chat4u
1.0.0
استخدم سجلات دردشة WeChat لتدريب برنامج الدردشة الآلي المخصص لك.
سيتم تشفير سجلات دردشة WeChat وتخزينها في قاعدة بيانات sqlite. أولاً، تحتاج إلى الحصول على مفتاح قاعدة البيانات. أنت بحاجة إلى جهاز كمبيوتر محمول يعمل بنظام التشغيل macOS، ويمكن أن يكون هاتفك المحمول Android/iPhone.
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log ، والمثال على النحو التالي. sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
يمكن لمستخدمي أنظمة التشغيل الأخرى تجربة الطرق التالية، والتي تم بحثها فقط ولم يتم التحقق منها كمرجع:
EnMicroMsg.db : https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db : https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker على جهاز الكمبيوتر المحمول الذي يعمل بنظام التشغيل macOS، يتم تخزين سجلات دردشة WeChat في msg_0.db - msg_9.db ، ويمكن فك تشفير قواعد البيانات هذه فقط.
تحتاج إلى تثبيت sqlcipher لفك التشفير، ويمكن لمستخدمي نظام macOS تنفيذ الأمر مباشرةً:
brew install sqlcipher قم بتنفيذ البرنامج النصي التالي لتحليل dbtrace.log وفك تشفير msg_x.db وتصديره إلى plain_msg_x.db تلقائيًا.
python3 decrypt.py يمكنك فتح قاعدة البيانات التي تم فك تشفيرها plain_msg_x.db من خلال https://sqliteviewer.app/، والعثور على الجدول الذي توجد به سجلات الدردشة التي تحتاجها، وملء قاعدة البيانات وأسماء الجداول في prepare_data.py ، وتنفيذ البرنامج النصي التالي لإنشاء تدريب بيانات train.json ، الإستراتيجية الحالية بسيطة نسبيًا، فهي تتعامل فقط مع جولة واحدة من الحوار، وسوف تدمج الحوارات المتتالية في غضون 5 دقائق.
python3 prepare_data.pyأمثلة على بيانات التدريب هي كما يلي:
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] قم بإعداد جهاز Linux مزودًا بوحدة معالجة الرسومات (GPU) وscp train.json لجهاز وحدة معالجة الرسومات (GPU).
