[ورقة] [صفحة المشروع] [نموذج miniFLUX] [نموذج SD3 ⚡️] [عرض توضيحي؟]
هذا هو المستودع الرسمي لـ Pyramid Flow، وهي طريقة إنشاء فيديو ذات انحدار تلقائي فعالة في التدريب تعتمد على مطابقة التدفق . من خلال التدريب فقط على مجموعات البيانات مفتوحة المصدر ، يمكنه إنشاء مقاطع فيديو عالية الجودة مدتها 10 ثوانٍ بدقة 768 بكسل و24 إطارًا في الثانية، ويدعم بشكل طبيعي إنشاء صورة إلى فيديو.
| 10 ثوانٍ، 768 بكسل، 24 إطارًا في الثانية | 5ث، 768 بكسل، 24 إطارًا في الثانية | صورة إلى فيديو |
|---|---|---|
الألعاب النارية.mp4 | مقطورة.mp4 | Sunday.mp4 |
2024.11.13 نقوم بتحرير نقطة تفتيش 768p miniFLUX (حتى 10 ثوانٍ).
لقد قمنا بتحويل بنية النموذج من SD3 إلى mini FLUX لإصلاح مشكلات البنية البشرية، يرجى تجربة نقطة تفتيش الصورة بدقة 1024 بكسل ونقطة تفتيش الفيديو بدقة 384 بكسل (حتى 5 ثوانٍ) ونقطة تفتيش الفيديو بدقة 768 بكسل (حتى 10 ثوانٍ). يُظهر نموذج miniflux الجديد تحسنًا كبيرًا في البنية البشرية واستقرار الحركة
2024.10.29 ⚡️⚡️⚡️ قمنا بإصدار كود التدريب لـ VAE، وكود الضبط الدقيق لـ DiT ونقاط التفتيش النموذجية الجديدة مع هيكل FLUX المدرب من الصفر.
2024.10.13 يتم دعم استدلال وحدات معالجة الرسومات المتعددة وتفريغ وحدة المعالجة المركزية. استخدمه مع ذاكرة GPU أقل من 8 جيجابايت ، مع سرعة كبيرة على وحدات معالجة الرسومات المتعددة.
2024.10.11 ؟؟؟ عرض Hugging Face متاح. شكرًا @multimodalart على الالتزام!
2024.10.10 نصدر التقرير الفني وصفحة المشروع ونقطة التفتيش النموذجية لـ Pyramid Flow.
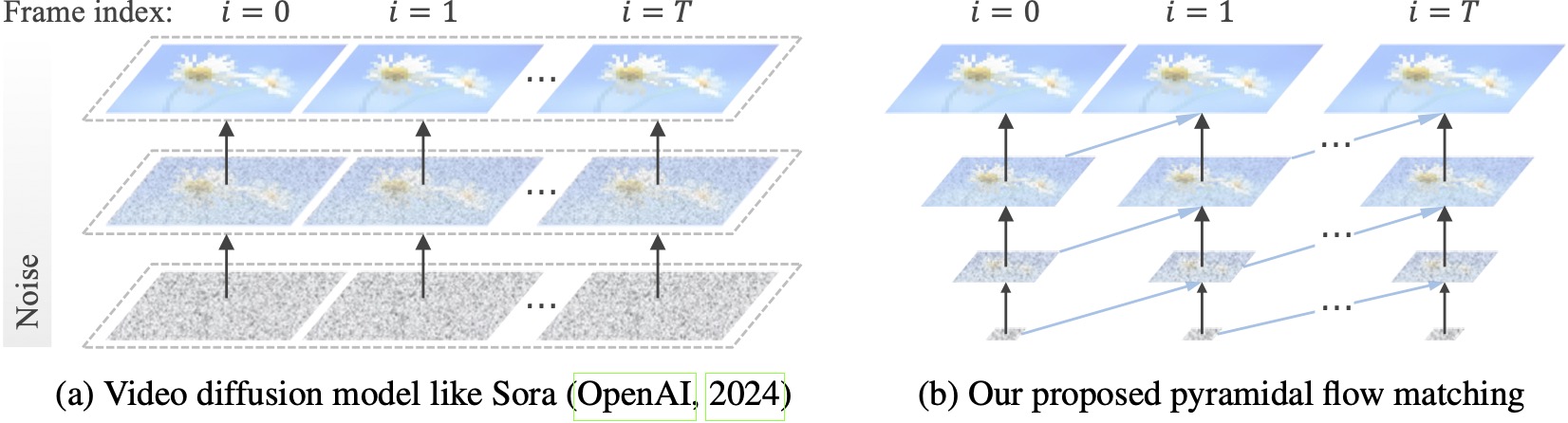
تعمل نماذج نشر الفيديو الحالية بدقة كاملة، وتنفق الكثير من العمليات الحسابية على كامنة شديدة الضجيج. على النقيض من ذلك، تستفيد طريقتنا من مرونة مطابقة التدفق (Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023) للاستيفاء بين العناصر الكامنة ذات الدقة ومستويات الضوضاء المختلفة، مما يسمح بالتوليد المتزامن و تخفيف ضغط المحتوى المرئي بكفاءة حسابية أفضل. تم تحسين الإطار بأكمله من البداية إلى النهاية باستخدام DiT واحد (Peebles & Xie, 2023)، مما يؤدي إلى إنشاء مقاطع فيديو عالية الجودة مدتها 10 ثوانٍ بدقة 768 بكسل و24 إطارًا في الثانية خلال 20.7 ألف ساعة تدريب على وحدة معالجة الرسومات A100.
