ChatLM mini Chinese
1.0.0
الصينية | انجليزية
تميل نماذج اللغات الكبيرة اليوم إلى أن تحتوي على معلمات كبيرة، وأجهزة الكمبيوتر المخصصة للمستهلكين بطيئة في القيام بالاستدلال البسيط، ناهيك عن تدريب النموذج من الصفر. الهدف من هذا المشروع هو تدريب نموذج لغة توليدي من الصفر، بما في ذلك تنظيف البيانات، والتدريب على الرموز المميزة، والتدريب المسبق للنموذج، وضبط تعليمات SFT، وتحسين RLHF، وما إلى ذلك.
ChatLM-mini-Chinese هو نموذج حوار صيني صغير يحتوي على 0.2B فقط من معلمات النموذج (حوالي 210M بما في ذلك الأوزان المشتركة)، ويمكن تدريبه مسبقًا على جهاز مزود بذاكرة فيديو لا تقل عن 4 جيجابايت ( batch_size=1 أو fp16 أو bf16 . )، ويتطلب التحميل والاستدلال float16 ما لا يقل عن 512 ميجابايت من ذاكرة الفيديو.
Huggingface NLP، بما في ذلك transformers ، accelerate ، trl ، peft ، وما إلى ذلك.trainer الذي يتم تنفيذه ذاتيًا التدريب المسبق وضبط SFT على جهاز واحد باستخدام بطاقة واحدة أو مع بطاقات متعددة على جهاز واحد. وهو يدعم التوقف في أي موقف أثناء التدريب ومواصلة التدريب في أي موقف.Text-to-Text والتدريب المسبق على التنبؤ بدون mask .sentencepiece huggingface tokenizers ؛batch_size=1, max_len=320 ، يتم دعم التدريب المسبق على جهاز مزود بذاكرة سعة 16 جيجابايت على الأقل + ذاكرة فيديو سعة 4 جيجابايت؛trainer الذي يتم تنفيذه ذاتيًا الضبط الدقيق للأوامر السريعة ويدعم أي نقطة توقف لمواصلة التدريب؛sequence to sequence تسلسل Huggingface trainer ؛peft lora لتحسين التفضيلات؛Lora adapter في النموذج الأصلي.إذا كنت بحاجة إلى القيام بالتوليد المعزز للاسترجاع (RAG) استنادًا إلى نماذج صغيرة، فيمكنك الرجوع إلى مشروعي الآخر Phi2-mini-Chinese للحصول على الكود، راجع rag_with_langchain.ipynb
آخر التحديثات
تأتي جميع مجموعات البيانات من مجموعات بيانات المحادثة ذات الجولة الواحدة المنشورة على الإنترنت، وبعد تنظيف البيانات وتنسيقها، يتم حفظها كملفات باركيه. للتعرف على عملية معالجة البيانات، راجع utils/raw_data_process.py . تتضمن مجموعات البيانات الرئيسية ما يلي:
Belle_open_source_1M و train_2M_CN و train_3.5M_CN التي تحتوي على إجابات قصيرة، ولا تحتوي على هياكل جدول معقدة ومهام الترجمة (لا توجد قائمة مفردات باللغة الإنجليزية)، إجمالي 3.7 مليون صف، ويبقى 3.38 مليون صف بعد التنظيف.N الأولى في الموسوعة هي الإجابات. باستخدام بيانات الموسوعة 202309 ، يبقى 1.19 مليون مطالبة وإجابة بعد التنظيف. تنزيل Wiki: zhwiki، قم بتحويل ملف bz2 الذي تم تنزيله إلى مرجع wiki.txt: WikiExtractor. العدد الإجمالي لمجموعات البيانات هو 10.23 مليون: مجموعة التدريب المسبق لتحويل النص إلى نص: 9.3 مليون، مجموعة التقييم: 25000 (نظرًا لأن فك التشفير بطيء، لم يتم تعيين مجموعة التقييم كبيرة جدًا). مجموعة الاختبار: 900.000. يتم عرض مجموعات بيانات ضبط SFT وتحسين DPO أدناه.
نموذج T5 (محول نقل النص إلى النص)، راجع الورقة للحصول على التفاصيل: استكشاف حدود نقل التعلم باستخدام محول نص إلى نص موحد.
الكود المصدري للنموذج يأتي من Huggingface، راجع: T5ForConditionalGeneration.
راجع model_config.json للتعرف على تكوين النموذج. T5-base الرسمية: تتكون كل من encoder layer decoder layer من 12 طبقة. في هذا المشروع، تم تعديل هاتين المعلمتين إلى 10 طبقات.
