local LLM with RAG
1.0.0

هذا المشروع عبارة عن صندوق اختبار تجريبي لاختبار الأفكار المتعلقة بتشغيل نماذج اللغات الكبيرة المحلية (LLMs) مع Ollama لإجراء عملية توليد الاسترجاع المعزز (RAG) للإجابة على الأسئلة بناءً على نماذج ملفات PDF. في هذا المشروع، نستخدم أيضًا Ollama لإنشاء عمليات تضمين باستخدام نص التضمين الاسمي لاستخدامه مع Chroma. يرجى ملاحظة أنه يتم إعادة تحميل التضمينات في كل مرة يتم فيها تشغيل التطبيق، وهو أمر غير فعال ويتم إجراؤه هنا فقط لأغراض الاختبار.
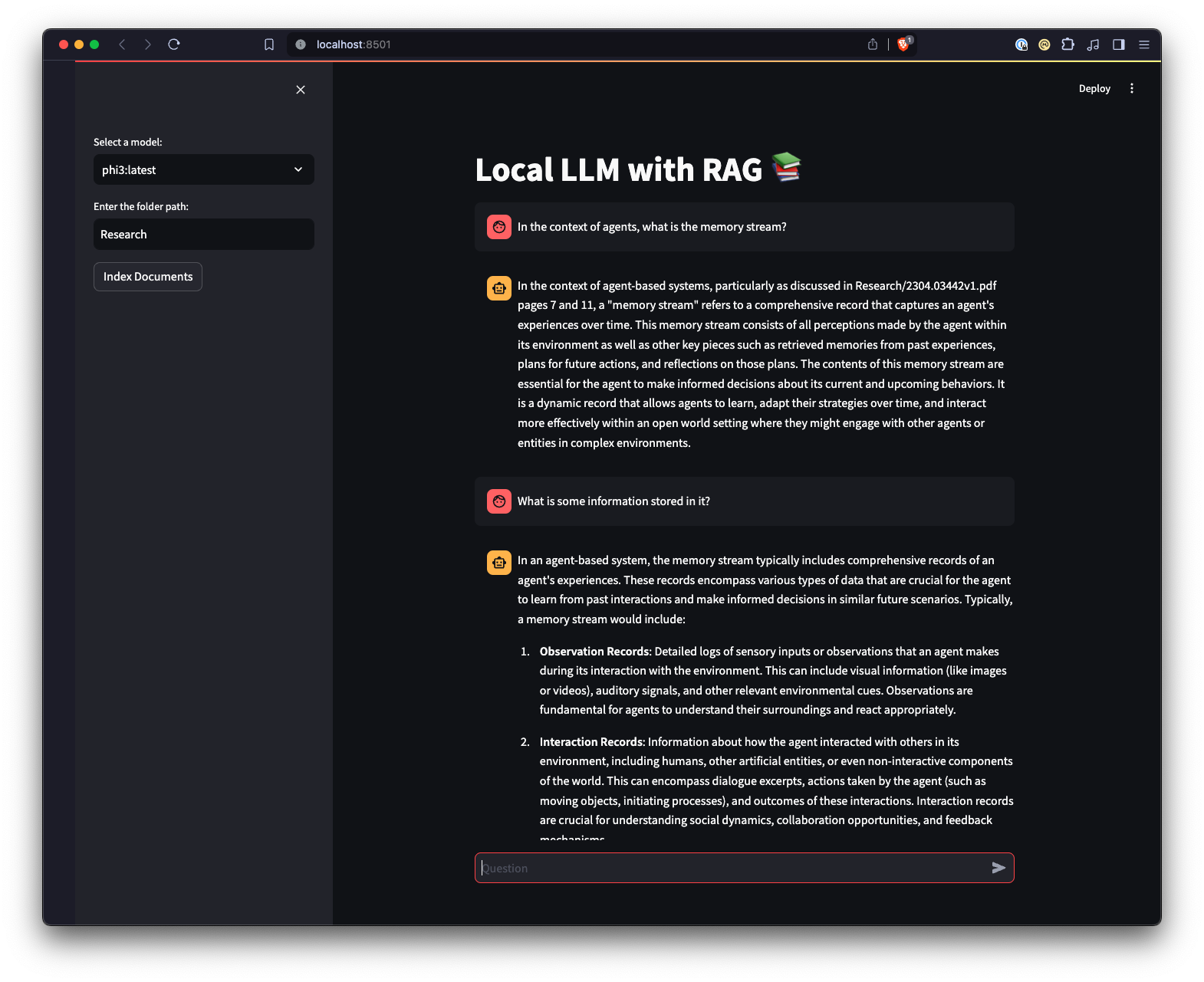
هناك أيضًا واجهة مستخدم ويب تم إنشاؤها باستخدام Streamlit لتوفير طريقة مختلفة للتفاعل مع Ollama.
python3 -m venv .venv .source .venv/bin/activate على Unix أو MacOS، أو ..venvScriptsactivate على Windows.pip install -r requirements.txt . ملاحظة: في المرة الأولى التي تقوم فيها بتشغيل المشروع، سيتم تنزيل النماذج الضرورية من Ollama لماجستير القانون والتضمين. هذه عملية إعداد تتم لمرة واحدة وقد تستغرق بعض الوقت حسب اتصالك بالإنترنت.
python app.py -m <model_name> -p <path_to_documents> لتحديد النموذج والمسار إلى المستندات. إذا لم يتم تحديد أي نموذج، فسيتم تعيينه افتراضيًا على ميسترال. إذا لم يتم تحديد مسار، فسيتم تعيينه افتراضيًا على Research الموجود في المستودع على سبيل المثال للأغراض.-e <embedding_model_name> . إذا لم يتم تحديده، فسيتم تعيينه افتراضيًا على nomic-embed-text. سيؤدي هذا إلى تحميل ملفات PDF وملفات Markdown، وإنشاء التضمينات، والاستعلام عن المجموعة، والإجابة على السؤال المحدد في app.py .
ui.pystreamlit run ui.py في جهازك الطرفي.سيؤدي هذا إلى تشغيل خادم ويب محلي وفتح علامة تبويب جديدة في متصفح الويب الافتراضي الخاص بك حيث يمكنك التفاعل مع التطبيق. تتيح لك واجهة المستخدم Streamlit تحديد النماذج وتحديد مجلد، مما يوفر طريقة أسهل وأكثر سهولة للتفاعل مع نظام RAG chatbot مقارنة بواجهة سطر الأوامر. سيتعامل التطبيق مع تحميل المستندات، وإنشاء التضمينات، والاستعلام عن المجموعة، وعرض النتائج بشكل تفاعلي.