نوصي بإعداد البيئة باستخدام conda. تستخدم قاعدة التعليمات البرمجية حاليًا Python 3.8.10 وPyTorch 2.1.2 (الدليل)، ونحن نعمل بنشاط لدعم نطاق أوسع من الإصدارات.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtبعد ذلك، قم بتنزيل النموذج من Huggingface (يوجد نوعان مختلفان: miniFLUX أو SD3). تدعم طرازات miniFLUX إنشاء صور بدقة 1024 بكسل وفيديو بدقة 384 بكسل و768 بكسل، وتدعم الطرازات المعتمدة على SD3 إنشاء فيديو بدقة 768 بكسل و384 بكسل. تولد نقطة التفتيش 384 بكسل فيديو مدته 5 ثوانٍ بمعدل 24 إطارًا في الثانية، بينما تولد نقطة التفتيش 768 بكسل ما يصل إلى 10 ثوانٍ بمعدل 24 إطارًا في الثانية.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )للبدء، قم أولاً بتثبيت Gradio، ثم قم بتعيين مسار النموذج الخاص بك على #L36، ثم قم بتشغيله على جهازك المحلي:
python app.pyسيتم فتح العرض التوضيحي لـ Gradio في المتصفح. بفضل @tpc2233 الالتزام، راجع رقم 48 للحصول على التفاصيل.
أو جربه دون عناء على Hugging Face Space؟ تم إنشاؤها بواسطة @multimodalart. نظرًا لقيود وحدة معالجة الرسومات، يمكن لهذا العرض التوضيحي عبر الإنترنت إنشاء 25 إطارًا فقط (التصدير بمعدل 8 إطارًا في الثانية أو 24 إطارًا في الثانية). قم بتكرار المساحة لإنشاء مقاطع فيديو أطول.
لتجربة Pyramid Flow على Google Colab بسرعة، قم بتشغيل الكود أدناه:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
لاستخدام نموذجنا، يرجى اتباع رمز الاستدلال الموجود في video_generation_demo.ipynb على هذا الرابط. نحن ننصحك بشدة بتجربة أحدث إصدار من الهرم المصغر، والذي يُظهر تحسنًا كبيرًا في البنية البشرية واستقرار الحركة. قم بتعيين المعلمة model_name على pyramid_flux المراد استخدامها. نقوم بتبسيط الأمر أيضًا في الإجراء التالي المكون من خطوتين. أولاً، قم بتحميل النموذج الذي تم تنزيله:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()وبعد ذلك، يمكنك تجربة إنشاء تحويل النص إلى فيديو وفقًا للمطالبات الخاصة بك. مع ملاحظة أن الإصدار 384p يدعم فقط 5s الآن (اضبط درجة الحرارة على 16)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )كنموذج انحدار ذاتي، يدعم نموذجنا أيضًا إنشاء صورة إلى فيديو (نص مشروط):
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )نحن ندعم أيضًا نوعين من تفريغ وحدة المعالجة المركزية لتقليل متطلبات ذاكرة وحدة معالجة الرسومات. لاحظ أنهم قد يضحون بالكفاءة.
cpu_offloading=True المعلمة إلى وظيفة الإنشاء بالاستدلال باستخدام ذاكرة GPU أقل من 12 جيجابايت . هذه الميزة ساهم بها @Ednaordinary، راجع رقم 23 للحصول على التفاصيل.model.enable_sequential_cpu_offload() قبل الإجراء أعلاه إلى السماح بالاستدلال باستخدام ذاكرة GPU أقل من 8 جيجابايت . هذه الميزة ساهم بها @rodjjo، انظر رقم 75 للحصول على التفاصيل. بفضل @niw، يمكن لمستخدمي Apple Silicon (مثل MacBook Pro المزود بـ M2 24GB) أيضًا تجربة نموذجنا باستخدام الواجهة الخلفية MPS! راجع رقم 113 لمزيد من التفاصيل.
