LARS
v2.0-beta8:

LARS هو تطبيق يمكّنك من تشغيل LLM (نماذج اللغات الكبيرة) محليًا على جهازك، وتحميل مستنداتك الخاصة والمشاركة في المحادثات حيث يؤسس LLM ردوده على المحتوى الذي تم تحميله. يساعد هذا التأريض على زيادة الدقة وتقليل المشكلة الشائعة المتمثلة في عدم الدقة أو "الهلوسة" الناتجة عن الذكاء الاصطناعي. تُعرف هذه التقنية عمومًا باسم "الجيل المعزز للاسترجاع" أو RAG.
هناك العديد من تطبيقات سطح المكتب لتشغيل LLM محليًا، ويهدف LARS إلى أن يكون تطبيق LLM مفتوح المصدر المرتكز على RAG. ولتحقيق هذه الغاية، تأخذ LARS مفهوم RAG إلى أبعد من ذلك بكثير عن طريق إضافة استشهادات مفصلة لكل إجابة، وتزويدك بأسماء مستندات محددة، وأرقام الصفحات، وإبراز النص، والصور ذات الصلة بسؤالك، وحتى تقديم قارئ المستندات مباشرة داخل نافذة الاستجابة. على الرغم من أن جميع الاستشهادات لا تكون موجودة دائمًا لكل استجابة، فإن الفكرة هي أن يكون لديك على الأقل مجموعة من الاستشهادات التي يتم طرحها لكل استجابة من إجابة RAG وهذا هو الحال بشكل عام.
فيديو توضيحي لميزات LARS
بايثون v3.10.x أو أعلى: https://www.python.org/downloads/
بايتورتش:
إذا كنت تخطط لاستخدام وحدة معالجة الرسومات الخاصة بك لتشغيل LLMs، فتأكد من تثبيت برامج تشغيل وحدة معالجة الرسومات ومجموعة أدوات CUDA/ROCm بالشكل المناسب لإعدادك، وبعد ذلك فقط تابع إعداد PyTorch أدناه
قم بتنزيل وتثبيت إصدار PyTorch المناسب لنظامك: https://pytorch.org/get-started/locally/
استنساخ المستودع:
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensتثبيت تبعيات بايثون:
ويندوز عبر PIP:
pip install -r .requirements.txt
لينكس عبر PIP:
pip3 install -r ./requirements.txt
ملاحظة حول Azure: بعض مكتبات Azure المطلوبة غير متوفرة على نظام MacOS الأساسي! لذلك يتم تضمين ملف متطلبات منفصل لنظام التشغيل MacOS باستثناء هذه المكتبات:
ماك:
pip3 install -r ./requirements_mac.txt
العودة إلى جدول المحتويات
بعد التثبيت، قم بتشغيل LARS باستخدام:
cd web_app
python app.py # Use 'python3' on Linux/macOS
انتقل إلى http://localhost:5000/ في متصفحك
سيتم الآن إنشاء كافة أدلة التطبيقات التي تتطلبها LARS على القرص
سيبدأ خادم HF-Waitress تلقائيًا وسيقوم بتنزيل LLM (Microsoft Phi-3-Mini-Instruct-44) عند التشغيل لأول مرة، الأمر الذي قد يستغرق بعض الوقت اعتمادًا على سرعة اتصالك بالإنترنت
عند الاستعلام الأول، سيتم تنزيل نموذج التضمين (all-mpnet-base-v2) من HuggingFace Hub، والذي من المفترض أن يستغرق وقتًا قصيرًا
العودة إلى جدول المحتويات
على نظام التشغيل Windows:
قم بتنزيل Microsoft Visual Studio Build Tools 2022 من الموقع الرسمي - "Tools for Visual Studio"
ملاحظة: عند تثبيت ما ورد أعلاه، تأكد من تحديد المكونات التالية:
