shap
v0.46.0
SHAP (SHapley Additive exPlanations) هو منهج نظري للعبة لشرح مخرجات أي نموذج للتعلم الآلي. فهو يربط التخصيص الأمثل للائتمان مع التفسيرات المحلية باستخدام قيم شابلي الكلاسيكية من نظرية اللعبة والملحقات المرتبطة بها (انظر الأوراق للحصول على التفاصيل والاستشهادات).
يمكن تثبيت SHAP من PyPI أو conda-forge:
نقطة تثبيت الشكل أو conda install -c conda-forge shap
في حين أن SHAP يمكنه شرح مخرجات أي نموذج للتعلم الآلي، فقد قمنا بتطوير خوارزمية دقيقة عالية السرعة لطرق تجميع الأشجار (انظر ورقة Nature MI الخاصة بنا). يتم دعم تطبيقات Fast C++ لنماذج XGBoost و LightGBM و CatBoost و scikit-learn و pyspark Tree:
import xgboost
import shap
# train an XGBoost model
X , y = shap . datasets . california ()
model = xgboost . XGBRegressor (). fit ( X , y )
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap . Explainer ( model )
shap_values = explainer ( X )
# visualize the first prediction's explanation
shap . plots . waterfall ( shap_values [ 0 ])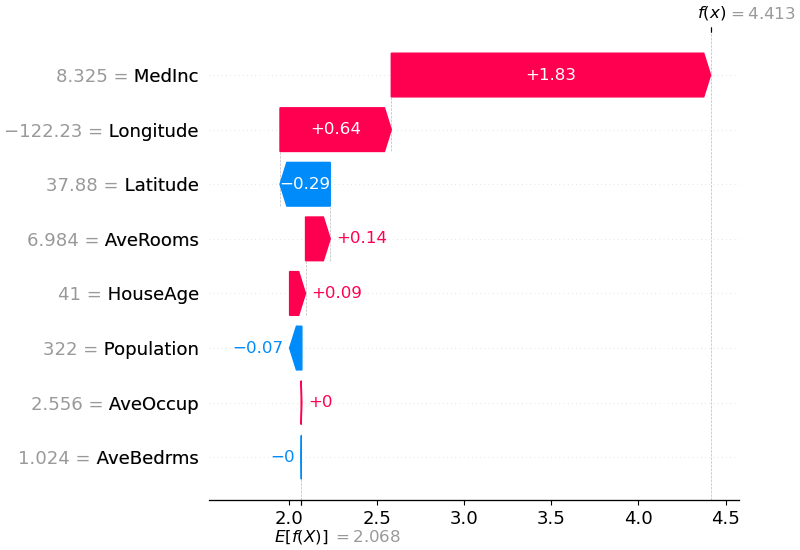
يوضح الشرح أعلاه الميزات التي يساهم كل منها في دفع مخرجات النموذج من القيمة الأساسية (متوسط مخرجات النموذج عبر مجموعة بيانات التدريب التي مررناها) إلى مخرجات النموذج. تظهر الميزات التي