نظام إدارة المترو
SUSTech 2024 مشاريع الربيع للدورة CS307 - Principles of Database System بقيادة Yuxin MA
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
يتعلق الجزء الأول من المشروع بشكل أساسي بتصميم مخطط قاعدة بيانات يلبي مبادئ قواعد البيانات العلائقية بناءً على خلفية البيانات المقدمة. بمجرد اكتمال مرحلة التصميم، قمنا بكتابة نصوص برمجية لاستيراد مجموعات البيانات الكبيرة هذه. للتأكد من دقة البيانات المستوردة، كان علينا إجراء بعض عبارات الاستعلام والتحقق من نتائج الاستعلام في يوم الدفاع. بالإضافة إلى ذلك، أجرينا أيضًا بعض التجارب على البيانات للحصول على بعض الأفكار الرائعة، كما هو موضح لاحقًا.
[اقرأ المتطلبات التفصيلية]
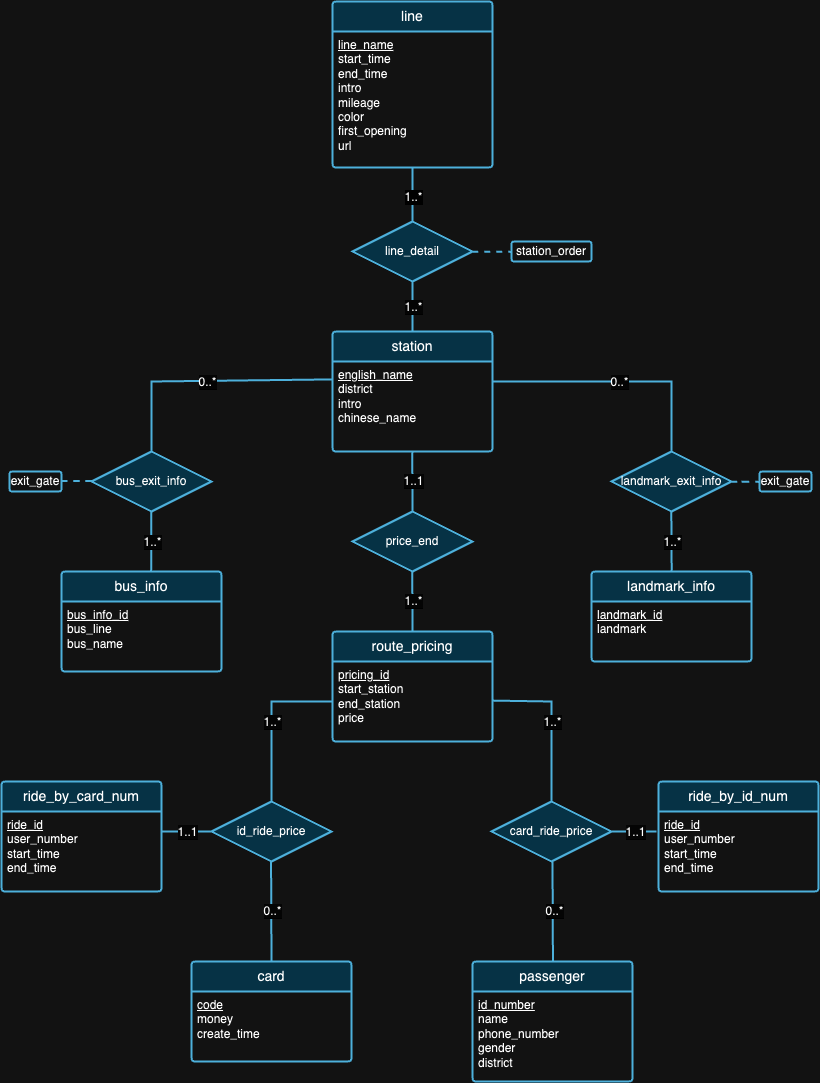
نحن نؤمن بأنه لا يوجد تصميم مثالي لقاعدة البيانات. في الواقع، هناك عيوب في التصميم الذي اقترحناه في مخطط ER أعلاه. بعد النظر إلى مجموعات البيانات وخلفية كل مجموعة بيانات، نأمل أن تتمكن من محاولة اكتشاف عيوب التصميم بنفسك! :)
ملاحظة : لتفسير الشكل،
| بطاقة تعريف | نظام التشغيل | رقاقة | ذاكرة | SSD | أدوات |
|---|---|---|---|---|---|
| 1 | ماك سونوما 14.4.1 | أبل إم 3 برو | 18 جيجابايت | 1 تيرابايت | IDEA 2024.1 (CE)، PyCharm 2023.3.4 (CE)، Datagrip 2024.1 |
| 2 | ويندوز 11 هوم 23H2 | الجيل الثاني عشر من Intel(R) Core(TM) i9-12900H | 32 جيجابايت | 1 تيرابايت | آيديا 2024.1 (CE)، داتا جريب 2024.1 |
| 3 | أوبونتو 22.04.4 (VM) | أبل ام 1 برو | 16 جيجابايت | 512 جيجابايت | آيديا 2024.1 (CE)، داتا جريب 2024.1 |
Experiment 1: Different Import Methods الطريقة الأولى (البرنامج النصي الأصلي): تستخدم هذه الطريقة مكتبة java.sql . أولاً، قمنا بإنشاء اتصال بخادم PostgreSQL الخاص بنا. ثم نقرأ جميع البيانات من ملفات JSON. بعد ذلك، قمنا بالتكرار خلال كل مرجع وأنشأنا PreparedStatement لكل عبارة إدراج. وأخيرًا، قمنا باستدعاء طريقة executeUpdate() لتنفيذ كل عبارة على حدة.