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
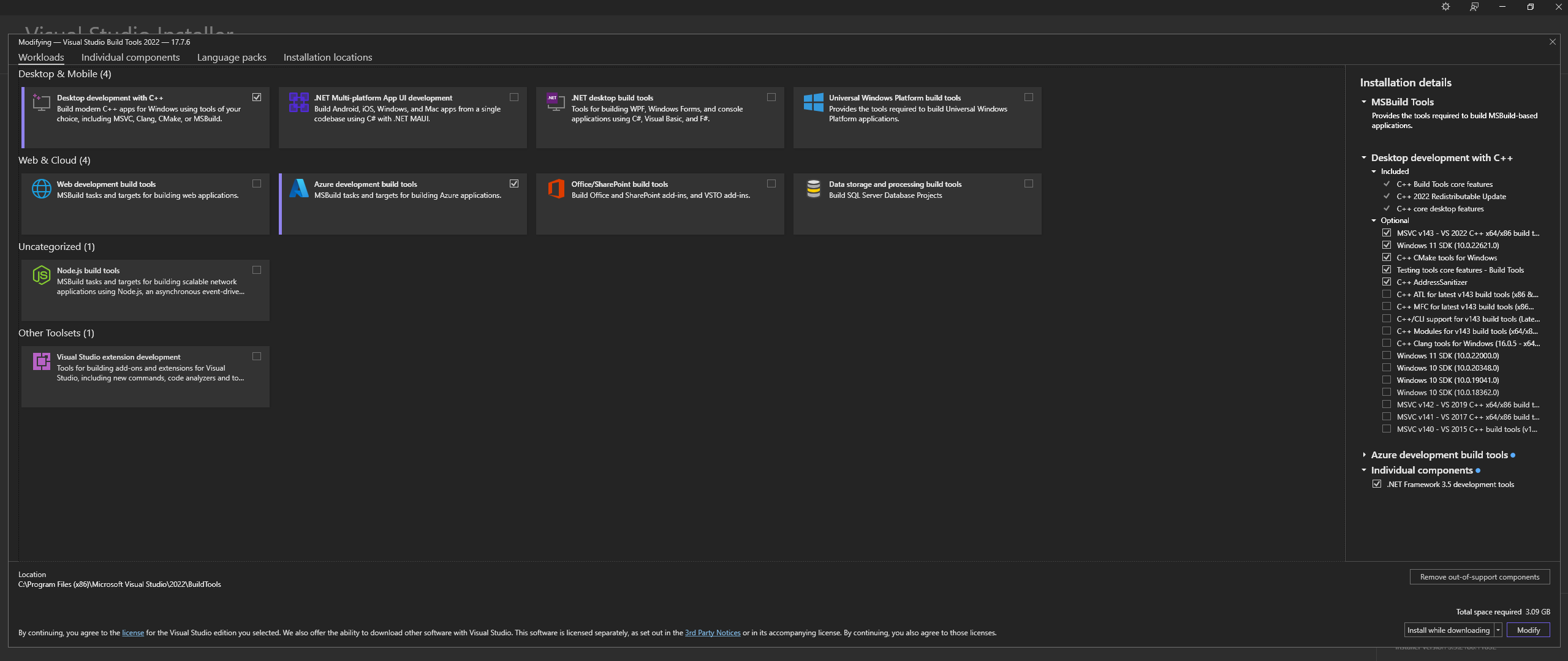
Desktop development with C++ واختيارات MSVC and C++ CMake الاختيارية كما هو موضح أعلاهعلى Linux (المستند إلى Ubuntu وDebian)، قم بتثبيت الحزم التالية:
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
تحميل من الريبو الرسمي:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
قم بتثبيت CMAKE على نظام التشغيل Windows من الموقع الرسمي
C:Program FilesCMakebinإنشاء llama.cpp باستخدام CMAKE:
ملاحظة: لتجميع أسرع، أضف الوسيطة -j لتشغيل مهام متعددة بالتوازي. على سبيل المثال، cmake --build build --config Release -j 8 سوف يقوم بتشغيل 8 مهام بالتوازي.
البناء باستخدام CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
إذا واجهت مشكلات عند محاولة تشغيل CMake -B build ، فراجع الخطوات الشاملة لاستكشاف أخطاء تثبيت CMake وإصلاحها أدناه
إضافة إلى المسار:
path_to_cloned_repollama.cppbuildbinRelease
التحقق من التثبيت عبر المحطة:
llama-server
قم بتثبيت برامج تشغيل Nvidia GPU
قم بتثبيت مجموعة أدوات Nvidia CUDA - تم تصميم LARS واختبارها باستخدام الإصدارين 12.2 و12.4
التحقق من التثبيت عبر المحطة:
nvcc -V
nvidia-smi
إصلاح CMAKE-CUDA (مهم جدًا!):
انسخ جميع الملفات الأربعة من الدليل التالي:
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
والصقها في الدليل التالي:
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
هذه تبعية اختيارية، ولكن يوصى بها بشدة - يتم دعم ملفات PDF فقط إذا لم يكتمل هذا الإعداد
ويندوز:
تحميل من الموقع الرسمي
أضف إلى PATH، إما عبر:
إعدادات النظام المتقدمة -> متغيرات البيئة -> متغيرات النظام -> تحرير متغير المسار -> أضف ما يلي (قم بالتغيير حسب موقع التثبيت):
C:Program FilesLibreOfficeprogram
أو عبر PowerShell:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Linux المستند إلى Ubuntu وDebian - قم بالتنزيل من الموقع الرسمي أو التثبيت عبر المحطة الطرفية:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora والتوزيعات الأخرى المستندة إلى RPM - قم بالتنزيل من الموقع الرسمي أو التثبيت عبر المحطة الطرفية:
sudo dnf update
sudo dnf install libreoffice
MacOS - قم بالتنزيل من الموقع الرسمي أو التثبيت عبر Homebrew:
brew install --cask libreoffice
التحقق من التثبيت:
على نظامي التشغيل Windows وMacOS: قم بتشغيل تطبيق LibreOffice
على Linux عبر المحطة:
libreoffice --version
يستخدم LARS مكتبة pdf2image Python لتحويل كل صفحة من المستند إلى صورة كما هو مطلوب للتعرف الضوئي على الحروف. هذه المكتبة هي في الأساس عبارة عن غلاف حول الأداة المساعدة Poppler التي تتولى عملية التحويل.
