
قم بتوحيد البيانات في دورة حياة التعلم الآلي بالكامل باستخدام Space ، وهو حل تخزين شامل يتعامل مع البيانات بسلاسة بدءًا من الاستيعاب وحتى التدريب.
الميزات الرئيسية:
space.core.schema.types.files ).space.TfFeatures هو نوع حقل مضمن يوفر مُسلسلات للإملاءات المتداخلة للصفائف numpy، استنادًا إلى TFDS FeaturesDict.ثَبَّتَ:
pip install space-datasetsأو التثبيت من الكود:
cd python
pip install .[dev]راجع مستند الإعداد والأداء.
أنشئ مجموعة بيانات مساحة تحتوي على حقلي فهرس ( id و image_name ) (مخزن في Parquet) وحقل سجل ( feature ) (مخزن في ArrayRecord).
يستخدم هذا المثال النوع binary العادي لحقل السجل. يدعم Space نوع space.TfFeatures الذي يتكامل مع برنامج تسلسل ميزات TFDS. شاهد المزيد من التفاصيل في مثال TFDS.
import pyarrow as pa
from space import Dataset
schema = pa . schema ([
( "id" , pa . int64 ()),
( "image_name" , pa . string ()),
( "feature" , pa . binary ())])
ds = Dataset . create (
"/path/to/<mybucket>/example_ds" ,
schema ,
primary_keys = [ "id" ],
record_fields = [ "feature" ]) # Store this field in ArrayRecord files
# Load the dataset from files later:
ds = Dataset . load ( "/path/to/<mybucket>/example_ds" ) اختياريًا، يمكنك استخدام catalogs لإدارة مجموعات البيانات حسب الأسماء بدلاً من المواقع:
from space import DirCatalog
# DirCatalog manages datasets in a directory.
catalog = DirCatalog ( "/path/to/<mybucket>" )
# Same as the creation above.
ds = catalog . create_dataset ( "example_ds" , schema ,
primary_keys = [ "id" ], record_fields = [ "feature" ])
# Same as the load above.
ds = catalog . dataset ( "example_ds" )
# List all datasets and materialized views.
print ( catalog . datasets ())إلحاق، حذف بعض البيانات. تولد كل طفرة نسخة جديدة من البيانات، ممثلة بمعرف عدد صحيح متزايد. يمكن للمستخدمين إضافة علامات إلى معرفات الإصدار كاسم مستعار.
import pyarrow . compute as pc
from space import RayOptions
# Create a local runner:
runner = ds . local ()
# Or create a Ray runner:
runner = ds . ray ( ray_options = RayOptions ( max_parallelism = 8 ))
# To avoid https://github.com/ray-project/ray/issues/41333, wrap the runner
# with @ray.remote when running in a remote Ray cluster.
#
# @ray.remote
# def run():
# return runner.read_all()
#
# Appending data generates a new dataset version `snapshot_id=1`
# Write methods:
# - append(...): no primary key check.
# - insert(...): fail if primary key exists.
# - upsert(...): overwrite if primary key exists.
ids = range ( 100 )
runner . append ({
"id" : ids ,
"image_name" : [ f" { i } .jpg" for i in ids ],
"feature" : [ f"somedata { i } " . encode ( "utf-8" ) for i in ids ]
})
ds . add_tag ( "after_append" ) # Version management: add tag to snapshot
# Deletion generates a new version `snapshot_id=2`
runner . delete ( pc . field ( "id" ) == 1 )
ds . add_tag ( "after_delete" )
# Show all versions
ds . versions (). to_pandas ()
# >>>
# snapshot_id create_time tag_or_branch
# 0 2 2024-01-12 20:23:57+00:00 after_delete
# 1 1 2024-01-12 20:23:38+00:00 after_append
# 2 0 2024-01-12 20:22:51+00:00 None
# Read options:
# - filter_: optional, apply a filter (push down to reader).
# - fields: optional, field selection.
# - version: optional, snapshot_id or tag, time travel back to an old version.
# - batch_size: optional, output size.
runner . read_all (
filter_ = pc . field ( "image_name" ) == "2.jpg" ,
fields = [ "feature" ],
version = "after_add" # or snapshot ID `1`
)
# Read the changes between version 0 and 2.
for change in runner . diff ( 0 , "after_delete" ):
print ( change . change_type )
print ( change . data )
print ( "===============" )إنشاء فرع جديد وإجراء التغييرات في الفرع الجديد:
# The default branch is "main"
ds . add_branch ( "dev" )
ds . set_current_branch ( "dev" )