الطريقة الثانية (البرنامج النصي المحسّن): تستخدم هذه الطريقة أيضًا مكتبة java.sql وتستخدم نفس خوارزمية قراءة البيانات مثل الطريقة الأولى. والفرق الآن هو أننا نستخدم طريقة executeBatch() . لذلك قمنا بتكرار البيانات بأكملها، وأنشأنا كل عبارة إدراج باستخدام PreparedStatement ، وأضفنا كل PreparedStatement إلى دفعة لتنفيذها على دفعات.
الطريقة الثالثة (تشغيل ملف .sql): استخدمنا برنامج Java لإنشاء عبارات إدراج SQL وكتابتها في ملف .sql باستخدام نفس خوارزمية قراءة البيانات المذكورة أعلاه. ثم نقوم بتشغيل الملف في DataGrip.
وبما أننا نستخدم نفس خوارزمية قراءة البيانات عبر الطرق الثلاث، فسوف نستخدم متوسط وقت التشغيل لاختباراتنا اللاحقة. قمنا في البداية بجمع ثلاثة أوقات تشغيل مختلفة - 504 مللي ثانية، و546 مللي ثانية، و552 مللي ثانية - وحسبنا متوسط وقت تشغيل يبلغ 534 مللي ثانية.
| بيئة الاختبار | طريقة | متوسط وقت القراءة (مللي ثانية) | وقت الكتابة (مللي ثانية) | الوقت الإجمالي (مللي ثانية) | الإنتاجية (البيانات/البيانات) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636.91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
يوضح الجدول 2 مقاييس الأداء المختلفة عبر طرق مختلفة، حيث تعرض الطريقة 2 أعلى إنتاجية بينما تتميز الطريقة 1 بأبطأ إجمالي وقت. وهذا يجعل الطريقة الثانية هي طريقة الاختبار القياسية في التجارب القادمة.
Experiment 2: Data Import with Different Data Volumesتعد إدارة واستيراد البيانات ذات الأحجام المختلفة جانبًا حاسمًا لضمان الأداء وقابلية التوسع والموثوقية لنظام قاعدة البيانات.
قبل عملية الاستيراد، لاحظنا أن بيانات "الرحلة" كانت أكبر حجمًا بشكل ملحوظ مقارنة بالبيانات الأخرى. بناءً على هذه الفكرة، قررنا اختبار استيراد البيانات بأحجام مختلفة على ملف ride.json فقط. نظرًا لأن وزن البيانات غير متسق، فإن استيراد حجم أقل للجداول الأخرى قد يؤدي إلى مشكلة خطيرة بسبب الاتصال بين الجداول.