بالنسبة للمستخدمين الذين لديهم وحدات معالجة رسومات متعددة، فإننا نقدم نصًا استدلاليًا يستخدم التوازي التسلسلي لحفظ الذاكرة على كل وحدة معالجة رسومات. يوفر هذا أيضًا سرعة كبيرة، حيث يستغرق 2.5 دقيقة فقط لإنشاء فيديو بدقة 5 ثوانٍ و768 بكسل و24 إطارًا في الثانية على 4 وحدات معالجة رسوميات A100 (مقابل 5.5 دقيقة على وحدة معالجة رسومات A100 واحدة). قم بتشغيله على وحدتي GPU باستخدام الأمر التالي:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shوهو يدعم حاليًا وحدتين أو أربع وحدات معالجة رسوميات (لإصدار SD3)، مع توفر المزيد من التكوينات في البرنامج النصي الأصلي. يمكنك أيضًا تشغيل عرض توضيحي لوحدة معالجة الرسومات المتعددة Gradio تم إنشاؤه بواسطة @tpc2233، راجع رقم 59 للحصول على التفاصيل.
حرق: لم نستخدم حتى توازي التسلسل في التدريب، وذلك بفضل تصميماتنا الهرمية الفعالة.
guidance_scale في الجودة المرئية. نقترح استخدام الإرشادات ضمن [7، 9] لنقطة تفتيش 768p أثناء إنشاء تحويل النص إلى فيديو، و7 لنقطة تفتيش 384p.video_guidance_scale في الحركة. تزيد القيمة الأكبر من الدرجة الديناميكية وتخفف من تدهور توليد الانحدار الذاتي، بينما تعمل القيمة الأصغر على تثبيت الفيديو.متطلبات الأجهزة لتدريب VAE هي 8 وحدات معالجة رسوميات A100 على الأقل. يرجى الرجوع إلى هذه الوثيقة. هذا هو MAGVIT-v2 مثل VAE ثلاثي الأبعاد المستمر، والذي يجب أن يكون مرنًا تمامًا. لا تتردد في إنشاء نموذج الفيديو الخاص بك على هذا الجزء من كود تدريب VAE.
