MELD
1.0.0
إذا كنت مهتمًا ببرامج LLM لاختبار الذكاء، فاطلع على عملنا الجديد: AlgoPuzzleVQA
لقد أصدرنا الميزات المرئية المستخرجة باستخدام Resnet - https://github.com/declare-lab/MM-Align
للحصول على خطوط الأساس المحدثة، يرجى زيارة هذا الرابط: conv-emotion
لتنزيل البيانات، استخدم wget: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
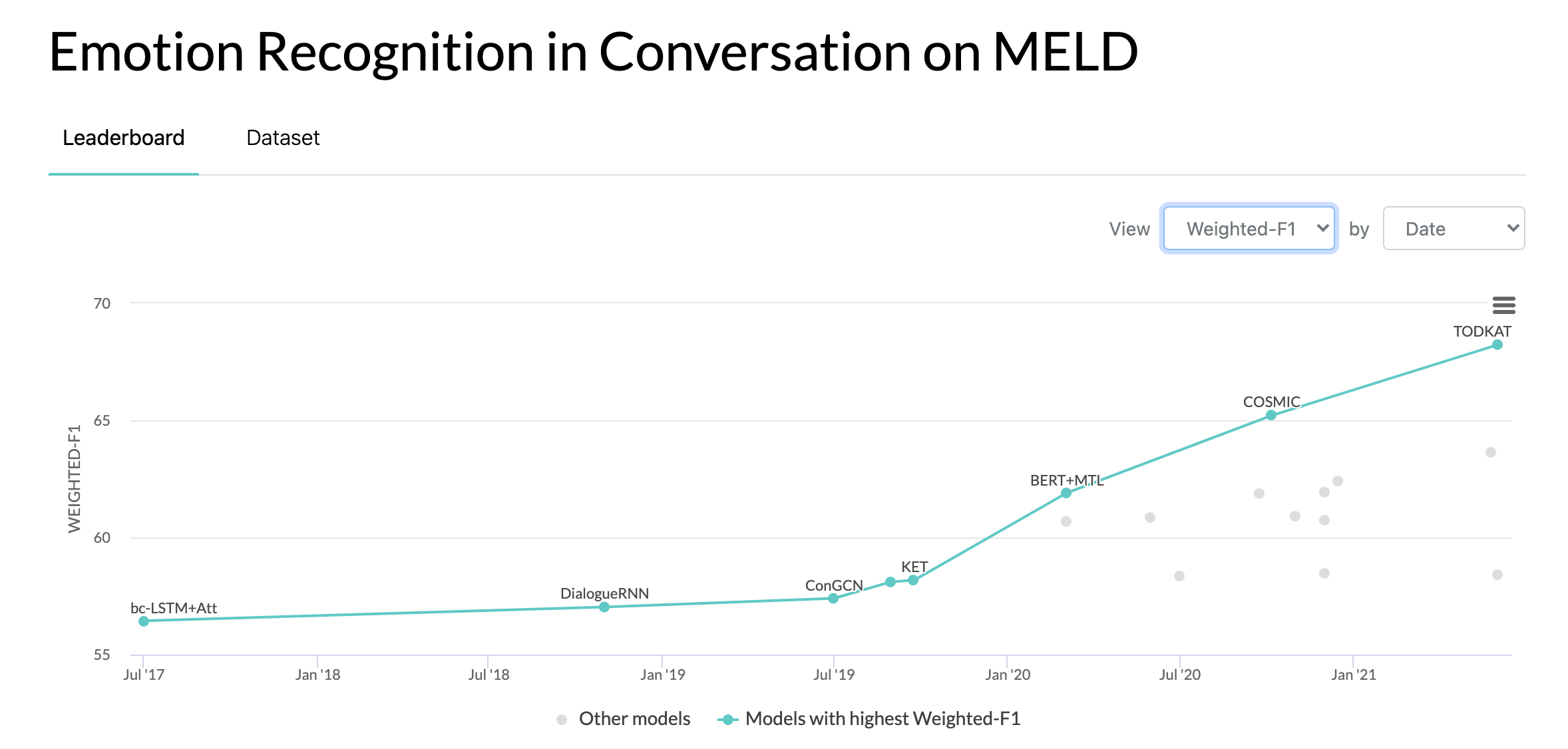
10/10/2020: ورقة بحثية جديدة وSOTA في التعرف على المشاعر في المحادثات على مجموعة بيانات MELD. ارجع إلى دليل COSMIC للحصول على الكود. اقرأ المقال - COSMIC: معرفة CommonSense لتحديد الحركة الإلكترونية في المحادثات.