في البداية، بدأنا باستيراد البيانات الكاملة (حجم 100%) لجميع الجداول الأخرى باستثناء جداول rides_by_id_num و rides_by_card_num لضمان اتساق تصميمنا. ولإدارة ذلك بفعالية، اعتمدنا استراتيجية استيراد مرحلية لبيانات ride ، بدءًا بمجموعة فرعية بنسبة 20% من البيانات، أي ما يعادل 20000 سجل. أتاحت لنا هذه المرحلة الأولية تقييم التأثير على أداء النظام وإجراء التعديلات اللازمة على عملية الاستيراد دون المساس باستقرار قاعدة البيانات. بعد التحقق من الصحة وضبط الأداء بنجاح، شرعنا في استيراد 50% من البيانات، وأخيراً الجزء المتبقي لإكمال استيراد البيانات بنسبة 100%. لاحظ أننا استخدمنا الطريقة الثانية لجميع الواردات لأنها الأسرع.
| بيئة الاختبار | طريقة | مقدار | وقت القراءة (مللي ثانية) | وقت الكتابة (مللي ثانية) | الوقت الإجمالي (مللي ثانية) | عدد البيان | الإنتاجية (البيانات/البيانات) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | 1859 | 130849 | 97794.47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263.95 |
من الجدول 3، مع زيادة حجم البيانات (من 20% إلى 50% وإلى 100%)، تميل أوقات القراءة والكتابة إلى الزيادة، مما يؤدي إلى إجمالي أوقات أطول للعمليات. ومع ذلك، فإن هذه الأرقام لا تعطي أي معنى ثاقبة حيث كان لدينا أحجام واردات مختلفة. إذا نظرنا إلى عدد الإنتاجية بدلاً من ذلك، فإن الإنتاجية (البيانات/البيانات) تتناقص تدريجيًا مع زيادة حجم البيانات، مما يشير إلى أن النظام يصبح أقل كفاءة في معالجة البيانات مع زيادة عبء العمل.
Experiment 3: Data Import on Different Operating Systemsفي اختبار عملية استيراد البيانات على أنظمة تشغيل مختلفة، استخدمنا أسرع طريقة استيراد، وهي الطريقة الثانية، بحجم استيراد يصل إلى 100%.
لاحظ أنه عند تشغيل البرنامج النصي لاستيراد Java على Linux من خلال جهاز افتراضي، من الضروري مراعاة العيب غير العادل فيما يتعلق بالأداء وتخصيص الموارد، حيث يمكن أن تؤدي المحاكاة الافتراضية إلى زيادة الحمل والتأثير على كفاءة النظام.
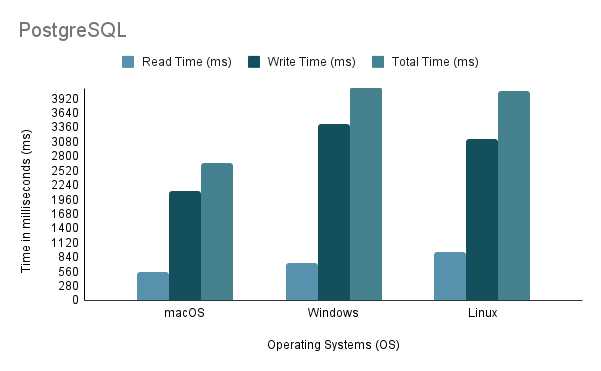
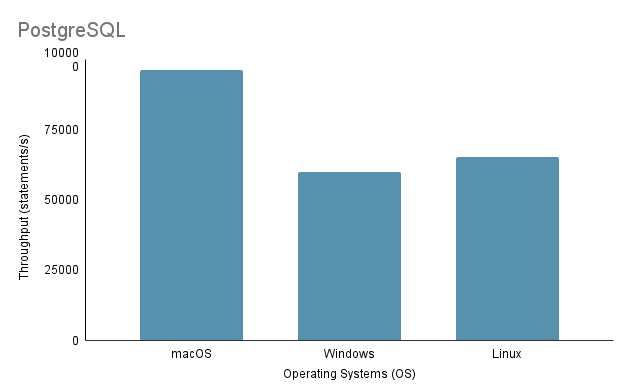
بناءً على التحليل أعلاه، من الواضح أن البيئة 1 (macOS) تظهر أفضل أداء مع أقصر وقت إجمالي يبلغ 2648 مللي ثانية وأعلى إنتاجية عند 97,632.92 عبارة/ثانية. في المقابل، البيئة 2 (Windows) هي الأبطأ بإجمالي وقت يبلغ 4117 مللي ثانية وأقل إنتاجية عند 60,669.02 عبارة/ثانية. تجدر الإشارة إلى أن Linux Ubuntu، أثناء تشغيله كجهاز افتراضي، لا يزال يتفوق على نظام التشغيل Windows المعدني.