معلمات النموذج: 0.2B. حجم قائمة الكلمات: 29298، بما في ذلك اللغة الصينية فقط وكمية صغيرة من اللغة الإنجليزية.
الأجهزة:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 تدريب الرموز المميزة : تواجه مكتبة تدريب tokenizer الحالية مشكلات OOM عند مواجهة مجموعة كبيرة من النصوص، لذلك يتم دمج المجموعة الكاملة وإنشائها بناءً على تكرار الكلمات وفقًا لطريقة مشابهة لـ BPE ، والتي تستغرق نصف يوم للتشغيل.
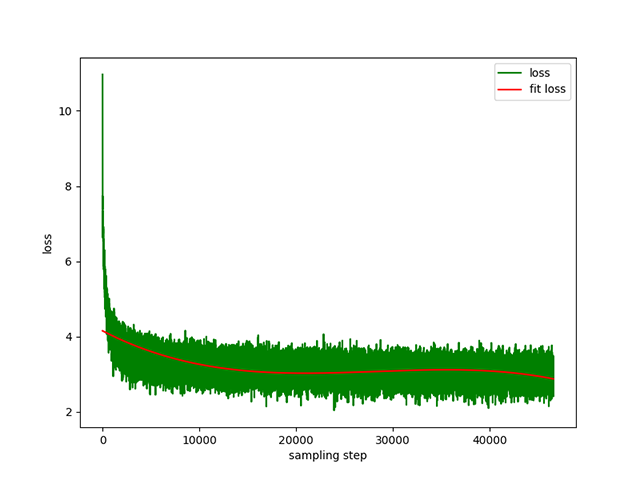
التدريب المسبق على تحويل النص إلى نص : معدل تعلم ديناميكي من 1e-4 إلى 5e-3 ، ووقت تدريب مسبق مدته 8 أيام. خسارة التدريب:
belle (طول كل من التعليمات والإجابة أقل من 512)، ومعدل التعلم هو معدل تعلم ديناميكي من 1e-7 إلى 5e-5 ، ووقت الضبط الدقيق هو 2 أيام. فقدان الضبط الدقيق: 
chosen ، في الخطوة 2 ، generate دفعة نموذج SFT المطالبات في مجموعة البيانات وتحصل على النص rejected ، ويستغرق الأمر يومًا واحدًا لتحسين تفضيل dpo الكامل والتعلم، المعدل هو le-5 ، بنصف الدقة fp16 ، epoch 2 ويستغرق الأمر 3 ساعات. خسارة دي بي أو: 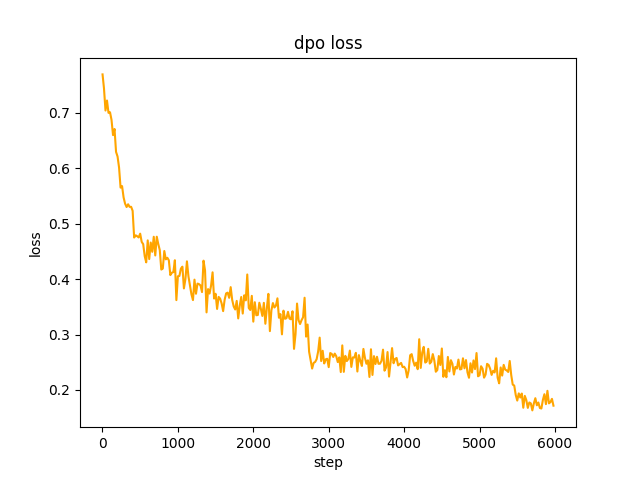
افتراضيًا، يتم استخدام TextIteratorStreamer huggingface transformers لتنفيذ الحوار المتدفق، والذي يدعم فقط greedy search . إذا كنت بحاجة إلى طرق إنشاء أخرى مثل beam sample ، فيرجى تغيير معلمة stream_chat لـ cli_demo.py إلى False . 

هناك مشاكل: تحتوي مجموعة بيانات ما قبل التدريب على أكثر من 9 ملايين فقط، ومعلمات النموذج هي 0.2B فقط، ولا يمكنها تغطية جميع الجوانب، وستكون هناك مواقف تكون فيها الإجابة خاطئة والمولد هراء.
إذا تعذر توصيل Huggingface، فاستخدم modelscope.snapshot_download لتنزيل ملف النموذج من modelscope.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
حذر
نموذج هذا المشروع هو نموذج TextToText في حقول prompt response والحقول الأخرى في مراحل التدريب المسبق وSFT وRLFH، يرجى التأكد من إضافة علامة نهاية التسلسل [EOS] .
