BLIVA
1.0.0
وينبو هو*، ييفان شو*، يي لي، ويوي لي، زيوان تشين، وزووين تو. * المساهمة المتساوية
جامعة كاليفورنيا في سان دييغو ، Coinbase Global، Inc.
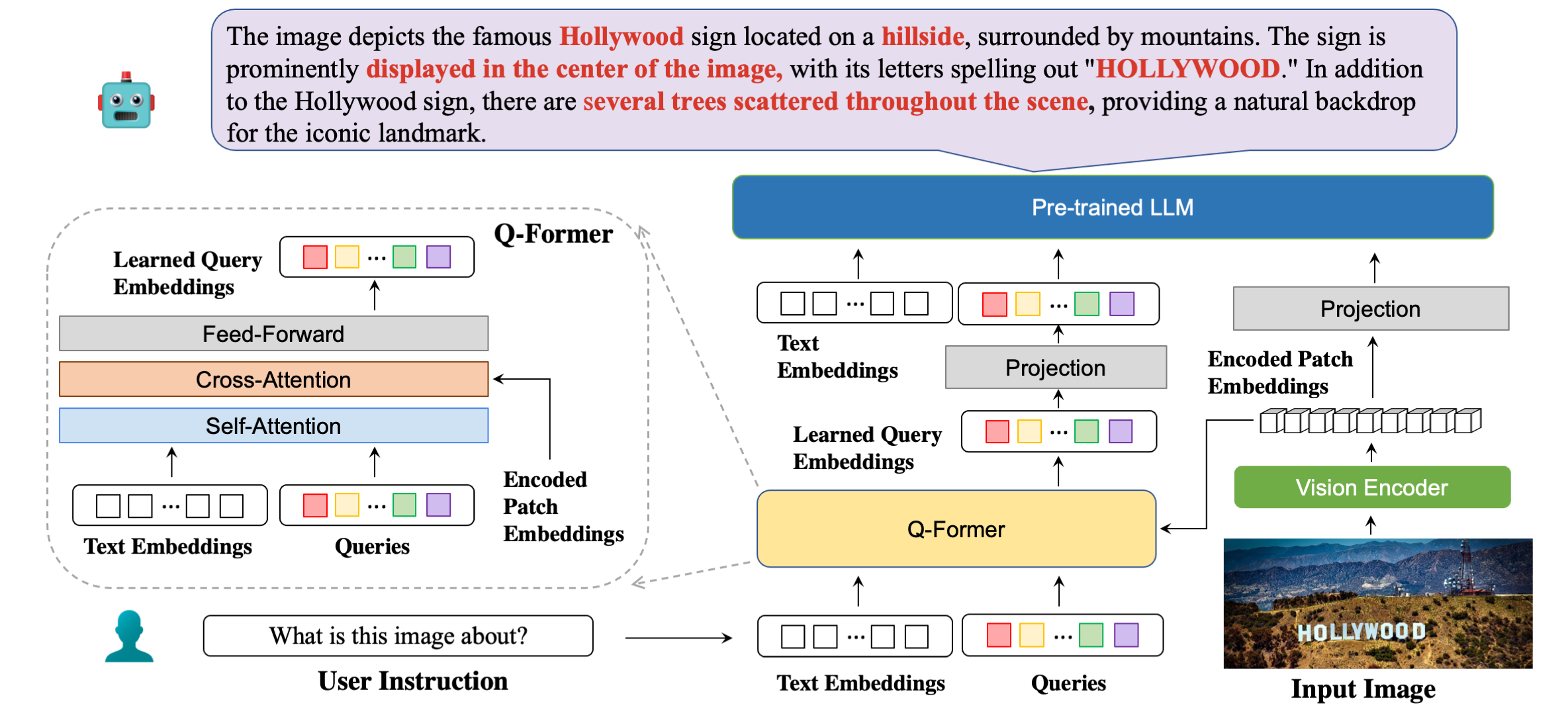
بنيتنا النموذجية بالتفصيل مع أمثلة الردود.
| طريقة | STVQA | OCRVQA | TextVQA | DocVQA | معلوماتVQA | ChartQA | ESTVQA | متعة | سروي | بوي | متوسط |
|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenFlamingo | 19.32 | 27.82 | 29.08 | 5.05 | 14.99 | 9.12 | 28.20 | 0.85 | 0.12 | 2.12 | 13.67 |
| BLIP2-OPT | 13.36 | 10.58 | 21.18 | 0.82 | 8.82 | 7.44 | 27.02 | 0.00 | 0.00 | 0.02 | 8.92 |
| BLIP2-FLanT5XXL | 21.38 | 30.28 | 30.62 | 4.00 | 10.17 | 7.20 | 42.46 | 1.19 | 0.20 | 2.52 | 15.00 |
| ميني جي بي تي 4 | 14.02 | 11.52 | 18.72 | 2.97 | 13.32 | 4.32 | 28.36 | 1.19 | 0.04 | 1.31 | 9.58 |
| لافا | 22.93 | 15.02 | 28.30 | 4.40 | 13.78 | 7.28 | 33.48 | 1.02 | 0.12 | 2.09 | 12.84 |
| mPLUG-البومة | 26.32 | 35.00 | 37.44 | 6.17 | 16.46 | 9.52 | 49.68 | 1.02 | 0.64 | 3.26 | 18.56 |
| إنستركتبليب (FLANT5XXL) | 26.22 | 55.04 | 36.86 | 4.94 | 10.14 | 8.16 | 43.84 | 1.36 | 0.50 | 1.91 | 18.90 |
| إنستركتبليب (فيكونا-7ب) | 28.64 | 47.62 | 39.60 | 5.89 | 13.10 | 5.52 | 47.66 | 0.85 | 0.64 | 2.66 | 19.22 |
| بليفا (FLANT5XXL) | 28.24 | 61.34 | 39.36 | 5.22 | 10.82 | 9.28 | 45.66 | 1.53 | 0.50 | 2.39 | 20.43 |
| بليفا (فيكونا-7B) | 29.08 | 65.38 | 42.18 | 6.24 | 13.50 | 8.16 | 48.14 | 1.02 | 0.88 | 2.91 | 21.75 |
| طريقة | VSR | IconQA | TextVQA | فيسديال | فليكر30ك | جلالة الملك | VizWiz | MSRVTT |
|---|---|---|---|---|---|---|---|---|
| فلامنغو-3ب | - | - | 30.1 | - | 60.6 | - | - | - |
| فلامنغو-9B | - | - | 31.8 | - | 61.5 | - | - | - |
| فلامنغو-80ب | - | - | 35.0 | - | 67.2 | - | - | - |
| ميني جي بي تي-4 | 50.65 | - | 18.56 | - | - | 29.0 | 34.78 | - |
| لافا | 56.3 | - | 37.98 | - | - | 9.2 | 36.74 | - |
| بليب-2 (فيكونا-7ب) | 50.0 | 39.7 | 40.1 | 44.9 | 74.9 | 50.2 | 49.34 | 4.17 |
| إنستركتبليب (فيكونا-7B) | 54.3 | 43.1 | 50.1 | 45.2 | 82.4 | 54.8 | 43.3 | 18.7 |
| بليفا (فيكونا-7B) | 62.2 | 44.88 | 57.96 | 45.63 | 87.1 | 55.6 | 42.9 | 23.81 |
conda create -n bliva python=3.9
conda activate blivagit clone https://github.com/mlpc-ucsd/BLIVA
cd BLIVA
pip install -e . بليفا فيكونا 7 ب
تم إصدار نموذج إصدار Vicuna الخاص بنا هنا. قم بتنزيل وزن النموذج الخاص بنا وحدد المسار في تكوين النموذج هنا في السطر 8.
