chrono_lens
v1.1.1
هذا هو المستودع العام لمشروع تحليل كاميرات المرور كما تم نشره على مدونة الحرم الجامعي لعلوم بيانات البيانات الإحصائية الوطنية كجزء من المؤشرات الأسرع لفيروس كورونا التابع لمكتب الإحصاءات الوطنية (على سبيل المثال - نشاط كاميرات المرور - 10 سبتمبر 2020) والمنهجية الأساسية. استخدم المشروع Google Compute Platform (GCP) لتمكين حل قابل للتطوير، ولكن المنهجية الأساسية لا تعتمد على النظام الأساسي؛ يحتوي هذا المستودع على التنفيذ الموجه لبرنامج Google Cloud Platform.
ويرد أدناه مثال على المخرجات التي تم إنتاجها لمؤشر فيروس كورونا الأسرع.
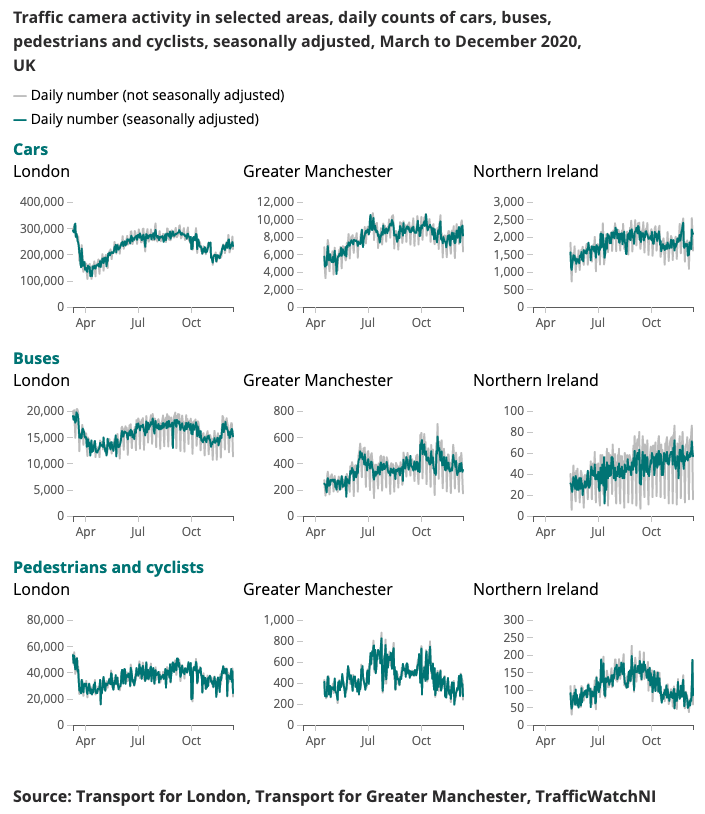
لقد كان فهم الأنماط المتغيرة في التنقل والسلوك في الوقت الفعلي محورًا رئيسيًا لاستجابة الحكومة لفيروس كورونا (COVID-19). يستكشف حرم علوم البيانات مصادر بيانات بديلة قد تعطي رؤى حول كيفية تقدير مستويات التباعد الاجتماعي، وتتبع تطور المجتمع والاقتصاد مع تخفيف ظروف الإغلاق.
تعد كاميرات المرور مصدر بيانات متاحًا على نطاق واسع وعامة، مما يسمح لمحترفي النقل والجمهور بتقييم تدفق حركة المرور في أجزاء مختلفة من البلاد عبر الإنترنت. الصور التي تنتجها كاميرات المرور متاحة للجمهور، وذات دقة منخفضة، ولا تسمح بالتعرف على الأشخاص أو المركبات بشكل فردي. وهي تختلف عن الدوائر التلفزيونية المغلقة المستخدمة للسلامة العامة وإنفاذ القانون للتعرف التلقائي على لوحة الأرقام (ANPR) أو لمراقبة سرعة حركة المرور.
