duplicut
v2.2 release
في الوقت الحاضر، عادةً ما يتضمن إنشاء قائمة كلمات المرور ربط مصادر بيانات متعددة.
من الناحية المثالية، يجب أن تكون معظم كلمات المرور المحتملة في بداية قائمة الكلمات، بحيث يتم اختراق معظم كلمات المرور الشائعة على الفور.
باستخدام أدوات إلغاء البيانات المكررة الموجودة، فإنك مجبر على الاختيار ما إذا كنت تفضل الحفاظ على الترتيب أو التعامل مع قوائم الكلمات الضخمة .
لسوء الحظ، يتطلب إنشاء قائمة الكلمات كلا من :

لذا كتبت نسخة مكررة بلغة C مُحسَّنة للغاية لتلبية هذه الحاجة المحددة للغاية؟
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt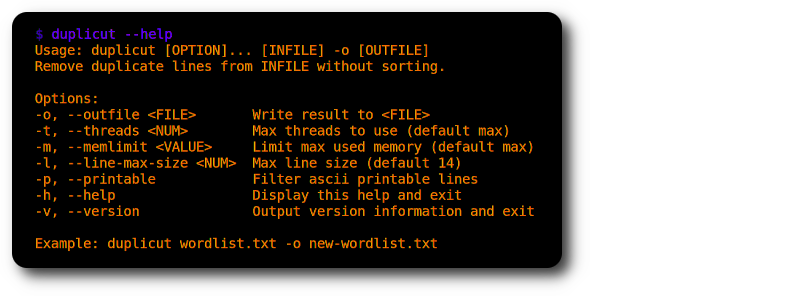
سمات :
-l )-p )تطبيق :
القيود :
يعد uint64 كافيًا لفهرسة الخطوط في hashmap، عن طريق تعبئة معلومات size داخل البتات الإضافية للمؤشر:
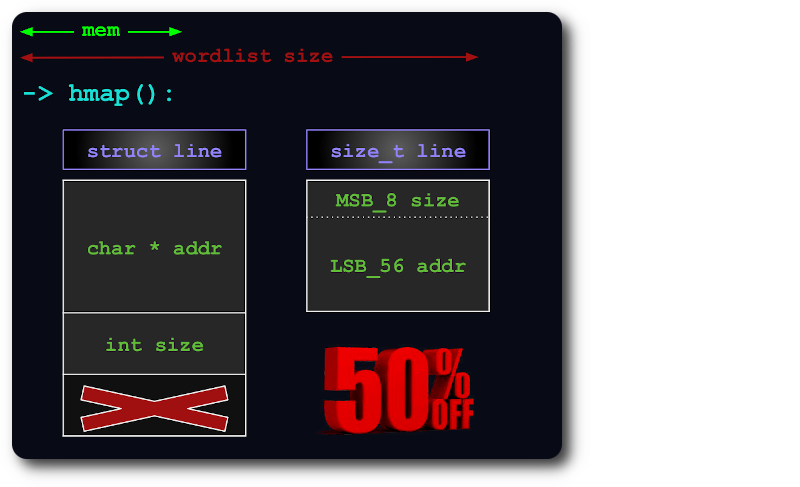
إذا لم يكن من الممكن احتواء الملف بأكمله في الذاكرة، فسيتم تقسيمه إلى أجزاء افتراضية، بحيث تستخدم كل قطعة أكبر قدر ممكن من ذاكرة الوصول العشوائي (RAM).
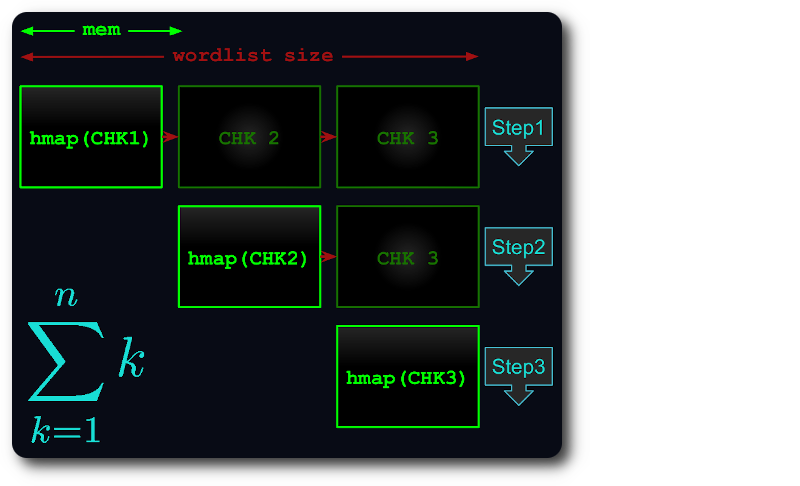
يتم بعد ذلك تحميل كل قطعة في خريطة التجزئة واستخلاصها واختبارها مقابل الأجزاء اللاحقة.
بهذه الطريقة، ينخفض وقت التنفيذ إلى رقم المثلث على الأكثر:
إذا وجدت خطأ ما، أو أن شيئًا ما لا يعمل كما هو متوقع، فيرجى تجميع النسخة المكررة في وضع التصحيح ونشر مشكلة بالمخرجات المرفقة:
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log