ويندوز:
تحميل من الريبو الرسمي
أضف إلى PATH، إما عبر:
إعدادات النظام المتقدمة -> متغيرات البيئة -> متغيرات النظام -> تحرير متغير المسار -> أضف ما يلي (قم بالتغيير حسب موقع التثبيت):
path_to_installationpoppler_versionLibrarybin
أو عبر PowerShell:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
لينكس:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
هذه تبعية اختيارية - لا يتم استخدام Tesseract-OCR بشكل نشط في LARS ولكن طرق استخدامها موجودة في الكود المصدري
ويندوز:
قم بتنزيل Tesseract-OCR لنظام التشغيل Windows عبر UB-Mannheim
أضف إلى PATH، إما عبر:
إعدادات النظام المتقدمة -> متغيرات البيئة -> متغيرات النظام -> تحرير متغير المسار -> أضف ما يلي (قم بالتغيير حسب موقع التثبيت):
C:Program FilesTesseract-OCR
أو عبر PowerShell:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
العودة إلى جدول المحتويات
تم إنشاء LARS واختباره باستخدام Python v3.11.x
تثبيت Python v3.11.x على نظام التشغيل Windows:
قم بتنزيل الإصدار 3.11.9 من الموقع الرسمي
أثناء التثبيت، تأكد من تحديد "إضافة Python 3.11 إلى PATH" أو إضافته يدويًا لاحقًا، إما عبر:
إعدادات النظام المتقدمة -> متغيرات البيئة -> متغيرات النظام -> تحرير متغير المسار -> أضف ما يلي (قم بالتغيير حسب موقع التثبيت):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
أو عبر PowerShell:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
قم بتثبيت Python v3.11.x على Linux (المستند إلى Ubuntu وDebian):
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
التحقق من التثبيت عبر المحطة:
python3 --version
إذا واجهت أخطاء أثناء pip install ، فجرّب ما يلي:
إزالة أرقام الإصدارات:
==version.number ، على سبيل المثال:urllib3==2.0.4urllib3إنشاء واستخدام بيئة بايثون الافتراضية:
يُنصح باستخدام بيئة افتراضية لتجنب التعارض مع مشاريع بايثون الأخرى
ويندوز:
إنشاء بيئة بايثون الافتراضية (venv):
python -m venv larsenv
قم بتنشيط venv ثم استخدامه:
.larsenvScriptsactivate
قم بإلغاء تنشيط venv عند الانتهاء:
deactivate
لينكس وماك:
إنشاء بيئة بايثون الافتراضية (venv):
python3 -m venv larsenv
قم بتنشيط venv ثم استخدامه:
source larsenv/bin/activate
قم بإلغاء تنشيط venv عند الانتهاء:
deactivate
إذا استمرت المشكلات، فكر في فتح مشكلة في مستودع LARS GitHub للحصول على الدعم.
CMake nmake failed عند محاولة إنشاء llama.cpp كما هو موضح أدناه: 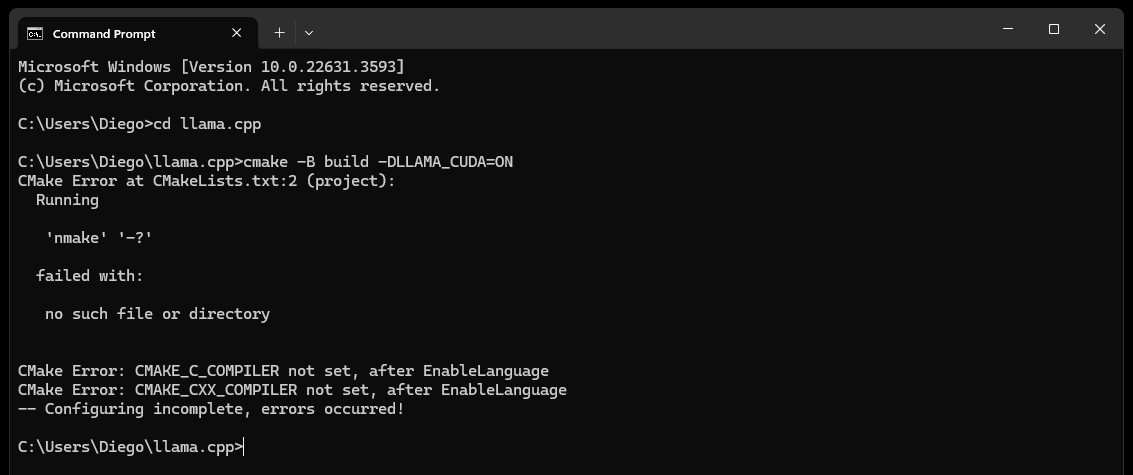
يشير هذا عادةً إلى وجود مشكلة في أدوات إنشاء Microsoft Visual Studio، حيث أن CMake غير قادر على العثور على أداة nmake، التي تعد جزءًا من أدوات إنشاء Microsoft Visual Studio. جرب الخطوات التالية لحل المشكلة:
تأكد من تثبيت أدوات إنشاء Visual Studio:
تأكد من تثبيت أدوات إنشاء Visual Studio، بما في ذلك nmake. يمكنك تثبيت هذه الأدوات من خلال Visual Studio Installer عن طريق تحديد Desktop development with C++ ، واختياريي MSVC and C++ CMake
تحقق من الخطوة 0 من قسم التبعيات، وتحديدًا لقطة الشاشة الموجودة فيه
التحقق من متغيرات البيئة:
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
استخدم موجه أوامر المطور:
افتح "موجه أوامر المطور لبرنامج Visual Studio" الذي يقوم بإعداد متغيرات البيئة الضرورية لك
يمكنك العثور على هذه المطالبة من قائمة "ابدأ" ضمن Visual Studio
تعيين مولد CMake:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
إذا استمرت المشكلات، فكر في فتح مشكلة في مستودع LARS GitHub للحصول على الدعم.
