gutenberg dialog
1.0.0
رمز لتنزيل وإنشاء الإصدار الخاص بك من Gutenberg Dialog Dataset. قابلة للتوسيع بسهولة مع لغات جديدة. جرب روبوتات الدردشة المدربة بلغات مختلفة هنا: https://ricsinaruto.github.io/chatbot.html.
| رابط التحميل | عدد الأقوال | متوسط طول الكلام | عدد الحوارات | متوسط طول الحوار |
|---|---|---|---|---|
| إنجليزي | 14773741 | 22.17 | 2526877 | 5.85 |
| الألمانية | 226015 | 24.44 | 43440 | 5.20 |
| هولندي | 129471 | 24.26 | 23541 | 5.50 |
| الأسبانية | 58174 | 18.62 | 6912 | 8.42 |
| ايطالي | 41388 | 19.47 | 6664 | 6.21 |
| المجرية | 18816 | 14.68 | 2826 | 6.66 |
| البرتغالية | 16228 | 21.40 | 2233 | 7.27 |
؟ قم بإنشاء مجموعة البيانات الخاصة بك عن طريق ضبط المعلمات التي تؤثر على مقايضة حجم ونوعية مجموعة البيانات
تسهل الواجهة المعيارية توسيع مجموعة البيانات إلى لغات أخرى
؟ يمكنك بسهولة استبعاد الكتب يدويًا عند إنشاء مجموعة البيانات
قم بتشغيل setup.py الذي يقوم بتثبيت الحزم المطلوبة.
python setup.py
يجب استدعاء الملف الرئيسي من جذر الريبو. يقوم الأمر أدناه بتشغيل مسار بناء مجموعة البيانات للغات المفصولة بفواصل المقدمة كوسيطة. يتم حاليًا دعم اللغات الإنجليزية والألمانية والهولندية والإسبانية والبرتغالية والإيطالية والمجرية.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
يمكن رؤية جميع الوسائط القابلة للتعيين أدناه: 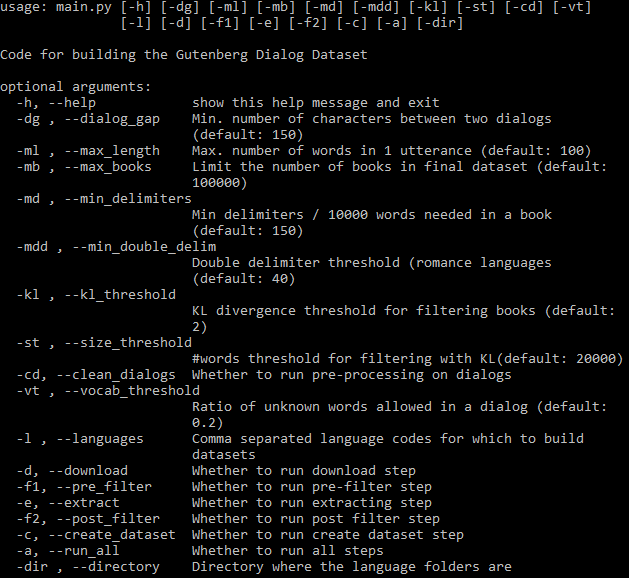
تتحكم العلامة -a في تشغيل خط الأنابيب بالكامل تلقائيًا. إذا تم حذف -a ، فيجب تحديد مجموعة فرعية من الخطوات باستخدام العلامات (انظر المساعدة أعلاه). بمجرد الانتهاء من الخطوة، يمكن استخدام مخرجاتها في الخطوات اللاحقة، ولا يتم تشغيلها مرة أخرى إلا إذا تم تغيير المعلمات أو التعليمات البرمجية المتعلقة بهذه الخطوة. يتم تشغيل كافة الخطوات بشكل منفصل لكل لغة.
تحميل الكتب للغات معينة.
