكن فك ضغطه باستخدام الأمر التالي.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
تتميز مجموعة البيانات التي نقدمها بمجموعة من التفضيلات المقدمة من نماذج Llama 2، والمضمنة في preference/ الدليل، باستخدام المطالبات المختلفة الموضحة في الورقة. تتبع أسماء ملفات .npy التي تحتوي على التعليقات التوضيحية القالب llama{size}b_msg_{instruction}_{version} ، حيث size هو حجم LLM من المجموعة {7,13,70} ، instruction هي تعليمات مقدمة إلى المطالبة الممنوحة لـ LLM من المجموعة {defaultgoal, zeroknowledge, combat, gold, stairs} ، version هو إصدار قالب المطالبة الذي سيتم استخدامه من المجموعة {default, reworded} . نقدم هنا ملخصًا للتعليقات التوضيحية المتاحة:
| تعليق توضيحي | حالة الاستخدام من الورق |
|---|---|
llama70b_msg_defaultgoal_default | التجارب الرئيسية |
llama70b_msg_combat_default | التوجيه نحو سلوك Monster Slayer |
llama70b_msg_gold_default | التوجيه نحو سلوك جامع الذهب |
llama70b_msg_stairs_default | التوجيه نحو سلوك السليل |
llama7b_msg_defaultgoal_default | تجربة التحجيم |
llama13b_msg_defaultgoal_default | تجربة التحجيم |
llama70b_msg_zeroknowledge_default | تجربة سريعة للمعرفة الصفرية |
llama70b_msg_defaultgoal_reworded | تجربة إعادة صياغة سريعة |
لإنشاء التعليقات التوضيحية، نستخدم vLLM وإصدار الدردشة من Llama 2. إذا كنت تريد إنشاء التعليقات التوضيحية الخاصة بك باستخدام Llama 2 أو إعادة إنتاج عملية التعليقات التوضيحية الخاصة بنا، فتأكد من قدرتك على تنزيل النموذج باتباع الإرشادات الرسمية (يمكن ذلك يستغرق بضعة أيام للوصول إلى أوزان النموذج).
يفترض البرنامج النصي للتعليق التوضيحي أن مجموعة البيانات سيتم شرحها في أجزاء مختلفة باستخدام وسيطة n-annotation-chunks . وهذا يسمح بعملية يمكن موازنتها اعتمادًا على توفر الموارد، كما أنها قوية لإعادة التشغيل/الاستباقية. للتشغيل باستخدام قطعة واحدة (أي لمعالجة مجموعة البيانات بأكملها)، وإضافة تعليقات توضيحية باستخدام قالب المطالبة الافتراضي ومواصفات المهمة، قم بتشغيل الأمر التالي.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
لاحظ أن السلوك الافتراضي يستأنف عملية التعليق التوضيحي عن طريق إلحاق التعليقات التوضيحية بالملف الذي يحدد التكوين، ما لم تتم الإشارة إلى خلاف ذلك باستخدام العلامة --ignore-existing . يمكن أيضًا تحديد اسم الملف ".npy" الذي تم إنشاؤه للتعليقات التوضيحية يدويًا باستخدام علامة --custom-annotator-string . من الممكن التعليق باستخدام --llm-size 7 و --llm-size 13 باستخدام وحدة معالجة رسومات واحدة بذاكرة تبلغ 32 جيجابايت. يمكنك التعليق باستخدام --llm-size 70 مع عقدة مكونة من 8 وحدات معالجة رسومية. نقدم هنا تقديرات تقريبية لأوقات التعليقات التوضيحية باستخدام وحدات معالجة الرسومات NVIDIA V100s 32G، لمجموعة بيانات مكونة من 100 ألف زوج، والتي يجب أن تكون قادرة على إعادة إنتاج معظم نتائجنا تقريبًا (والتي تم الحصول عليها باستخدام 500 ألف زوج).
| نموذج | الموارد للتعليق |
|---|---|
| اللاما 2 7 ب | ~ 32 ساعة GPU |
| اللاما 2 13 ب | ~ 40 ساعة GPU |
| اللاما 2 70 ب | ~ 72 ساعة GPU |
في المرحلة الثانية، نقوم بتقطير تفضيلات LLM إلى وظيفة المكافأة من خلال الإنتروبيا المتقاطعة. لبدء تدريب المكافأة باستخدام المعلمات الفائقة الافتراضية، استخدم الأمر التالي.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
سيتم تدريب وظيفة المكافأة من خلال التعليقات التوضيحية annotator الموجود في --dataset_dir . سيتم بعد ذلك حفظ الوظيفة الناتجة في train_dir ضمن المجلد الفرعي --experiment .
وأخيرًا، نقوم بتدريب العميل على وظائف المكافأة الناتجة من خلال التعلم المعزز. لتدريب وكيل على مهمة NetHackScore-v1 ، باستخدام المعلمات الفائقة الافتراضية المستخدمة للتجارب التي تجمع بين المكافآت الجوهرية والخارجية، يمكنك استخدام الأمر التالي.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
لتغيير المهمة، ما عليك سوى تعديل الوسيطة --root_env . يوضح الجدول التالي القيم المطلوبة بوضوح لمطابقة التجارب المقدمة في الورقة. يتم التعرف على مهمة NetHackScore-v1 بقيمة extrinsic_reward لتكون 0.1 ، بينما تأخذ جميع المهام الأخرى قيمة 10.0 ، من أجل تحفيز الوكيل للوصول إلى الهدف.
| بيئة | root_env |
|---|---|
| نتيجة | NetHackScore-v1 |
| الدرج | NetHackStaircase-v1 |
| الدرج (المستوى 3) | NetHackStaircaseLvl3-v1 |
| الدرج (المستوى 4) | NetHackStaircaseLvl4-v1 |
| أوراكل | NetHackOracle-v1 |
| أوراكل الرصين | NetHackOracleSober-v1 |
بالإضافة إلى ذلك، إذا كنت ترغب في تدريب الوكلاء باستخدام المكافأة الجوهرية القادمة من LLM فقط ولكن بدون مكافأة من البيئة، فما عليك سوى تعيين --extrinsic_reward 0.0 . في تجارب المكافأة الجوهرية فقط، نقوم بإنهاء الحلقة فقط في حالة وفاة العميل، وليس عندما يصل العميل إلى الهدف. يتم تعداد هذه البيئات المعدلة في الجدول التالي.
| بيئة | root_env |
|---|---|
| الدرج (المستوى 3) - جوهري فقط | NetHackStaircaseLvl3Continual-v1 |
| الدرج (المستوى 4) - جوهري فقط | NetHackStaircaseLvl4Continual-v1 |
بالإضافة إلى ذلك، نقدم لك برنامجًا نصيًا لتصور وكلاء RL المدربين لديك. يمكن أن يوفر هذا رؤى مهمة حول سلوكها، ولكنه سيؤدي أيضًا إلى إنشاء أهم الرسائل لكل حلقة، مما يمكن أن يساعد في فهم ما تحاول تحسينه. تحتاج ببساطة إلى تشغيل الأمر التالي.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
إذا قمت بالبناء على عملنا أو وجدته مفيدًا، فيرجى الاستشهاد به باستخدام bibtex التالي.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
غالبية Motif مرخصة بموجب CC-BY-NC، ولكن أجزاء من المشروع متاحة بموجب شروط ترخيص منفصلة: Sample-factory مرخص بموجب ترخيص MIT.