في النهاية (بعد حوالي 60 ثانية) سترى تنبيهًا على الصفحة يشير إلى وجود خطأ:
Failed to start llama.cpp local-server
يشير هذا إلى أن التشغيل الأول قد اكتمل، وتم إنشاء جميع أدلة التطبيق، ولكن لا توجد LLMs في دليل models ويمكن الآن نقلها إليه
انقل LLMs (أي تنسيق ملف يدعمه llama.cpp، ويفضل GGUF) إلى مجلد models الذي تم إنشاؤه حديثًا، والموجود افتراضيًا في المواقع التالية:
C:/web_app_storage/models/app/storage/models/app/models بمجرد قيامك بوضع شهادات LLM الخاصة بك في models المناسبة الموضحة أعلاه، قم بتحديث http://localhost:5000/
ستتلقى مرة أخرى تنبيهًا بالخطأ يفيد Failed to start llama.cpp local-server بعد حوالي 60 ثانية
وذلك لأن شهادة LLM الخاصة بك تحتاج الآن إلى التحديد في قائمة Settings LARS
اقبل التنبيه وانقر على أيقونة ترس Settings في الجزء العلوي الأيسر
في علامة التبويب LLM Selection ، حدد LLM الخاص بك وتنسيق قالب المطالبة المناسب من القوائم المنسدلة المناسبة
قم بتعديل الإعدادات المتقدمة لتعيين خيارات GPU بشكل صحيح، Context-Length ، واختياريًا، حد إنشاء الرمز المميز ( Maximum tokens to predict ) لـ LLM المحدد
اضغط على Save ، وإذا لم يتم تشغيل التحديث التلقائي، فقم بتحديث الصفحة يدويًا
إذا تم تنفيذ جميع الخطوات بشكل صحيح، فهذا يعني أن الإعداد لأول مرة قد اكتمل الآن، وأصبح LARS جاهزًا للاستخدام
سوف يتذكر LARS أيضًا إعدادات LLM الخاصة بك لاستخدامها لاحقًا
العودة إلى جدول المحتويات
تنسيقات المستندات المدعومة:
إذا تم تثبيت LibreOffice وإضافته إلى PATH كما هو مفصل في الخطوة 4 من قسم التبعيات، فسيتم دعم التنسيقات التالية:
إذا لم يتم إعداد LibreOffice، فسيتم دعم ملفات PDF فقط
خيارات التعرف الضوئي على الحروف لاستخراج النص:
يوفر LARS ثلاث طرق لاستخراج النص من المستندات، واستيعاب أنواع المستندات المختلفة وجودتها:
استخراج النص المحلي: يستخدم PyPDF2 لاستخراج النص بكفاءة من ملفات PDF غير الممسوحة ضوئيًا. مثالية للمعالجة السريعة عندما لا تكون الدقة العالية ضرورية، أو عندما تكون المعالجة المحلية بالكامل ضرورية.
Azure ComputerVision OCR - يعزز دقة استخراج النص ويدعم المستندات الممسوحة ضوئيًا. مفيد للتعامل مع تخطيطات المستندات القياسية. تقدم طبقة مجانية مناسبة للتجارب الأولية والاستخدام منخفض الحجم، بحد أقصى 5000 معاملة/الشهر بمعدل 20 معاملة/الدقيقة.
Azure AI Document Intelligence OCR - الأفضل للمستندات ذات الهياكل المعقدة مثل الجداول. يعمل المحلل اللغوي المخصص في LARS على تحسين عملية الاستخراج.
ملحوظات:
تتحمل خيارات Azure OCR تكاليف API في معظم الحالات ولا يتم تجميعها مع LARS.
تتوفر طبقة مجانية محدودة لبرنامج ComputerVision OCR كما هو موضح أعلاه. هذه الخدمة أرخص بشكل عام ولكنها أبطأ وقد لا تعمل مع تخطيطات المستندات غير القياسية (بخلاف A4 وما إلى ذلك).
ضع في اعتبارك أنواع المستندات واحتياجاتك من الدقة عند تحديد خيار التعرف الضوئي على الحروف.
ماجستير في القانون:
يتم دعم شهادات LLM المحلية فقط في الوقت الحالي
توفر قائمة Settings العديد من الخيارات للمستخدم القوي لتكوين LLM وتغييره عبر علامة التبويب LLM Selection
لاحظ في حالة استخدام llama.cpp: هام جدًا: حدد تنسيق قالب المطالبة المناسب لـ LLM الذي تقوم بتشغيله
يتم حاليًا دعم LLMs المدربين على تنسيقات القوالب السريعة التالية عبر llama.cpp:
قم بتعديل إعدادات التكوين الأساسي عبر Advanced Settings (يؤدي إلى إعادة تحميل LLM وتحديث الصفحة):
قم بتعديل الإعدادات لتغيير سلوك الاستجابة في أي وقت:
نماذج التضمين وقاعدة بيانات المتجهات:
يتم توفير أربعة نماذج التضمين في LARS:
باستثناء عمليات تضمين Azure-OpenAI، يتم تشغيل جميع النماذج الأخرى محليًا بالكامل ومجانًا. عند التشغيل لأول مرة، سيتم تنزيل هذه النماذج من HuggingFace Hub. يتم هذا التنزيل لمرة واحدة وسيتم توفيره محليًا لاحقًا.
يمكن للمستخدم التبديل بين نماذج التضمين هذه في أي وقت عبر علامة التبويب VectorDB & Embedding Models في قائمة Settings
جدول Docs-Loaded: في قائمة Settings ، يتم عرض جدول لنموذج التضمين المحدد الذي يعرض قائمة المستندات المضمنة في قاعدة بيانات المتجهات المرتبطة. إذا تم تحميل مستند عدة مرات، فسوف يحتوي على إدخالات متعددة في هذا الجدول، مما قد يكون مفيدًا لتصحيح أي مشكلات.
مسح VectorDB: استخدم زر Reset وقدم تأكيدًا لمسح قاعدة بيانات المتجهات المحددة. يؤدي هذا إلى إنشاء VectorDB جديد على القرص لنموذج التضمين المحدد. لا يزال VectorDB القديم محفوظًا ويمكن الرجوع إليه عن طريق تعديل ملف config.json يدويًا.