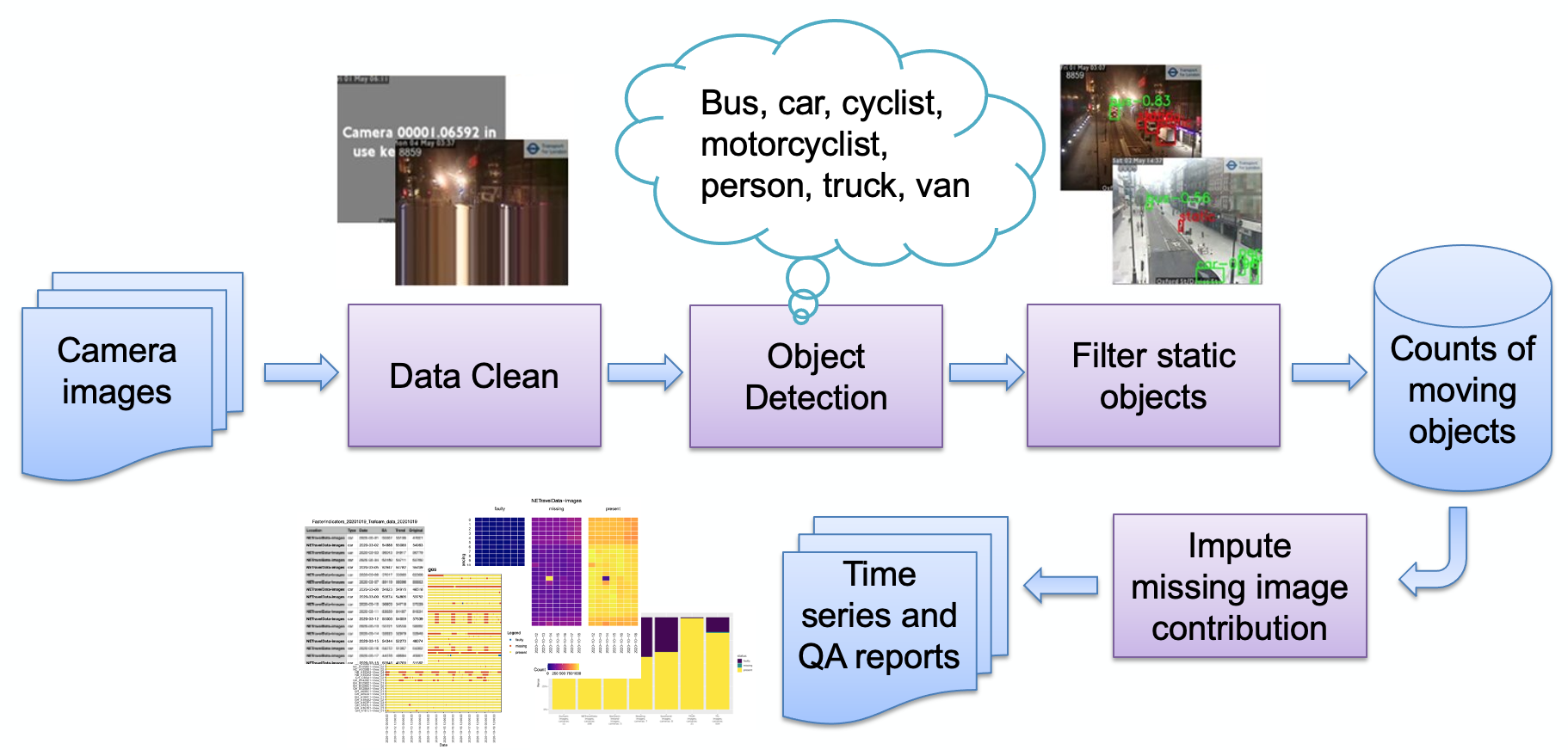
المراحل الرئيسية لخط الأنابيب، كما هو موضح في الصورة، هي:
استيعاب الصورة
كشف الصورة الخاطئة
كشف الكائنات
الكشف عن الكائنات الثابتة
تخزين الأعداد الناتجة
ويمكن بعد ذلك معالجة الأعداد بشكل أكبر (التعديل الموسمي، واحتساب القيمة المفقودة) وتحويلها إلى تقارير كما هو مطلوب. سنراجع بإيجاز المراحل الرئيسية لخط الأنابيب.
يتم تحديد مجموعة من مصادر الكاميرا (صور JPEG المستضافة على الويب) من قبل المستخدم، ويتم توفيرها كقائمة من عناوين URL للمستخدم. يتم توفير رمز المثال للحصول على الصور العامة من هيئة النقل في لندن، والكود المتخصص لسحب بيانات المرور في شمال شرق البلاد مباشرة من المرصد الحضري بجامعة نيوكاسل.