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese يوصي هذا المشروع باستخدام python 3.10 . قد لا تكون إصدارات python الأقدم متوافقة مع مكتبات الطرف الثالث التي تعتمد عليها.
تركيب النقطة:
pip install -r ./requirements.txtإذا قامت النقطة بتثبيت إصدار وحدة المعالجة المركزية من pytorch، فيمكنك تثبيت إصدار CUDA من pytorch باستخدام الأمر التالي:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118تركيب كوندا:
conda install --yes --file ./requirements.txt استخدم الأمر git لتنزيل أوزان النموذج وملفات التكوين من Hugging Face Hub . تحتاج إلى تثبيت Git LFS أولاً، ثم تشغيل:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save يمكنك أيضًا تنزيله يدويًا مباشرةً من مستودع Hugging Face Hub ChatLM-Chinese-0.2B ونقل الملف الذي تم تنزيله إلى دليل model_save .
يجب أن تكون متطلبات المجموعة كاملة قدر الإمكان. ويوصى بإضافة مجموعات متعددة، مثل الموسوعات، والأكواد، والأبحاث، والمدونات، والمحادثات، وما إلى ذلك.
يعتمد هذا المشروع بشكل أساسي على موسوعة ويكي الصينية. كيفية الحصول على مجموعة الويكي الصينية: عنوان تنزيل Wiki الصيني: zhwiki، قم بتنزيل ملف zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 ، حوالي 2.7 جيجابايت، قم بتحويل ملف bz2 الذي تم تنزيله إلى مرجع wiki.txt: WikiExtractor ، ثم استخدم مكتبة OpenCC الخاصة بـ python لتحويلها إلى اللغة الصينية المبسطة، وأخيرًا ضع ملف wiki.simple.txt الذي تم الحصول عليه في دليل data للدليل الجذر للمشروع. يرجى دمج عدة مجموعات في ملف txt واحد بنفسك.
نظرًا لأن رمز التدريب يستهلك قدرًا كبيرًا من الذاكرة، إذا كان مجموعتك كبيرة جدًا (يتجاوز ملف txt المدمج 2G)، فمن المستحسن أخذ عينة من النص وفقًا للفئات والنسب لتقليل وقت التدريب واستهلاك الذاكرة. يتطلب تدريب ملف txt بحجم 1.7 جيجابايت حوالي 48 جيجابايت من الذاكرة (يقدر أن لدي 32 جيجابايت فقط، مما يؤدي إلى تشغيل المبادلة بشكل متكرر، وتعطل الكمبيوتر لفترة طويلة T_T)، وتستغرق وحدة المعالجة المركزية 13600 كيلو حوالي ساعة واحدة.
الفرق بين char level ومستوى byte level هو كما يلي (يرجى البحث عن المعلومات بنفسك لمعرفة اختلافات الاستخدام المحددة). يقوم أداة الرمز المميز بتدريب char level بشكل افتراضي، إذا كان byte level مطلوبًا، فما عليك سوى تعيين token_type='byte' في train_tokenizer.py .
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']ابدأ التدريب:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab أو دفتر jupyter:
راجع الملف train.ipynb يوصى باستخدام jupyter-lab لتجنب التفكير في الموقف الذي يتم فيه إيقاف العملية الطرفية بعد قطع الاتصال بالخادم.
وحدة التحكم:
يجب أن يأخذ تدريب وحدة التحكم في الاعتبار أنه سيتم إنهاء العملية بعد قطع الاتصال. يوصى باستخدام Supervisor أو أداة البرنامج screen للعملية لإنشاء جلسة اتصال.
أولاً، قم بتكوين accelerate ، وقم بتنفيذ الأمر التالي، ثم حدد وفقًا للمطالبات، راجع accelerate.yaml . ملاحظة: يعد تثبيت DeepSpeed على نظام التشغيل Windows أكثر صعوبة .
accelerate config ابدأ التدريب. إذا كنت تريد استخدام التكوين الذي يوفره المشروع، فيرجى إضافة المعلمة --config_file ./accelerate.yaml بعد الأمر التالي accelerate launch . يعتمد التكوين على تكوين 2xGPU للجهاز الواحد.
هناك نصان للتدريب المسبق. المدرب المطبق في هذا المشروع يتوافق مع train.py ، والمدرب المطبق بواسطة Huggingface يتوافق مع pre_train.py . يمكنك استخدام أي منهما وسيكون التأثير هو نفسه. يعرض المدرب المطبق في هذا المشروع معلومات تدريب أكثر جمالا ويسهل تعديل تفاصيل التدريب (مثل وظائف الخسارة وسجلات السجل وما إلى ذلك). جميع نقاط التوقف الداعمة لمواصلة التدريب تدعم المدرب المطبق في هذا المشروع التدريب المستمر بعد ذلك نقطة التوقف في أي موضع، اضغط على ctrl+c لحفظ معلومات نقطة التوقف عند الخروج من البرنامج النصي.