تحرير موجه النظام:
يعد موجه النظام بمثابة تعليمات إلى LLM للمحادثة بأكملها
يوفر LARS للمستخدم القدرة على تحرير موجه النظام عبر قائمة Settings عن طريق تحديد الخيار Custom من القائمة المنسدلة في علامة التبويب System Prompt
ستؤدي التغييرات التي يتم إجراؤها على موجه النظام إلى بدء محادثة جديدة
فرض تمكين/تعطيل RAG:
من خلال قائمة Settings ، يجوز للمستخدم فرض تمكين أو تعطيل RAG (إنشاء الاسترجاع المعزز - استخدام المحتوى من مستنداتك لتحسين الاستجابات التي تم إنشاؤها بواسطة LLM) كلما لزم الأمر
غالبًا ما يكون هذا مفيدًا لأغراض تقييم استجابات LLM في كلا السيناريوهين
سيؤدي التعطيل القسري أيضًا إلى إيقاف ميزات الإسناد
يعد الإعداد الافتراضي، الذي يستخدم البرمجة اللغوية العصبية (NLP) لتحديد متى يجب أو لا ينبغي تنفيذ RAG، هو الخيار الموصى به
يمكن تغيير هذا الإعداد في أي وقت
سجل الدردشة:
استخدم قائمة سجل الدردشة في الجزء العلوي الأيسر لتصفح المحادثات السابقة واستئنافها
هام جدًا: انتبه إلى عدم تطابق قالب المطالبة عند استئناف المحادثات السابقة! استخدم أيقونة Information الموجودة في أعلى اليمين للتأكد من أن شهادة LLM المستخدمة في المحادثة السابقة، وشهادة LLM المستخدمة حاليًا، تعتمدان على نفس تنسيقات قالب المطالبة!
تقييم المستخدم:
يمكن للمستخدم تقييم كل إجابة على مقياس مكون من 5 نقاط في أي وقت
يتم تخزين بيانات التقييمات في قاعدة بيانات chat-history.db SQLite3 الموجودة في دليل التطبيق:
C:/web_app_storage/app/storage/appتعتبر بيانات التقييمات ذات قيمة كبيرة لتقييم الأداة وتحسينها لتناسب سير العمل لديك
ما يجب فعله وما لا يجب فعله:
العودة إلى جدول المحتويات
إذا سارت إحدى المحادثات بشكل خاطئ، أو تم إنشاء أي ردود غريبة، فما عليك سوى محاولة بدء New Chat عبر القائمة الموجودة في الجزء العلوي الأيسر
وبدلاً من ذلك، ابدأ محادثة جديدة بمجرد تحديث الصفحة
إذا واجهت مشكلات تتعلق بالاستشهادات أو أداء RAG، فحاول إعادة تعيين VectorDB كما هو موضح في الخطوة 4 من دليل المستخدم العام أعلاه
إذا ظهرت أي مشكلات في التطبيق ولم يتم حلها ببساطة عن طريق بدء محادثة جديدة أو إعادة تشغيل LARS، فحاول حذف ملف config.json باتباع الخطوات التالية:
CTRL+Cconfig.json الموجود في LARS/web_app (نفس الدليل مثل app.py )بالنسبة لأي مشكلات خطيرة تتعلق بالبيانات والاقتباسات والتي لم يتم حلها حتى عن طريق إعادة تعيين VectorDB كما هو موضح في الخطوة 4 من دليل المستخدم العام أعلاه، قم بتنفيذ الخطوات التالية:
CTRL+CC:/web_app_storage/app/storage/appإذا استمرت المشكلات، فكر في فتح مشكلة في مستودع LARS GitHub للحصول على الدعم.
العودة إلى جدول المحتويات
تم تكييف LARS مع بيئة نشر حاوية Docker عبر صورتين منفصلتين على النحو التالي:
كلاهما لهما متطلبات مختلفة، حيث أن الأول عبارة عن نشر أبسط، ولكنه يعاني من أداء استدلالي أبطأ بكثير نظرًا لأن وحدة المعالجة المركزية وذاكرة DDR تعملان كاختناقات
على الرغم من أن ذلك ليس مطلوبًا بشكل صريح، إلا أن بعض الخبرة في التعامل مع حاويات Docker والإلمام بمفاهيم النقل بالحاويات والمحاكاة الافتراضية ستكون مفيدة جدًا في هذا القسم!
البدء بخطوات الإعداد الشائعة لكليهما:
تثبيت عامل الميناء
يجب أن تدعم وحدة المعالجة المركزية لديك المحاكاة الافتراضية ويجب تمكينها في BIOS/UEFI الخاص بنظامك
قم بتنزيل وتثبيت Docker Desktop
إذا كنت تستخدم نظام التشغيل Windows، فقد تحتاج إلى تثبيت نظام Windows الفرعي لنظام التشغيل Linux إذا لم يكن موجودًا بالفعل. للقيام بذلك، افتح PowerShell كمسؤول وقم بتشغيل ما يلي:
wsl --install
تأكد من أن Docker Desktop قيد التشغيل، ثم افتح موجه الأوامر/المحطة الطرفية وقم بتنفيذ الأمر التالي للتأكد من تثبيت Docker وتشغيله بشكل صحيح:
docker ps
قم بإنشاء وحدة تخزين Docker، والتي سيتم ربطها بحاويات LARS في وقت التشغيل:
يعد إنشاء وحدة تخزين للاستخدام مع حاوية LARS مفيدًا للغاية لأنه سيسمح لك بترقية حاوية LARS إلى إصدار أحدث، أو التبديل بين متغيرات حاوية وحدة المعالجة المركزية ووحدة معالجة الرسومات مع الحفاظ على جميع إعداداتك وسجل الدردشة وقواعد بيانات المتجهات بسلاسة .
قم بتنفيذ الأمر التالي في موجه الأوامر/المحطة الطرفية:
docker volume create lars_storage_volue
سيتم إرفاق هذا المجلد بحاوية LARS لاحقًا في وقت التشغيل، تابع الآن إنشاء صورة LARS في الخطوات أدناه.