ملاحظة: إذا فشل تنزيل جميع الكتب مع ظهور الخطأ "تعذر تنزيل الكتاب"، فإن السبب المحتمل هو أن المرآة الافتراضية التي تستخدمها حزمة جوتنبرج أصبحت غير قابلة للوصول. في حالة حدوث ذلك، فمن الممكن استخدام أي من المرايا البديلة المدرجة في https://www.gutenberg.org/MIRRORS.ALL عبر متغير البيئة GUTENBERG_MIRROR . على سبيل المثال:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
تعمل التصفية المسبقة على إزالة بعض الكتب القديمة والضوضاء.
يتم استخراج الحوارات من الكتب. عند توسيع مجموعة البيانات إلى لغات جديدة (انظر القسم أدناه)، هذه هي الخطوة التي يمكن تعديلها، وبالتالي يمكن تخطي الخطوات السابقة بمجرد الانتهاء.
خطوة التصفية الثانية هي إزالة بعض مربعات الحوار بناءً على المفردات.
تجميع مجموعة البيانات النهائية وتقسيمها إلى بيانات تدريب/تطوير/اختبار. تقوم الخطوة الأخيرة بإنشاء ملف Author_and_title.txt في دليل الإخراج الذي يحتوي على جميع الكتب (بالإضافة إلى العناوين والمؤلفين) المستخدمة لاستخراج مجموعة البيانات النهائية. يمكن للمستخدمين نسخ الأسطر يدويًا من هذا الملف إلى Banan_books.txt المطابق للكتب التي لا ينبغي السماح بها في مجموعة البيانات. في عمليات التشغيل اللاحقة لأي خطوات، لن يتم أخذ الكتب الموجودة في هذا الملف في الاعتبار.
يمكن توسيع الكود بسهولة لمعالجة اللغات الأخرى. يجب إنشاء ملف باسم <language code>.py في مجلد اللغات. هنا يجب تعريف فئة باسم رمز اللغة الكبير (على سبيل المثال En للغة الإنجليزية)، مع LANG أو أي من الفئات الفرعية الأخرى كأصل. مع معلمات التكوين self.cfg يمكن الوصول إليها. داخل هذه الفئة يجب تحديد الوظائف الثلاثة أدناه. يرجى الاطلاع على it.py للحصول على مثال.
إحصائيات اللغات
يجب أن تقوم هذه الوظيفة بإرجاع قاموس حيث تكون المفاتيح عبارة عن محددات محتملة. يجب تحديد دالة لكل محدد (قيم في القاموس)، والتي تأخذ سطرًا كمدخل وترجع رقمًا. يمكن أن يكون هذا الرقم على سبيل المثال عدد المحددات، أو إشارة إلى ما إذا كان هناك محدد في السطر، وما إلى ذلك. عادةً ما يُنصح بالعد المرجح، اعتمادًا على أهمية المحددات المختلفة. سيتم استخدام القيم لتحديد المحدد الذي يجب استخدامه في الكتاب المعني (يتم تمريره إلى الوظيفة أدناه)، ولتصفية الكتب التي تحتوي على كمية منخفضة من المحددات. يحتوي en.py على أمثلة لمحددات متعددة.
يجب أن تقوم هذه الوظيفة باستخراج مربعات الحوار من الكتاب وإلحاقها بـ self.dialogs ، وهي عبارة عن قائمة من مربعات الحوار، وكل مربع حوار عبارة عن قائمة من العبارات المتتالية. Para_list تحتوي على الكتاب كقائمة من الفقرات المتتالية. المحدد هو المحدد الأكثر شيوعًا في هذا الملف والذي يجب استخدامه لاستخراج مربعات الحوار.
يتم استخدام هذه الوظيفة لمربعات حوار ما بعد المعالجة (على سبيل المثال، إزالة أحرف معينة). فإنه يأخذ كمدخل الكلام. يرجى ملاحظة أن ترميز الكلمات nltk يتم تشغيله تلقائيًا.
هذا المشروع مرخص بموجب ترخيص MIT - راجع ملف الترخيص للحصول على التفاصيل.
يرجى تضمين رابط إلى هذا الريبو إذا كنت تستخدم أيًا من مجموعة البيانات أو الكود في عملك وفكر في الاستشهاد بالورقة التالية:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