22/05/2019: MELD: تم قبول مجموعة بيانات متعددة الوسائط للتعرف على المشاعر أثناء المحادثة كورقة كاملة في ACL 2019. يمكن العثور على الورقة المحدثة هنا - https://arxiv.org/pdf/1810.02508. قوات الدفاع الشعبي
22/05/2019: تم إصدار Dyadic MELD. يمكن استخدامه لاختبار نماذج المحادثة الثنائية.
15/11/2018: تم إصلاح المشكلة في Train.tar.gz.
تشانغ، وياتشو، وكيوتشي لي، وداوي سونغ، وبنغ تشانغ، وبانبان وانغ. "الشبكات التفاعلية المستوحاة من الكم لتحليل مشاعر المحادثة." إيجيكي 2019.
تشانغ، دونغ، ليانغقينغ وو، تشانغ لونغ صن، شوشان لي، تشياومينغ تشو، وجودونغ تشو. "نمذجة الاعتماد الحساس للسياق والمتحدث لاكتشاف المشاعر في المحادثات متعددة المتحدثين." إيجيكي 2019.
غوسال، ديبانواي، نافونيل ماجومدير، سوجانيا بوريا، نياتي تشايا، وألكسندر جلبوخ. "DialogueGCN: شبكة عصبية تلافيفية للرسم البياني للتعرف على المشاعر في المحادثة." إي إم إن إل بي 2019.
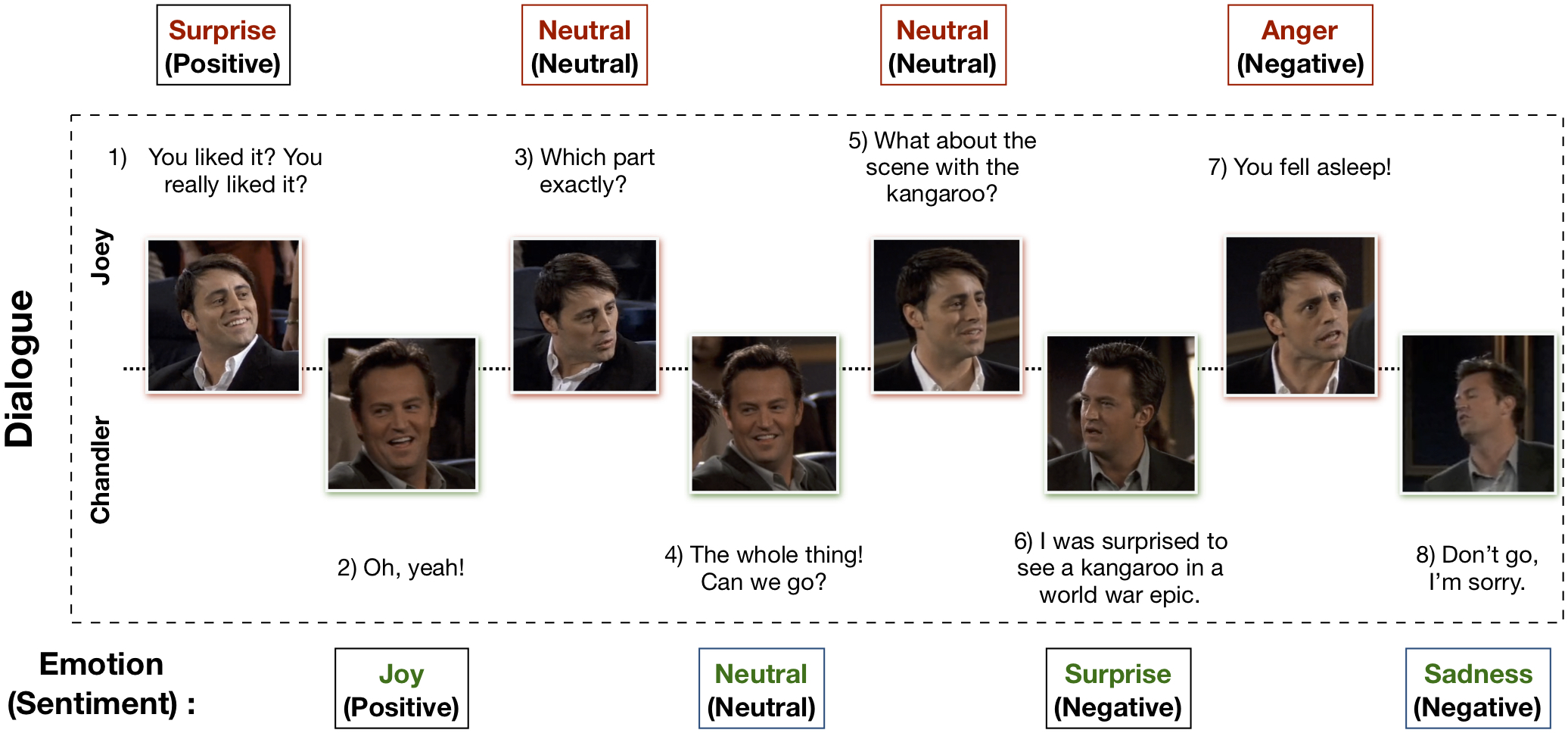