في موجه الأوامر/المحطة الطرفية، قم بتنفيذ الأوامر التالية:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
بمجرد الانتهاء، انتقل إلى http://localhost:5000/ في متصفحك واتبع باقي خطوات التشغيل الأولى ودليل المستخدم
تنطبق أقسام استكشاف الأخطاء وإصلاحها على Container-LARS أيضًا
المتطلبات (بالإضافة إلى Docker):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
بالنسبة لنظام التشغيل Linux، لقد تم إعدادك تمامًا بما ورد أعلاه، لذا قم بتخطي الخطوة التالية وتوجه مباشرة إلى خطوات الإنشاء والتشغيل أدناه
إذا كنت تستخدم نظام التشغيل Windows، وإذا كانت هذه هي المرة الأولى التي تقوم فيها بتشغيل حاوية Nvidia GPU على Docker، فاستعد لأن هذا سيكون أمرًا رائعًا (المشروب المفضل أو الثلاثة الموصى بها بشدة!)
المخاطرة بالتكرار الشديد، قبل المتابعة تأكد من وجود التبعيات التالية:
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
ارجع إلى قسم تبعيات Nvidia CUDA وقسم إعداد Docker أعلاه إذا لم تكن متأكدًا
إذا كان ما ورد أعلاه موجودًا وتم إعداده، فيمكنك المتابعة
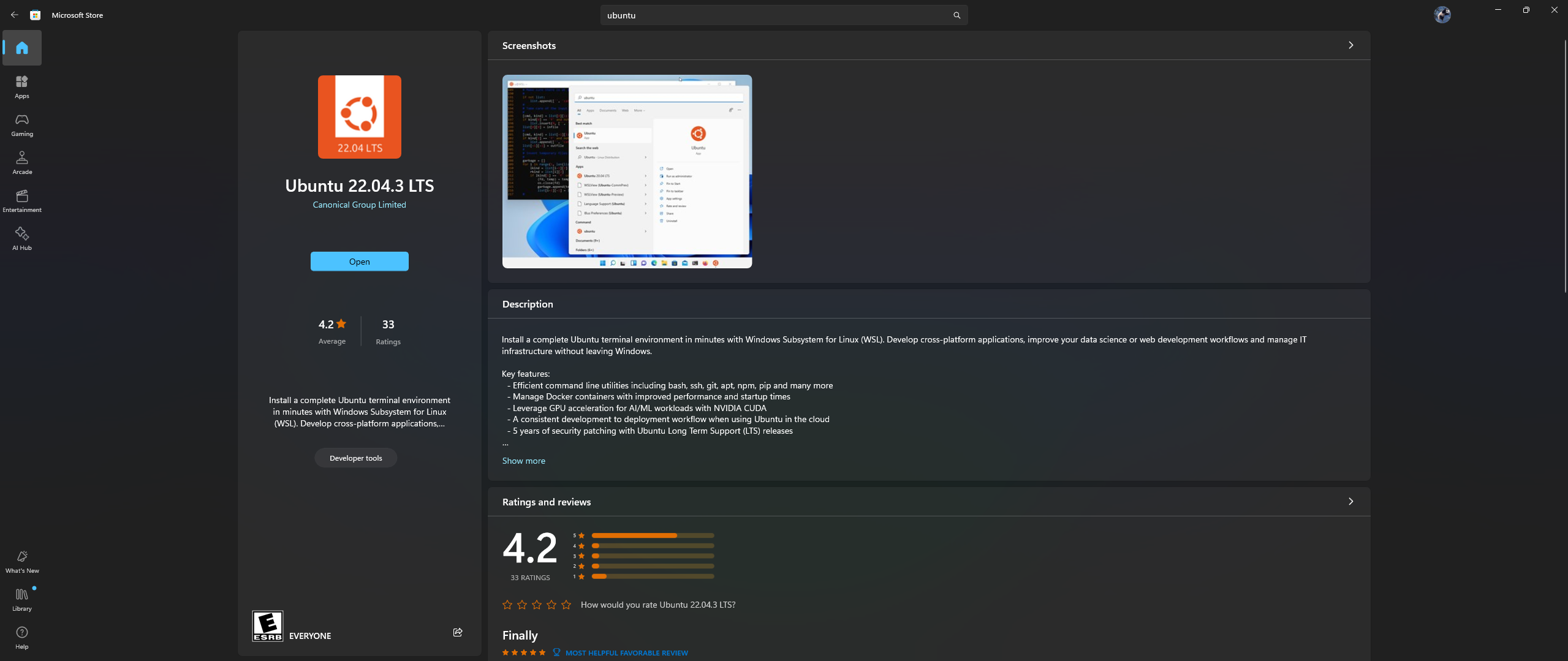
افتح تطبيق Microsoft Store على جهاز الكمبيوتر الخاص بك، وقم بتنزيل وتثبيت Ubuntu 22.04.3 LTS (يجب أن يتطابق مع الإصدار الموجود في السطر 2 في ملف الإرساء)
نعم، لقد قرأت ما ورد أعلاه بشكل صحيح: قم بتنزيل Ubuntu وتثبيته من تطبيق متجر Microsoft، راجع لقطة الشاشة أدناه:
