

MPIRE ، اختصار لـ MultiProcessing Is Real Easy، هي حزمة بايثون للمعالجة المتعددة. يعد MPIRE أسرع في معظم السيناريوهات، ويحتوي على المزيد من الميزات، وهو بشكل عام أكثر سهولة في الاستخدام من حزمة المعالجة المتعددة الافتراضية. فهي تجمع بين الخريطة الملائمة مثل وظائف multiprocessing.Pool تجمع مع فوائد استخدام الكائنات المشتركة للنسخ عند الكتابة multiprocessing.Process . العملية، جنبًا إلى جنب مع حالة العامل سهلة الاستخدام، ورؤى العامل، ووظائف بدء وخروج العامل، والمهلات، و وظيفة شريط التقدم.
الوثائق الكاملة متاحة على https://sybrenjansen.github.io/mpire/.
map / map_unordered / imap / imap_unordered / apply / apply_asyncfork طريقة البدء)rich والمحمولة)daemonتم اختبار MPIRE على أنظمة التشغيل Linux وmacOS وWindows. بالنسبة لمستخدمي Windows وmacOS، هناك بعض التحذيرات البسيطة المعروفة، والتي تم توثيقها في فصل استكشاف الأخطاء وإصلاحها.
من خلال النقطة (PyPi):
pip install mpireMPIRE متاح أيضًا من خلال conda-forge:
conda install -c conda-forge mpire لنفترض أن لديك دالة تستغرق وقتًا طويلاً وتتلقى بعض المدخلات وترجع نتائجها. تُعرف الوظائف البسيطة مثل هذه بالمشكلات المتوازية المحرجة، وهي وظائف تتطلب القليل من الجهد أو لا تتطلب أي جهد لتتحول إلى مهمة متوازية. إن موازنة وظيفة بسيطة حيث يمكن أن يكون ذلك سهلاً مثل استيراد multiprocessing واستخدام المعالجة multiprocessing.Pool Pool:
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) يمكن استخدام MPIRE كبديل مباشر للمعالجة multiprocessing . نستخدم فئة mpire.WorkerPool ونستدعي إحدى وظائف map المتاحة:
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) الاختلافات في التعليمات البرمجية صغيرة: ليست هناك حاجة لتعلم بناء جملة معالجة متعددة جديد تمامًا، إذا كنت معتادًا على multiprocessing الفانيليا. ومع ذلك، فإن الوظيفة الإضافية المتاحة هي ما يميز MPIRE.
لنفترض أننا نريد معرفة حالة المهمة الحالية: كم عدد المهام المكتملة، وكم من الوقت قبل أن يصبح العمل جاهزًا؟ الأمر بسيط مثل تعيين معلمة progress_bar على True :
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )وسيتم إخراج شريط تقدم tqdm منسق بشكل جيد.
تقدم MPIRE أيضًا لوحة معلومات تحتاج إلى تثبيت تبعيات إضافية لها. راجع لوحة المعلومات لمزيد من المعلومات.
ملاحظة: الكائنات المشتركة للنسخ عند الكتابة متاحة فقط لطريقة البدء fork . بالنسبة threading تتم مشاركة الكائنات كما هي. بالنسبة لطرق البدء الأخرى، يتم نسخ الكائنات المشتركة مرة واحدة لكل عامل، وهو ما قد يظل أفضل من مرة واحدة لكل مهمة.
إذا كان لديك كائن واحد أو أكثر تريد مشاركته بين جميع العاملين، فيمكنك الاستفادة من خيار shared_objects للنسخ عند الكتابة في MPIRE. سوف يقوم MPIRE بتمرير هذه الكائنات مرة واحدة فقط لكل عامل دون نسخ/تسلسل. فقط عندما تقوم بتغيير الكائن في وظيفة العامل، سيبدأ نسخه لهذا العامل.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )راجع Shared_objects لمزيد من التفاصيل.
يمكن تهيئة العمال باستخدام ميزة worker_init . يمكنك، جنبًا إلى جنب مع worker_state تحميل نموذج، أو إعداد اتصال بقاعدة البيانات، وما إلى ذلك:
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) وبالمثل، يمكنك استخدام ميزة worker_exit للسماح لـ MPIRE باستدعاء وظيفة عندما ينتهي العامل. يمكنك أيضًا السماح لوظيفة الخروج هذه بإرجاع النتائج، والتي يمكن الحصول عليها لاحقًا. راجع قسمworker_init وworker_exit لمزيد من المعلومات.
عندما لا يعمل إعداد المعالجة المتعددة لديك بالشكل الذي تريده وليس لديك أدنى فكرة عن سبب ذلك، فهناك وظيفة رؤى العامل. سيعطيك هذا نظرة ثاقبة على الإعداد الخاص بك، لكنه لن يقوم بتعريف الوظيفة التي تقوم بتشغيلها (توجد مكتبات أخرى لذلك). وبدلاً من ذلك، يقوم بتوصيف وقت بدء تشغيل العامل ووقت الانتظار ووقت العمل. عندما يتم توفير وظائف بدء التشغيل والخروج للعامل، فسيتم تحديد وقتها أيضًا.
ربما تقوم بإرسال الكثير من البيانات عبر قائمة انتظار المهام، مما يؤدي إلى زيادة وقت الانتظار. مهما كانت الحالة، يمكنك تمكين الرؤى والحصول عليها باستخدام علامة enable_insights ووظيفة mpire.WorkerPool.get_insights ، على التوالي:
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()راجع رؤى العمال للحصول على مثال أكثر تفصيلاً والمخرجات المتوقعة.