# Make changes in the new branch, the main branch is not updated.
# Switch back to the main branch.
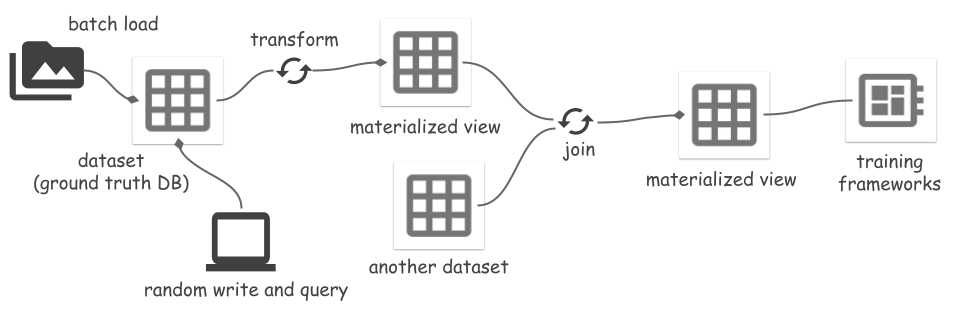
ds . set_current_branch ( "main" )يدعم Space تحويل مجموعة البيانات إلى طريقة عرض، وتجسيد العرض في الملفات. التحولات تشمل:
عندما يتم تعديل مجموعة البيانات المصدر، يؤدي تحديث العرض الفعلي إلى مزامنة التغييرات بشكل متزايد، مما يوفر تكلفة الحوسبة والإدخال والإخراج. اطلع على مزيد من التفاصيل في مثال لقسم أي شيء. يجب أن تكون طرق العرض القراءة أو التحديث هي مشغل Ray ، لأنه يتم تنفيذها بناءً على تحويل Ray.
يمكن استخدام العرض المادي mv كعرض mv.view أو مجموعة بيانات mv.dataset . يقرأ الأول دائمًا البيانات من ملفات مجموعة البيانات المصدر ويعالج جميع البيانات بسرعة. يقوم الأخير بقراءة البيانات المعالجة مباشرة من ملفات MV، ويتخطى معالجة البيانات.
# A sample transform UDF.
# Input is {"field_name": [values, ...], ...}
def modify_feature_udf ( batch ):
batch [ "feature" ] = [ d + b"123" for d in batch [ "feature" ]]
return batch
# Create a view and materialize it.
view = ds . map_batches (
fn = modify_feature_udf ,
output_schema = ds . schema ,
output_record_fields = [ "feature" ]
)
view_runner = view . ray ()
# Reading a view will read the source dataset and apply transforms on it.
# It processes all data using `modify_feature_udf` on the fly.
for d in view_runner . read ():
print ( d )
mv = view . materialize ( "/path/to/<mybucket>/example_mv" )
# Or use a catalog:
# mv = catalog.materialize("example_mv", view)
mv_runner = mv . ray ()
# Refresh the MV up to version tag `after_add` of the source.
mv_runner . refresh ( "after_add" , batch_size = 64 ) # Reading batch size
# Or, mv_runner.refresh() refresh to the latest version
# Use the MV runner instead of view runner to directly read from materialized
# view files, no data processing any more.
mv_runner . read_all ()راجع المثال الكامل في مثال Segment Anything. إنشاء عرض حقيقي لنتيجة الانضمام غير مدعوم حتى الآن.
# If input is a materialized view, using `mv.dataset` instead of `mv.view`
# Only support 1 join key, it must be primary key of both left and right.
joined_view = mv_left . dataset . join ( mv_right . dataset , keys = [ "id" ])هناك عدة طرق لدمج مساحة التخزين مع أطر تعلم الآلة. يوفر Space مصدر بيانات وصول عشوائي لقراءة البيانات في ملفات ArrayRecord:
from space import RandomAccessDataSource
datasource = RandomAccessDataSource (
# <field-name>: <storage-location>, for reading data from ArrayRecord files.
{
"feature" : "/path/to/<mybucket>/example_mv" ,
},
# Don't auto deserialize data, because we store them as plain bytes.
deserialize = False )
len ( datasource )
datasource [ 2 ]يمكن أيضًا قراءة مجموعة البيانات أو العرض كمجموعة بيانات Ray:
ray_ds = ds . ray_dataset ()
ray_ds . take ( 2 )يمكن قراءة البيانات الموجودة في ملفات Parquet كمجموعة بيانات HuggingFace:
from datasets import load_dataset
huggingface_ds = load_dataset ( "parquet" , data_files = { "train" : ds . index_files ()})قائمة مسار الملف لجميع ملفات الفهرس (الباركيه):
ds . index_files ()
# Or show more statistics information of Parquet files.
ds . storage . index_manifest () # Accept filter and snapshot_idعرض المعلومات الإحصائية لجميع ملفات ArrayRecord:
ds . storage . record_manifest () # Accept filter and snapshot_id الفضاء هو مشروع جديد قيد التطوير النشط.
؟ المهام المستمرة:
هذا ليس أحد منتجات Google المدعومة رسميًا.


