clearml agent
v1.9.2

وكيل ClearML - أصبح MLOps/LLMOps سهلاً
حل جدولة وتنسيق MLOps/LLMOps الذي يدعم Linux وmacOS وWindows
? ClearML is open-source - Leave a star to support the project! ?
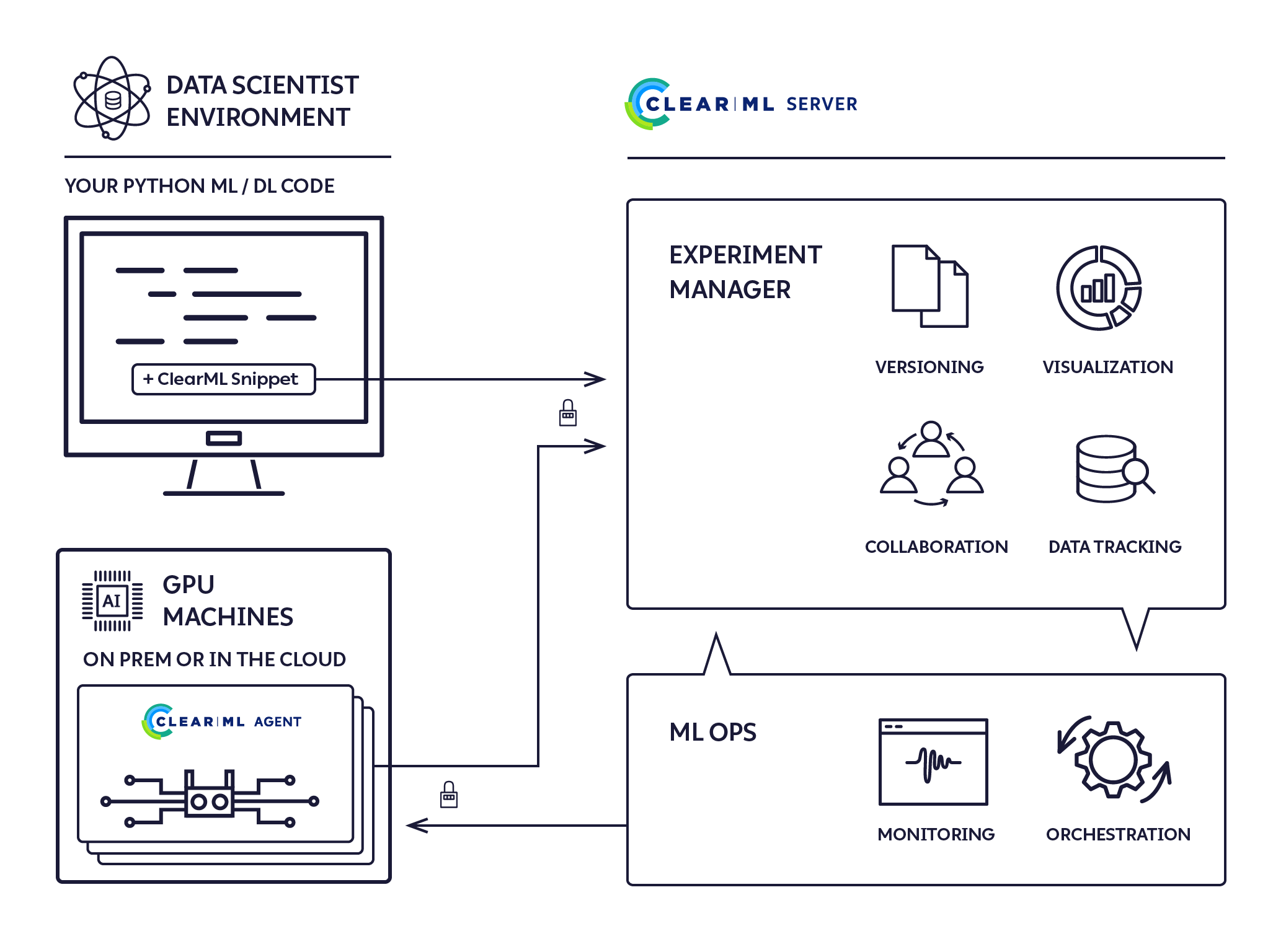
إنه وكيل تنفيذ صفري التكوين، يوفر حلاً كاملاً لمجموعة ML/DL.