يمكن تعيين المهلات بشكل منفصل لوظائف الهدف، worker_init و worker_exit . عندما يتم تعيين المهلة والوصول إليها، فإنه سيتم رمي TimeoutError :
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) عند استخدام threading كأسلوب بدء، لن يتمكن MPIRE من مقاطعة وظائف معينة، مثل time.sleep .
راجع المهلات لمزيد من التفاصيل.
تم قياس MPIRE على ثلاثة معايير مختلفة: الحساب العددي، والحساب ذو الحالة، والتهيئة الباهظة الثمن. يمكن العثور على مزيد من التفاصيل حول هذه المعايير في منشور المدونة هذا. يمكن العثور على كافة التعليمات البرمجية لهذه المعايير في هذا المشروع.
باختصار، الأسباب الرئيسية التي تجعل MPIRE أسرع هي:
fork ، يمكننا الاستفادة من الكائنات المشتركة للنسخ عند الكتابة، مما يقلل الحاجة إلى نسخ الكائنات التي تحتاج إلى المشاركة عبر العمليات الفرعيةيوضح الرسم البياني التالي متوسط النتائج المعيارية لجميع المعايير الثلاثة. يمكن العثور على نتائج المعايير الفردية في منشور المدونة. تم تشغيل المعايير على جهاز Linux مزود بـ 20 مركزًا، مع تعطيل تقنية Hyperthreading وذاكرة وصول عشوائي (RAM) سعة 200 جيجابايت. لكل مهمة، تم إجراء تجارب بأعداد مختلفة من العمليات/العاملين وتم حساب متوسط النتائج على مدى 5 عمليات تشغيل.
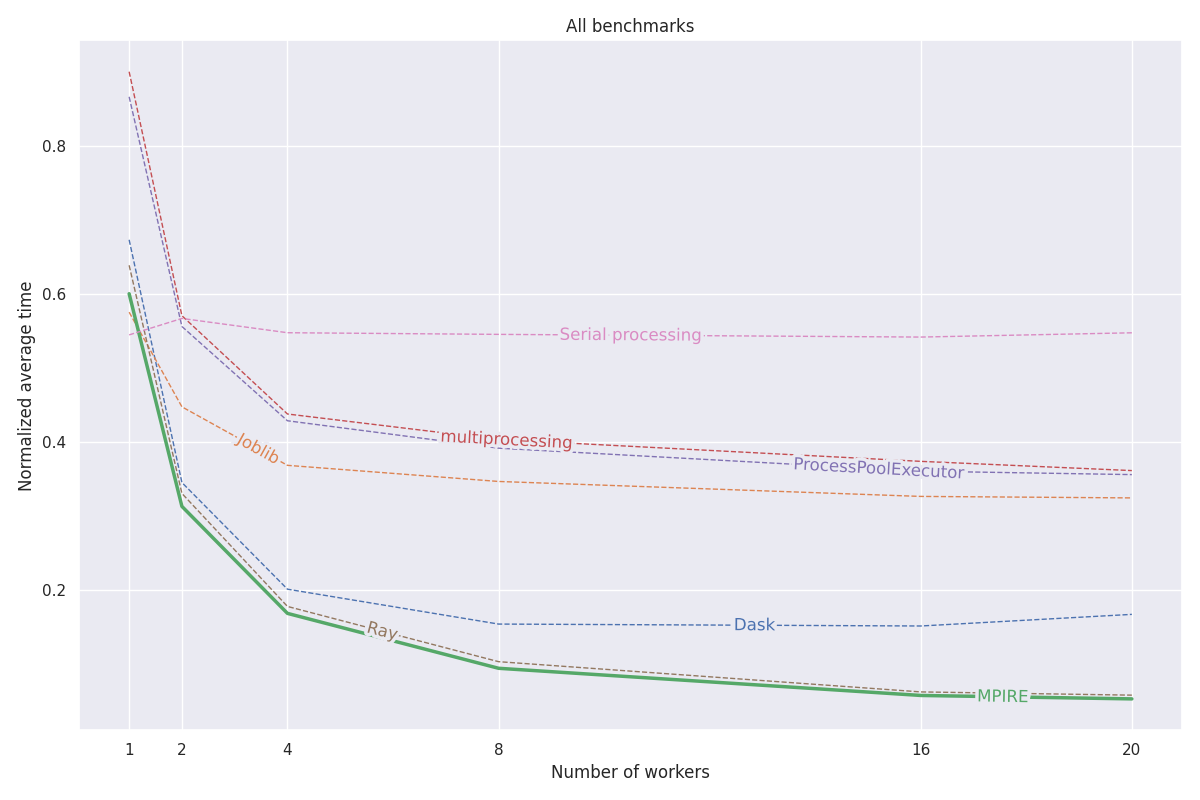
راجع الوثائق الكاملة على https://sybrenjansen.github.io/mpire/ للحصول على معلومات حول جميع الميزات الأخرى لـ MPIRE.
إذا كنت ترغب في إنشاء الوثائق بنفسك، يرجى تثبيت تبعيات الوثائق عن طريق تنفيذ:
pip install mpire[docs]أو
pip install .[docs]يمكن بعد ذلك إنشاء التوثيق باستخدام Python <= 3.9 وتنفيذ:
python setup.py build_docs يمكن أيضًا إنشاء الوثائق من مجلد docs مباشرةً. في هذه الحالة، يجب تثبيت MPIRE وإتاحته في بيئة العمل الحالية لديك. ثم نفذ:
make html في مجلد docs .