آلة واحدة وبطاقة واحدة:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py جهاز واحد مزود ببطاقات متعددة: 2 هو عدد بطاقات الرسومات، يرجى تعديله وفقًا لحالتك الفعلية.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyمواصلة التدريب من نقطة التوقف:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyمجموعة بيانات SFT كلها تأتي من مساهمة رئيس BELLE، شكرًا لك. مجموعات بيانات SFT هي: generator_chat_0.4M وtrain_0.5M_CN وtrain_2M_CN، مع بقاء ما يقرب من 1.37 مليون صف بعد التنظيف. مثال على ضبط مجموعة البيانات باستخدام الأمر sft:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} قم بإنشاء مجموعة البيانات الخاصة بك عن طريق الرجوع إلى نموذج ملف parquet في دليل data . تنسيق مجموعة البيانات هو: ملف parquet مقسم إلى عمودين، عمود واحد من نص prompt ، الذي يمثل المطالبة، وعمود واحد من نص response ، والذي يمثل مخرجات النموذج المتوقعة. للحصول على تفاصيل الضبط الدقيق، راجع طريقة train ضمن model/trainer.py عندما يتم ضبط is_finetune على True ، سيتم إجراء الضبط الدقيق على تجميد طبقة التضمين وطبقة التشفير بشكل افتراضي، وتدريب وحدة فك التشفير فقط طبقة. إذا كنت بحاجة إلى تجميد معلمات أخرى، يرجى ضبط الكود بنفسك.
تشغيل الضبط الدقيق لـ SFT:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyفيما يلي طريقتان مفضلتان شائعتان: PPO وDPO، يرجى البحث في الأوراق والمدونات عن عمليات تنفيذ محددة.
طريقة PPO (تحسين التفضيلات التقريبية، تحسين السياسة القريبة)
الخطوة 1: استخدم مجموعة بيانات الضبط الدقيق لإجراء الضبط الدقيق تحت الإشراف (SFT، الضبط الدقيق تحت الإشراف).
الخطوة 2: استخدم مجموعة بيانات التفضيلات (تحتوي المطالبة على استجابتين على الأقل، استجابة واحدة مطلوبة واستجابة واحدة غير مرغوب فيها. يمكن فرز الاستجابات المتعددة حسب النتيجة، مع حصول الاستجابة الأكثر طلبًا على أعلى الدرجات) لتدريب نموذج المكافأة (RM) ، نموذج المكافأة). يمكنك استخدام مكتبة peft لبناء نموذج مكافأة Lora بسرعة.
الخطوة 3: استخدم RM لإجراء تدريب PPO تحت الإشراف على نموذج SFT بحيث يلبي النموذج التفضيلات.
استخدم الضبط الدقيق DPO (التحسين المباشر للتفضيلات) ( يستخدم هذا المشروع طريقة الضبط الدقيق DPO التي توفر ذاكرة الفيديو ، على أساس الحصول على نموذج SFT، ليست هناك حاجة لتدريب نموذج المكافأة للحصول على إجابات إيجابية ( تم اختياره) والإجابات السلبية (المرفوضة) لبدء الضبط الدقيق. يأتي النص chosen بدقة من مجموعة البيانات الأصلية alpaca-gpt4-data-zh، ويأتي النص rejected من مخرجات النموذج بعد ضبط SFT الدقيق لمجموعتي البيانات الأخريين: huozi_rlhf_data_json وrlhf-reward-. جولة واحدة عبر الصين، بعد دمج إجمالي 80.000 بيانات dpo.
للتعرف على عملية معالجة مجموعة بيانات dpo، راجع utils/dpo_data_process.py .
