cambrian
1.0.0
حقيقة طريفة: ظهرت الرؤية عند الحيوانات خلال العصر الكامبري! كان هذا مصدر إلهام لاسم مشروعنا، Cambrian.
eval/ لمزيد من التفاصيل.dataengine/ المجلد الفرعي لمزيد من التفاصيل.حاليًا، ندعم التدريب على مادة TPU باستخدام TorchXLA
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " فيما يلي نقاط التفتيش الكامبري الخاصة بنا بالإضافة إلى تعليمات حول كيفية استخدام الأوزان. تتفوق نماذجنا عبر أبعاد مختلفة، عند مستويات المعلمات 8B، و13B، و34B. إنها تُظهر أداءً تنافسيًا مقارنةً بالنماذج المملوكة مغلقة المصدر مثل GPT-4V وGemini-Pro وGrok-1.4V وفقًا للعديد من المعايير.
| نموذج | #فيس. توك. | إم إم بي | SQA-I | ماثفيستا إم | ChartQA | MMVP |
|---|---|---|---|---|---|---|
| جي بي تي-4V | UNK | 75.8 | - | 49.9 | 78.5 | 50.0 |
| الجوزاء-1.0 برو | UNK | 73.6 | - | 45.2 | - | - |
| الجوزاء-1.5 برو | UNK | - | - | 52.1 | 81.3 | - |
| جروك-1.5 | UNK | - | - | 52.8 | 76.1 | - |
| مم-1-8ب | 144 | 72.3 | 72.6 | 35.9 | - | - |
| مم-1-30ب | 144 | 75.1 | 81.0 | 39.4 | - | - |
| LLM الأساسي: Phi-3-3.8B | ||||||
| الكمبري-1-8ب | 576 | 74.6 | 79.2 | 48.4 | 66.8 | 40.0 |
| LLM الأساسية: LLaMA3-8B-Instruct | ||||||
| ميني الجوزاء-HD-8B | 2880 | 72.7 | 75.1 | 37.0 | 59.1 | 18.7 |
| لافا-نيكست-8بي | 2880 | 72.1 | 72.8 | 36.3 | 69.5 | 38.7 |
| الكمبري-1-8ب | 576 | 75.9 | 80.4 | 49.0 | 73.3 | 51.3 |
| LLM الأساسي: Vicuna1.5-13B | ||||||
| ميني الجوزاء-HD-13B | 2880 | 68.6 | 71.9 | 37.0 | 56.6 | 19.3 |
| لافا-نيكست-13بي | 2880 | 70.0 | 73.5 | 35.1 | 62.2 | 36.0 |
| الكمبري-1-13ب | 576 | 75.7 | 79.3 | 48.0 | 73.8 | 41.3 |
| LLM الأساسية: Hermes2-Yi-34B | ||||||
| ميني الجوزاء-HD-34B | 2880 | 80.6 | 77.7 | 43.4 | 67.6 | 37.3 |
| لافا-نيكست-34ب | 2880 | 79.3 | 81.8 | 46.5 | 68.7 | 47.3 |
| الكمبري-1-34ب | 576 | 81.4 | 85.6 | 53.2 | 75.6 | 52.7 |
للحصول على الجدول الكامل، يرجى الرجوع إلى ورقتنا Cambrian-1.