أتمتة كاملة في 5 خطوات
pip install clearml-agent (قم بتثبيت ClearML Agent على أي جهاز GPU: محلي / سحابي / ...)"كل ما تحتاج إليه أبحاثك من عمليات تطوير التعلم العميق/التعلم الآلي، ثم بعضها... لأنه لا يوجد أحد لديه الوقت لذلك"
جرب ClearML الآن استضافة ذاتية أو استضافة مجانية 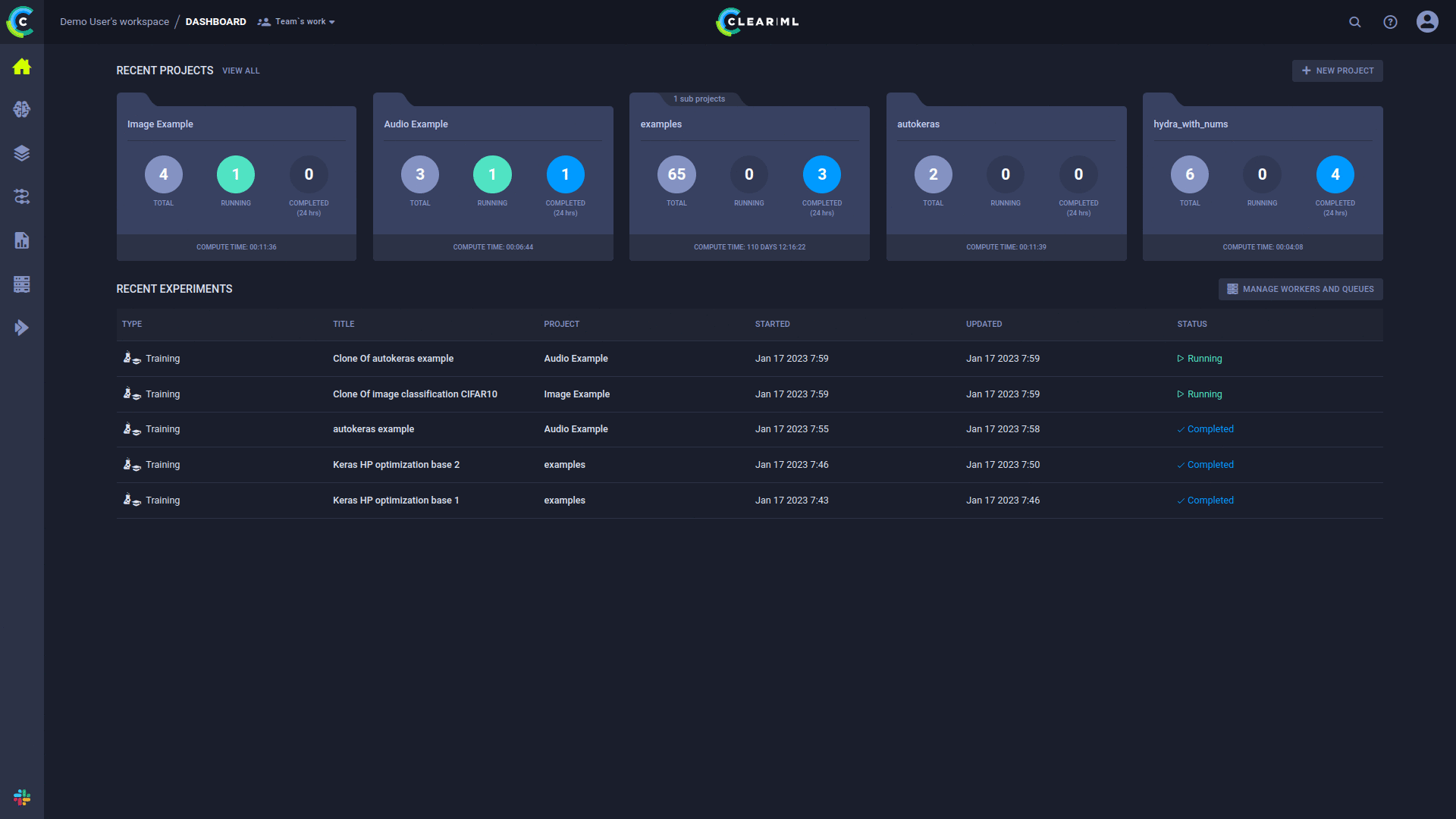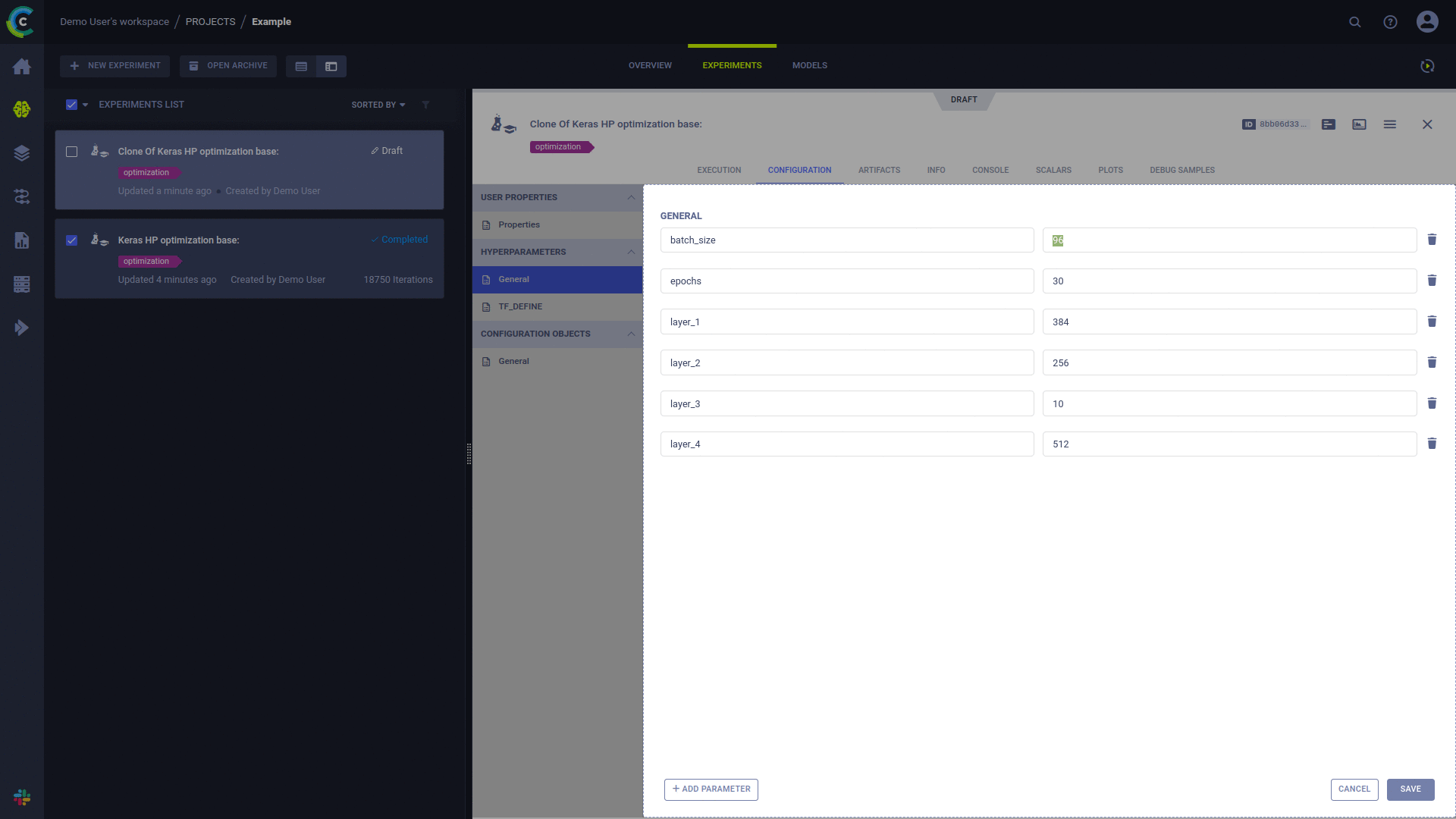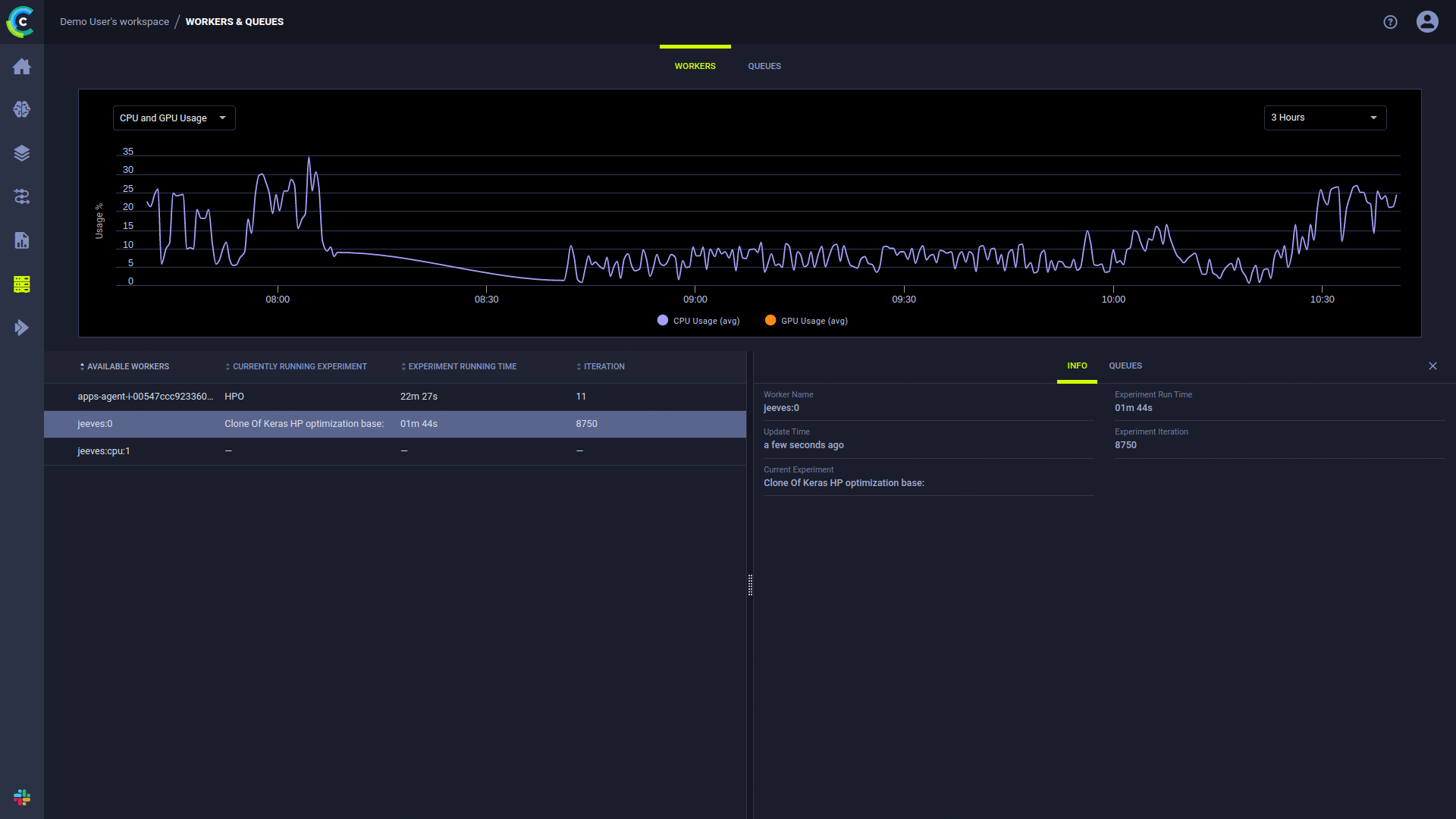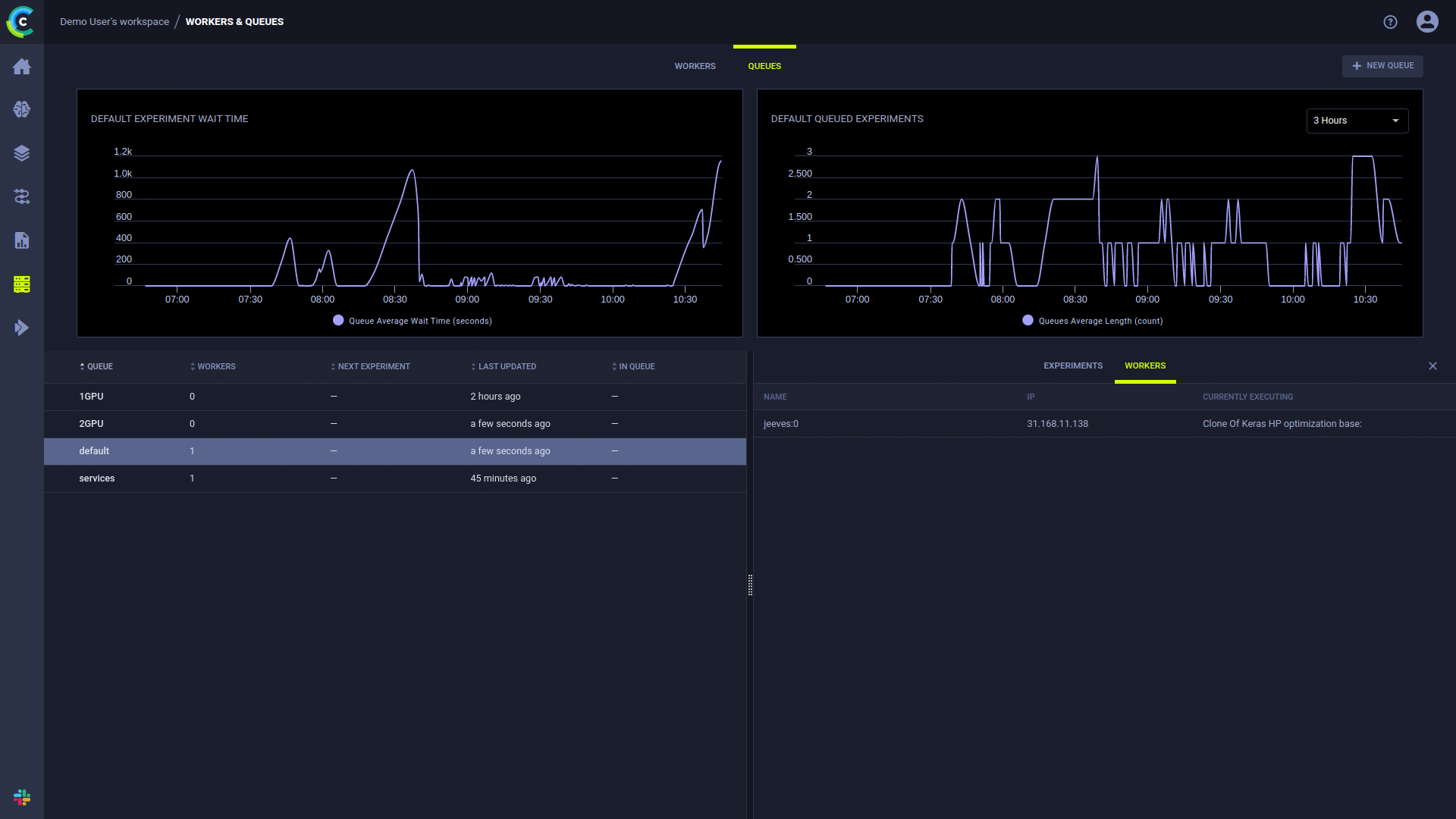
تم تصميم ClearML Agent لتلبية احتياجات DL/ML R&D DevOps:
باستخدام ClearML Agent، يمكنك الآن إعداد مجموعة ديناميكية باستخدام *epsilon DevOps
* إبسيلون - لأننا؟ وليس هناك ما هو في الواقع عمل صفر
نعتقد أن Kubernetes رائع، ولكن ليس من الضروري البدء باستخدام وكلاء التنفيذ عن بعد وإدارة المجموعة. لقد قمنا بتصميم clearml-agent حتى تتمكن من تشغيل كل من النظام المعدني وفوق Kubernetes، في أي مجموعة تناسب بيئتك.