لقد حان الوقت الآن لتثبيت مجموعة أدوات Nvidia Container Toolkit داخل Ubuntu، اتبع الخطوات أدناه للقيام بذلك:
قم بتشغيل Ubuntu Shell في Windows من خلال البحث عن Ubuntu في قائمة ابدأ بعد اكتمال التثبيت أعلاه
في سطر أوامر Ubuntu الذي يفتح، قم بالخطوات التالية:
تكوين مستودع الإنتاج:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
قم بتحديث قائمة الحزم من المستودع وقم بتثبيت حزم Nvidia Container Toolkit:
sudo apt-get update && apt-get install -y nvidia-container-toolkit
قم بتكوين وقت تشغيل الحاوية باستخدام الأمر nvidia-ctk، الذي يعدل الملف /etc/docker/daemon.json بحيث يتمكن Docker من استخدام Nvidia Container Runtime:
sudo nvidia-ctk runtime configure --runtime=docker
أعد تشغيل البرنامج الخفي Docker:
sudo systemctl restart docker
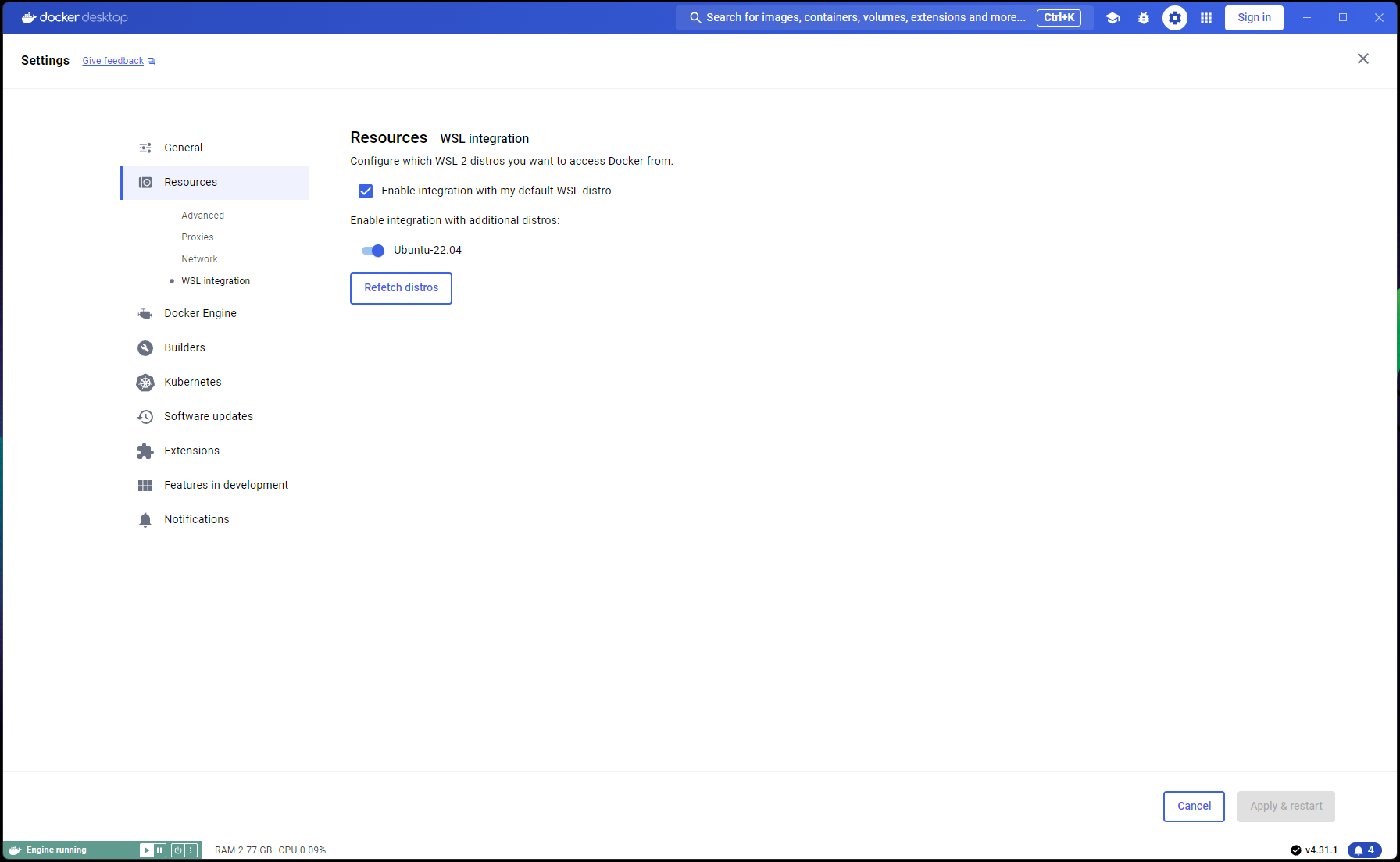
الآن اكتمل إعداد Ubuntu، حان الوقت لإكمال تكامل WSL وDocker:
افتح نافذة PowerShell جديدة وقم بتعيين تثبيت Ubuntu كإعداد WSL الافتراضي:
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
انتقل إلى Docker Desktop -> Settings -> Resources -> WSL Integration -> التحقق من التكامل الافتراضي مع Ubuntu 22.04. الرجوع إلى لقطة الشاشة أدناه:
الآن، إذا تم كل شيء بشكل صحيح، فأنت جاهز لبناء الحاوية وتشغيلها!