تم إنشاء مجموعة بيانات EmotionLines متعددة الوسائط (MELD) من خلال تحسين مجموعة بيانات EmotionLines وتوسيع نطاقها. يحتوي MELD على نفس مثيلات الحوار المتوفرة في EmotionLines، ولكنه يشمل أيضًا الطريقة الصوتية والمرئية بالإضافة إلى النص. يحتوي MELD على أكثر من 1400 حوار و13000 كلمة من مسلسل Friends TV. وشارك العديد من المتحدثين في الحوارات. يتم تصنيف كل قول في الحوار بأي من هذه المشاعر السبعة - الغضب، والاشمئزاز، والحزن، والفرح، والمحايد، والمفاجأة، والخوف. يحتوي MELD أيضًا على تعليق توضيحي للمشاعر (الإيجابية والسلبية والمحايدة) لكل كلام.
| إحصائيات | يدرب | ديف | امتحان |
|---|---|---|---|
| # من الطريقة | {أ، ت، ر} | {أ، ت، ر} | {أ، ت، ر} |
| # من الكلمات الفريدة | 10,643 | 2,384 | 4,361 |
| متوسط طول الكلام | 8.03 | 7.99 | 8.28 |
| الأعلى. طول الكلام | 69 | 37 | 45 |
| متوسط # من العواطف في الحوار | 3.30 | 3.35 | 3.24 |
| # من الحوارات | 1039 | 114 | 280 |
| # من الأقوال | 9989 | 1109 | 2610 |
| # من المتحدثين | 260 | 47 | 100 |
| #تحول المشاعر | 4003 | 427 | 1003 |
| متوسط مدة الكلام | 3.59 ثانية | 3.59 ثانية | 3.58 ثانية |
يرجى زيارة https://affective-meld.github.io لمزيد من التفاصيل.