يمكنك العثور على ملفات Dockerfiles في مجلد عامل الإرساء ومخطط الدفة في https://github.com/allegroai/clearml-helm-charts
قم بتشغيل الوكيل في وضع Kubernetes Glue، وقم بتعيين وظائف ClearML مباشرة إلى وظائف K8s:
نعم! تكامل Slurm متاح، راجع الوثائق لمزيد من التفاصيل
HPC واسع النطاق بنقرة زر واحدة
يعد ClearML Agent بمثابة برنامج جدولة المهام الذي يستمع إلى قائمة (قوائم) المهام، ويسحب الوظائف، ويضبط بيئات الوظائف، وينفذ المهمة ويراقب تقدمها.
يمكن جدولة أي تجربة "مسودة" للتنفيذ بواسطة وكيل ClearML.
يمكن وضع تجربة تم إجراؤها مسبقًا في حالة "مسودة" بإحدى الطريقتين التاليتين:
تمت جدولة تجربة للتنفيذ باستخدام الإجراء "Enqueue" من قائمة سياق النقر بزر الماوس الأيمن فوق التجربة في واجهة مستخدم ClearML وتحديد قائمة انتظار التنفيذ.
راجع إنشاء تجربة ووضعها في قائمة الانتظار للتنفيذ.
بمجرد وضع التجربة في قائمة الانتظار، سيتم التقاطها وتنفيذها بواسطة وكيل ClearML الذي يراقب قائمة الانتظار هذه.
توفر صفحة ClearML UI Workers & Queues معلومات التنفيذ المستمر:
يقوم ClearML Agent بتنفيذ التجارب باستخدام العملية التالية:
pip install clearml-agentتتوفر واجهة كاملة وقدرات مع
clearml-agent --help
clearml-agent daemon --helpclearml-agent init ملاحظة: يستخدم وكيل ClearML مجلد ذاكرة التخزين المؤقت لتخزين حزم النقاط والحزم الملائمة والمستودعات المستنسخة. مجلد ذاكرة التخزين المؤقت لعامل ClearML الافتراضي هو ~/.clearml .
راجع التفاصيل الكاملة في ملف التكوين الخاص بك على ~/clearml.conf .
ملاحظة: يقوم وكيل ClearML بتوسيع ملف تكوين ClearML ~/clearml.conf . وهي مصممة لمشاركة نفس ملف التكوين، انظر المثال هنا
لتصحيح الأخطاء والتجريب، ابدأ تشغيل وكيل ClearML في الوضع foreground ، حيث تتم طباعة جميع المخرجات على الشاشة:
clearml-agent daemon --queue default --foreground بالنسبة إلى وضع الخدمة الفعلي، سيتم تخزين كافة البيانات القياسية تلقائيًا في ملف مؤقت (لا حاجة إلى توجيه البيانات). ملاحظة: مع العلامة --detached ، سيتم تشغيل عامل Clearml في الخلفية
clearml-agent daemon --detached --queue default يتم التحكم في تخصيص وحدة معالجة الرسومات عبر بيئة نظام التشغيل القياسية NVIDIA_VISIBLE_DEVICES أو علامة --gpus (أو تعطيلها باستخدام --cpu-only ).
إذا لم يتم تعيين علامة، ولم يكن المتغير NVIDIA_VISIBLE_DEVICES موجودًا، فسيتم تخصيص جميع وحدات معالجة الرسومات لـ clearml-agent .
إذا تم تعيين علامة --cpu-only ، أو NVIDIA_VISIBLE_DEVICES="none" ، فلن يتم تخصيص وحدة معالجة الرسومات clearml-agent .