تدفع التنبؤ إلى أعلى باللون الأحمر، وتلك التي تدفع التنبؤ إلى الأسفل تظهر باللون الأزرق. هناك طريقة أخرى لتصور نفس التفسير وهي استخدام مخطط القوة (تم تقديمه في بحثنا عن Nature BME):
# visualize the first prediction's explanation with a force plot
shap . plots . force ( shap_values [ 0 ])
إذا أخذنا العديد من تفسيرات مخططات القوة مثل تلك الموضحة أعلاه، وقمنا بتدويرها بمقدار 90 درجة، ثم قمنا بتجميعها أفقيًا، فيمكننا رؤية تفسيرات لمجموعة بيانات بأكملها (في دفتر الملاحظات، هذه المخططات تفاعلية):
# visualize all the training set predictions
shap . plots . force ( shap_values [: 500 ])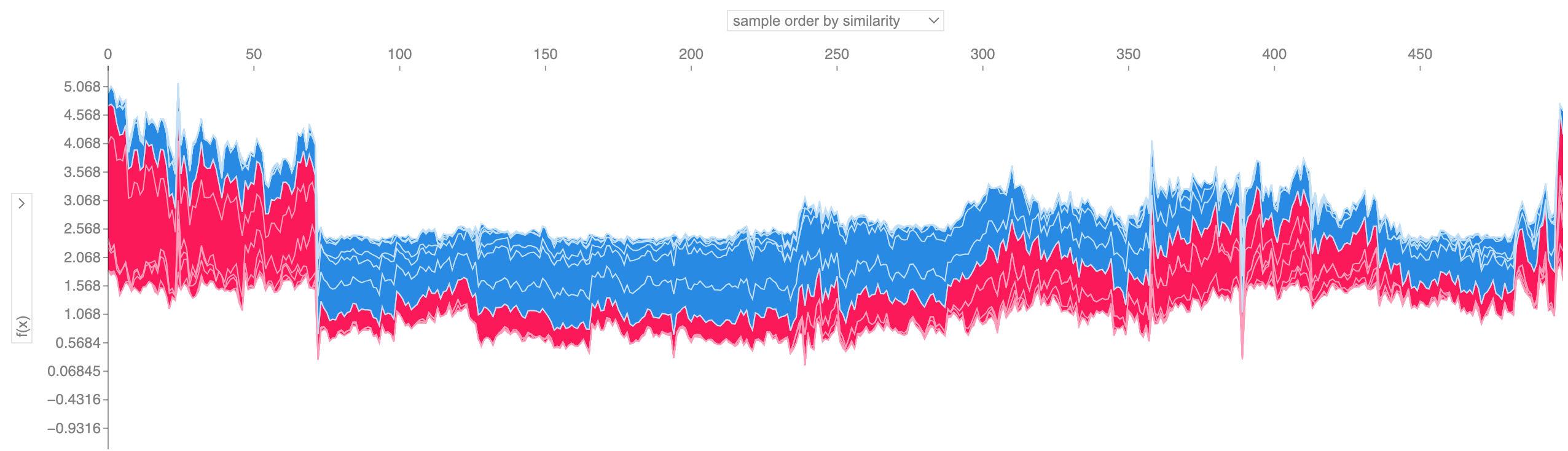
لفهم كيفية تأثير ميزة واحدة على مخرجات النموذج، يمكننا رسم قيمة SHAP لتلك الميزة مقابل قيمة الميزة لجميع الأمثلة في مجموعة البيانات. وبما أن قيم SHAP تمثل مسؤولية الميزة عن التغيير في مخرجات النموذج، فإن الرسم البياني أدناه يمثل التغيير في سعر المنزل المتوقع مع تغير خط العرض. يمثل التشتت الرأسي عند قيمة واحدة لخط العرض تأثيرات التفاعل مع الميزات الأخرى. للمساعدة في الكشف عن هذه التفاعلات يمكننا تلوينها بميزة أخرى. إذا قمنا بتمرير موتر الشرح بالكامل إلى وسيطة color ، فسوف يختار المخطط المبعثر أفضل ميزة للتلوين بها. في هذه الحالة فإنه يختار خط الطول.