| يدرب | ديف | امتحان | |
|---|---|---|---|
| الغضب | 1109 | 153 | 345 |
| الاشمئزاز | 271 | 22 | 68 |
| يخاف | 268 | 40 | 50 |
| مرح | 1743 | 163 | 402 |
| حيادي | 4710 | 470 | 1256 |
| الحزن | 683 | 111 | 208 |
| مفاجأة | 1205 | 150 | 281 |
يستغل تحليل البيانات متعدد الوسائط المعلومات الواردة من قنوات البيانات المتوازية المتعددة لاتخاذ القرار. مع النمو السريع للذكاء الاصطناعي، اكتسب التعرف على المشاعر متعدد الوسائط اهتمامًا بحثيًا كبيرًا، ويرجع ذلك أساسًا إلى تطبيقاته المحتملة في العديد من المهام الصعبة، مثل توليد الحوار والتفاعل متعدد الوسائط وما إلى ذلك. يمكن استخدام نظام التعرف على المشاعر التحادثية لتوليد استجابات مناسبة عن طريق تحليل مشاعر المستخدم. على الرغم من وجود العديد من الأعمال التي تم إجراؤها على التعرف على المشاعر متعددة الوسائط، إلا أن القليل منها فقط يركز فعليًا على فهم المشاعر في المحادثات. ومع ذلك، فإن عملهم يقتصر فقط على فهم المحادثة الثنائية، وبالتالي لا يمكن توسيع نطاقه ليشمل التعرف على المشاعر في المحادثات متعددة الأطراف التي تضم أكثر من مشاركين اثنين. يمكن استخدام EmotionLines كمورد للتعرف على المشاعر للنص فقط، حيث أنه لا يتضمن بيانات من طرق أخرى مثل المرئية والصوتية. وفي الوقت نفسه، تجدر الإشارة إلى أنه لا توجد مجموعة بيانات محادثة متعددة الوسائط ومتعددة الأطراف متاحة لأبحاث التعرف على المشاعر. في هذا العمل، قمنا بتوسيع وتحسين وتطوير مجموعة بيانات EmotionLines للسيناريو متعدد الوسائط. يواجه التعرف على المشاعر في المنعطفات المتسلسلة العديد من التحديات، ويعد فهم السياق أحد هذه التحديات. إن تغير المشاعر وتدفق المشاعر في تسلسل المنعطفات في الحوار يجعل النمذجة الدقيقة للسياق مهمة صعبة. في مجموعة البيانات هذه، بما أننا نستطيع الوصول إلى مصادر البيانات متعددة الوسائط لكل حوار، فإننا نفترض أنها ستحسن نمذجة السياق وبالتالي تستفيد من الأداء العام للتعرف على المشاعر. يمكن أيضًا استخدام مجموعة البيانات هذه لتطوير نظام حوار عاطفي متعدد الوسائط. IEMOCAP وSEMAINE عبارة عن مجموعات بيانات محادثة متعددة الوسائط تحتوي على تسمية عاطفية لكل عبارة. ومع ذلك، فإن مجموعات البيانات هذه ثنائية بطبيعتها، مما يبرر أهمية مجموعة بيانات Multimodal-EmotionLines الخاصة بنا. مجموعات بيانات التعرف على المشاعر والمشاعر المتعددة الوسائط الأخرى المتاحة للجمهور هي MOSEI وMOSI وMOUD. ومع ذلك، لا تعتبر أي من مجموعات البيانات هذه محادثة.
تتناول الخطوة الأولى العثور على الطابع الزمني لكل عبارة في كل حوار موجود في مجموعة بيانات EmotionLines. ولتحقيق ذلك، قمنا بالزحف عبر ملفات الترجمة لجميع الحلقات التي تحتوي على الطابع الزمني لبداية الكلام ونهايته. مكنتنا هذه العملية من الحصول على معرف الموسم ومعرف الحلقة والطابع الزمني لكل عبارة في الحلقة. لقد وضعنا قيدين أثناء الحصول على الطوابع الزمنية: (أ) يجب أن تكون الطوابع الزمنية للكلام في الحوار بترتيب متزايد، (ب) يجب أن تنتمي جميع الأقوال في الحوار إلى نفس الحلقة والمشهد. وكشف التقييد بهذين الشرطين أنه في EmotionLines، تتكون بعض الحوارات من حوارات طبيعية متعددة. قمنا بتصفية تلك الحالات من مجموعة البيانات. بسبب خطوة تصحيح الخطأ هذه، في حالتنا، لدينا عدد مختلف من الحوارات مقارنةً بـ EmotionLines. بعد الحصول على الطابع الزمني لكل عبارة، استخرجنا المقاطع الصوتية والمرئية المقابلة لها من الحلقة المصدر. وبشكل منفصل، قمنا أيضًا بإزالة المحتوى الصوتي من مقاطع الفيديو تلك. وأخيرًا، تحتوي مجموعة البيانات على طريقة مرئية وصوتية ونصية لكل حوار.
