snips nlu
0.20.2
Snips NLU (فهم اللغة الطبيعية) هي مكتبة Python تسمح باستخراج المعلومات المنظمة من الجمل المكتوبة باللغة الطبيعية.
وراء كل روبوت دردشة ومساعد صوتي تكمن قطعة مشتركة من التكنولوجيا: فهم اللغة الطبيعية (NLU). في أي وقت يتفاعل فيه المستخدم مع الذكاء الاصطناعي باستخدام لغة طبيعية، يجب ترجمة كلماته إلى وصف يمكن قراءته آليًا لما يقصده.
يكتشف محرك NLU أولا ما هي نية المستخدم (ويعرف أيضا باسم النية)، ثم يستخرج المعلمات (وتسمى فتحات) للاستعلام. يمكن للمطور بعد ذلك استخدام هذا لتحديد الإجراء أو الاستجابة المناسبة.
ولنأخذ مثالاً لتوضيح ذلك، ولنتأمل الجملة التالية:
"كيف سيكون الطقس في باريس الساعة 9 مساءً؟"
بعد تدريبه بشكل مناسب، سيتمكن محرك Snips NLU من استخراج البيانات المنظمة مثل:
{
"intent" : {
"intentName" : " searchWeatherForecast " ,
"probability" : 0.95
},
"slots" : [
{
"value" : " paris " ,
"entity" : " locality " ,
"slotName" : " forecast_locality "
},
{
"value" : {
"kind" : " InstantTime " ,
"value" : " 2018-02-08 20:00:00 +00:00 "
},
"entity" : " snips/datetime " ,
"slotName" : " forecast_start_datetime "
}
]
} في هذه الحالة، الهدف المحدد هو searchWeatherForecast وتم استخراج فتحتين، المنطقة المحلية والوقت والوقت. كما ترون، يقوم Snips NLU بخطوة إضافية فوق استخراج الكيانات: فهو يحلها. لقد تم بالفعل تحويل قيمة التاريخ والوقت المستخرجة إلى تنسيق ISO سهل الاستخدام.
قم بمراجعة منشور مدونتنا للحصول على مزيد من التفاصيل حول سبب قيامنا ببناء Snips NLU وكيفية عمله تحت الغطاء. قمنا أيضًا بنشر ورقة بحثية عن arxiv، تعرض فيها بنية التعلم الآلي لمنصة Snips Voice Platform.
pip install snips - nlu لدينا حاليًا ثنائيات (عجلات) معدة مسبقًا لـ snips-nlu وتبعياتها لنظام التشغيل MacOS (10.11 والإصدارات الأحدث)، وLinux x86_64 وWindows.
بالنسبة لأي بنية/نظام تشغيل آخر، يمكن تثبيت snips-nlu من التوزيع المصدر. للقيام بذلك، يجب تثبيت Rust وsetuptools_rust قبل تشغيل الأمر pip install snips-nlu .
تعتمد Snips NLU على موارد اللغة الخارجية التي يجب تنزيلها قبل استخدام المكتبة. يمكنك جلب الموارد للغة معينة عن طريق تشغيل الأمر التالي:
python -m snips_nlu download enأو ببساطة:
snips-nlu download enقائمة اللغات المدعومة متاحة على هذا العنوان.
أسهل طريقة لاختبار قدرات هذه المكتبة هي من خلال واجهة سطر الأوامر.
أولاً، ابدأ بتدريب وحدة البرمجة اللغوية العصبية باستخدام إحدى مجموعات البيانات النموذجية:
snips-nlu train path/to/dataset.json path/to/output_trained_engine حيث path/to/dataset.json هو المسار إلى مجموعة البيانات التي سيتم استخدامها أثناء التدريب، path/to/output_trained_engine هو الموقع الذي يجب أن يستمر فيه المحرك المدرب بمجرد الانتهاء من التدريب.
بعد ذلك، يمكنك البدء في تحليل الجمل بشكل تفاعلي عن طريق تشغيل:
snips-nlu parse path/to/trained_engine حيث يتوافق path/to/trained_engine مع الموقع الذي قمت فيه بتخزين المحرك المدرب خلال الخطوة السابقة.
فيما يلي نموذج للتعليمة البرمجية التي يمكنك تشغيلها على جهازك بعد تثبيت snips-nlu وجلب الموارد الإنجليزية وتنزيل إحدى مجموعات البيانات النموذجية:
>> > from __future__ import unicode_literals , print_function
>> > import io
>> > import json
>> > from snips_nlu import SnipsNLUEngine
>> > from snips_nlu . default_configs import CONFIG_EN
>> > with io . open ( "sample_datasets/lights_dataset.json" ) as f :
... sample_dataset = json . load ( f )
>> > nlu_engine = SnipsNLUEngine ( config = CONFIG_EN )
>> > nlu_engine = nlu_engine . fit ( sample_dataset )
>> > text = "Please turn the light on in the kitchen"
>> > parsing = nlu_engine . parse ( text )
>> > parsing [ "intent" ][ "intentName" ]
'turnLightOn'ما يفعله هو تدريب محرك NLU على مجموعة بيانات الطقس النموذجية وتحليل استعلام الطقس.