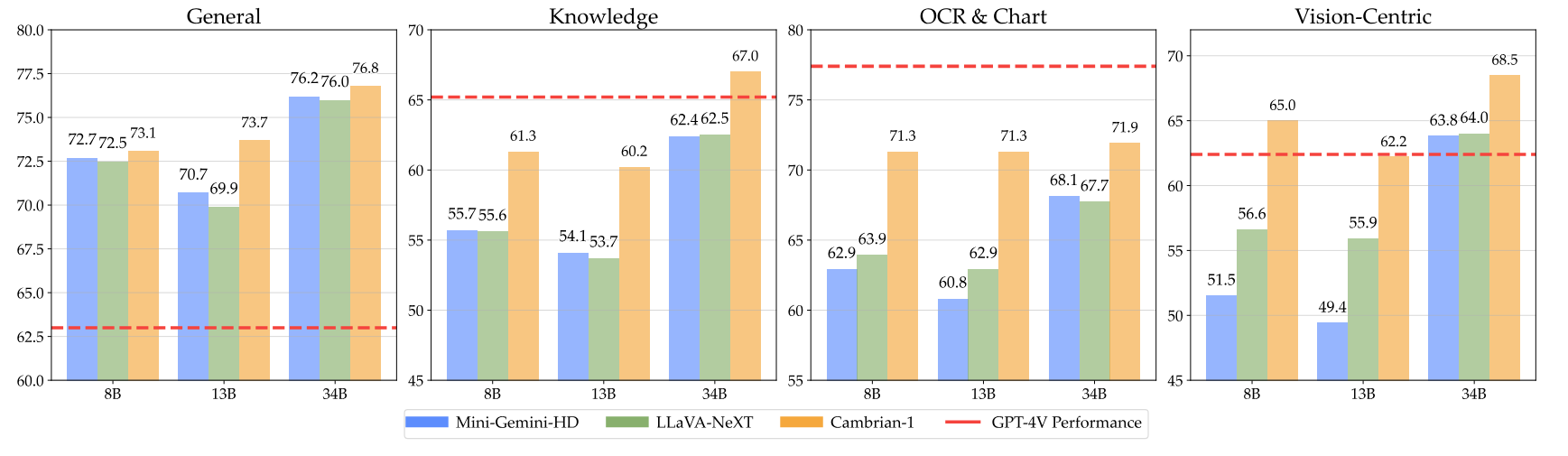
تقدم نماذجنا أداءً تنافسيًا للغاية مع استخدام عدد ثابت أصغر من الرموز المرئية.
لاستخدام الأوزان النموذجية قم بتحميلها من Hugging Face:
نحن نقدم نموذجًا لتحميل النموذج وإنشاء البرنامج النصي في inference.py .

في هذا العمل، قمنا بجمع مجموعة كبيرة جدًا من بيانات ضبط التعليمات، Cambrian-10M، لنا وللعمل المستقبلي لدراسة البيانات في تدريب MLLMs. في دراستنا الأولية، قمنا بتصفية البيانات وصولاً إلى مجموعة عالية الجودة من 7 ملايين نقطة بيانات منسقة، والتي نسميها Cambrian-7M. تتوفر كلتا مجموعتي البيانات في مجموعة بيانات Hugging Face التالية: Cambrian-10M.
لقد جمعنا مجموعة متنوعة من بيانات ضبط التعليمات المرئية من مصادر مختلفة، بما في ذلك VQA والمحادثة المرئية والتفاعل البصري المتجسد. لضمان الحصول على بيانات معرفية عالية الجودة وموثوقة وواسعة النطاق، قمنا بتصميم محرك بيانات الإنترنت.
بالإضافة إلى ذلك، لاحظنا أن بيانات VQA تميل إلى توليد مخرجات قصيرة جدًا، مما يؤدي إلى تحول في التوزيع عن بيانات التدريب. ولمعالجة هذه المشكلة، قمنا بالاستفادة من GPT-4v وGPT-4o لإنشاء استجابات موسعة والمزيد من البيانات الإبداعية.
لحل مشكلة عدم كفاية البيانات المتعلقة بالعلم، قمنا بتصميم محرك بيانات الإنترنت لجمع بيانات VQA الموثوقة ذات الصلة بالعلم. يمكن تطبيق هذا المحرك لجمع البيانات حول أي موضوع. باستخدام هذا المحرك، قمنا بجمع 161 ألف نقطة بيانات إضافية للتعليمات المرئية المتعلقة بالعلوم، مما أدى إلى زيادة إجمالي البيانات في هذا المجال بنسبة 400%! إذا كنت تريد استخدام هذا الجزء من البيانات، فيرجى استخدام ملف jsonl هذا.
استخدمنا GPT-4v لإنشاء 77 ألف نقطة بيانات إضافية. تستخدم هذه البيانات إما GPT-4v لإعادة كتابة VQA الأصلي للإجابة فقط إلى إجابات أطول مع استجابات أكثر تفصيلاً أو إنشاء بيانات ضبط التعليمات المرئية بناءً على الصورة المحددة. إذا كنت تريد استخدام هذا الجزء من البيانات، فيرجى استخدام ملف jsonl هذا.
استخدمنا GPT-4o لإنشاء 60 ألف نقطة بيانات إبداعية إضافية. تشجع هذه البيانات النموذج على إنشاء استجابات طويلة جدًا وغالبًا ما تحتوي على أسئلة إبداعية للغاية، مثل كتابة قصيدة وتأليف أغنية والمزيد. إذا كنت تريد استخدام هذا الجزء من البيانات، فيرجى استخدام ملف jsonl هذا.