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap . plots . scatter ( shap_values [:, "Latitude" ], color = shap_values )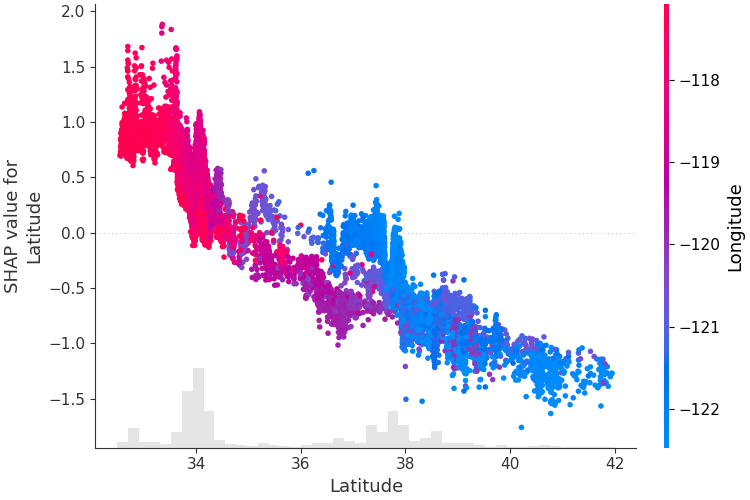
للحصول على نظرة عامة حول الميزات الأكثر أهمية بالنسبة للنموذج، يمكننا رسم قيم SHAP لكل ميزة لكل عينة. يقوم المخطط أدناه بفرز الميزات حسب مجموع مقادير قيمة SHAP على جميع العينات، ويستخدم قيم SHAP لإظهار توزيع تأثيرات كل ميزة على مخرجات النموذج. يمثل اللون قيمة الميزة (أحمر مرتفع، أزرق منخفض). ويكشف هذا على سبيل المثال أن ارتفاع متوسط الدخل يؤدي إلى تحسين سعر المنزل المتوقع.
# summarize the effects of all the features
shap . plots . beeswarm ( shap_values )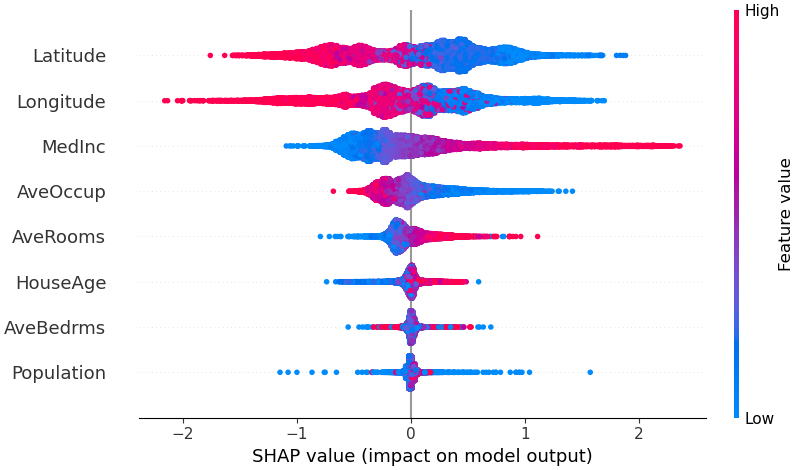
يمكننا أيضًا أن نأخذ القيمة المطلقة المتوسطة لقيم SHAP لكل ميزة للحصول على مخطط شريطي قياسي (ينتج أشرطة مكدسة لمخرجات متعددة الفئات):
shap . plots . bar ( shap_values )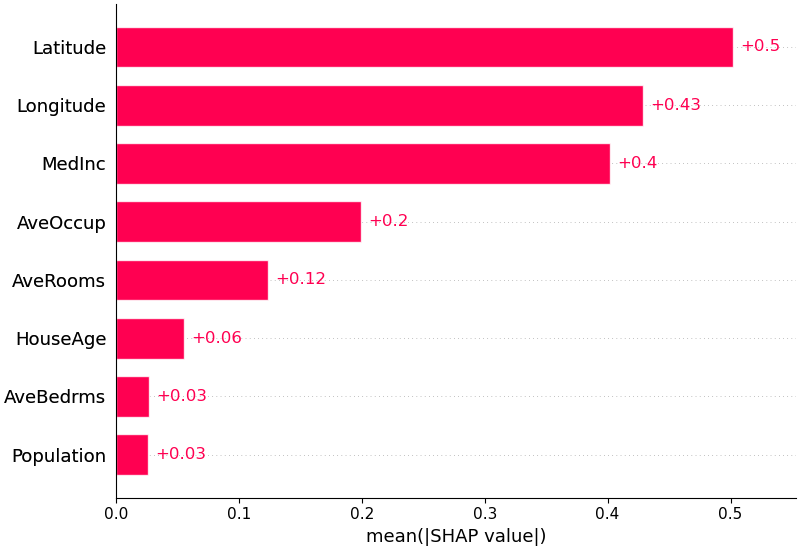
يتمتع SHAP بدعم خاص لنماذج اللغة الطبيعية مثل تلك الموجودة في مكتبة محولات Hugging Face. من خلال إضافة قواعد ائتلافية إلى قيم شابلي التقليدية، يمكننا تشكيل ألعاب تشرح نموذج البرمجة اللغوية العصبية الحديث الكبير باستخدام عدد قليل جدًا من تقييمات الوظائف. يعد استخدام هذه الوظيفة أمرًا بسيطًا مثل تمرير خط أنابيب محولات مدعوم إلى SHAP:
import transformers
import shap
# load a transformers pipeline model
model = transformers . pipeline ( 'sentiment-analysis' , return_all_scores = True )
# explain the model on two sample inputs
explainer = shap . Explainer ( model )
shap_values = explainer ([ "What a great movie! ...if you have no taste." ])
