Seq2seq Chatbot for Keras
1.0.0
يحتوي هذا المستودع على نموذج توليدي جديد لبرنامج chatbot يعتمد على نمذجة seq2seq. يمكن العثور على مزيد من التفاصيل حول هذا النموذج في القسم 3 من ورقة التعلم التنافسي الشامل لوكلاء المحادثة التوليديين. في حالة النشر باستخدام أفكار أو أجزاء من التعليمات البرمجية من هذا المستودع، يرجى التكرم بالاستشهاد بهذه الورقة.
استخدم النموذج المدرّب المتوفر هنا مجموعة بيانات صغيرة تتألف من حوالي 8 آلاف زوج من السياق (آخر نطقين في الحوار حتى النقطة الحالية) والاستجابة ذات الصلة. تم جمع البيانات من حوارات دورات اللغة الإنجليزية عبر الإنترنت. يمكن ضبط هذا النموذج المدرّب بدقة باستخدام مجموعة بيانات المجال المغلق لتطبيقات العالم الحقيقي.
أصبح نموذج seq2seq الأساسي شائعًا في الترجمة الآلية العصبية، وهي مهمة لها توزيعات احتمالية سابقة مختلفة للكلمات التي تنتمي إلى تسلسلات الإدخال والإخراج، نظرًا لأن عبارات الإدخال والإخراج مكتوبة بلغات مختلفة. تفترض البنية المعروضة هنا نفس التوزيعات السابقة لكلمات الإدخال والإخراج. ولذلك، فإنه يشترك في طبقة التضمين (تضمين الكلمات المدربة مسبقًا بواسطة القفاز) بين عمليتي التشفير وفك التشفير من خلال اعتماد نموذج جديد. لتحسين حساسية السياق، يقوم ناقل الفكر (أي مخرجات برنامج التشفير) بتشفير النطقين الأخيرين للمحادثة حتى النقطة الحالية. لتجنب نسيان السياق أثناء إنشاء الإجابات، يتم ربط متجه الفكر بمتجه كثيف يقوم بتشفير الإجابة غير الكاملة التي تم إنشاؤها حتى النقطة الحالية. يتم توفير المتجه الناتج إلى طبقات كثيفة تتنبأ بالرمز المميز الحالي للإجابة. راجع القسم 3.1 من ورقتنا للحصول على فكرة أفضل عن مزايا نموذجنا.
تتكرر الخوارزمية من خلال تضمين الرمز المميز المتوقع في الإجابة غير الكاملة وإعادته إلى طبقة الإدخال اليمنى من النموذج الموضح أدناه.
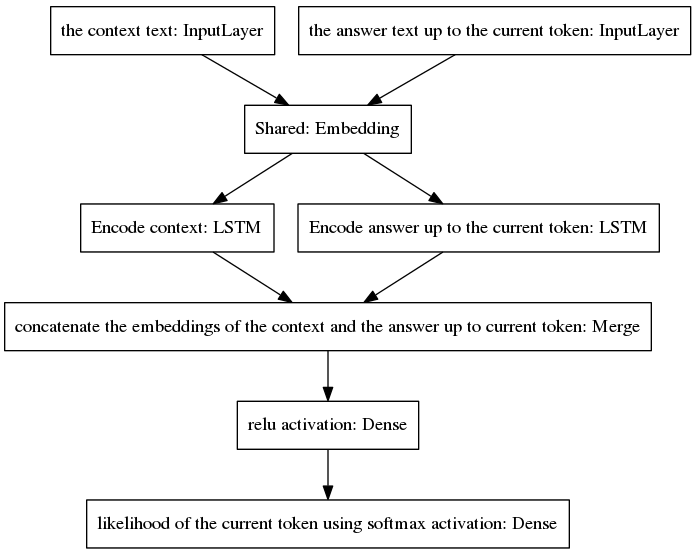
كما هو موضح في الشكل أعلاه، تم ترتيب جهازي LSTM بالتوازي، بينما يحتوي seq2seq الأساسي على طبقات متكررة من التشفير ووحدة فك التشفير مرتبة في سلسلة. يتم الكشف عن الطبقات المتكررة أثناء الانتشار العكسي عبر الزمن، مما يؤدي إلى عدد كبير من الوظائف المتداخلة، وبالتالي زيادة خطر تلاشي التدرج، والذي يتفاقم بسبب سلسلة الطبقات المتكررة لنموذج seq2seq المتعارف عليه، حتى في حالة البنى المسورة مثل LSTMs. أعتقد أن هذا هو أحد الأسباب التي تجعل نموذجي يتصرف بشكل أفضل أثناء التدريب من seq2seq الأساسي.