يمكن العثور على الورقة التي تشرح مجموعة البيانات هذه - https://arxiv.org/pdf/1810.02508.pdf
يرجى زيارة - http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz لتنزيل البيانات الأولية. يتم تخزين البيانات بتنسيق mp4 ويمكن العثور عليها في ملفات XXX.tar.gz. يمكن العثور على التعليقات التوضيحية في https://github.com/declare-lab/MELD/tree/master/data/MELD.
| اسم العمود | وصف |
|---|---|
| رقم السيد | الأرقام التسلسلية للكلام بشكل أساسي للإشارة إلى الكلام في حالة الإصدارات المختلفة أو النسخ المتعددة مع مجموعات فرعية مختلفة |
| الكلام | الكلام الفردي من EmotionLines كسلسلة. |
| المتحدث | اسم المتكلم المرتبط بالكلام. |
| العاطفة | الانفعال (الحيادية، الفرح، الحزن، الغضب، المفاجأة، الخوف، الاشمئزاز) الذي يعبر عنه المتحدث في الكلام. |
| المشاعر | المشاعر (الإيجابية والمحايدة والسلبية) التي يعبر عنها المتحدث في الكلام. |
| Dialogue_ID | فهرس الحوار يبدأ من 0. |
| معرف_النطق | فهرس اللفظ المعين في الحوار يبدأ من 0. |
| موسم | الموسم لا. من برنامج Friends TV الذي ينتمي إليه كلام معين. |
| حلقة | الحلقة رقم. من برنامج Friends TV في موسم معين ينتمي إليه الكلام. |
| وقت البدء | وقت بدء الكلام في الحلقة المحددة بالتنسيق "hh:mm:ss,ms". |
| وقت النهاية | وقت انتهاء الكلام في الحلقة المحددة بالتنسيق "hh:mm:ss,ms". |
يوجد 13 ملفًا مخللًا يتكون من البيانات والميزات المستخدمة لتدريب النماذج الأساسية. فيما يلي وصف موجز لكل ملف من ملفات المخلل.
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))يوجد نصان برمجيان لبيثون متوفران في "./utils/":
للتجريب، يتم تمثيل جميع التسميات على شكل ترميزات واحدة ساخنة، وتكون مؤشراتها كما يلي:
بالنسبة لخط الأساس لتصنيف المشاعر، تم استخدام أوزان الفئات التالية. الفهرسة هي نفسها كما ذكرنا أعلاه. أوزان الفئة: [4.0، 15.0، 15.0، 3.0، 1.0، 6.0، 3.0].
يرجى اتباع هذه الخطوات لتشغيل خط الأساس -
./data/pickles/baseline/baseline.py كما يلي:python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h للحصول على نص تعليمات للمعلمات../data/models/ . يرجى الاستشهاد بالأوراق التالية إذا وجدت مجموعة البيانات هذه مفيدة في بحثك
S. Poria، D. Hazarika، N. Majumder، G. Naik، E. Cambria، R. Mihalcea. MELD: مجموعة بيانات متعددة الأطراف للتعرف على المشاعر أثناء المحادثة. دوري أبطال آسيا 2019.
Chen, SY, Hsu, CC, Kuo, CC and Ku, LW EmotionLines: مجموعة عاطفية من المحادثات متعددة الأطراف. arXiv طبعة أولية arXiv:1802.08379 (2018).
تم إنشاء مجموعة بيانات الكشف عن المشاعر EmoryNLP متعددة الوسائط من خلال تحسين وتوسيع مجموعة بيانات اكتشاف المشاعر EmoryNLP. وهو يحتوي على نفس مثيلات الحوار المتوفرة في مجموعة بيانات EmoryNLP Emotion Detection، ولكنه يشمل أيضًا الطريقة الصوتية والمرئية إلى جانب النص. يوجد أكثر من 800 حوار و9000 كلام من مسلسل Friends TV في مجموعة بيانات EmoryNLP متعددة الوسائط. وشارك العديد من المتحدثين في الحوارات. تم تصنيف كل كلام في الحوار بأي من هذه المشاعر السبعة - محايد، بهيج، مسالم، قوي، خائف، مجنون، وحزين. يتم استعارة التعليقات التوضيحية من مجموعة البيانات الأصلية.