أجرينا دراسة أولية حول تنظيم البيانات من خلال:
تجريبيا، وجدنا هذا الإعداد
| فئة | نسبة البيانات |
|---|---|
| لغة | 21.00% |
| عام | 34.52% |
| التعرف الضوئي على الحروف | 27.22% |
| عد | 8.71% |
| الرياضيات | 7.20% |
| شفرة | 0.87% |
| علوم | 0.88% |
بالمقارنة مع طراز LLaVA-665K السابق، فإن توسيع نطاق البيانات وتحسين تنظيمها يؤدي إلى تحسين أداء النموذج بشكل كبير، كما هو موضح في الجدول أدناه:
| نموذج | متوسط | المعرفة العامة | التعرف الضوئي على الحروف | جدول | تتمحور الرؤية |
|---|---|---|---|---|---|
| لافا-665K | 40.4 | 64.7 | 45.2 | 20.8 | 31.0 |
| الكمبري-10M | 53.8 | 68.7 | 51.6 | 47.1 | 47.6 |
| الكمبري-7M | 54.8 | 69.6 | 52.6 | 47.3 | 49.5 |
في حين أن التدريب باستخدام Cambrian-7M يوفر نتائج قياسية تنافسية، فقد لاحظنا أن النموذج يميل إلى إنتاج استجابات أقصر ويعمل كآلة أسئلة وأجوبة. هذا السلوك، الذي نشير إليه بظاهرة "آلة الرد"، يمكن أن يحد من فائدة النموذج في التفاعلات الأكثر تعقيدًا.
لقد وجدنا أن إضافة موجه النظام مثل "الإجابة على السؤال باستخدام كلمة أو عبارة واحدة". يمكن أن يساعد في تخفيف المشكلة. يشجع هذا النهج النموذج على تقديم مثل هذه الإجابات المختصرة فقط عندما يكون ذلك مناسبًا للسياق. لمزيد من التفاصيل، يرجى الرجوع إلى ورقتنا.
لقد قمنا أيضًا برعاية مجموعة بيانات، Cambrian-7M مع موجه النظام، والتي تتضمن موجه النظام لتعزيز إبداع النموذج وقدرته على الدردشة.
يوجد أدناه أحدث تكوين تدريبي لـ Cambrian-1.
في ورقة Cambrian-1، قمنا بإجراء دراسات موسعة لإثبات ضرورة التدريب على مرحلتين. يتكون تدريب Cambrian-1 من مرحلتين:
تم تدريب Cambrian-1 على TPU-V4-512 ولكن يمكن أيضًا تدريبه على TPU بدءًا من TPU-V4-64. سيتم إصدار كود تدريب GPU قريبًا. بالنسبة لتدريب وحدة معالجة الرسومات على عدد أقل من وحدات معالجة الرسومات، قم بتقليل حجم per_device_train_batch_size وزيادة gradient_accumulation_steps وفقًا لذلك، مع التأكد من بقاء حجم الدفعة العامة كما هو: per_device_train_batch_size x gradient_accumulation_steps x num_gpus .
يتم توفير كل من المعلمات الفائقة المستخدمة في التدريب المسبق والضبط الدقيق أدناه.
| قاعدة LLM | حجم الدفعة العالمية | معدل التعلم | معدل التعلم SVA | العصور | أقصى طول |
|---|---|---|---|---|---|
| لاما-3 8ب | 512 | 1ه-3 | 1ه-4 | 1 | 2048 |
| فيكونا-1.5 13 ب | 512 | 1ه-3 | 1ه-4 | 1 | 2048 |
| هيرميس يي-34ب | 1024 | 1ه-3 | 1ه-4 | 1 | 2048 |
| قاعدة LLM | حجم الدفعة العالمية | معدل التعلم | العصور | أقصى طول |
|---|---|---|---|---|
| لاما-3 8ب | 512 | 4ه-5 | 1 | 2048 |
| فيكونا-1.5 13 ب | 512 | 4ه-5 | 1 | 2048 |
| هيرميس يي-34ب | 1024 | 2ه-5 | 1 | 2048 |
ولضبط التعليمات، أجرينا تجارب لتحديد معدل التعلم الأمثل لنموذج التدريب الخاص بنا. بناءً على النتائج التي توصلنا إليها، نوصي باستخدام الصيغة التالية لضبط معدل التعلم الخاص بك بناءً على مدى توفر جهازك:
optimal lr = base_lr * sqrt(bs / base_bs)
للحصول على LLM الأساسي وتدريب نماذج 8B و13B و34B:
نحن نستخدم مجموعة من بيانات محاذاة LLaVA وShareGPT4V وMini-Gemini وALLaVA للتدريب المسبق للموصل المرئي (SVA). في Cambrian-1، نقوم بإجراء دراسات موسعة لإثبات ضرورة وفوائد استخدام بيانات المحاذاة الإضافية.