# visualize the first prediction's explanation for the POSITIVE output class
shap . plots . text ( shap_values [ 0 , :, "POSITIVE" ])Deep SHAP عبارة عن خوارزمية تقريبية عالية السرعة لقيم SHAP في نماذج التعلم العميق التي تعتمد على الاتصال مع DeepLIFT الموضح في ورقة SHAP NIPS. يختلف التنفيذ هنا عن DeepLIFT الأصلي عن طريق استخدام توزيع عينات الخلفية بدلاً من قيمة مرجعية واحدة، واستخدام معادلات شابلي لجعل المكونات خطية مثل الحد الأقصى، والسوفت ماكس، والمنتجات، والأقسام، وما إلى ذلك. لاحظ أنه تم أيضًا إدخال بعض هذه التحسينات منذ دمجها في DeepLIFT. يتم دعم نماذج TensorFlow ونماذج Keras التي تستخدم الواجهة الخلفية TensorFlow (يوجد أيضًا دعم أولي لـ PyTorch):
# ...include code from https://github.com/keras-team/keras/blob/master/examples/demo_mnist_convnet.py
import shap
import numpy as np
# select a set of background examples to take an expectation over
background = x_train [ np . random . choice ( x_train . shape [ 0 ], 100 , replace = False )]
# explain predictions of the model on four images
e = shap . DeepExplainer ( model , background )
# ...or pass tensors directly
# e = shap.DeepExplainer((model.layers[0].input, model.layers[-1].output), background)
shap_values = e . shap_values ( x_test [ 1 : 5 ])
# plot the feature attributions
shap . image_plot ( shap_values , - x_test [ 1 : 5 ])يشرح المخطط أعلاه عشرة مخرجات (الأرقام من 0 إلى 9) لأربع صور مختلفة. تعمل وحدات البكسل الحمراء على زيادة مخرجات النموذج بينما تعمل وحدات البكسل الزرقاء على تقليل المخرجات. تظهر الصور المدخلة على اليسار، وخلف كل تفسير من الشروحات بدعائم ذات تدرج رمادي شفاف تقريبًا. يساوي مجموع قيم SHAP الفرق بين مخرجات النموذج المتوقعة (التي تم حساب متوسطها على مجموعة بيانات الخلفية) ومخرجات النموذج الحالية. لاحظ أنه بالنسبة للصورة "صفر" فإن الوسط الفارغ مهم، بينما بالنسبة للصورة "الأربعة" فإن عدم وجود اتصال في الأعلى يجعلها أربعة بدلاً من تسعة.