قد تكون الكاميرات غير متاحة لأسباب مختلفة (خطأ في النظام، أو تعطيل التغذية من قبل المشغل المحلي، وما إلى ذلك) وقد تتسبب هذه الأسباب في إنشاء النموذج لأعداد كائنات زائفة (على سبيل المثال، قد تبدو النقطة الصغيرة مثل ناقل بعيد). مثال على هذه الصورة هو: 
اتبعت جميع هذه الصور حتى الآن نمطًا من صورة اصطناعية للغاية، تتكون من لون خلفية مسطح ونص متراكب (مقارنة بصورة مشهد طبيعي). يتم اكتشاف هذه الصور حاليًا عن طريق تقليل عمق الألوان (التقاط الألوان المتشابهة معًا) ثم النظر إلى الجزء الأعلى من الصورة الذي يشغله لون واحد. بمجرد تجاوز هذا الحد، نحدد أن الصورة اصطناعية ونضع علامة عليها على أنها معيبة. قد تحدث أخطاء أخرى بسبب التشفير، مثل: 
هنا، توقف بث الكاميرا وتم تكرار الصف "المباشر" الأخير؛ نكتشف ذلك عن طريق التحقق مما إذا كان الصف السفلي من الصورة يتطابق مع الصف أعلاه (ضمن العتبة). إذا كان الأمر كذلك، فسيتم التحقق من وجود تطابق في الصف التالي أعلاه، وهكذا حتى لا تتطابق الصفوف أو نفاد الصفوف. إذا كان عدد الصفوف المطابقة أعلى من الحد، فمن غير المرجح أن تولد الصورة بيانات مفيدة وبالتالي يتم وضع علامة عليها على أنها معيبة.
لاحظ أن موفري الصور المختلفين يستخدمون طرقًا مختلفة لإظهار عدم توفر الكاميرا؛ تعتمد تقنية الكشف لدينا على عدد قليل من الألوان المستخدمة - أي صورة اصطناعية بحتة. إذا تم استخدام صورة أكثر طبيعية، فقد لا تعمل تقنيتنا. البديل هو الاحتفاظ بـ "مكتبة" من الصور الفاشلة والبحث عن أوجه التشابه، والتي قد تعمل بشكل أفضل مع الصور الأكثر طبيعية.
تحدد عملية الكشف عن الأجسام كلاً من الأجسام الثابتة والمتحركة، باستخدام Faster-RCNN المدرب مسبقًا والمقدم من المرصد الحضري بجامعة نيوكاسل. تم تدريب النموذج على 10000 صورة لكاميرات المرور من شمال شرق إنجلترا، وتم التحقق من صحتها من قبل مجمع علوم البيانات التابع لمكتب الإحصاءات الوطني للتأكد من أن النموذج كان قابلاً للاستخدام مع صور الكاميرا من مناطق أخرى في المملكة المتحدة. يكتشف أنواع الكائنات التالية: سيارة، شاحنة صغيرة، شاحنة، حافلة، مشاة، راكب دراجة، سائق دراجة نارية.
نظرًا لأننا نهدف إلى اكتشاف النشاط، فمن المهم تصفية الكائنات الثابتة باستخدام المعلومات الزمنية. يتم أخذ عينات من الصور بفواصل زمنية مدتها 10 دقائق، لذا فإن الطرق التقليدية لاكتشاف الخلفية في الفيديو، مثل خليط Gaussians، ليست مناسبة.
سيتم تعيين أي مشاة ومركبات تم تصنيفها أثناء اكتشاف الكائنات على أنها ثابتة وإزالتها من الأعداد النهائية إذا ظهرت أيضًا في الخلفية. توضح الصورة أدناه نتائج نموذجية للقناع الثابت، حيث يتم تحديد السيارات المتوقفة في الصورة (أ) على أنها ثابتة وإزالتها. هناك فائدة إضافية تتمثل في أن القناع الثابت يمكن أن يساعد في إزالة الإنذارات الكاذبة. على سبيل المثال، في الصورة (ب)، تم تعريف سلة المهملات بشكل خاطئ على أنها أحد المشاة في اكتشاف الكائن ولكن تمت تصفيتها كخلفية ثابتة.

يتم تخزين النتائج ببساطة كجدول، ومعرف كاميرا تسجيل المخطط، والتاريخ، والوقت، والأعداد ذات الصلة لكل نوع كائن (سيارة، شاحنة صغيرة، مشاة، وما إلى ذلك)، إذا كانت الصورة معيبة أو إذا كانت الصورة مفقودة.
