Okapi
1.0.0
أوكابي
نماذج لغة كبيرة مضبوطة للتعليمات بلغات متعددة مع تعزيز التعلم من ردود الفعل البشرية
هذا هو الريبو الخاص بإطار عمل Okapi الذي يقدم موارد ونماذج لضبط التعليمات لنماذج اللغات الكبيرة (LLMs) مع التعلم المعزز من ردود الفعل البشرية (RLHF) بلغات متعددة. يدعم إطار عملنا 26 لغة، بما في ذلك 8 لغات عالية الموارد، و11 لغة متوسطة الموارد، و7 لغات منخفضة الموارد.
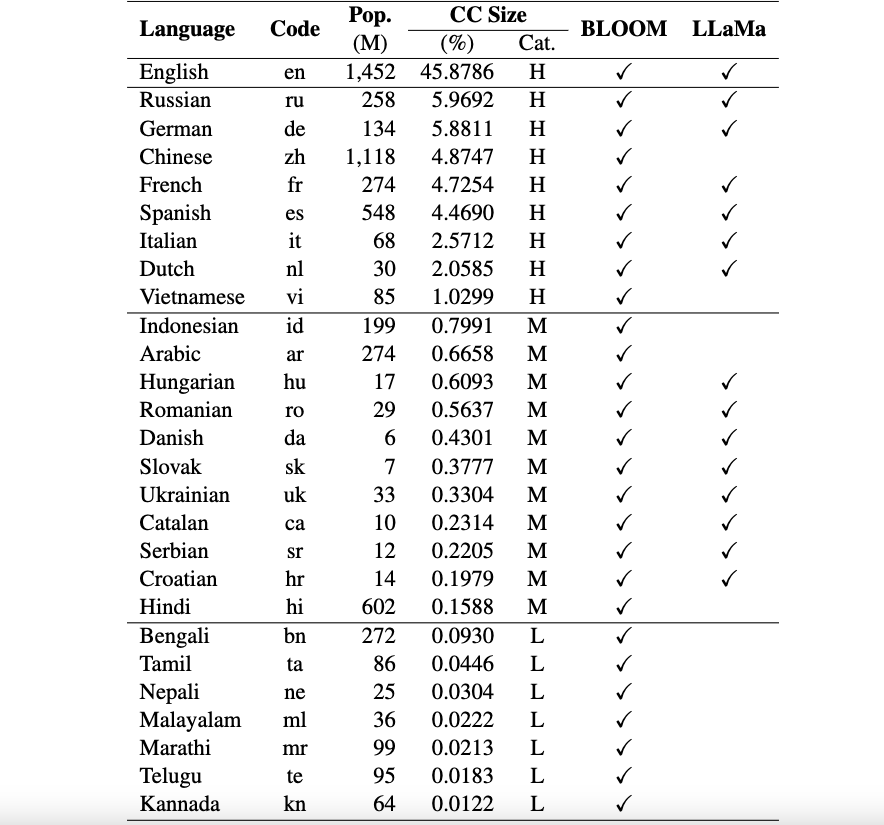
موارد Okapi : نحن نقدم موارد لإجراء ضبط التعليمات باستخدام RLHF لـ 26 لغة، بما في ذلك مطالبات ChatGPT ومجموعات بيانات التعليمات متعددة اللغات وبيانات تصنيف الاستجابة متعددة اللغات.
نماذج Okapi : نحن نقدم دورات LLM مبنية على تعليمات RLHF لـ 26 لغة على مجموعة بيانات Okapi. تشتمل نماذجنا على الإصدارات المستندة إلى BLOOM والإصدارات المستندة إلى LLaMa. نحن نقدم أيضًا نصوصًا برمجية للتفاعل مع نماذجنا وضبط ماجستير إدارة الأعمال (LLM) باستخدام مواردنا.
مجموعات البيانات المعيارية للتقييم متعدد اللغات : نحن نقدم ثلاث مجموعات بيانات مرجعية لتقييم نماذج اللغات الكبيرة متعددة اللغات (LLMs) لـ 26 لغة. يمكنك الوصول إلى مجموعات البيانات الكاملة ونصوص التقييم: هنا.
إشعارات الاستخدام والترخيص : تم تصميم Okapi وترخيصه للاستخدام البحثي فقط. مجموعات البيانات هي CC BY NC 4.0 (تسمح فقط بالاستخدام غير التجاري) ولا ينبغي استخدام النماذج التي تم تدريبها باستخدام مجموعة البيانات خارج أغراض البحث.
يمكن العثور على ورقتنا الفنية مع نتائج التقييم هنا.
نقوم بإجراء عملية جمع بيانات شاملة لإعداد البيانات اللازمة لإطار عملنا متعدد اللغات Okapi في أربع خطوات رئيسية:
لتنزيل مجموعة البيانات بأكملها، يمكنك استخدام البرنامج النصي التالي:
bash scripts/download.shإذا كنت تحتاج فقط إلى البيانات الخاصة بلغة معينة، فيمكنك تحديد رمز اللغة كوسيطة للبرنامج النصي:
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viبعد التنزيل، يمكن العثور على بياناتنا الصادرة في دليل مجموعات البيانات . ويشمل:
multilingual-alpaca-52k : البيانات المترجمة لتعليمات 52K الإنجليزية في الألبكة إلى 26 لغة.
multilingual-ranking-data-42k : بيانات تصنيف الاستجابة متعددة اللغات لـ 26 لغة. لكل لغة، نقدم تعليمات 42K؛ كل واحد منهم لديه 4 ردود مرتبة. يمكن استخدام هذه البيانات لتدريب نماذج المكافآت لـ 26 لغة.
multilingual-rl-tuning-64k : بيانات التعليمات متعددة اللغات لـ RLHF. نحن نقدم تعليمات 62K لكل لغة من اللغات الـ 26.
باستخدام مجموعات بيانات Okapi الخاصة بنا وتقنية ضبط التعليمات المستندة إلى RLHF، نقدم LLMs متعددة اللغات المضبوطة بدقة لـ 26 لغة، مبنية على إصدارات 7B من LLaMA وBLOOM. يمكن الحصول على النماذج من HuggingFace هنا.
يدعم Okapi المحادثات التفاعلية مع دورات LLM متعددة اللغات المضبوطة للتعليمات بـ 26 لغة. اتبع الخطوات التالية للمحادثات:
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )نحن نقدم أيضًا نصوصًا برمجية لضبط LLMs باستخدام بيانات التعليمات الخاصة بنا باستخدام RLHF، والتي تغطي ثلاث خطوات رئيسية: الضبط الدقيق تحت الإشراف، ونمذجة المكافآت، والضبط الدقيق باستخدام RLHF. استخدم الخطوات التالية لضبط LLMs:
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]إذا كنت تستخدم البيانات أو النموذج أو الكود الموجود في هذا المستودع، فيرجى الاستشهاد بما يلي:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