Experiment 4: Data Import with Various Programming Languagesفي هذه التجربة، استخدمنا الطريقة الثانية المذكورة أعلاه لكود Java لأنها الأسرع. وفي الوقت نفسه، بالنسبة لـ Python، كتبنا طريقة استيراد تستخدم Psycopg2 للتواصل مع خادم قاعدة بيانات PostgreSQL.
| بيئة الاختبار | لغة البرمجة | وقت القراءة (مللي ثانية) | وقت الكتابة (مللي ثانية) | الوقت الإجمالي (مللي ثانية) | الإنتاجية (البيانات/البيانات) |
|---|---|---|---|---|---|
| 1 | جافا | 534 | 2114 | 2648 | 96263.95 |
| 1 | بايثون | 390 | 7237 | 7627 | 28119.66 |
توضح البيانات الواردة في الجدول 4 أن Java تفوقت على Python في كل من السرعة والإنتاجية، مما يشير إلى كفاءتها الفائقة في عمليات القراءة والكتابة.
Experiment 5: Data Import on Different Databasesلقد قمنا بتطوير ثلاث طرق استيراد مختلفة لكل من PostgreSQL وMySQL، لكننا أجرينا تجربة على الطريقة الثانية فقط لأنها اختيار المطور لاستيراد البيانات. يتمتع كل من PostgreSQL وMySQL بتصميم مماثل لتنفيذ قاعدة البيانات (DDL) وتصميم مماثل لرمز الاستيراد.
| بيئة الاختبار | طريقة | قاعدة البيانات | وقت القراءة (مللي ثانية) | وقت الكتابة (مللي ثانية) | الوقت الإجمالي (مللي ثانية) | الإنتاجية (البيانات/البيانات) |
|---|---|---|---|---|---|---|
| 1 | 2 | PostgreSQL | 534 | 2114 | 2648 | 96263.95 |
| 1 | 2 | ماي إس كيو إل | 534 | 42315 | 42849 | 4809.22 |
على الرغم من كونهما قاعدتي بيانات مبنيتين على SQL، إلا أن PostgreSQL أسرع بحوالي 16 مرة عندما يتعلق الأمر بوقت الكتابة. قد يكون هذا بسبب الاختلافات في بنية محرك قاعدة البيانات وتنفيذ برنامج التشغيل ( postgresql-42.2.5.jar لـ PostgreSQL و mysql-connector-j-8.3.0.jar لـ MySQL).
يركز الجزء الثاني من المشروع على توفير الوظيفة الأساسية للوصول إلى نظام قاعدة البيانات من خلال بناء مكتبة خلفية تعرض مجموعة من واجهات برمجة التطبيقات (APIs). لاحظ أن هناك أيضًا مجموعة بيانات إضافية يلزم استيرادها، وبالتالي يتطلب تنفيذ قاعدة بيانات محدثة (يمكن العثور عليها في ./Project2/DataImport ).
[اقرأ المتطلبات التفصيلية]
./Project2/DataImport/src/main/sql/ddl.sql./Project2/DataImport/src/main/java/ImportScript.java./Project2/ShenzhenMetro ) باستخدام Maven (يوصى بـ IntelliJ IDEA IDE)