في البداية، تم تصميم النظام ليكون سحابيًا أصليًا، لتمكين قابلية التوسع؛ ومع ذلك، فإن هذا يمثل عائقًا أمام الدخول - يجب أن يكون لديك حساب مع موفر السحابة، ومعرفة كيفية تأمين البنية التحتية، وما إلى ذلك. ومع أخذ ذلك في الاعتبار، قمنا أيضًا بإعادة نقل التعليمات البرمجية للعمل على جهاز مستقل (أو "المضيف المحلي") لتمكين المستخدم المهتم من تشغيل النظام ببساطة على الكمبيوتر المحمول الخاص به. يتم الآن وصف كلا التنفيذين أدناه.
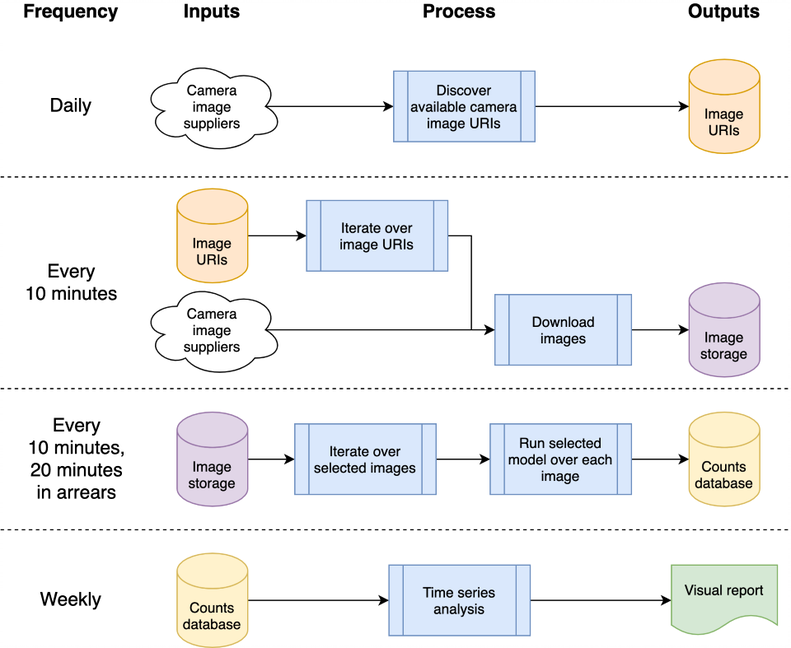
يمكن تعيين هذه البنية إلى جهاز واحد أو نظام سحابي؛ لقد اخترنا استخدام Google Compute Platform (GCP)، ولكن الأنظمة الأساسية الأخرى مثل Amazon Web Services (AWS) أو Microsoft Azure ستوفر خدمات مكافئة نسبيًا.
تتم استضافة النظام كـ "وظائف سحابية"، وهي عبارة عن تعليمات برمجية مستقلة عديمة الحالة يمكن استدعاؤها بشكل متكرر دون التسبب في تلف - وهو اعتبار رئيسي لزيادة قوة الوظائف. يتم تنظيم دفعات المعالجة اليومية و"كل 10 دقائق" باستخدام برنامج جدولة GCP لتشغيل موضوع نشر/فرعي في GCP وفقًا للجدول الزمني المطلوب. يتم تسجيل وظائف سحابة GCP مقابل الموضوع ويتم تشغيلها عند تشغيل الموضوع.
تؤدي معالجة الصور لاكتشاف المركبات والمشاة إلى كتابة أعداد الكائنات في قاعدة بيانات لتحليلها لاحقًا كسلسلة زمنية. يتم استخدام قاعدة البيانات لمشاركة البيانات بين جمع البيانات وتحليل السلاسل الزمنية، مما يقلل من الاقتران. نحن نستخدم BigQuery ضمن Google Cloud Platform كقاعدة بيانات لدينا نظرًا لدعمها الواسع في منتجات Google Cloud Platform الأخرى، مثل Data Studio لتصور البيانات؛ يقوم تطبيق المضيف المحلي بتخزين ملفات CSV اليومية بالمقارنة، لإزالة أي اعتماد على قاعدة بيانات معينة أو بنية تحتية أخرى.