تجمع التدرجات المتوقعة أفكارًا من التدرجات المتكاملة وSHAP وSmothGrad في معادلة قيمة متوقعة واحدة. يسمح هذا باستخدام مجموعة بيانات كاملة كتوزيع الخلفية (على عكس قيمة مرجعية واحدة) ويسمح بالتجانس المحلي. إذا قمنا بتقريب النموذج بوظيفة خطية بين كل عينة بيانات خلفية والمدخل الحالي المراد شرحه، وافترضنا أن ميزات الإدخال مستقلة، فإن التدرجات المتوقعة ستحسب قيم SHAP التقريبية. في المثال أدناه، أوضحنا كيف تؤثر الطبقة المتوسطة السابعة لنموذج VGG16 ImageNet على احتمالات الإخراج.
from keras . applications . vgg16 import VGG16
from keras . applications . vgg16 import preprocess_input
import keras . backend as K
import numpy as np
import json
import shap
# load pre-trained model and choose two images to explain
model = VGG16 ( weights = 'imagenet' , include_top = True )
X , y = shap . datasets . imagenet50 ()
to_explain = X [[ 39 , 41 ]]
# load the ImageNet class names
url = "https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json"
fname = shap . datasets . cache ( url )
with open ( fname ) as f :
class_names = json . load ( f )
# explain how the input to the 7th layer of the model explains the top two classes
def map2layer ( x , layer ):
feed_dict = dict ( zip ([ model . layers [ 0 ]. input ], [ preprocess_input ( x . copy ())]))
return K . get_session (). run ( model . layers [ layer ]. input , feed_dict )
e = shap . GradientExplainer (
( model . layers [ 7 ]. input , model . layers [ - 1 ]. output ),
map2layer ( X , 7 ),
local_smoothing = 0 # std dev of smoothing noise
)
shap_values , indexes = e . shap_values ( map2layer ( to_explain , 7 ), ranked_outputs = 2 )
# get the names for the classes
index_names = np . vectorize ( lambda x : class_names [ str ( x )][ 1 ])( indexes )
# plot the explanations
shap . image_plot ( shap_values , to_explain , index_names ) تم توضيح التوقعات الخاصة بصورتين مدخلتين في المخطط أعلاه. تمثل البيكسلات الحمراء قيم SHAP الموجبة التي تزيد من احتمالية الفئة، بينما تمثل البيكسلات الزرقاء قيم SHAP السالبة التي تقلل من احتمالية الفئة. باستخدام ranked_outputs=2 نشرح فقط الفئتين الأكثر احتمالية لكل إدخال (وهذا يعفينا من شرح جميع الفئات الـ 1000).
يستخدم Kernel SHAP انحدارًا خطيًا محليًا مرجحًا بشكل خاص لتقدير قيم SHAP لأي نموذج. يوجد أدناه مثال بسيط لشرح SVM متعدد الفئات في مجموعة بيانات القزحية الكلاسيكية.
import sklearn
import shap
from sklearn . model_selection import train_test_split
# print the JS visualization code to the notebook
shap . initjs ()
# train a SVM classifier
X_train , X_test , Y_train , Y_test = train_test_split ( * shap . datasets . iris (), test_size = 0.2 , random_state = 0 )
svm = sklearn . svm . SVC ( kernel = 'rbf' , probability = True )
svm . fit ( X_train , Y_train )
# use Kernel SHAP to explain test set predictions
explainer = shap . KernelExplainer ( svm . predict_proba , X_train , link = "logit" )
shap_values = explainer . shap_values ( X_test , nsamples = 100 )
# plot the SHAP values for the Setosa output of the first instance
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ][ 0 ,:], X_test . iloc [ 0 ,:], link = "logit" )يوضح الشرح أعلاه أربع ميزات تساهم كل منها في دفع مخرجات النموذج من القيمة الأساسية (متوسط مخرجات النموذج عبر مجموعة بيانات التدريب التي مررناها) نحو الصفر. إذا كانت هناك أي ميزات تدفع تسمية الفصل إلى أعلى، فسيتم عرضها باللون الأحمر.
