rasa ptbr boilerplate
1.0.4
للنسخة الإنجليزية: README-en
وُلدت الصورة النموذجية كفكرة عامة لمشروع تايس. اليوم، يهدف إلى جعل إنشاء Rasa chatbot أسهل. مع تطور إطار العمل، أصبح التركيز الحالي للنموذج المعياري هو التوثيق المباشر للتعليمات البرمجية.
يمكنك هنا العثور على برنامج chatbot بالكامل باللغة البرتغالية البرازيلية والذي سيساعدك بأمثلة على الحوار والتعليمات البرمجية واستخدام ميزات Rasa.
يمكن تقسيم البنية المعيارية إلى قسمين رئيسيين:
العملية التي تحول ملفات التكوين .yml إلى modelo treinado يحتوي على ذكاء chatbot.
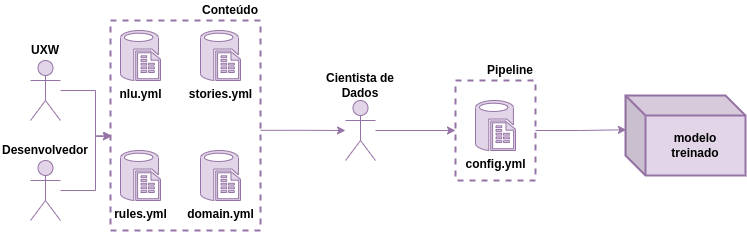
يتفاعل المستخدم مع Boilerplate عبر Telegram، الذي يرسل رسائل إلى Rasa NLU من خلال الموصلات، حيث يحدد القصد ، ويستجيب من خلال Rasa Core، وفقًا للقصص والإجراءات .
تم إنشاء النماذج المستخدمة للمحادثة بواسطة وحدة المدرب ثم نقلها إلى الروبوت. ويمكن إصدار هذه النماذج وتطويرها بين الروبوتات.
أولاً، قم باستنساخ المستودع على جهازك المحلي باستخدام الأمر:
git clone https://github.com/lappis-unb/rasa-ptbr-boilerplate.gitلتشغيل برنامج Rasa chatbot الخاص بك، تأكد من وجودك في مجلد المشروع ثم قم بتشغيل الأمر التالي في الجهاز:
make initسيقوم هذا الأمر ببناء البنية التحتية اللازمة (تحميل الحاويات ذات التبعيات، وتدريب روبوت الدردشة وبدء الدردشة في وضع الصدفة) لتمكين التفاعل مع روبوت الدردشة.
بمجرد تثبيت كل شيء، سترى الرسالة التالية ويمكنك البدء في التفاعل مع الروبوت:
Bot loaded. Type a message and press enter (use ' /stop ' to exit):
Your input - > لإغلاق التفاعل مع الروبوت، فقط اكتب ctrl+c .
make trainmake shellبعد إكمال البرنامج التعليمي للتصدير لجميع متغيرات البيئة الضرورية، يمكنك تشغيل الروبوت بشكل صحيح على Telegram.
قبل المضي قدما. هام: تعد متغيرات البيئة ضرورية لكي يعمل الروبوت بشكل صحيح، لذا لا تنس تصديرها.
ثم قم بتشغيل الروبوت على Telegram:
make telegramلتصور بيانات التفاعل بين المستخدم وروبوت الدردشة، نستخدم جزءًا من Elastic Stack، المكون من ElasticSearch وKibana. لذلك، نستخدم وسيطًا لإدارة الرسائل. لذلك تمكنا من إضافة رسائل إلى ElasticSearch بغض النظر عن نوع برنامج المراسلة الذي نستخدمه.
make build-analyticsانتظر حتى تصبح خدمات ElasticSearch جاهزة، وقم بتشغيل الأمر أدناه لتكوين الفهارس:
make config-elastic
انتظر حتى تصبح خدمات Kibana جاهزة، وقم بتشغيل الأمر أدناه لتكوين لوحات المعلومات :
make config-kibana
يجب تنفيذ الأمر أعلاه مرة واحدة فقط وسيترك البنية التحتية analytics بأكملها جاهزة للاستخدام.
قم بالوصول إلى kibana على عنوان url locahost:5601
إذا كنت تريد فهم عملية تكوين مكدس التحليلات ، فراجع شرح التحليلات الكامل.
يتيح لك Rasa إضافة وحدات مخصصة إلى مسار المعالجة الخاص بك، تعرف على المزيد هنا.
يوجد هنا مثال لمكون مخصص يقوم بتنفيذ تحليل المشاعر.
لاستخدامه، ما عليك سوى تقديم مكون components.sentiment_analyzer.SentimentAnalyzer إلى ملف bot/config.yml . كما في المثال:
language : "pt"
pipeline:
- name: WhitespaceTokenizer
- name: "components.sentiment_analyzer.SentimentAnalyzer" - name: RegexFeaturizer
بعد ذلك، كما في مثال ملف bot/components/labels.yml ، قم بإضافة العبارات التي تتوافق مع التصنيف (التقييم أو المشاعر).
أخيرًا، ما عليك سوى تدريب الروبوت مرة أخرى، وسيتم تخزين المعلومات في كيان sentiment إذا حدد المكون قيمة لهذا الكيان.
ارفع حاوية notebooks
make notebooks قم بالوصول إلى دفتر الملاحظات على localhost:8888
يمكن تشغيل وثائق المشروع محليًا باستخدام GitBook. لتثبيت gitbook عبر npm، تحتاج إلى تثبيت Node.js وnpm على جهاز الكمبيوتر الخاص بك.
npm install -g gitbook gitbook-cligitbook build .gitbook serve . http://localhost:4000/
المساهمة : للمساهمة في توثيق المشروع، اقرأ كيفية المساهمة في التوثيق
يتوفر جزء من الوثائق الفنية لإطار عمل Tais على موقع wiki الخاص بالمستودع. إذا لم تتمكن من العثور على إجابتك، فافتح مشكلة بعلامة duvida وسنحاول الرد في أسرع وقت ممكن.
إذا كانت لديك أي أسئلة بخصوص Rasa، فراجع مجموعة Rasa Stack Brasil Telegram، فنحن موجودون أيضًا للمساعدة.
شاهد المزيد من معلومات الاتصال على موقعنا: https://lappis.rocks.
تم تطوير إطار العمل النموذجي بالكامل بموجب ترخيص GPL3
راجع قائمة تبعيات الترخيص هنا