يتم تخزين كود المصدر المرتبط بـ GCP في المجلد cloud ؛ يؤدي هذا إلى تنزيل الصور ومعالجتها لحساب عدد الكائنات وتخزين الأعداد في قاعدة بيانات وإنتاج تحليل السلاسل الزمنية (أسبوعيًا). يتم تخزين جميع الوثائق وكود المصدر في المجلد cloud ؛ ارجع إلى Cloud README.md للحصول على نظرة عامة على البنية وكيفية تثبيت المثيل الخاص بك باستخدام البرامج النصية الخاصة بنا في مساحة مشروع Google Cloud Platform الخاص بك. يمكن دمج المشروع في GitHub، مما يتيح النشر التلقائي وتنفيذ الاختبار تلقائيًا من الالتزامات إلى مشروع GitHub المحلي؛ تم توثيق هذا أيضًا في Cloud README.md. يتم أيضًا تخزين رمز دعم السحابة في وحدة chrono_lens.gcloud ، مما يمكّن البرامج النصية لسطر الأوامر من دعم GCP، جنبًا إلى جنب مع رمز وظيفة السحابة في مجلد cloud .
يوجد كود جهاز واحد مستقل ("المضيف المحلي") في وحدة chrono_lens.localhost . تتبع العملية نفس التدفق الذي يتبعه متغير GCP، وإن كان ذلك باستخدام جهاز واحد وكل ملف python في chrono_lens.localhost يعين الوظائف السحابية لـ GCP. ارجع إلى README-localhost.md لمزيد من التفاصيل.
نوضح الآن الخطوات المختلفة والمتطلبات المسبقة لتثبيت النظام، نظرًا لأن تطبيقات Google Cloud Platform والشبكة المحلية تتطلب على الأقل بعض التثبيت المحلي.
يُنصح بشدة بإنشاء بيئة افتراضية مما يسمح ببيئة عمل معزولة. من أمثلة بيئات العمل الجيدة: conda وpyenv وpoerty.
لاحظ أن التبعيات موجودة بالفعل في requirements.txt ، لذا يرجى تثبيت هذا عبر النقطة:
pip install -r requirements.txt
لمنع ارتكاب كلمات المرور عن طريق الخطأ، يوصى باستخدام خطافات الالتزام المسبق لمنع معالجة التزامات git قبل وصول المعلومات الحساسة إلى المستودع. لقد استخدمنا خطافات الالتزام المسبق من https://github.com/ukgovdatascience/govcookiecutter
سيؤدي تثبيت require.txt إلى تثبيت أداة الالتزام المسبق، والتي تحتاج الآن إلى الاتصال بـ git:
pre-commit install
... والذي سيقوم بعد ذلك بسحب التكوين من .pre-commit-config.yaml .
ملاحظة: اختبار الالتزام المسبق check-added-large-files له الحد الأقصى لحجم كيلو بايت في .pre-commit-config.yaml ويتم زيادته مؤقتًا إلى 60 ميجابايت عند إضافة ملف نموذج RCNN /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb . يتم بعد ذلك إرجاع الحد إلى 5 ميجابايت باعتباره الحد الأعلى "العادي" المعقول.
يوصى بإجراء مسح لجميع الملفات قبل المتابعة، فقط للتأكد من عدم وجود أي شيء عن طريق الخطأ:
pre-commit run --all-files
سيؤدي هذا إلى الإبلاغ عن أية مشكلات موجودة - وهو أمر مفيد لأن الخطاف يتم تشغيله فقط على الملفات التي تم تحريرها.
تم تصميم المشروع ليتم استخدامه بشكل أساسي عبر البنية التحتية السحابية، ولكن هناك نصوص برمجية مساعدة للوصول المحلي وتحديثات للسلسلة الزمنية في السحابة. توجد هذه البرامج النصية في مجلد scripts/gcloud ، مع وصف كل برنامج نصي الآن في الأقسام التالية المنفصلة. يمكن العثور على مزيد من المعلومات في scripts/gcloud/README.md ، ويتم وصف استخدامها بواسطة جهاز ظاهري اختياري في cloud/README.md .
يتم دعم الاستخدام غير السحابي من خلال البرامج النصية الموجودة في مجلد scripts/localhost ، ويتم شرح تفاصيل كيفية استخدام نظام chrono_lens على جهاز مستقل في README-localhost.md . يمكن العثور على مزيد من المعلومات حول استخدام البرامج النصية في scripts/localhost/README.md .