إذا أخذنا العديد من التفسيرات مثل تلك الموضحة أعلاه، وقمنا بتدويرها بمقدار 90 درجة، ثم قمنا بتجميعها أفقيًا، فيمكننا رؤية تفسيرات لمجموعة بيانات بأكملها. وهذا هو بالضبط ما نقوم به أدناه لجميع الأمثلة في مجموعة اختبار القزحية:
# plot the SHAP values for the Setosa output of all instances
shap . force_plot ( explainer . expected_value [ 0 ], shap_values [ 0 ], X_test , link = "logit" ) قيم تفاعل SHAP هي تعميم لقيم SHAP على تفاعلات ذات ترتيب أعلى. يتم تنفيذ حساب سريع ودقيق للتفاعلات الزوجية لنماذج الشجرة باستخدام shap.TreeExplainer(model).shap_interaction_values(X) . يؤدي هذا إلى إرجاع مصفوفة لكل تنبؤ، حيث تكون التأثيرات الرئيسية على القطر وتكون تأثيرات التفاعل خارج القطر. غالبًا ما تكشف هذه القيم عن علاقات مخفية مثيرة للاهتمام، مثل كيف أن خطر الوفاة المتزايد يصل إلى ذروته بالنسبة للرجال في سن 60 عامًا (راجع دفتر NHANES للحصول على التفاصيل):
توضح دفاتر الملاحظات أدناه حالات استخدام مختلفة لـ SHAP. ابحث داخل دليل دفاتر الملاحظات في المستودع إذا كنت تريد تجربة اللعب باستخدام دفاتر الملاحظات الأصلية بنفسك.
تطبيق Tree SHAP، وهي خوارزمية سريعة ودقيقة لحساب قيم SHAP للأشجار ومجموعات الأشجار.
نموذج البقاء على قيد الحياة NHANES مع قيم تفاعل XGBoost وSHAP - باستخدام بيانات الوفيات من 20 عامًا من المتابعة، يوضح هذا الدفتر كيفية استخدام XGBoost و shap للكشف عن علاقات عوامل الخطر المعقدة.
تصنيف دخل التعداد السكاني باستخدام LightGBM - باستخدام مجموعة بيانات دخل التعداد السكاني القياسية للبالغين، يقوم هذا الكمبيوتر الدفتري بتدريب نموذج شجرة تعزيز التدرج باستخدام LightGBM ثم يشرح التنبؤات باستخدام shap .
League of Legends Win Prediction مع XGBoost - باستخدام مجموعة بيانات Kaggle المكونة من 180.000 مباراة مصنفة من League of Legends، نقوم بتدريب وشرح نموذج شجرة التدرج المعزز باستخدام XGBoost للتنبؤ بما إذا كان اللاعب سيفوز بمباراته.
تطبيق Deep SHAP، وهي خوارزمية أسرع (لكن تقريبية فقط) لحساب قيم SHAP لنماذج التعلم العميق التي تعتمد على الاتصالات بين SHAP وخوارزمية DeepLIFT.
تصنيف أرقام MNIST باستخدام Keras - باستخدام مجموعة بيانات التعرف على خط اليد MNIST، يقوم هذا الكمبيوتر الدفتري بتدريب شبكة عصبية باستخدام Keras ثم يشرح التنبؤات باستخدام shap .
Keras LSTM لتصنيف مشاعر IMDB - يقوم هذا الكمبيوتر الدفتري بتدريب LSTM مع Keras على مجموعة بيانات تحليل مشاعر النص IMDB ثم يشرح التنبؤات باستخدام shap .
تنفيذ التدرجات المتوقعة لتقريب قيم SHAP لنماذج التعلم العميق. يعتمد على الاتصالات بين SHAP وخوارزمية التدرجات المتكاملة. GradientExplainer أبطأ من DeepExplainer ويقوم بافتراضات تقريبية مختلفة.