في موجه الأوامر/المحطة الطرفية، قم بتنفيذ الأوامر التالية:
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
بمجرد الانتهاء، انتقل إلى http://localhost:5000/ في متصفحك واتبع باقي خطوات التشغيل الأولى ودليل المستخدم
تنطبق أقسام استكشاف الأخطاء وإصلاحها على Container-LARS أيضًا
في حالة مواجهتك لأخطاء متعلقة بالشبكة، خاصة فيما يتعلق بمستودعات الحزم غير المتوفرة عند إنشاء الحاوية، فهذه مشكلة في الشبكة من جانبك غالبًا ما تتعلق بمشكلات جدار الحماية
على نظام التشغيل Windows، انتقل إلى Control PanelSystem and SecurityWindows Defender FirewallAllowed apps أو ابحث عن Firewall في قائمة ابدأ وتوجه إلى Allow an app through the firewall وتأكد من السماح بـ ``Docker Desktop Backend`` من خلال
في المرة الأولى التي تقوم فيها بتشغيل LARS، سيتم تنزيل نموذج تضمين محولات الجملة
في بيئة الحاوية، يمكن أن يكون هذا التنزيل في بعض الأحيان مشكلة ويؤدي إلى حدوث أخطاء عند طرح استعلام
إذا حدث ذلك، فما عليك سوى التوجه إلى قائمة إعدادات LARS: Settings->VectorDB & Embedding Models وتغيير نموذج التضمين إما إلى BGE-Base أو BGE-Large، سيؤدي ذلك إلى فرض إعادة التحميل وإعادة التنزيل
بمجرد الانتهاء من ذلك، تابع طرح الأسئلة مرة أخرى ويجب أن يتم الرد كالمعتاد
يمكنك الرجوع مرة أخرى إلى نموذج تضمين محولات الجملة ويجب حل المشكلة
كما هو مذكور في قسم استكشاف الأخطاء وإصلاحها أعلاه، يتم تنزيل نماذج التضمين عند تشغيل LARS لأول مرة
من الأفضل حفظ حالة الحاوية قبل إيقاف تشغيلها، لذلك لا يلزم تكرار خطوة التنزيل هذه في كل مرة يتم فيها تشغيل الحاوية لاحقًا
للقيام بذلك، افتح موجه أوامر/محطة طرفية أخرى وقم بتنفيذ التغييرات قبل إغلاق حاوية LARS قيد التشغيل:
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
سيؤدي هذا إلى إنشاء صورة محدثة يمكنك استخدامها في عمليات التشغيل اللاحقة:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
ملحوظة: بعد القيام بما سبق، إذا قمت بفحص المساحة المستخدمة بواسطة الصور باستخدام docker images ، ستلاحظ استخدام مساحة كبيرة. لكن، لا تأخذ الأحجام هنا بشكل حرفي! يتضمن الحجم الموضح لكل صورة الحجم الإجمالي لجميع طبقاتها، ولكن تتم مشاركة العديد من تلك الطبقات بين الصور، خاصة إذا كانت تلك الصور مبنية على نفس الصورة الأساسية أو إذا كانت إحدى الصور عبارة عن نسخة مخصصة من أخرى. لمعرفة مقدار مساحة القرص التي تستخدمها صور Docker فعليًا، استخدم:
docker system df
العودة إلى جدول المحتويات
| فئة | المهام | حالة |
|---|---|---|
| إصلاحات الأخطاء: | خطر إنشاء ملف نصي صفر بايت - في بعض الأحيان، إذا فشل التعرف الضوئي على الحروف/استخراج النص من مستند الإدخال، فقد يتم ترك ملف .txt بحجم 0B مما يؤدي إلى المزيد من محاولات إعادة المحاولة للاعتقاد بأن الملف قد تم تحميله بالفعل | ؟ المهمة المستقبلية |
| الميزات العملية: | سهولة الاستخدام تتمركز: | |
| تبديل واجهة المستخدم ذات الطبقة الحرة لـ Azure CV-OCR | ✅ تم في 8 يونيو 2024 | |
| حذف الدردشات | ؟ المهمة المستقبلية | |
| إعادة تسمية الدردشات | ؟ المهمة المستقبلية | |
| البرنامج النصي لتثبيت PowerShell | ؟ المهمة المستقبلية | |
| سكريبت تثبيت لينكس | ؟ المهمة المستقبلية | |
| الواجهة الخلفية للاستدلال على Ollama LLM كبديل لـ llama.cpp | ؟ المهمة المستقبلية | |
| تكامل خدمات التعرف الضوئي على الحروف (OCR) من موفري الخدمات السحابية الآخرين (GCP، وAWS، وOCI، وما إلى ذلك) | ؟ المهمة المستقبلية | |
| تبديل واجهة المستخدم لتجاهل المقتطفات النصية السابقة عند تحميل مستند | ؟ المهمة المستقبلية | |
| نافذة منبثقة مشروطة لتحميلات الملفات: تعكس خيارات استخراج النص من الإعدادات، والكتابة فوق العامة عند عمليات الإرسال، والتبديل إلى إعدادات الاستمرار | ؟ المهمة المستقبلية | |
| تتمحور حول الأداء: | ||
| دعم نفيديا TensorRT-LLM AWQ | ؟ المهمة المستقبلية | |
| المهام البحثية: | التحقق من Nvidia TensorRT-LLM: يتطلب بناء محركات AWQ-LLM TRT خاصة بوحدة معالجة الرسومات المستهدفة، NvTensorRT-LLM هو نظام بيئي خاص به ويعمل فقط على Python v3.10. | ✅ تم في 13 يونيو 2024 |
| التعرف الضوئي على الحروف المحلي مع Vision LLMs: MS-TrOCR (تم إنجازه)، Kosmos-2.5 (أولوية عالية)، Lava، Florence-2 | ؟ تحديث قيد التقدم بتاريخ 5 يوليو 2024 | |
| تحسينات RAG: إعادة الترتيب، RAPTOR، T-RAG | ؟ المهمة المستقبلية | |
| التحقيق في تكامل GraphDB: استخدام LLMs لاستخراج بيانات علاقة الكيان من المستندات وملء GraphDB وتحديثه وصيانته | ؟ المهمة المستقبلية |
العودة إلى جدول المحتويات
أتمنى أن يكون LARS ذا قيمة في عملك، وأدعوك لدعم تطويره المستمر! إذا كنت تقدر الأداة وترغب في المساهمة في تحسيناتها المستقبلية، ففكر في التبرع. دعمكم يساعدني على مواصلة تحسين LARS وإضافة ميزات جديدة.
كيفية التبرع لتقديم التبرع، يرجى استخدام الرابط التالي لحساب PayPal الخاص بي:
التبرع عبر باي بال
تحظى مساهماتك بتقدير كبير وسيتم استخدامها لتمويل المزيد من جهود التطوير.
العودة إلى جدول المحتويات