لاحظ أن البرامج النصية تستخدم التعليمات البرمجية الموجودة في مجلد chrono_lens .
| إصدار | تاريخ | ملحوظات |
|---|---|---|
| 1.0.0 | 2021-06-08 | الإصدار الأول من المستودع العام |
| 1.0.1 | 2021-09-21 | إصلاح الخلل في الصور المعزولة، عثرة إصدار Tensorflow |
| 1.1.0 | ؟ | تمت إضافة دعم محدود لجهاز واحد مستقل |
مجالات العمل المستقبلية المحتملة معروضة هنا؛ قد لا يتم التحقيق في هذه التغييرات، ولكنها موجودة هنا لتوعية الأشخاص بالتحسينات المحتملة التي أخذناها في الاعتبار.
في الوقت الحاضر، يتم استخدام البرامج النصية لـ bash Shell لإنشاء البنية التحتية لـ GCP؛ سيكون التحسين هو استخدام IaC، مثل Terraform. يعمل هذا على تبسيط تغيير (على سبيل المثال) تكوينات وظيفة السحابة دون الحاجة إلى إزالة Cloud Build Trigger يدويًا وإعادة إنشائه عند تغيير بيئة التشغيل أو حدود الذاكرة.
ينبع التصميم الحالي من حالة الاستخدام الأولي للحصول على الصور قبل الانتهاء من النماذج، وبالتالي يتم تنزيل جميع الصور المتاحة بدلاً من تلك التي يتم تحليلها فقط. لتوفير تكاليف العرض، يجب أن يقوم رمز الإدخال بمراجعة ملفات JSON للتحليل وتنزيل هذه الملفات فقط؛ ويجب إصدار تنبيه عندما لا يعود أي من هذه المصادر متاحًا، أو إذا توفرت مصادر جديدة.
يبدو أن التعبئة الليلية لصور NETravelData تعمل على تحديث حوالي 40% من صور NETravelData؛ تتضاءل ميزة التحديث المنتظم إذا كانت الأرقام مطلوبة يوميًا فقط، ومن ثم قد تتم إزالة وظيفة السحابة distribute_ne_travel_data .
http async إلى PubSub يستخدم التصميم الأولي نصوصًا برمجية يتم تشغيلها يدويًا عند اختبار النماذج الجديدة - وهي batch_process_images.py . يشير هذا إلى النجاح (أو لا) وعدد الصور التي تمت معالجتها. للقيام بذلك، تعمل الدالة السحابية بشكل جيد حيث تقوم بإرجاع نتيجة. ومع ذلك، قد تكون البنية الأكثر كفاءة هي استخدام قائمة انتظار PubSub داخليًا مع وظائف distribute_json_sources و processed_scheduled التي تضيف العمل إلى قوائم انتظار PubSub التي تستهلكها وظيفة عامل واحدة، بدلاً من التسلسل الهرمي الحالي للاستدعاءات غير المتزامنة (باستخدام وظيفتين إضافيتين للتوسيع ).
قام المرصد الحضري بجامعة نيوكاسل بتوفير Faster-RCNNN المدرب مسبقًا والذي نستخدمه (يتم تخزين نسخة محلية في /tests/test_data/test_detector_data/fig_frcnn_rebuscov-3.pb ).
يتم توفير البيانات من خلال خدمة البيانات المفتوحة لإدارة حركة المرور الحضرية والتحكم فيها في شمال شرق البلاد، والمرخصة بموجب ترخيص الحكومة المفتوحة 3.0. تُنسب الصور إلى شركة Tyne and Wear لإدارة ومراقبة حركة المرور في المناطق الحضرية.
تتم معالجة بيانات الشمال الشرقي بشكل أكبر واستضافتها من قبل المرصد الحضري بجامعة نيوكاسل، الذي نقدر دعمه ونصائحه بامتنان.
يتم توفير البيانات بواسطة TfL ويتم تشغيلها بواسطة TfL Open Data. تم ترخيص البيانات بموجب الإصدار 2.0 من الترخيص الحكومي المفتوح. تحتوي بيانات TfL على بيانات نظام التشغيل © حقوق الطبع والنشر وحقوق قاعدة البيانات لعام 2016 وبيانات خريطة Geomni UK © وحقوق قاعدة البيانات (2019).
يتم استخدام مكتبات خارجية مختلفة في هذا المشروع؛ تم إدراجها في صفحة التبعيات، والتي نقدر مساهماتها بامتنان.