لقد استخدمت LLaMA-7B لضبط الصورة الكاملة بدقة stanford_alpaca، وقمت بتدريب 90 ألفًا من البيانات لمدة 3 فترات على بطاقة V100-SXM2-32GB المكونة من 8 بطاقات، والتي استغرقت ساعة واحدة فقط.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 Falseسيحفظ DeepSpeed zero3 الأوزان في شرائح، ويجب دمجها في ملف نقطة تفتيش pytorch:
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binعلى بطاقات الرسومات الاستهلاكية، يمكنك تجربة alpaca-lora فقط الضبط الدقيق لأوزان lora هو الذي يمكن أن يقلل بشكل كبير من ذاكرة الرسومات وتكاليف التدريب.
يمكنك استخدام alpaca-lora لنشر الواجهة الأمامية المتدرجة لتصحيح الأخطاء. إذا كنت تقوم بضبط الصورة بأكملها بشكل دقيق، فستحتاج إلى التعليق على الكود المتعلق بالـ peft وتحميل النموذج الأساسي فقط.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechatتأثير العملية:

من الضروري نشر خدمة نموذجية متوافقة مع OpenAI API، إليك تعديل بسيط يعتمد على llama4openai-api.py، راجع llama4openai-api.py في هذا المستودع لبدء الخدمة:
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyاختبار ما إذا كانت الواجهة متاحة:
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'استخدم wechat-chatgpt للوصول إلى WeChat، واملأ عنوان خدمة النموذج المحلي الخاص بك لعنوان API:
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latestتأثير العملية:
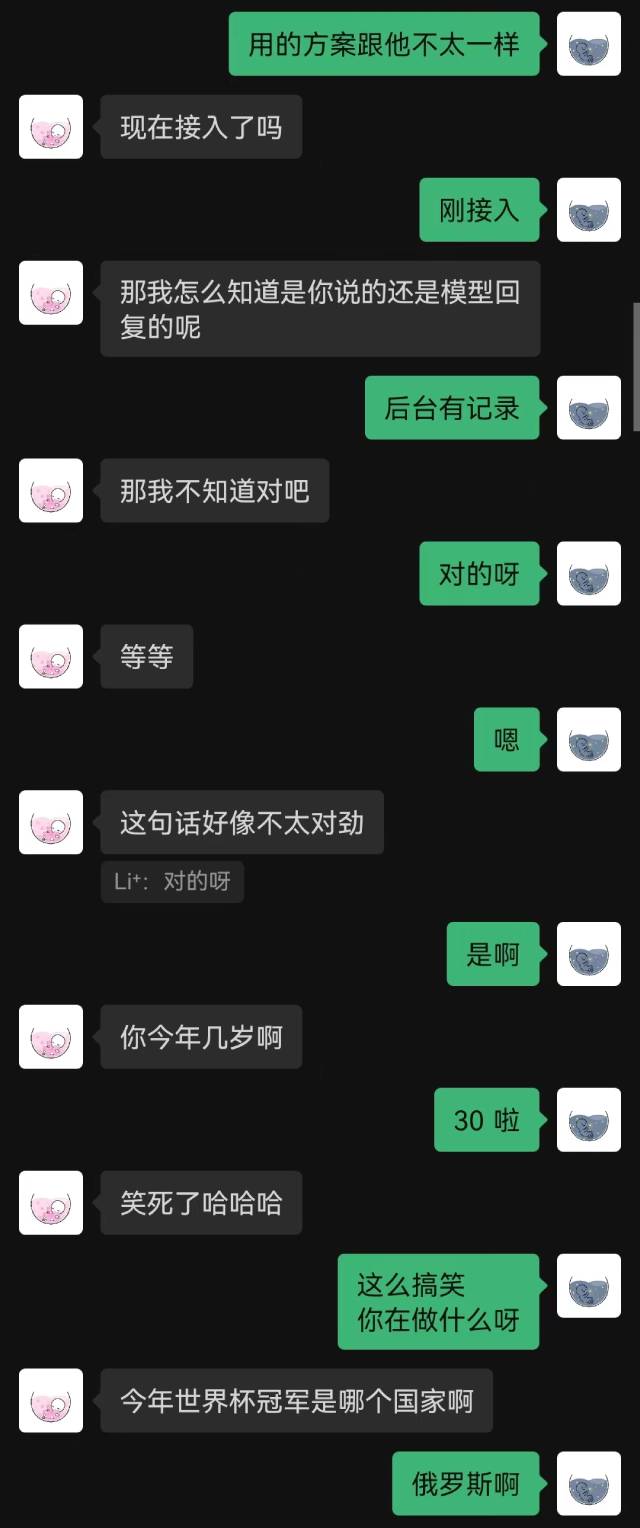 | 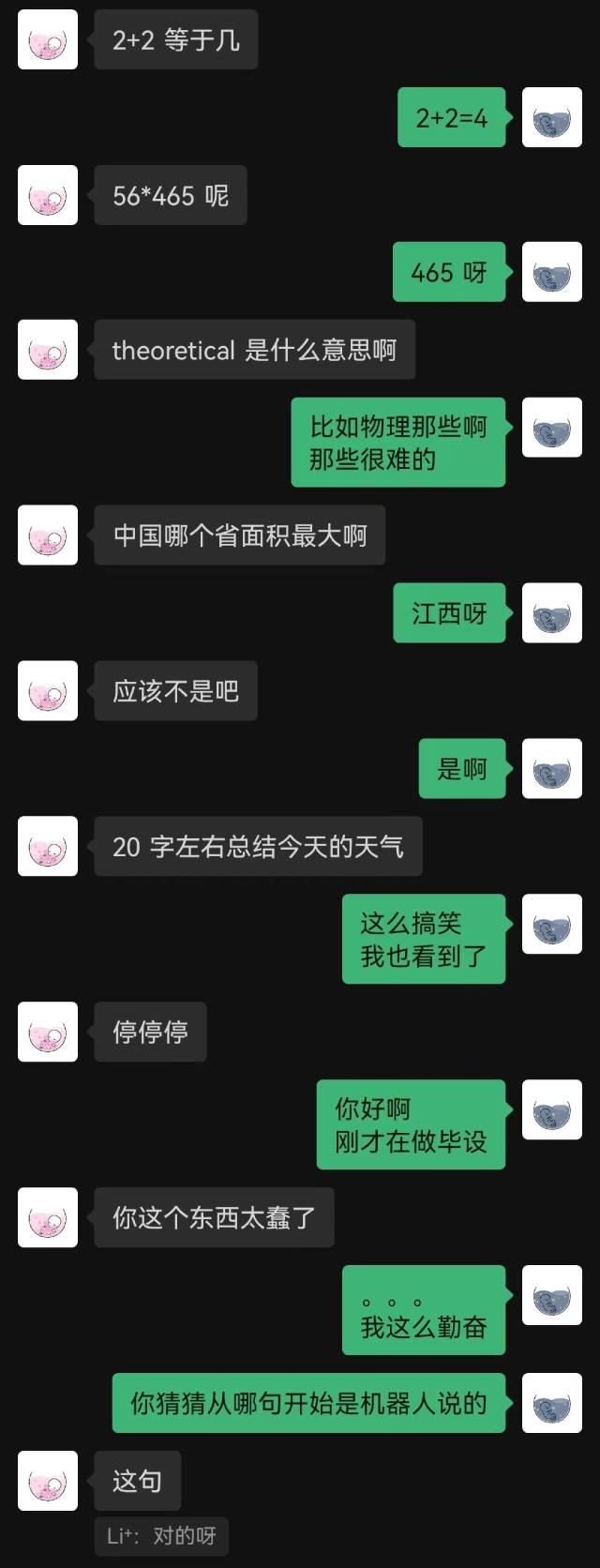 |
|---|
"لقد اتصلت للتو" كانت الجملة الأولى التي قالها الروبوت، ولم يخمنها الطرف الآخر حتى النهاية.
بشكل عام، من المؤكد أن الروبوتات المدربة على سجلات الدردشة ستواجه بعض الأخطاء المنطقية، لكنها قلدت أسلوب الدردشة بشكل أفضل.