بالنسبة للنموذج الخطي ذو الميزات المستقلة، يمكننا تحليل قيم SHAP الدقيقة. يمكننا أيضًا حساب ارتباط الميزات إذا كنا على استعداد لتقدير مصفوفة التغاير المشترك للميزات. يدعم LinearExplainer كلا الخيارين.
تطبيق Kernel SHAP، وهي طريقة غير محددة لتقدير قيم SHAP لأي نموذج. نظرًا لأنه لا يقدم أي افتراضات حول نوع النموذج، فإن KernelExplainer أبطأ من الخوارزميات الأخرى المحددة لنوع النموذج.
تصنيف دخل التعداد السكاني باستخدام scikit-learn - باستخدام مجموعة بيانات دخل التعداد السكاني القياسية للبالغين، يقوم هذا الكمبيوتر الدفتري بتدريب مصنف الجيران الأقرب إلى k باستخدام scikit-learn ثم يشرح التنبؤات باستخدام shap .
نموذج ImageNet VGG16 مع Keras - شرح تنبؤات الشبكة العصبية التلافيفية الكلاسيكية VGG16 للصورة. يعمل هذا من خلال تطبيق طريقة Kernel SHAP النموذجية على صورة مجزأة فائقة البكسل.
تصنيف القزحية - عرض أساسي باستخدام مجموعة بيانات أنواع القزحية الشائعة. وهو يشرح التنبؤات من ستة نماذج مختلفة في scikit-Learn باستخدام shap .
توضح دفاتر الملاحظات هذه بشكل شامل كيفية استخدام وظائف وكائنات محددة.
shap.decision_plot و shap.multioutput_decision_plot
shap.dependence_plot
لايم: ريبيرو، ماركو توليو، سمير سينغ، وكارلوس جيسترين. "لماذا يجب أن أثق بك؟: شرح تنبؤات أي مصنف." وقائع المؤتمر الدولي الثاني والعشرون لـ ACM SIGKDD حول اكتشاف المعرفة واستخراج البيانات. ايه سي ام، 2016.
قيم أخذ عينات شابلي: سترومبيلج وإريك وإيجور كونونينكو. "شرح نماذج التنبؤ والتنبؤات الفردية مع مساهمات مميزة." نظم المعرفة والمعلومات 41.3 (2014): 647-665.
DeepLIFT: شريكومار، وأفانتي، وبيتون جرينسايد، وأنشول كونداجي. "تعلم الميزات المهمة من خلال نشر اختلافات التنشيط." arXiv طبعة أولية arXiv:1704.02685 (2017).
QII: داتا، أنوبام، شاياك سين، ويائير زيك. "الشفافية الخوارزمية عبر تأثير المدخلات الكمية: النظرية والتجارب مع أنظمة التعلم." الأمن والخصوصية (SP)، ندوة IEEE لعام 2016. معهد مهندسي الكهرباء والإلكترونيات، 2016.
نشر الصلة بالطبقة: باخ، سيباستيان، وآخرون. "حول التفسيرات المتعلقة بالبكسل لقرارات المصنف غير الخطية عن طريق نشر الصلة بالطبقة." بلوس وان 10.7 (2015): e0130140.
قيم انحدار شابلي: ليبوفيتسكي، ستان، ومايكل كونكلين. "تحليل الانحدار في نهج نظرية اللعبة." النماذج العشوائية التطبيقية في الأعمال والصناعة 17.4 (2001): 319-330.
مترجم الشجرة: ساباص، أندو. تفسير الغابات العشوائية. http://blog.datadive.net/interpreting-random-forests/
الخوارزميات والتصورات المستخدمة في هذه الحزمة جاءت في المقام الأول من الأبحاث التي أجريت في مختبر Su-In Lee بجامعة واشنطن، وأبحاث Microsoft. إذا كنت تستخدم SHAP في بحثك، فسنكون ممتنين للإشارة إلى الورقة (الأوراق) المناسبة:
force_plot والتطبيقات الطبية، يمكنك قراءة/الاستشهاد بمقالة Nature Biomedical Engineering (bibtex؛ الوصول المجاني).