متطلبات الأجهزة لضبط DiT هي 8 وحدات معالجة رسوميات A100 على الأقل. يرجى الرجوع إلى هذه الوثيقة. نحن نقدم تعليمات لكل من إصدارات الانحدار الذاتي وغير الانحدار الذاتي من Pyramid Flow. الأول أكثر توجهاً نحو البحث والثاني أكثر استقرارًا (ولكنه أقل كفاءة بدون الهرم الزمني).
يتم إنشاء أمثلة الفيديو التالية بسرعة 5 ثوانٍ، و768 بكسل، و24 إطارًا في الثانية. لمزيد من النتائج، يرجى زيارة صفحة مشروعنا.
tokyo.mp4 | eiffel.mp4 |
wave.mp4 | السكك الحديدية.mp4 |
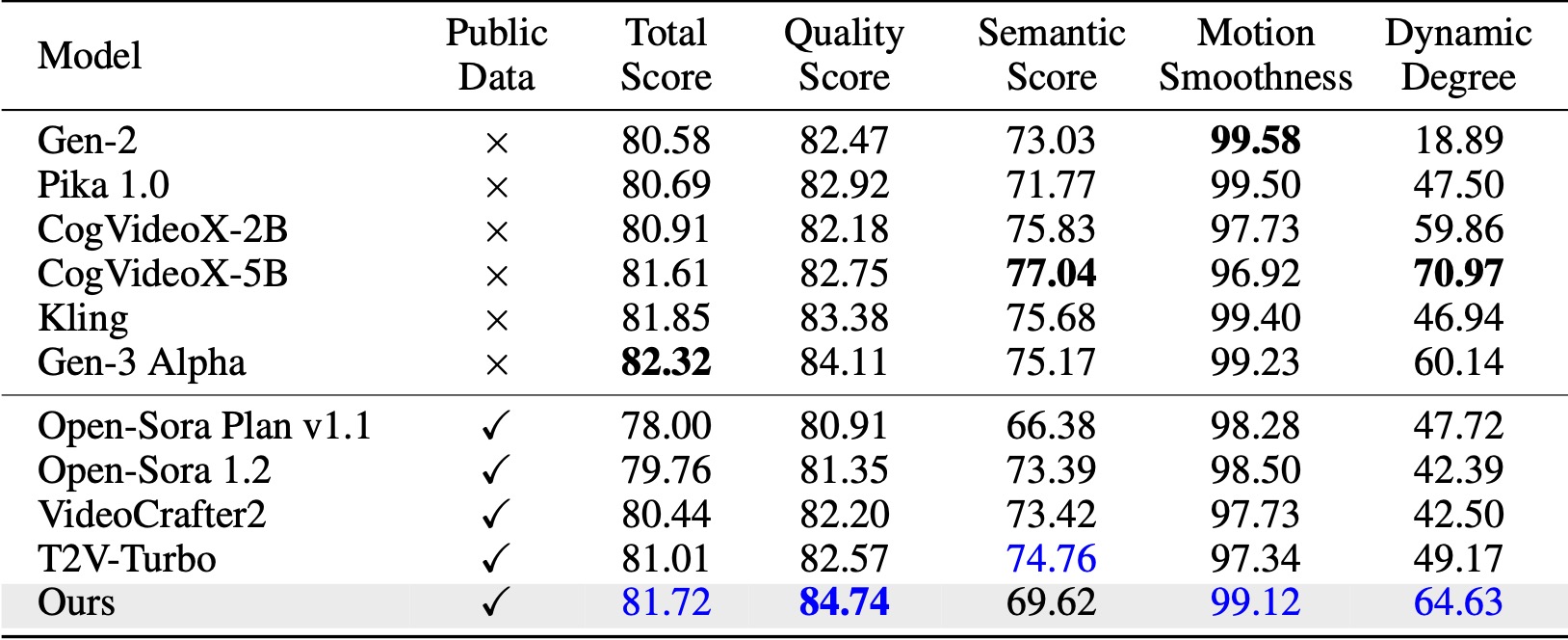
في VBench (Huang et al., 2024)، تتفوق طريقتنا على جميع خطوط الأساس مفتوحة المصدر المقارنة. حتى مع بيانات الفيديو العامة فقط، فإنه يحقق أداءً مشابهًا للنماذج التجارية مثل Kling (Kuaishou، 2024) وGen-3 Alpha (Runway، 2024)، خاصة في نقاط الجودة (84.74 مقابل 84.11 للجيل الثالث) وسلاسة الحركة. .
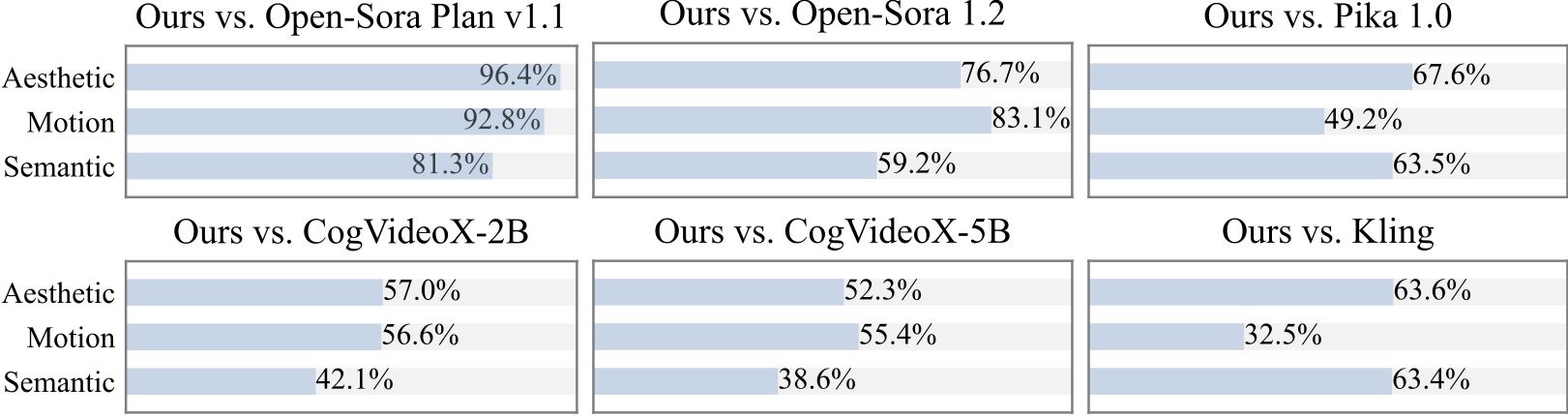
نجري دراسة إضافية للمستخدم مع أكثر من 20 مشاركًا. كما هو واضح، فإن طريقتنا مفضلة على النماذج مفتوحة المصدر مثل Open-Sora وCogVideoX-2B خاصة من حيث سلاسة الحركة.
نحن ممتنون للمشاريع الرائعة التالية عند تنفيذ Pyramid Flow:
فكر في منح هذا المستودع نجمة واستشهد بـ Pyramid Flow في منشوراتك إذا كان ذلك يساعد في بحثك.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