LLM الذي استخدمناه هو الإصدار v0.1 من Vicuna-7B. لتحضير وزن فيكونا، يرجى الرجوع إلى تعليماتنا هنا. بعد ذلك، قم بتعيين المسار إلى وزن vicuna في ملف تكوين النموذج هنا في السطر 21.
BLIVA FlanT5 XXL (متوفر للاستخدام التجاري)
تم إصدار نموذج إصدار FlanT5 هنا. قم بتنزيل وزن النموذج الخاص بنا وحدد المسار في تكوين النموذج هنا في السطر 8.
سيبدأ تنزيل وزن LLM لـ Flant5 تلقائيًا من Huggingface عند تشغيل رمز الاستدلال الخاص بنا.
للإجابة على سؤال واحد من الصورة، قم بتشغيل كود التقييم التالي. على سبيل المثال،
python evaluate.py --answer_qs
--model_name bliva_vicuna
--img_path images/example.jpg
--question " what is this image about? "نحن ندعم أيضًا الإجابة على أسئلة الاختيار من متعدد، وهو نفس ما استخدمناه في مهام التقييم الورقية. لتوفير قائمة الاختيارات، ينبغي أن تكون سلسلة مقسمة بفاصلة. على سبيل المثال،
python evaluate.py --answer_mc
--model_name bliva_vicuna
--img_path images/mi6.png
--question " Which genre does this image belong to? "
--candidates " play, tv show, movie " العرض التوضيحي الخاص بنا متاح للعامة هنا. لتشغيل العرض التوضيحي الخاص بنا محليًا على جهازك. يجري:
python demo.pyبعد تنزيل مجموعات بيانات التدريب وتحديد مسارها في تكوينات مجموعة البيانات، نكون جاهزين للتدريب. استخدمنا 8x A6000 Ada في تجاربنا. يرجى ضبط المعلمات الفائقة وفقًا لموارد وحدة معالجة الرسومات لديك. قد يستغرق تحميل النموذج حوالي دقيقتين من المحولات، مما يمنح النموذج بعض الوقت لبدء التدريب. نعطي هنا مثالاً على تدريب نسخة BLIVA Vicuna، نسخة Flant5 تتبع نفس التنسيق.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/pretrain_bliva_vicuna.yamltorchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_vicuna.yamlأو، ندعم أيضًا تدريب Vicuna7b مع BLIVA باستخدام LoRA خلال الخطوة الثانية، بشكل افتراضي لا نستخدم هذا الإصدار.
torchrun --nnodes=1 --nproc_per_node=8
train.py
--cfg-path train_configs/finetune_bliva_and_vicuna.yamlإذا وجدت BLIVA مفيدًا لأبحاثك وتطبيقاتك، فيرجى الاستشهاد باستخدام BibTeX:
@misc { hu2023bliva ,
title = { BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions } ,
author = { Wenbo Hu and Yifan Xu and Yi Li and Weiyue Li and Zeyuan Chen and Zhuowen Tu } ,
publisher = { arXiv:2308.09936 } ,
year = { 2023 } ,
}كود هذا المستودع موجود تحت ترخيص BSD 3-Clause. تعتمد العديد من الرموز على Lavis مع ترخيص BSD 3-Clause هنا.
بالنسبة لمعلمات النموذج الخاصة بنا لإصدار BLIVA Vicuna، يجب استخدامها بموجب ترخيص نموذج LLaMA. بالنسبة لوزن طراز BLIVA FlanT5، فهو خاضع لترخيص Apache 2.0. بالنسبة لبيانات YTTB-VQA الخاصة بنا، فهي تخضع لـ CC BY NC 4.0