يشرح الكود الكاذب التالي الخوارزمية.

يتقارب تدريب هذا النموذج الجديد في فترات قليلة. باستخدام مجموعة البيانات الخاصة بنا المكونة من أمثلة تدريب 8K، كان الأمر يتطلب 100 حقبة فقط للوصول إلى خسارة إنتروبيا فئوية تبلغ 0.0318، بتكلفة 139 ثانية/حقبة تعمل في وحدة معالجة الرسومات GTX980. يبدو أداء هذا النموذج المدرب (المقدم في هذا المستودع) مقنعًا مثل أداء نموذج Vanilla seq2seq الذي تم تدريبه على أمثلة تدريب تبلغ حوالي 300 ألف من مجموعة Cornell Movie Dialogs Corpus، ولكنه يتطلب جهدًا حسابيًا أقل بكثير للتدريب.
للدردشة مع النموذج المُدرب مسبقًا:
قم بتنزيل ملف python "conversation.py"، وملف المفردات "vocabulary_movie"، والأوزان الصافية "my_model_weights20"، والتي يمكن العثور عليها هنا؛
قم بتشغيل المحادثة.py.
للدردشة مع النموذج الجديد الذي تم تدريبه بواسطة خوارزمية التدريب الجديدة المستندة إلى GAN:
قم بتنزيل ملف python "conversation_discriminator.py"، وملف المفردات "vocabulary_movie"، والأوزان الصافية "my_model_weights20.h5"، و"my_model_weights.h5"، و"my_model_weights_discriminator.h5"، والتي يمكن العثور عليها هنا؛
قم بتشغيل المحادثة_discriminator.py.
يتمتع هذا النموذج بأداء أفضل باستخدام نفس بيانات التدريب. يتم استخدام أداة تمييز النموذج القائم على GAN لاختيار أفضل إجابة بين نموذجين، أحدهما تم تدريبه بواسطة إجبار المعلم والآخر تم تدريبه بواسطة طريقة التدريب الجديدة المشابهة لـ GAN، والتي يمكن العثور على تفاصيلها في هذه الورقة.
لتدريب نموذج جديد أو لضبط البيانات الخاصة بك:
إذا كنت تريد التدريب من الصفر، فاحذف الملف my_model_weights20.h5. لتحسين بياناتك، احتفظ بهذا الملف؛
قم بتنزيل مجلد Glove "glove.6B" وقم بتضمين هذا المجلد في دليل chatbot (يمكنك العثور على هذا المجلد هنا). تطبق هذه الخوارزمية نقل التعلم باستخدام تضمين الكلمات المدرب مسبقًا، والذي يتم ضبطه جيدًا أثناء التدريب؛
قم بتشغيل Split_qa.py لتقسيم محتوى بيانات التدريب الخاصة بك إلى ملفين: "context" و"answers" وget_train_data.py لتخزين الجمل المبطنة في الملفين "Padded_context" و"Padded_answers"؛
قم بتشغيل Train_bot.py لتدريب chatbot (يوصى باستخدام GPU، للقيام بذلك اكتب: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,exception_verbosity=high python Train_bot.py);
قم بتسمية بيانات التدريب الخاصة بك باسم "data.txt". يجب أن يحتوي هذا الملف على جملة حوار واحدة في كل سطر. إذا كانت مجموعة البيانات الخاصة بك كبيرة، فقم بتعيين المتغير num_subsets (في السطر 29 من Train_bot.py) على رقم أكبر.
ملف الأوزان = 'my_model_weights20.h5' الأوزان_ملف_GAN = 'my_model_weights.h5' الأوزان_ملف_discrim = 'my_model_weights_discriminator.h5'
يمكن العثور هنا على نظرة عامة لطيفة على التطبيقات الحالية لنماذج المحادثة العصبية لأطر عمل مختلفة (مع بعض النتائج).
يمكن تطبيق نموذجنا على مهام البرمجة اللغوية العصبية الأخرى، مثل تلخيص النص، انظر على سبيل المثال البديل 2: النموذج العودي أ. نحن نشجع تطبيق نموذجنا في مهام أخرى، وفي هذه الحالة، نرجو منك الاستشهاد بعملنا قدر الإمكان. يمكن رؤيتها في هذه الوثيقة، المسجلة في يوليو 2017.
يمكن تشغيل هذه الرموز في Ubuntu 14.04.3 LTS وPython 2.7.6 وTheano 0.9.0 وKeras 2.0.4. قد يتطلب استخدام تكوين آخر بعض التعديلات الطفيفة.