فيما يلي قائمة ببعض مجموعات البيانات التي يمكن استخدامها لتدريب محرك Snips NLU:
في يناير 2018، قمنا بإعادة إنتاج معيار أكاديمي تم نشره خلال صيف 2017. في هذه المقالة، قام المؤلفون بتقييم أداء API.ai (الآن Dialogflow، Google)، وLuis.ai (Microsoft)، وIBM Watson، وRasa NLU. من أجل الإنصاف، استخدمنا نسخة محدثة من Rasa NLU وقمنا بمقارنتها بأحدث إصدار من Snips NLU (كلاهما باللون الأزرق الداكن).
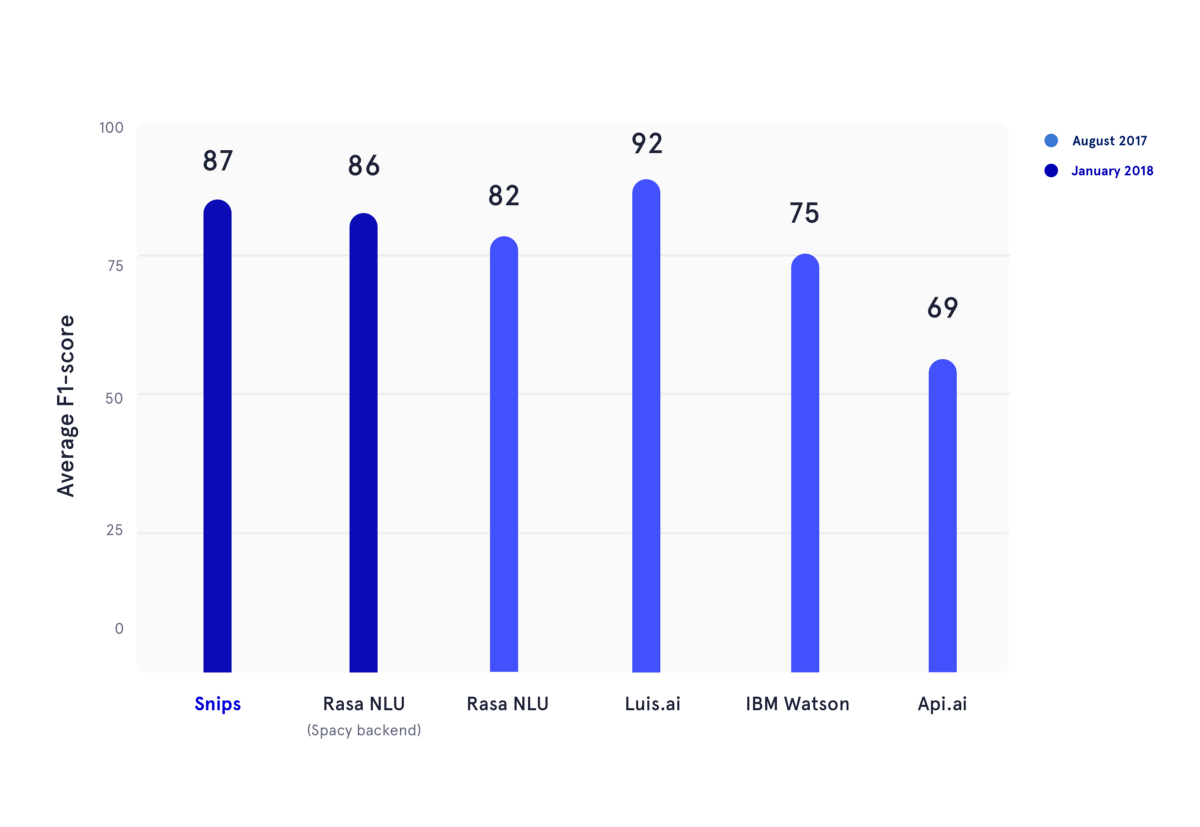
في الشكل أعلاه، تم حساب درجات F1 لكل من تصنيف النية وملء الفتحات للعديد من موفري NLU، وتم حساب متوسطها عبر مجموعات البيانات الثلاث المستخدمة في المعيار الأكاديمي المذكور من قبل. جميع النتائج الأساسية يمكن العثور عليها هنا.
لمعرفة كيفية استخدام Snips NLU، يرجى الرجوع إلى وثائق الحزمة، وسوف تزودك بدليل خطوة بخطوة حول كيفية إعداد هذه المكتبة واستخدامها.
يرجى ذكر الورقة التالية عند استخدام Snips NLU:
@article { coucke2018snips ,
title = { Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces } ,
author = { Coucke, Alice and Saade, Alaa and Ball, Adrien and Bluche, Th{'e}odore and Caulier, Alexandre and Leroy, David and Doumouro, Cl{'e}ment and Gisselbrecht, Thibault and Caltagirone, Francesco and Lavril, Thibaut and others } ,
journal = { arXiv preprint arXiv:1805.10190 } ,
pages = { 12--16 } ,
year = { 2018 }
}يرجى الانضمام إلى المنتدى لطرح أسئلتك والحصول على تعليقات من المجتمع.
يرجى الاطلاع على إرشادات المساهمة.
يتم توفير هذه المكتبة بواسطة Snips كبرنامج مفتوح المصدر. راجع الترخيص لمزيد من المعلومات.
تعتمد الكيانات المضمنة في القصاصات/المدينة والقصاصات/البلد والقصاصات/المنطقة على برنامج من Geonames، والذي يتم توفيره بموجب ترخيص Creative Commons Attribution 4.0 الدولي. للحصول على الترخيص والضمانات الخاصة بـ Geonames، يرجى الرجوع إلى: https://creativecommons.org/licenses/by/4.0/legalcode.