| إحصائيات | يدرب | ديف | امتحان |
|---|---|---|---|
| # من الطريقة | {أ، ت، ر} | {أ، ت، ر} | {أ، ت، ر} |
| # من الكلمات الفريدة | 9,744 | 2,123 | 2,345 |
| متوسط طول الكلام | 7.86 | 6.97 | 7.79 |
| الأعلى. طول الكلام | 78 | 60 | 61 |
| متوسط # من العواطف في كل مشهد | 4.10 | 4.00 | 4.40 |
| # من الحوارات | 659 | 89 | 79 |
| # من الأقوال | 7551 | 954 | 984 |
| # من المتحدثين | 250 | 46 | 48 |
| #تحول المشاعر | 4596 | 575 | 653 |
| متوسط مدة الكلام | 5.55 ثانية | 5.46 ثانية | 5.27 ثانية |
| يدرب | ديف | امتحان | |
|---|---|---|---|
| بهيجة | 1677 | 205 | 217 |
| مجنون | 785 | 97 | 86 |
| حيادي | 2485 | 322 | 288 |
| سلمي | 638 | 82 | 111 |
| قوي | 551 | 70 | 96 |
| حزين | 474 | 51 | 70 |
| مقدس | 941 | 127 | 116 |
يمكن تنزيل مقاطع الفيديو لمجموعة البيانات هذه من هذا الرابط. يمكن العثور على ملفات التعليقات التوضيحية في https://github.com/SenticNet/MELD/tree/master/data/emorynlp. هناك 3 ملفات .csv. يحتوي كل إدخال في العمود الأول من ملفات CSV هذه على عبارة يمكن العثور على مقطع الفيديو المطابق لها هنا. تتم فهرسة كل عبارة ومقطع الفيديو الخاص بها حسب رقم الموسم ورقم الحلقة ومعرف المشهد ومعرف الكلام. على سبيل المثال، sea1_ep2_sc6_utt3.mp4 يعني أن المقطع يتوافق مع الكلام مع رقم الموسم. 1، الحلقة رقم. 2، ومعرف_المشهد 6، ومعرف_النطق 3. المشهد هو مجرد حوار. تتوافق هذه الفهرسة مع مجموعة البيانات الأصلية. يتم تقسيم ملفات .csv وملفات الفيديو إلى مجموعة التدريب والتحقق والاختبار وفقًا لمجموعة البيانات الأصلية. تم استعارة التعليقات التوضيحية مباشرة من مجموعة بيانات EmoryNLP الأصلية (Zahiri et al. (2018)).
| اسم العمود | وصف |
|---|---|
| الكلام | الكلام الفردي من EmoryNLP كسلسلة. |
| المتحدث | اسم المتكلم المرتبط بالكلام. |
| العاطفة | العاطفة (محايدة، بهيجة، مسالمة، قوية، خائفة، غاضبة، حزينة) التي يعبر عنها المتحدث في الكلام. |
| معرف_المشهد | فهرس الحوار يبدأ من 0. |
| معرف_النطق | فهرس اللفظ المعين في الحوار يبدأ من صفر. |
| موسم | الموسم لا. من برنامج Friends TV الذي ينتمي إليه كلام معين. |
| حلقة | الحلقة رقم. من برنامج Friends TV في موسم معين ينتمي إليه الكلام. |
| وقت البدء | وقت بدء الكلام في الحلقة المحددة بالتنسيق "hh:mm:ss,ms". |
| وقت النهاية | وقت انتهاء الكلام في الحلقة المحددة بالتنسيق "hh:mm:ss,ms". |
ملاحظة : هناك بعض الكلمات التي لم نتمكن من العثور على وقت البداية والنهاية لها بسبب بعض التناقضات في الترجمة. لقد تم حذف مثل هذه العبارات من مجموعة البيانات. ومع ذلك، فإننا نشجع المستخدمين على العثور على العبارات المقابلة من مجموعة البيانات الأصلية وإنشاء مقاطع فيديو لها.
يرجى الاستشهاد بالأوراق التالية إذا وجدت مجموعة البيانات هذه مفيدة في بحثك
S. ظاهري وجي دي تشوي. الكشف عن المشاعر في نصوص البرامج التلفزيونية باستخدام الشبكات العصبية التلافيفية القائمة على التسلسل. في ورشة عمل AAAI حول تحليل المحتوى العاطفي، AFFCON'18، 2018.
S. Poria، D. Hazarika، N. Majumder، G. Naik، E. Cambria، R. Mihalcea. MELD: مجموعة بيانات متعددة الأطراف للتعرف على المشاعر أثناء المحادثة. دوري أبطال آسيا 2019.