على سبيل المثال: قم بتدوير وكيلين، واحد لكل وحدة معالجة رسومات (GPU) على نفس الجهاز:
ملاحظة: مع العلامة --detached ، سيتم تشغيل عامل Clearml في الخلفية
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default على سبيل المثال: قم بتدوير وكيلين، مع السحب من قائمة انتظار dual_gpu المخصصة، ووحدتي GPU لكل وكيل
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu لتصحيح الأخطاء والتجريب، قم بتشغيل وكيل ClearML في الوضع foreground ، حيث تتم طباعة جميع المخرجات على الشاشة
clearml-agent daemon --queue default --docker --foreground بالنسبة إلى وضع الخدمة الفعلي، سيتم تخزين كافة البيانات القياسية تلقائيًا في ملف (لا حاجة إلى توجيه البيانات). ملاحظة: مع العلامة --detached ، سيتم تشغيل عامل Clearml في الخلفية
clearml-agent daemon --detached --queue default --docker مثال: قم بتدوير وكيلين، واحد لكل وحدة معالجة رسومات على نفس الجهاز، مع عامل الإرساء الافتراضي nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 :
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 على سبيل المثال: قم بتدوير وكيلين، بالسحب من قائمة انتظار dual_gpu المخصصة، ووحدتي GPU لكل وكيل، مع عامل الإرساء الافتراضي nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 :
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04يتم أيضًا دعم قوائم الانتظار ذات الأولوية، مثال على حالة الاستخدام:
قائمة الانتظار ذات الأولوية العالية: important_jobs ، قائمة الانتظار ذات الأولوية المنخفضة: default
clearml-agent daemon --queue important_jobs default سيحاول وكيل ClearML أولاً سحب المهام من قائمة انتظار important_jobs ، وفقط إذا كانت فارغة، سيحاول الوكيل السحب من قائمة الانتظار default .
تتوفر إمكانية إضافة قوائم الانتظار، وإدارة أوامر العمل داخل قائمة الانتظار، ونقل المهام بين قوائم الانتظار باستخدام واجهة مستخدم الويب، راجع المثال على خادمنا المجاني
لإيقاف تشغيل وكيل ClearML في الخلفية، قم بتشغيل نفس سطر الأوامر المستخدم لبدء تشغيل الوكيل مع إلحاق --stop . على سبيل المثال، لإيقاف أول جهاز من نفس الجهاز الموضح أعلاه، وكيل GPU واحد:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopقم بدمج ClearML مع التعليمات البرمجية الخاصة بك
قم بتنفيذ الكود على جهازك (يدويًا / PyCharm / Jupyter Notebook)
أثناء تشغيل التعليمات البرمجية الخاصة بك، يقوم ClearML بإنشاء تجربة لتسجيل جميع معلومات التنفيذ الضرورية:
لديك الآن "نموذج" لتجربتك يحتوي على كل ما هو مطلوب للتنفيذ الآلي
في واجهة مستخدم ClearML، انقر بزر الماوس الأيمن على التجربة وحدد "استنساخ". سيتم إنشاء نسخة من تجربتك.
لديك الآن مسودة تجربة جديدة منسوخة من تجربتك الأصلية، فلا تتردد في تعديلها
قم بجدولة التجربة التي تم إنشاؤها حديثًا للتنفيذ: انقر بزر الماوس الأيمن فوق التجربة وحدد "قائمة الانتظار"
تعد خدمات ClearML-Agent بمثابة وضع خاص لـ ClearML-Agent يوفر القدرة على إطلاق مهام طويلة الأمد كان يتعين في السابق تنفيذها على أجهزة محلية / مخصصة. يسمح لوكيل واحد بإطلاق عدة عمال إرساء (مهام) لحالات استخدام مختلفة:
سيقوم وضع خدمات ClearML-Agent بتدوير أي مهمة مدرجة في قائمة الانتظار المحددة. سيتم تسجيل كل مهمة يتم إطلاقها بواسطة ClearML-Agent Services كعقدة جديدة في النظام، مما يوفر إمكانات التتبع والشفافية. حاليًا، يدعم Clearml-agent في وضع الخدمات تكوين وحدة المعالجة المركزية (CPU) فقط. يمكن تشغيل وضع خدمات ClearML-Agent جنبًا إلى جنب مع وكلاء GPU.
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-onlyملاحظة : تقع على عاتق المستخدم مسؤولية التأكد من دفع المهام المناسبة إلى قائمة الانتظار المحددة.
يمكن أيضًا استخدام وكيل ClearML لتنفيذ تنسيق AutoML وخطوط أنابيب التجربة بالتزامن مع حزمة ClearML.
يمكن العثور على نماذج من أمثلة AutoML والتنسيق في مجلد ClearML للمثال/الأتمتة.
أمثلة AutoML:
أمثلة على خطوط الأنابيب التجريبية:
ترخيص Apache، الإصدار 2.0 (راجع الترخيص لمزيد من المعلومات)