مثال على مجموعة بيانات تحسين تفضيلات DPO:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}تشغيل تحسين التفضيلات:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py تأكد من وجود الملفات التالية في دليل model_save ، ويمكن العثور على هذه الملفات في مستودع Hugging Face Hub ChatLM-Chinese-0.2B:
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
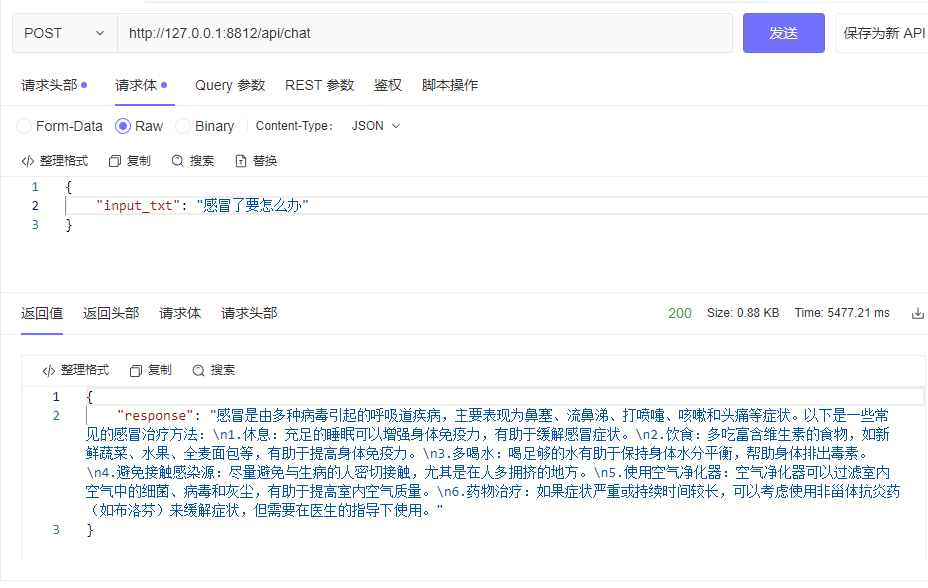
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyمثال لاستدعاء واجهة برمجة التطبيقات:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
نحن هنا نأخذ المعلومات الثلاثية في النص كمثال لإجراء الضبط الدقيق. للتعرف على طريقة استخراج التعلم العميق التقليدية لهذه المهمة، راجع نموذج المستودع pytorch_IE_model. استخرج جميع الثلاثيات في قطعة من النص، مثل جملة 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮، واستخرج الثلاثيات (写生随笔,作者,张来亮) و (写生随笔,出版社,冶金工业) ) (写生随笔,出版社,冶金工业) .
مجموعة البيانات الأصلية هي: مجموعة بيانات استخراج بايدو الثلاثية. مثال على تنسيق مجموعة البيانات المعالجة والمضبوطة بدقة:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} يمكنك استخدام البرنامج النصي sft_train.py مباشرة للضبط الدقيق. يحتوي البرنامج النصي Finetune_IE_task.ipynb على عملية فك التشفير التفصيلية. تحتوي مجموعة بيانات التدريب على حوالي 17000 عنصر، ومعدل التعلم 5e-5 ، وعصر التدريب 5 . ولم تختف إمكانيات الحوار للمهام الأخرى بعد الضبط الدقيق.

تأثير الضبط الدقيق: استخدم مجموعة بيانات dev التي نشرتها百度三元组抽取数据集كمجموعة اختبار للمقارنة مع الطريقة التقليدية pytorch_IE_model.
| نموذج | نتيجة F1 | الدقة P | أذكر ر |
|---|---|---|---|
| ChatLM-Chinese-0.2B صقل | 0.74 | 0.75 | 0.73 |
| ChatLM-Chinese-0.2B بدون تدريب مسبق | 0.51 | 0.53 | 0.49 |
| طرق التعلم العميق التقليدية | 0.80 | 0.79 | 80.1 |
ملحوظة: ChatLM-Chinese-0.2B无预训练يعني تهيئة المعلمات العشوائية مباشرة وبدء التدريب بمعدل تعلم 1e-4 تتوافق المعلمات الأخرى مع الضبط الدقيق.
لم يتم تدريب النموذج نفسه باستخدام مجموعة بيانات أكبر، ولم يتم ضبطه بشكل دقيق لتعليمات الإجابة على أسئلة الاختيار من متعدد. تعتبر درجة C-Eval في الأساس مستوى أساسي ويمكن استخدامها كمرجع إذا لزم الأمر. رمز تقييم C-Eval راجع: eval/c_eavl.ipynb
| فئة | صحيح | question_count | دقة |
|---|---|---|---|
| العلوم الإنسانية | 63 | 257 | 24.51% |
| آخر | 89 | 384 | 23.18% |
| ينبع | 89 | 430 | 20.70% |
| العلوم الاجتماعية | 72 | 275 | 26.18% |
إذا كنت تعتقد أن هذا المشروع مفيد لك، يرجى ذكره.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
لا يتحمل هذا المشروع أي مخاطر ومسؤوليات ناشئة عن مخاطر أمن البيانات والرأي العام الناجمة عن النماذج والأكواد مفتوحة المصدر، أو أي نموذج يتم تضليله أو إساءة استخدامه أو نشره أو استغلاله بشكل غير صحيح.