للبدء، يرجى زيارة صفحة بيانات محاذاة الوجه المعانقة لمزيد من التفاصيل. يمكنك تحميل بيانات المحاذاة من الروابط التالية:
نحن نقدم نماذج من النصوص التدريبية في:
إذا كنت ترغب في التدريب باستخدام مصادر بيانات أخرى أو بيانات مخصصة، فإننا ندعم تنسيق بيانات LLaVA الشائع الاستخدام. للتعامل مع الملفات الكبيرة جدًا، نستخدم تنسيق JSONL بدلاً من تنسيق JSON للتحميل البطيء للبيانات لتحسين استخدام الذاكرة.
على غرار تدريب SVA، يرجى زيارة بيانات Cambrian-10M الخاصة بنا للحصول على مزيد من التفاصيل حول بيانات ضبط التعليمات.
نحن نقدم نماذج من النصوص التدريبية في:
--mm_projector_type : لاستخدام وحدة SVA الخاصة بنا، قم بتعيين هذه القيمة على sva . لاستخدام جهاز عرض MLP بنمط LLaVA ثنائي الطبقة، اضبط هذه القيمة على mlp2x_gelu .--vision_tower_aux_list : قائمة نماذج الرؤية المطلوب استخدامها (على سبيل المثال '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : قائمة عدد رموز الرؤية لكل برج رؤية؛ يجب أن يكون كل رقم رقمًا مربعًا (على سبيل المثال '[576, 576, 576, 9216]' ). سيتم استيفاء خريطة الميزات لكل برج رؤية لتلبية هذا المطلب.--image_token_len : العدد النهائي لرموز الرؤية التي سيتم تقديمها إلى LLM؛ يجب أن يكون الرقم رقمًا مربعًا (على سبيل المثال 576 ). لاحظ أنه إذا كان mm_projector_type هو mlp، فيجب أن يكون كل رقم في vision_tower_aux_token_len_list هو نفس image_token_len . الوسائط الواردة أدناه ذات معنى فقط لجهاز العرض SVA--num_query_group : قيمة G لوحدة SVA.--query_num_list : قائمة بأرقام الاستعلام لكل مجموعة استعلام في SVA (على سبيل المثال '[576]' ). يجب أن يساوي طول القائمة num_query_group .--connector_depth : القيمة D لوحدة SVA.--vision_hidden_size : الحجم المخفي لوحدة SVA.--connector_only : إذا كان صحيحًا، ستظهر وحدة SVA فقط قبل LLM، وإلا فسيتم إدراجها عدة مرات داخل LLM. الوسائط الثلاث التالية تكون ذات معنى فقط عندما يتم تعيينها على False .--num_of_vision_sampler_layers : إجمالي عدد وحدات SVA المدرجة داخل LLM.--start_of_vision_sampler_layers : فهرس طبقة LLM الذي يبدأ بعده إدخال SVA.--stride_of_vision_sampler_layers : خطوة إدخال وحدة SVA داخل LLM. لقد أصدرنا رمز التقييم الخاص بنا في المجلد الفرعي eval/ . يرجى الاطلاع على التمهيدي هناك لمزيد من التفاصيل.
سوف ترشدك الإرشادات التالية خلال إطلاق عرض تجريبي محلي لـ Gradio باستخدام Cambrian. نحن نقدم لك واجهة ويب بسيطة للتفاعل مع النموذج. يمكنك أيضًا استخدام CLI للاستدلال. هذا الإعداد مستوحى بشكل كبير من LLaVA.
يرجى اتباع الخطوات أدناه لبدء تشغيل عرض Gradio المحلي. يوجد رسم تخطيطي لرمز الخدمة المحلي أدناه 1 .
%%{init: {"theme": "base"}}%%
مخطط انسيابي BT
%% أعلن العقد
تعبئة نمط gws:#f9f،السكتة الدماغية:#333،عرض السكتة الدماغية:2px
تعبئة النمط c:#bbf،السكتة الدماغية:#333،عرض السكتة الدماغية:2px
تعبئة النمط mw8b:#aff،السكتة الدماغية:#333،عرض السكتة الدماغية:2px
تعبئة النمط mw13b:#aff،السكتة الدماغية:#333،عرض السكتة الدماغية:2px
%% نمط sglw13b تعبئة:#ffa،السكتة الدماغية:#333،عرض السكتة الدماغية:2px
%% نمط lsglw13b تعبئة:#ffa،السكتة الدماغية:#333،عرض السكتة الدماغية:2px
gws["Gradio (خادم واجهة المستخدم)"]
c["وحدة التحكم (خادم API):<br/>المنفذ: 10000"]
mw8b["العامل النموذجي:<br/><b>Cambrian-1-8B</b><br/>المنفذ: 40000"]
mw13b["العامل النموذجي:<br/><b>Cambrian-1-13B</b><br/>المنفذ: 40001"]
%% sglw13b["SGLang Backend:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["عامل SGLang:<br/><b>Cambrian-1-34B<b><br/>المنفذ: 40002"]
رسم بياني فرعي "الهندسة المعمارية التجريبية"
الاتجاه بي تي
ج <--> جيجاواط
mw8b <--> ج
mw13b <--> ج
%% lsglw13b <--> ج
%% sglw13b <--> lsglw13b
نهاية
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadلقد قمت للتو بتشغيل واجهة ويب Gradio. يمكنك الآن فتح واجهة الويب باستخدام عنوان URL المطبوع على الشاشة. قد تلاحظ أنه لا يوجد نموذج في قائمة النماذج. لا تقلق، لأننا لم نطلق أي عامل نموذجي بعد. سيتم تحديثه تلقائيًا عند تشغيل عامل نموذجي.
قريباً.
هذا هو العامل الفعلي الذي يقوم بالاستدلال على وحدة معالجة الرسومات. كل عامل مسؤول عن نموذج واحد محدد في --model-path .
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bانتظر حتى تنتهي عملية تحميل النموذج وسترى "Uvicorn Running on...". الآن، قم بتحديث واجهة مستخدم الويب الخاصة بـ Gradio، وسترى النموذج الذي قمت بتشغيله للتو في قائمة النماذج.
يمكنك إطلاق أي عدد تريده من العمال، والمقارنة بين نقاط التحقق النموذجية المختلفة في نفس واجهة Gradio. يرجى الاحتفاظ بـ --controller كما هو، وتعديل --port و --worker إلى رقم منفذ مختلف لكل عامل.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> إذا كنت تستخدم جهاز Apple مزودًا بشريحة M1 أو M2، فيمكنك تحديد جهاز mps باستخدام علامة --device : --device mps .
إذا كانت ذاكرة VRAM الخاصة بوحدة معالجة الرسومات الخاصة بك أقل من 24 جيجابايت (على سبيل المثال، RTX 3090، RTX 4090، وما إلى ذلك)، فيمكنك محاولة تشغيلها باستخدام وحدات معالجة رسومات متعددة. ستحاول قاعدة الأكواد الأحدث لدينا تلقائيًا استخدام وحدات معالجة رسومات متعددة إذا كان لديك أكثر من وحدة معالجة رسومات واحدة. يمكنك تحديد وحدات معالجة الرسومات التي سيتم استخدامها مع CUDA_VISIBLE_DEVICES . يوجد أدناه مثال على التشغيل باستخدام أول وحدتي معالجة رسوميات.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bالمهام
إذا وجدت أن لغة Cambrian مفيدة لأبحاثك وتطبيقاتك، فيرجى الاستشهاد باستخدام BibTeX:
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
إشعارات الاستخدام والترخيص : يستخدم هذا المشروع مجموعات بيانات ونقاط تفتيش معينة تخضع للتراخيص الأصلية الخاصة بها. يجب على المستخدمين الالتزام بجميع شروط وأحكام هذه التراخيص الأصلية، بما في ذلك، على سبيل المثال لا الحصر، شروط استخدام OpenAI لمجموعة البيانات والتراخيص المحددة لنماذج اللغة الأساسية لنقاط التفتيش المدربة باستخدام مجموعة البيانات (على سبيل المثال، ترخيص مجتمع Llama لـ LLaMA-3، وفيكونا-1.5). ولا يفرض هذا المشروع أي قيود إضافية غير تلك المنصوص عليها في التراخيص الأصلية. علاوة على ذلك، يتم تذكير المستخدمين بالتأكد من أن استخدامهم لمجموعة البيانات ونقاط التفتيش يتوافق مع جميع القوانين واللوائح المعمول بها.
تم النسخ من مخطط LLaVA. ↩


